目錄
- 一、實驗環境
- 二、部署zookeeper
- 三、部署kafka
- kafka命令列操作
- 四、部署EFK
- 一、部署Elasticsearch
- 二、部署elasticsearch-head
- 三、部署kibana
- 四、部署logstash
- 五、部署Filebeat
- 五、驗證
一、實驗環境
192.168.238.150:zookeeper kafka
192.168.238.100:zookeeper kafka
192.168.238.99:zookeeper kafka
二、部署zookeeper
三臺服務器安裝
[root@localhost ~]# ntpdate ntp.aliyun.cpm #同步阿里云時鐘服務器
[root@localhost ~]# yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel #安裝依賴環境
[root@localhost ~]# java -version #查看java版本

[root@localhost ~]# cd /opt
[root@localhost opt]# wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz #下載zookeeper軟體包
[root@localhost opt]# tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz #解包
[root@localhost opt]# mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7 #將目錄移到/usr/local
[root@localhost opt]# cd /usr/local/zookeeper-3.5.7/conf/
[root@localhost conf]# cp zoo_sample.cfg zoo.cfg
[root@localhost conf]# vim zoo.cfg
tickTime=2000 #通信心跳時間,Zookeeper服務器與客戶端心跳時間,單位毫秒
initLimit=10 #Leader和Follower初始連接時能容忍的最多心跳數(tickTime的數量),這里表示為10*2s
syncLimit=5 #Leader和Follower之間同步通信的超時時間,這里表示如果超過5*2s,Leader認為Follwer死掉,并從服務器串列中洗掉Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ●修改,指定保存Zookeeper中的資料的目錄,目錄需要單獨創建
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●添加,指定存放日志的目錄,目錄需要單獨創建
clientPort=2181 #客戶端連接埠

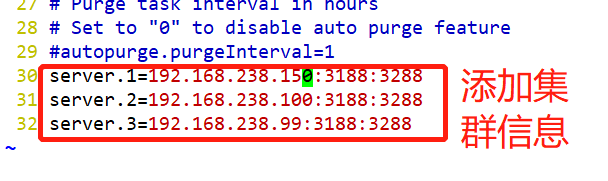
#在每個節點上創建資料目錄和日志目錄
[root@localhost conf]# mkdir /usr/local/zookeeper-3.5.7/data
[root@localhost conf]# mkdir /usr/local/zookeeper-3.5.7/logs
[root@localhost conf]# cd ..

#在每個節點的dataDir指定的目錄下創建一個 myid 的檔案
[root@localhost zookeeper-3.5.7]# echo 1 > /usr/local/zookeeper-3.5.7/data/myid #第一臺
[root@localhost zookeeper-3.5.7]# echo 2 > /usr/local/zookeeper-3.5.7/data/myid #第二臺
[root@localhost zookeeper-3.5.7]# echo 3 > /usr/local/zookeeper-3.5.7/data/myid #第三臺
#配置Zookeeper啟動腳本
[root@localhost zookeeper-3.5.7]# vim /etc/init.d/zookeeper
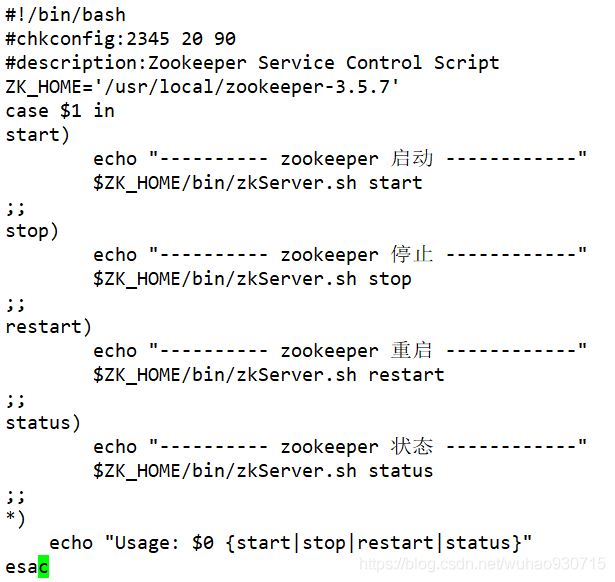
#設定開機自啟
[root@localhost zookeeper-3.5.7]# chmod +x /etc/init.d/zookeeper
[root@localhost zookeeper-3.5.7]# chkconfig --add zookeeper
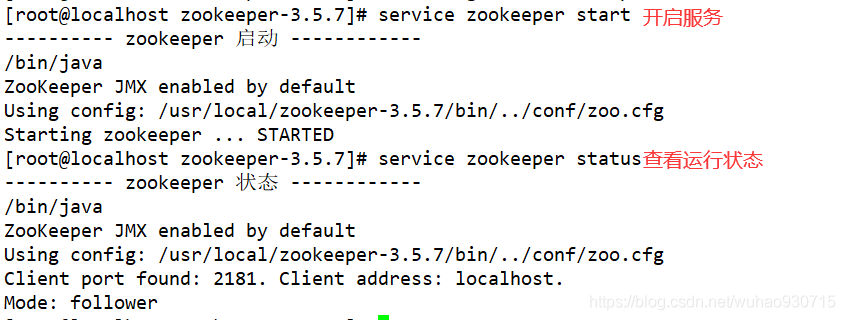
三、部署kafka
在安裝zookeeper的三臺服務器上部署kafka
[root@localhost zookeeper-3.5.7]# cd /opt
[root@localhost opt]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz #下載kafka軟體包
[root@localhost opt]# tar zxvf kafka_2.13-2.7.1.tgz #解包
[root@localhost opt]# mv kafka_2.13-2.7.1 /usr/local/kafka
[root@localhost opt]# cd /usr/local/kafka/config/
[root@localhost config]# cp server.properties{,.bak} #備份組態檔
[root@localhost config]# vim server.properties
第21行 broker.id=0 #broker的全域唯一編號,每個broker不能重復,因此要在其他機器上配置 broker.id=1、broker.id=2
第31行 listeners=PLAINTEXT://192.168.238.100:9092 #取消注釋,指定監聽的IP和埠,另外兩臺為192.168.238.150:9092;192.168.238.99:9092
第42行 num.network.threads=3 #broker處理網路請求的執行緒數量,一般情況下不需要去修改
第45行 num.io.threads=8 #用來處理磁盤IO的執行緒數量,數值應該大于硬碟數
第48行 socket.send.buffer.bytes=102400 #發送套接字的緩沖區大小
第51行 socket.receive.buffer.bytes=102400 #接收套接字的緩沖區大小
第54行 socket.request.max.bytes=104857600 #請求套接字的緩沖區大小
第60行 log.dirs=/usr/local/kafka/logs #kafka運行日志存放的路徑,也是資料存放的路徑
第65行 num.partitions=1 #topic在當前broker上的默認磁區個數,會被topic創建時的指定引數覆寫
第69行 num.recovery.threads.per.data.dir=1 #用來恢復和清理data下資料的執行緒數量
第103行 log.retention.hours=168 #segment檔案(資料檔案)保留的最長時間,單位為小時,默認為7天,超時將被洗掉
第110行 log.segment.bytes=1073741824 #一個segment檔案最大的大小,默認為1G,超出將新建一個新的segment檔案
第123行 zookeeper.connect=192.168.238.100:2181,192.168.238.150:2181,192.168.238.99:2181 #配置連接Zookeeper集群地址
[root@localhost config]# vim /etc/profile #修改環境變數
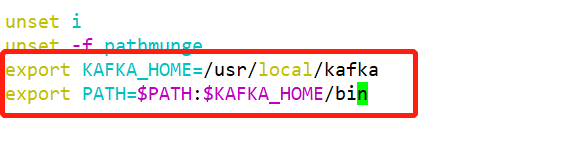
[root@localhost config]# source /etc/profile #多載檔案
[root@localhost config]# vim /etc/init.d/kafka #配置kafka啟動腳本
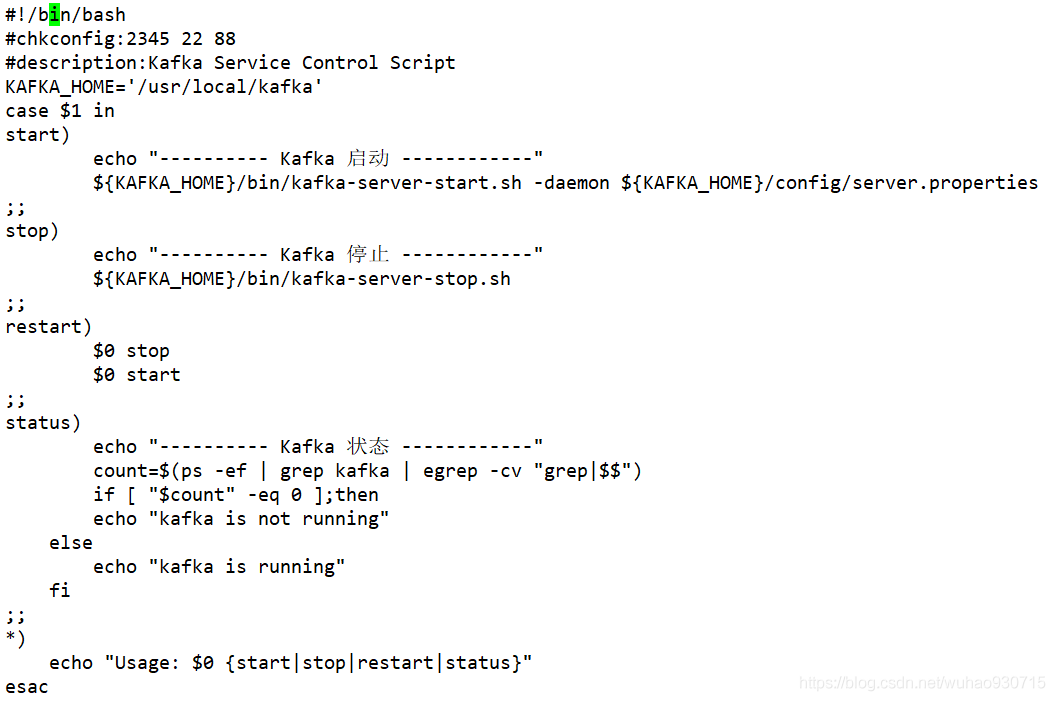
[root@localhost config]# chmod +x /etc/init.d/kafka
[root@localhost config]# chkconfig --add kafka
[root@localhost config]# service kafka start
---------- Kafka 啟動 ------------

kafka命令列操作
#創建topic
[root@localhost logs]# kafka-topics.sh --create --zookeeper 192.168.238.150:2181,192.168.238.100:2181,192.168.238.99:2181 --replication-factor 2 --partitions 3 --topic test

#查看當前系統的所有topic
[root@localhost logs]# kafka-topics.sh --list --zookeeper 192.168.238.150:2181,192.168.238.100:2181,192.168.238.99:2181
test
#查看指定topic詳情
[root@localhost logs]# kafka-topics.sh --describe --zookeeper 192.168.238.150:2181,192.168.238.100:2181,192.168.238.99:2181
Topic: test PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: test Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: test Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
#發布訊息
[root@localhost logs]# kafka-console-producer.sh --broker-list 192.168.238.150:9092,192.168.238.100:9092,192.168.238.99:9092 --topic test2
>holle
#消費訊息
[root@localhost logs]# kafka-console-consumer.sh --bootstrap-server 192.168.238.150:9092,192.168.238.100:9092,192.168.238.99:9092 --topic test2 --from-beginning
holle
#修改磁區數
[root@localhost logs]# kafka-topics.sh --zookeeper 192.168.238.150:2181,192.168.238.100:2181,192.168.238.99:2181 --alter --topic test2 --partitions 6
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!
#洗掉topic
[root@localhost logs]# kafka-topics.sh --delete --zookeeper 192.168.238.150:2181,192.168.238.100:2181,192.168.238.99:2181 --topic test
Topic test is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
四、部署EFK
node1:192.168.238.133 Elasticsearch kibana
node2:192.168.238.134 Elasticsearch
apach:192.168.238.135 Apache logstash
一、部署Elasticsearch
node1、node2
[root@localhost ~]# hostnamectl set-hostname node1 #修改主機名
[root@localhost ~]# su
[root@node1 ~]# ntpdate ntp.aliyun.com
[root@node1 ~]# vim /etc/hosts #添加主機映射
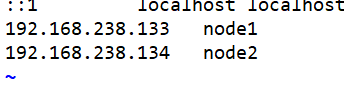

#上傳elasticsearch-5.5.0.rpm到/opt目錄下
[root@node1 ~]# cd /opt
[root@node1 opt]# rpm -ivh elasticsearch-5.5.0.rpm #安裝
#加載系統服務
[root@node1 opt]# systemctl daemon-reload
[root@node1 opt]# systemctl enable elasticsearch.service
[root@node1 opt]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak #備份
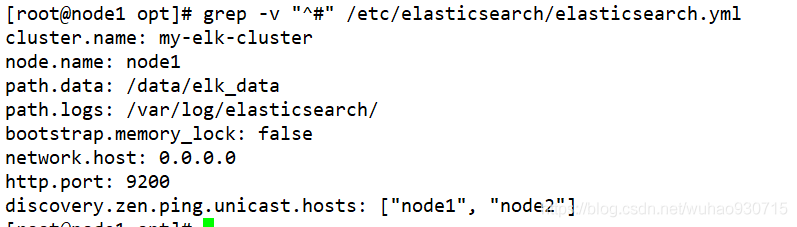
[root@node1 opt]# vim /etc/elasticsearch/elasticsearch.yml
第17行 cluster.name: my-elk-cluster #集群名稱
第23行 node.name: node1 #節點名稱,另一臺為node2
第33行 path.data: /data/elk_data #資料存放路徑
第37行 path. logs: /var/log/elasticsearch/ #日志存放路徑
第43行 bootstrap.memory_lock: false #鎖定物理記憶體地址,防止es記憶體被交換出去,也就是避免es使用swap交換磁區,頻繁的交換,會導致Ios變高(性能測驗:每秒的讀寫次數),
第55行 network.host: 0.0.0.0 #提供服務系結的IP地址,0.0.0.0代表所有地址
第59行 http.port: 9200 #偵聽埠為9200
第68行 discoveryp zen.ping.unicast.hosts:["node1", "node2"] #集群發現通過單播實作單播
[root@node1 opt]# mkdir -p /data/elk_data # #創建資料檔案目錄
[root@node1 opt]# chown elasticsearch:elasticsearch /data/elk_data/ ##修改目錄屬主屬組
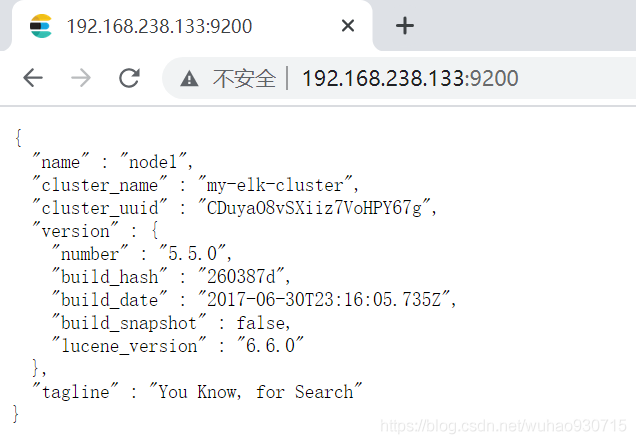
[root@node1 opt]# systemctl start elasticsearch.service #開啟

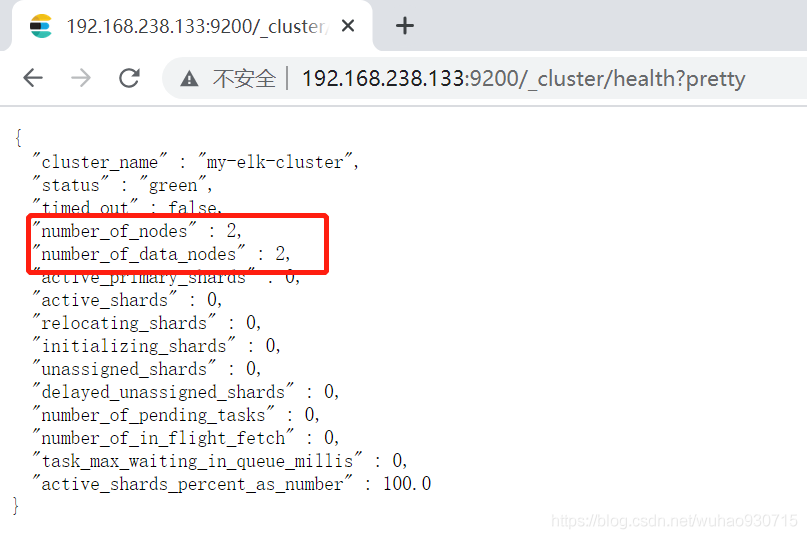
查看節點資訊
查看群集健康狀態資訊
二、部署elasticsearch-head
node1、node2
##安裝node組件
#上傳node-v8.2.1.tar.gz到/opt
[root@node1 opt]# yum install gcc gcc-c++ make -y #安裝依賴環境
[root@node1 opt]# tar xzvf node-v8.2.1.tar.gz #解包
[root@node1 node-v8.2.1]# ./configure && make -j3 && make install #編譯安裝
##安裝phantomjs前端框架
#上傳phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@node1 node-v8.2.1]# cd /usr/local/src/
[root@node1 src]# tar xjvf phantomjs-2.1.1-linux-x86_64.tar.bz2 #解包
[root@node2 bin]# cp phantomjs /usr/local/bin
##安裝elasticsearch-head圖形化界面
[root@node1 bin]# cd /usr/local/src/
#上傳elasticsearch-head軟體包
[root@localhost src]# tar xzvf elasticsearch-head.tar.gz #解包
[root@node1 src]# cd elasticsearch-head/
[root@node1 elasticsearch-head]# npm install

[root@node1 elasticsearch-head]# vim /etc/elasticsearch/elasticsearch.yml
在最后插入
http.cors.enabled: true #開啟跨域訪問支持
http.cors.allow-origin: "*" #跨域方位允許的域名地址

[root@node1 elasticsearch-head]# systemctl restart elasticsearch
[root@node1 elasticsearch-head]# npm run start &
[root@node1 elasticsearch-head]# netstat -natp | grep 9100
tcp 0 0 0.0.0.0:9100 0.0.0.0:* LISTEN 128023/grunt
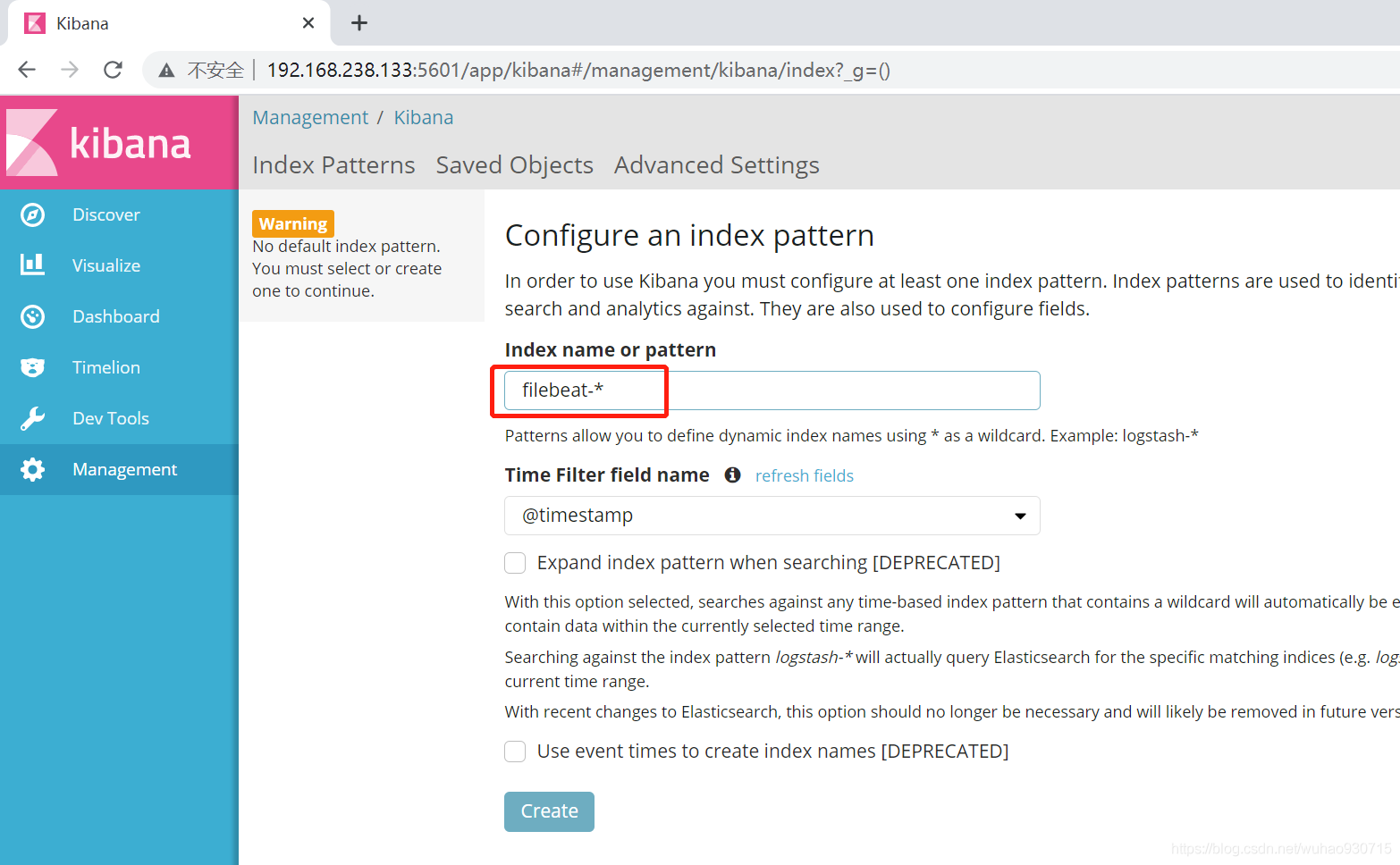
三、部署kibana
node1上部署kibana
[root@node1 elasticsearch-head]# cd /usr/local/src/
#上傳kibana-5.5.1-x86_64.rpm 到/usr/local/src目錄
[root@node1 src]# rpm -ivh kibana-5.5.1-x86_64.rpm #安裝
[root@node1 src]# cd /etc/kibana/
[root@node1 kibana]# cp kibana.yml kibana.yml.bak
[root@node1 kibana]# vim kibana.yml
第2行 server.port: 5601 #取消注釋打開埠
第7行 server.host: "0.0.0.0" #取消注釋,修改監聽地址
第21行 elasticsearch.url: "http://192.168.238.133:9200" #取消注釋,與elasticsearch建立聯系
第30行 kibana.index: ".kibana" #取消注釋,在elasticsearch中添加kibana索引
[root@node1 kibana]# systemctl start kibana.service #開啟服務
[root@node1 kibana]# systemctl enable kibana.service #設定開機自啟
四、部署logstash
Apache:192.168.238.135
##logstash是為了收集Kafka佇列傳輸過來的資料的
[root@localhost ~]# hostnamectl set-hostname apache
[root@localhost ~]# su
[root@apache ~]# ntpdate ntp.aliyun.com
[root@apache ~]# cd /opt
#上傳logstash軟體包
[root@apache opt]# rpm -ivh logstash-5.5.1.rpm #安裝
[root@apache opt]# systemctl start logstash.service
[root@apache opt]# systemctl enable logstash.service
[root@apache opt]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/ #命令優化
[root@apache opt]# cd /etc/logstash/conf.d/
[root@apache conf.d]# vim filebeat.conf
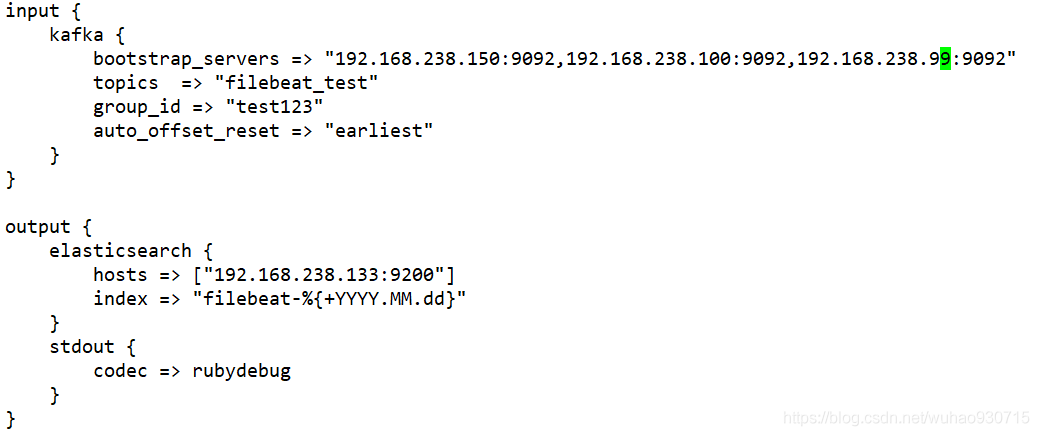
[root@apache conf.d]# nohup logstash -f filebeat.conf &

五、部署Filebeat
Filebeat:192.168.238.136
[root@localhost opt]# cd /usr/local/
[root@localhost local]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.5.1-linux-x86_64.tar.gz
[root@localhost local]# tar -xvzf filebeat-7.5.1-linux-x86_64.tar.gz
[root@localhost local]# mv filebeat-7.5.1-linux-x86_64 /usr/local/filebeat
[root@localhost local]# cd filebeat/
[root@localhost filebeat]# vim filebeat.yml
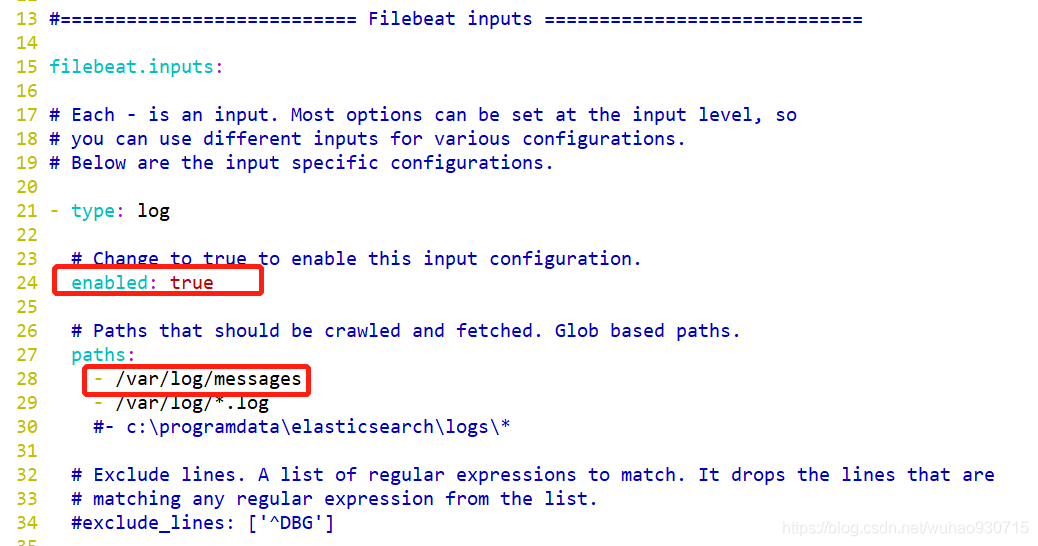

ps:將filebeat.yml檔案中,如下注釋掉,否則啟動不了
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
[root@localhost filebeat]# ./filebeat -e -c filebeat.yml #啟動
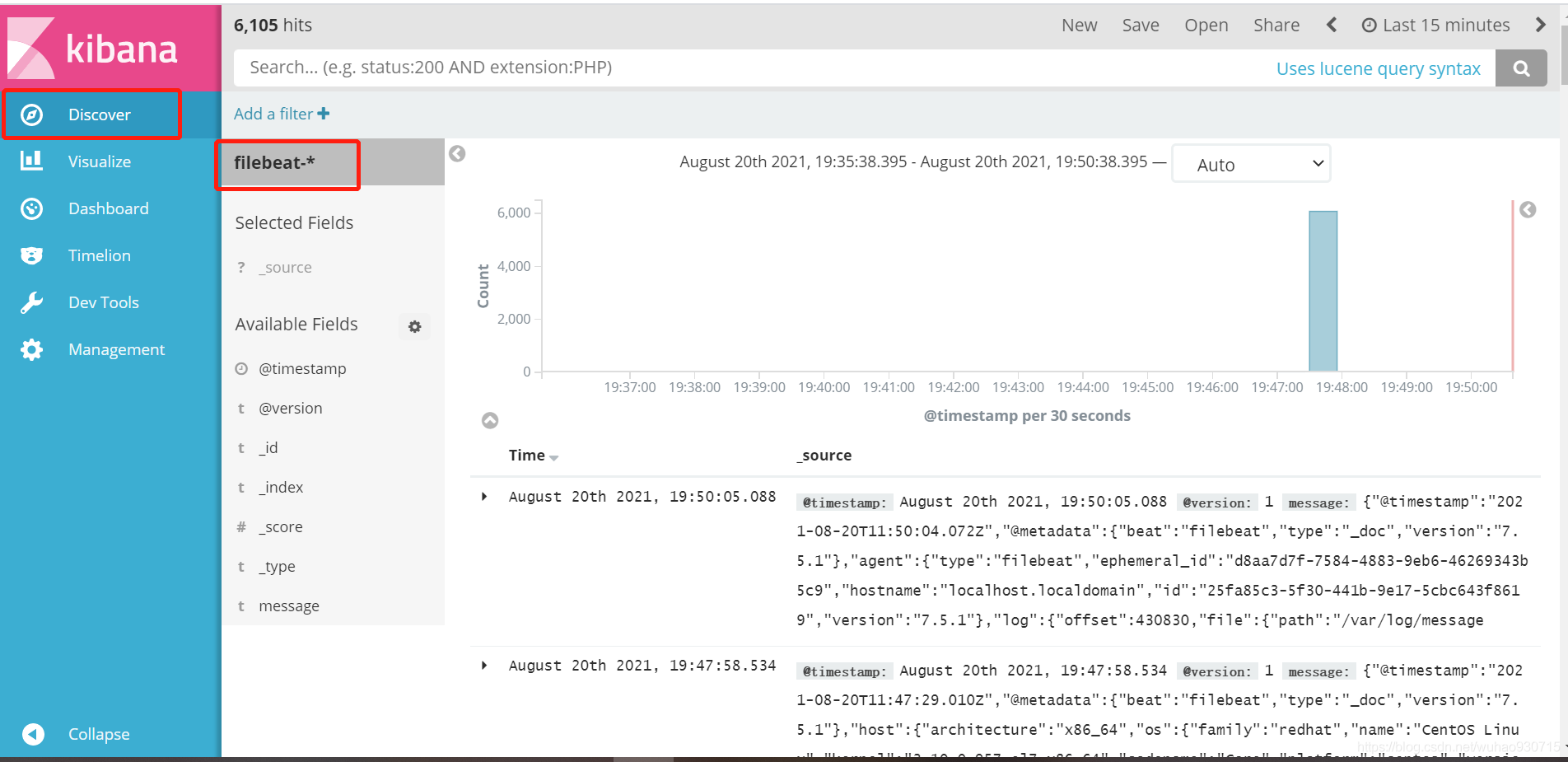
五、驗證
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295117.html
標籤:其他
上一篇:(1)大資料和應用場景介紹