前言
今天是用hackcaptcha庫,結合開源的DecryptLogin包打造一個驗證碼可以自動處理而非手動輸入的工具包,
廢話不多說,讓我們愉快地開始吧~
開發工具
Python版本: 3.6.4
相關模塊:
requests模塊;
opencv-python模塊;
numpy模塊;
keras模塊;
tensorflow模塊;
以及一些python自帶的模塊,
環境搭建
安裝python并添加到環境變數,pip安裝需要的相關模塊即可,
專案介紹
讓我們先來簡單介紹一下之前開源的DecryptLogin包,DecryptLogin是一個借助于requests包進行各大網站模擬登錄的python第三方包,專案地址:
https://github.com/CharlesPikachu/DecryptLogin
專案檔案:
https://httpsgithubcomcharlespikachudecryptlogin.readthedocs.io/zh/latest/
pip安裝這個包之后,你可以很輕松地實作各大網站的模擬登錄操作,例如模擬登錄知乎:
from DecryptLogin import login
lg = login.Login()
infos_return, session = lg.zhihu(username='Your Username', password='Your Password')
其中infos_return是一個字典物件,用于記錄用戶登錄后的一些資訊,而session則是用戶登錄之后的會話,進行模擬登錄的意義在于很多網站的資料必須在用戶登錄的狀態下才能看到,并且很多操作也必須在用戶登錄的狀態下才能進行(例如每日簽到等等),
上面那段代碼運行后效果如下:
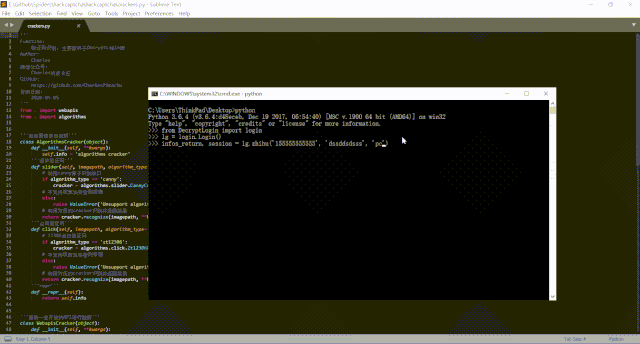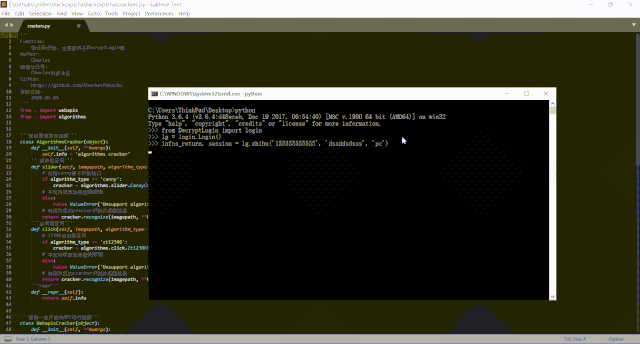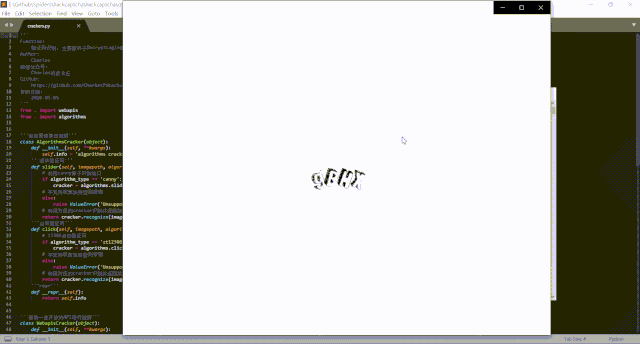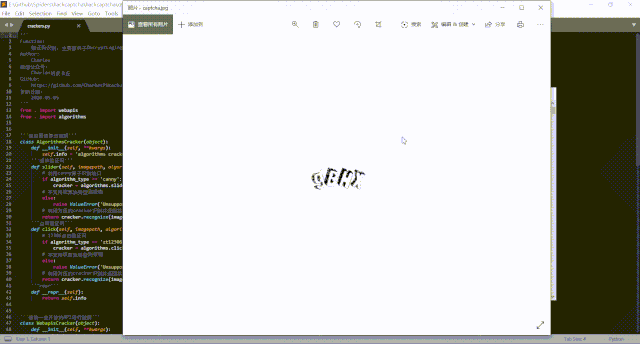
換句話說,在默認情況下,DecryptLogin庫要求用戶手動輸入登錄時遇到的驗證碼,
能不能讓DecryptLogin自動處理驗證碼呢?
答案是當然可以,你只需要自己定義一個驗證碼處理函式,然后在登錄的時候作為引數傳入就ok了,示例代碼如下:
from PIL import Image
from DecryptLogin import login
'''定義驗證碼識別函式'''
def crackvcFunc(imagepath):
# 打開驗證碼圖片
img = Image.open(imagepath)
# 識別驗證碼圖片
result = IdentifyAPI(img)
# 回傳識別結果(知乎為數字驗證碼)
return result
lg = login.Login()
infos_return, session = lg.zhihu(username='Your Username', password='Your Password', crackvcFunc=crackvcFunc)
上面這些內容其實在專案檔案里都有詳細的介紹,
hackcaptcha包誕生了,一款主要服務于驗證碼自動識別的python第三方包,專案檔案:
https://hackcaptcha-en.readthedocs.io/zh/latest/
因為開源hackcaptcha的主要目的是解決DecryptLogin庫的驗證碼自動處理問題,所以hackcaptcha目前只支持兩種型別的驗證碼自動處理,即數字(含英文字母)驗證碼以及12306的點擊驗證碼,當然,以后會隨著DecryptLogin庫的更新而逐漸加入一些新的支持,你只需要pip安裝這個庫就可以開始使用它了(安裝之前建議先提前在電腦上裝好keras和對應版本的tensorflow):
pip install hackcaptcha
對于數字驗證碼,hackcaptcha直接呼叫了百度的文字識別API:
https://ai.baidu.com/tech/ocr
因為我看了一下:
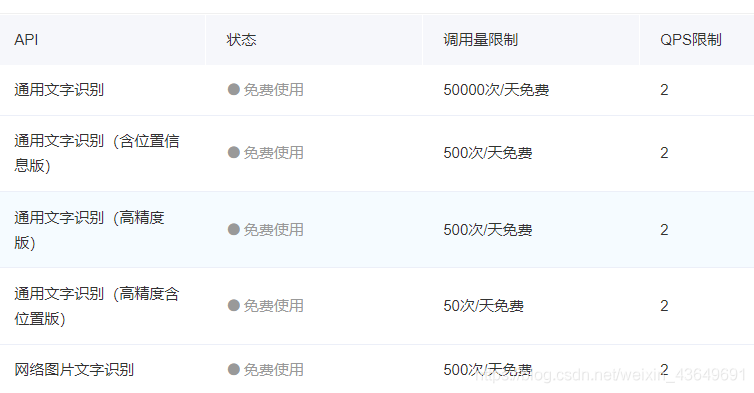
用戶每天可以免費呼叫這么多次,個人學習與玩耍使用完全是足夠的
具體而言,你需要到上面那個網站上自己注冊一個賬號,并新建一個應用,從而獲取到API Key和Secret Key就行了:

簡單寫幾行代碼就可以實作驗證碼識別的了:
from hackcaptcha.crackers import WebapisCracker
cracker = WebapisCracker()
infos_return = cracker.digital(imagepath='CAPTCHA IMAGE PATH', webapi_type='baidu', app_id='AppID', api_key='API Key', secret_key='Secret Key')
回傳的結果格式為:
{
'is_success': True,
'result': 'AFD2',
'error_msg': ''
}
對于12306的點擊驗證碼,我查閱了網上的做法,一般就是把12306的驗證碼做一下圖片分割:
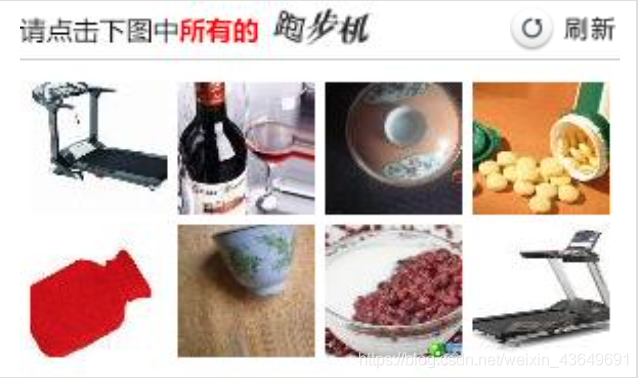
然后分別訓一個圖片分類器和文字分類器就行了,所以我就直接拿來用了,只需要這樣呼叫就行了:
from hackcaptcha.crackers import AlgorithmsCracker
cracker = AlgorithmsCracker()
infos_return = cracker.click(imagepath='CAPTCHA IMAGE PATH', algorithm_type='zt12306', text_model_path='text.h5', object_model_path='object.h5')
回傳的結果格式為:
{
'is_success': True,
'result': '1,2,5'
}
其中text.h5和object.h5這兩個模型在這可以下載到:
https://github.com/CharlesPikachu/hackcaptcha
我們可以結合DecryptLogin庫來看下效果(請注意,下面的代碼只適用于DecryptLogin版本號大于等于0.1.29的情況):
from DecryptLogin import login
from hackcaptcha.crackers import AlgorithmsCracker
'''定義驗證碼識別函式'''
def crackvcFunc(imagepath):
cracker = AlgorithmsCracker()
infos_return = cracker.click(imagepath=imagepath, algorithm_type='zt12306', text_model_path='text.h5', object_model_path='object.h5')
return infos_return['result']
lg = login.Login()
infos_return, session = lg.zt12306(username='用戶名', password='密碼', crackvcFunc=crackvcFunc)
運行效果:
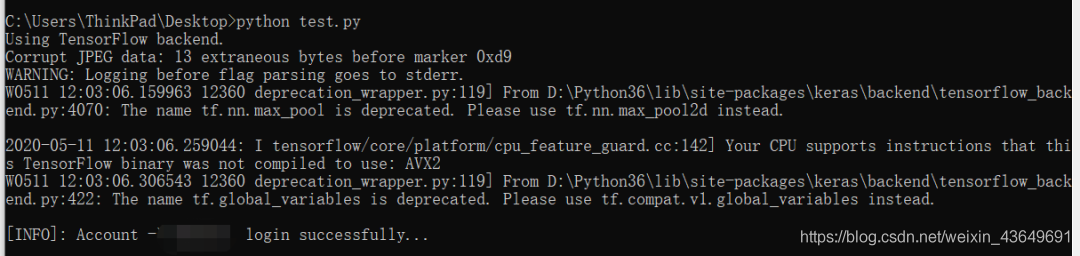
可以發現我們不再需要自己輸入那令人頭大的12306驗證碼,而直接呼叫訓練好的模型進行自動識別輸入即可實作12306的模擬登錄操作了~
文章到這里就結束了,感謝你的觀看,Python資訊安全,下篇文章分享Python+Selenium破譯淘寶滑塊驗證碼破解
為了感謝讀者們,我想把我最近收藏的一些編程干貨分享給大家,回饋每一個讀者,希望能幫到你們,
干貨主要有:
① 2000多本Python電子書(主流和經典的書籍應該都有了)
② Python標準庫資料(最全中文版)
③ 專案原始碼(四五十個有趣且經典的練手專案及原始碼)
④ Python基礎入門、爬蟲、web開發、大資料分析方面的視頻(適合小白學習)
⑤ Python學習路線圖(告別不入流的學習)
All done~私信獲取完整源代碼,,
往期回顧
用Python+Selenium破解春秋航空網滑塊驗證碼,資訊安全之路
用Python+Selenium破解B站滑塊驗證碼,資訊安全之路
簡單實作入門級隱寫術
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295096.html
標籤:其他
上一篇:什么是SSL技術