RDD依賴關系
RDD 血緣關系
RDD 只支持粗粒度轉換,即在大量記錄上執行的單個操作,將創建 RDD 的一系列Lineage(血統)記錄下來,以便恢復丟失的磁區,RDD 的Lineage 會記錄RDD 的元資料資訊和轉換行為,當該RDD 的部分磁區資料丟失時,它可以根據這些資訊來重新運算和恢復丟失的資料磁區,
package com.atguigu.bigdata.spark.core.rdd.dep
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark01_RDD_Dep {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
val lines: RDD[String] = sc.textFile("datas/word.txt")
println(lines.toDebugString)
println("**********************************")
val words: RDD[String] = lines.flatMap(_.split(" "))
println(words.toDebugString)
println("**********************************")
val wordToOne = words.map {
word => (word,1)
}
val wordGroup: RDD[((String, Int), Iterable[(String, Int)])] = wordToOne.groupBy(word => word)
println(wordGroup.toDebugString)
println("**********************************")
val wordToCount = wordGroup.map{
case (word, list) => {
list.reduce((t1, t2) => {
(t1._1, t1._2 + t2._2)
}
)
}
}
println(wordToCount.toDebugString)
println("**********************************")
val array = wordToCount.collect()
array.foreach(println)
//TODO 關閉spark的連接
sc.stop()
}
}
2. RDD 依賴關系
所謂的依賴關系,其實就是兩個相鄰RDD 之間的關系,
package com.atguigu.bigdata.spark.core.rdd.dep
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Spark01_RDD_Dep {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
val lines: RDD[String] = sc.textFile("datas/word.txt")
println(lines.dependencies)
println("**********************************")
val words: RDD[String] = lines.flatMap(_.split(" "))
println(words.dependencies)
println("**********************************")
val wordToOne = words.map {
word => (word,1)
}
val wordGroup: RDD[((String, Int), Iterable[(String, Int)])] = wordToOne.groupBy(word => word)
println(wordGroup.dependencies)
println("**********************************")
val wordToCount = wordGroup.map{
case (word, list) => {
list.reduce((t1, t2) => {
(t1._1, t1._2 + t2._2)
}
)
}
}
println(wordToCount.dependencies)
println("**********************************")
val array = wordToCount.collect()
array.foreach(println)
//TODO 關閉spark的連接
sc.stop()
}
}
3. RDD 窄依賴
窄依賴表示每一個父(上游)RDD 的Partition 最多被子(下游)RDD 的一個Partition 使用,窄依賴可以形象的比喻為獨生子女,
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd)
4. RDD 寬依賴
寬依賴表示同一個父(上游)RDD 的Partition 被多個子(下游)RDD 的Partition 依賴,會引起Shuffle,寬依賴可以形象的比喻為多生,
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]]
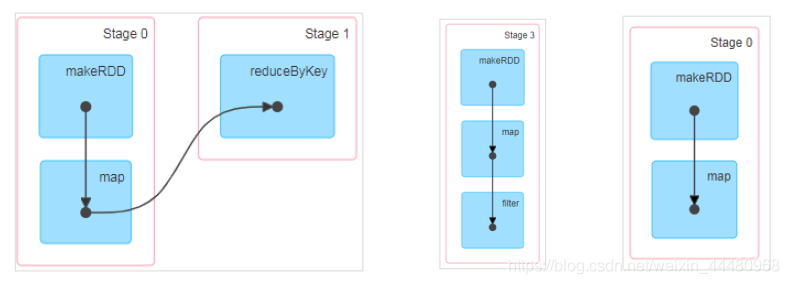
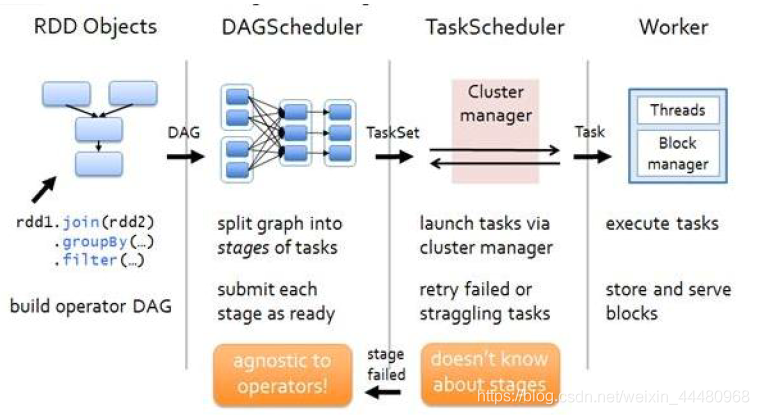
5. RDD 階段劃分
DAG(Directed Acyclic Graph)有向無環圖是由點和線組成的拓撲圖形,該圖形具有方向,不會倍訓,例如,DAG 記錄了RDD 的轉換程序和任務的階段,
RDD 階段劃分原始碼
try {
// New stage creation may throw an exception if, for example, jobs are run on
a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
……
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
……
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage]
= {
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
……
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
6. RDD 任務劃分
RDD 任務切分中間分為:Application、Job、Stage 和 Task,
- Application:初始化一個 SparkContext 即生成一個Application;
- Job:一個Action 算子就會生成一個Job;
- Stage:Stage 等于寬依賴(ShuffleDependency)的個數加1;
- Task:一個 Stage 階段中,最后一個RDD 的磁區個數就是Task 的個數,
注意:Application->Job->Stage->Task 每一層都是1 對n 的關系,
RDD 任務劃分原始碼
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties,
Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
……
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
……
override def findMissingPartitions(): Seq[Int] = {
mapOutputTrackerMaster
.findMissingPartitions(shuffleDep.shuffleId)
.getOrElse(0 until numPartitions)
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295114.html
標籤:其他
上一篇:Spark的RDD序列化
下一篇:Dubbo