文章目錄
- 一、為什么需要回圈神經網路?
- 二、RNN的原理
- 三、RNN的型別
- 四、RNN存在的問題
- 五、LSTM/GRU
- 六、Gated Recurrent Unit—GRU
- 七、BI-LSTM
- 1.雙向LSTM的模型代碼實作
- 2.雙向LSTM+Attention的模型代碼實作
- 八、Deep-BILSTM
一、為什么需要回圈神經網路?
??雖然全連接神經網路理論上只要訓練資料足夠,給定特定的x,就能得到希望的y,但是全連接神經網路只能處理獨立的輸入,前一個輸入和后一個輸入是完全沒有關系的,針對某些任務需要能夠更好的處理序列的資訊,即前面的輸入和后面的輸入是有關系的情況,此時,就需要用到回圈神經網路RNN,該神經網路能夠很好的處理序列資訊,
標準的全連接神經網路(fully connected neural network)處理序列資料會有兩個問題:
1)全連接神經網路輸入層和輸出層長度固定,而不同序列的輸入、輸出可能有不同的長度,選擇最大長度并對短序列進行填充(pad)不是一種很好的方式;
2)全連接神經網路同一層的節點之間是無連接的,當需要用到序列之前時刻的資訊時,全連接神經網路無法做到,一個序列的不同位置之間無法共享特征,
二、RNN的原理
參考于一文搞懂RNN(回圈神經網路)基礎篇
??一個簡單的回圈神經網路,它由輸入層、隱藏層(單個)、輸出層構成,
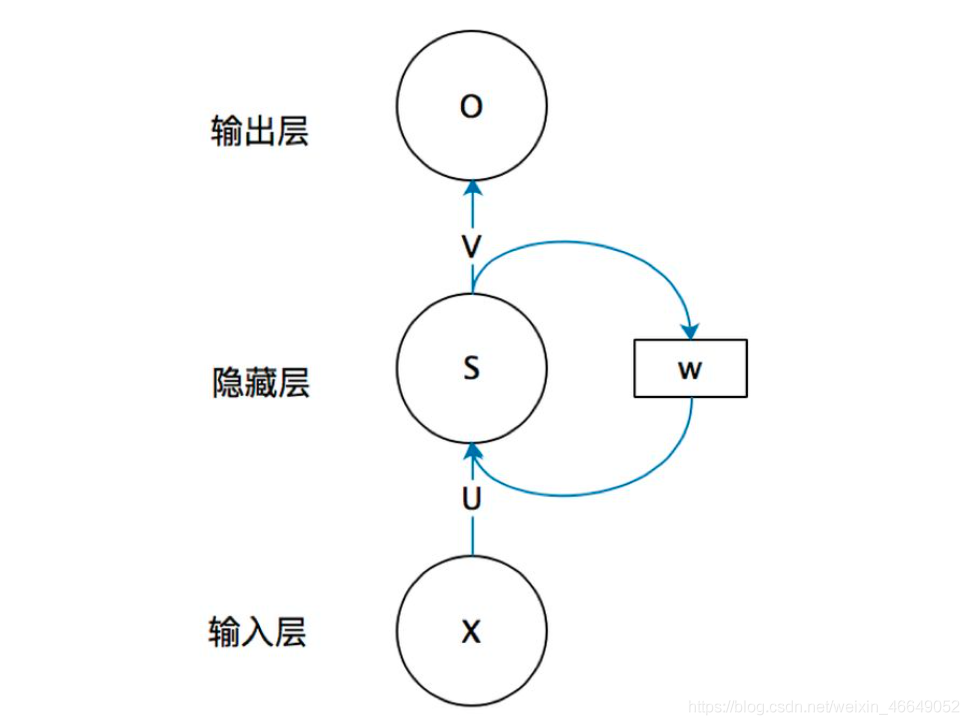
x是輸入層的值
U是輸入層到隱藏層的權重矩陣
s是隱藏層的值
權重矩陣 W就是上一個時刻隱藏層的值作為這一時刻的輸入的權重,回圈神經網路的隱藏層的值s不僅僅取決于當前時刻的輸入x,還取決于前一時刻隱藏層的值s,
V是隱藏層到輸出層的權重矩陣
注意事項:引數
U
、
V
、
W
U、V、W
U、V、W在RNN中是共享的,
????下圖展示了上一時刻的隱藏層是如何影響當前時刻的隱藏層的,
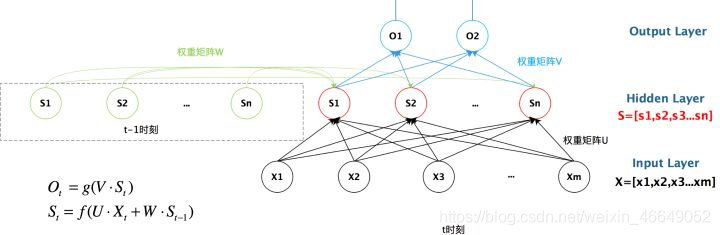
????回圈神經網路時間線展開圖為:
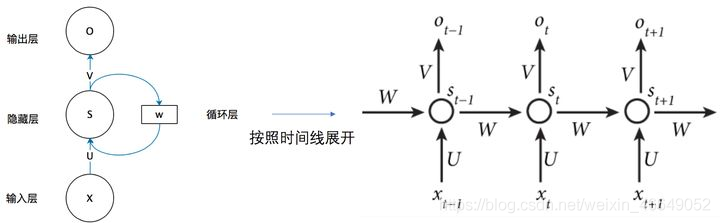
這個網路在t時刻接收到輸入
x
t
x_t
xt? 之后,隱藏層的值是
s
t
s_t
st? ,輸出值是
o
t
o_t
ot? ,
s
t
s_t
st?的值不僅僅取決于
x
t
x_t
xt?,還取決于
s
t
?
1
s_{t-1}
st?1?,
????回圈神經網路計算方法用公式表示為:
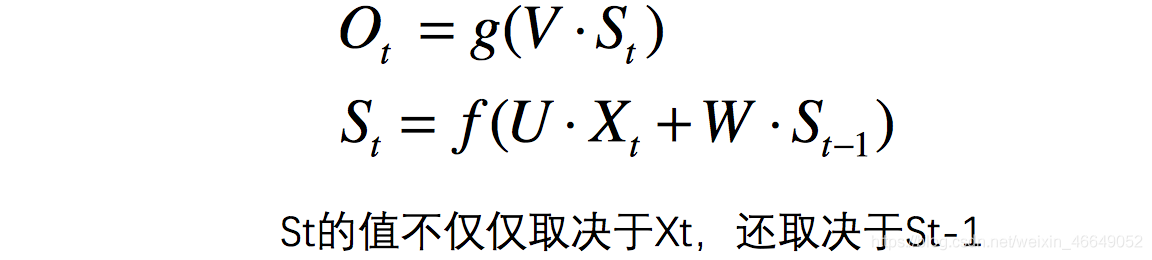
此處的
g
g
g在分類中為softmax函式,
??下圖展示了一個最簡單的使用單個全連接層作為回圈體 A 的 RNN,圖中黃色的 tanh 小方框表示一個使用 tanh 作為激活函式的全連接層,
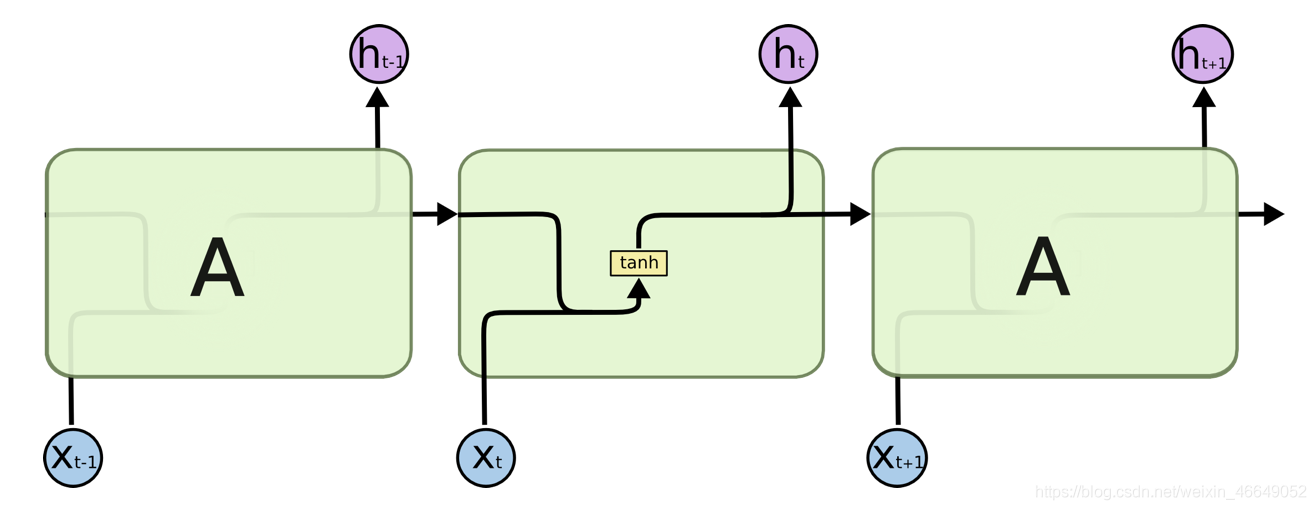
t
t
t時刻回圈體 A 的輸入包括
X
t
X_t
Xt?和從
t
?
1
t-1
t?1時刻傳遞來的隱藏狀態
h
t
?
1
h_{t-1}
ht?1?,回圈體 A 的兩部分輸入如何處理呢?將
X
t
X_t
Xt?和
h
t
?
1
h_{t-1}
ht?1?直接拼接起來,成為一個更大的矩陣/向量 [
X
t
X_t
Xt?,
h
t
?
1
h_{t-1}
ht?1?],假設
X
t
X_t
Xt? 和
h
t
?
1
h_{t-1}
ht?1?的形狀分別為 [1, 3] 和 [1, 4],則最后回圈體 A 中全連接層輸入向量的形狀為 [1, 7],拼接完后按照全連接層的方式進行處理即可,
????RNN前向傳播如圖所示:
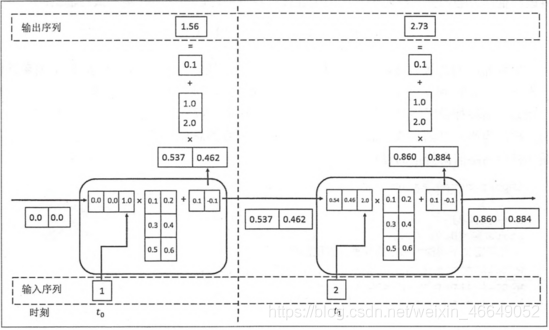
- RNN可以用于訓練語言模型 ,一個詞預測下一個詞的概率(非常稀疏的高維向量,和為1)并可以經過交叉熵進行優化,已經訓練好的RNN模型,可以生成一些文本,這個可以稱為decoding,
三、RNN的型別
??使用RNN解決特定的問題,根據不同的問題,我們可以定義出不同型別的RNN,
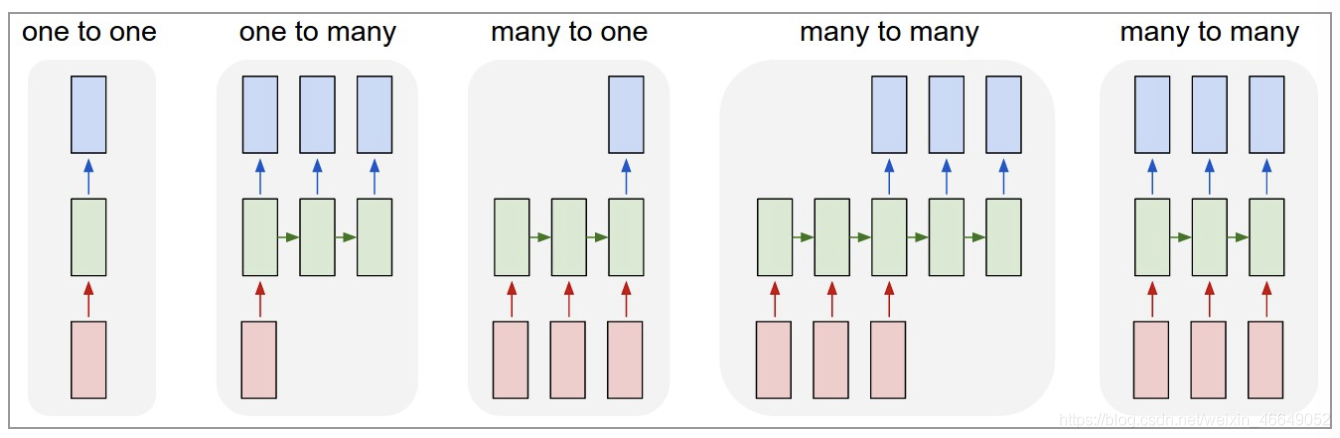
- one to one:其實和全連接神經網路并沒有什么區別,這一類別算不得是 RNN,
- one to many:輸入不是序列,輸出是序列,輸入是靜態的資料,輸出是動態的資料,這種模型可以用于輸入圖片根據RNN模型生成圖片表示內容,即文本生成,
- many to one:輸入是序列,輸出不是序列,這種模型適用于文本分類(情感分析)任務或者圖片生成任務,
- many to many:輸入和輸出都是序列,但兩者長度可以不一樣,這種模型可以用于機器翻譯,文案生成,自動生成摘要,
- many to many:輸出和輸出都是序列,兩者長度一樣,這種模型可以用于詞性標注或者股票預測,
四、RNN存在的問題
??單向 RNN 的缺點是在
t
t
t 時刻,無法使用
t
+
1
t+1
t+1 及之后時刻的序列資訊,所以就有了雙向回圈神經網路,理論上回圈神經網路可以支持任意長度的序列,然而在實際中,如果序列過長會導致優化時出現梯度消散的問題(the vanishing gradient problem),所以實際中一般會規定一個最大長度,當序列長度超過規定長度之后會對序列進行截斷,RNN 面臨的一個技術挑戰是長期依賴(long-term dependencies)問題,即當前時刻無法從序列中間隔較大的那個時刻獲得需要的資訊,在理論上,RNN 完全可以處理長期依賴問題,但實際處理程序中,RNN 表現得并不好,但是 GRU 和 LSTM 可以處理梯度消散問題和長期依賴問題,
??RNN縱向維度可能出現梯度消散與梯度爆炸問題,RNN在時間維度可能產生長期依賴問題(本質上也是梯度消散與梯度爆炸問題,梯度的問題導致了長期依賴問題),針對于RNN的梯度問題,

可抽象為
W
R
W_R
WR?的
k
k
k次方,當
W
R
W_R
WR?較小時,梯度彌散,當
W
R
W_R
WR?較大時,梯度爆炸,針對梯度爆炸問題,解決方案是引入Gradient Clipping(梯度裁剪),通過Gradient Clipping,將梯度約束在一個范圍內,這樣不會使得梯度過大,針對梯度消失與長期依賴問題,GRU 和 LSTM 可以處理梯度消散問題和長期依賴問題,GRU 和 LSTM只能緩解梯度消失問題,
五、LSTM/GRU
??在實際建模中,RNN 經常出現梯度爆炸或梯度消失等問題,因此我們一般使用長短期記憶單元或門控回圈單元代替基本的 RNN 回圈體,它們引入了門控機制以遺忘或保留特定的資訊而加強模型對長期依賴關系的捕捉,它們同時也大大緩解了梯度爆炸或梯度消失的問題,回圈網路的每一個隱藏層都有多個回圈單元,隱藏層
h
t
?
1
h_{t-1}
ht?1?的向量儲存了所有該層神經元在
t
?
1
t-1
t?1步的激活值,一般標準的回圈網路會將該向量通過一個仿射變換并添加到下一層的輸入中,即
W
?
h
t
?
1
+
U
?
X
t
W* h_{t-1}+U* X_t
W?ht?1?+U?Xt?,而這個簡單的計算程序由于重復使用
W
W
W 和
U
U
U 而會造成梯度爆炸或梯度消失,因此我們可以使用門控機制控制前一時間步隱藏層保留的資訊和當前時間步輸入的資訊,并選擇性地輸出一些值而作為該單元的激活值, 之所以叫“門”結構,是因為使用
s
i
g
m
o
i
d
sigmoid
sigmoid作為激活函式的全連接神經網路層會輸出一個 0 到 1 之間的數值,描述當前輸入有多少資訊量可以通過這個結構,于是這個結構的功能就類似于一扇門,當門打開時(sigmoid 全連接層輸出為 1 時),全部資訊可以通過;當門關上時(sigmoid 神經網路層輸出為 0 時),任何資訊都無法通過,
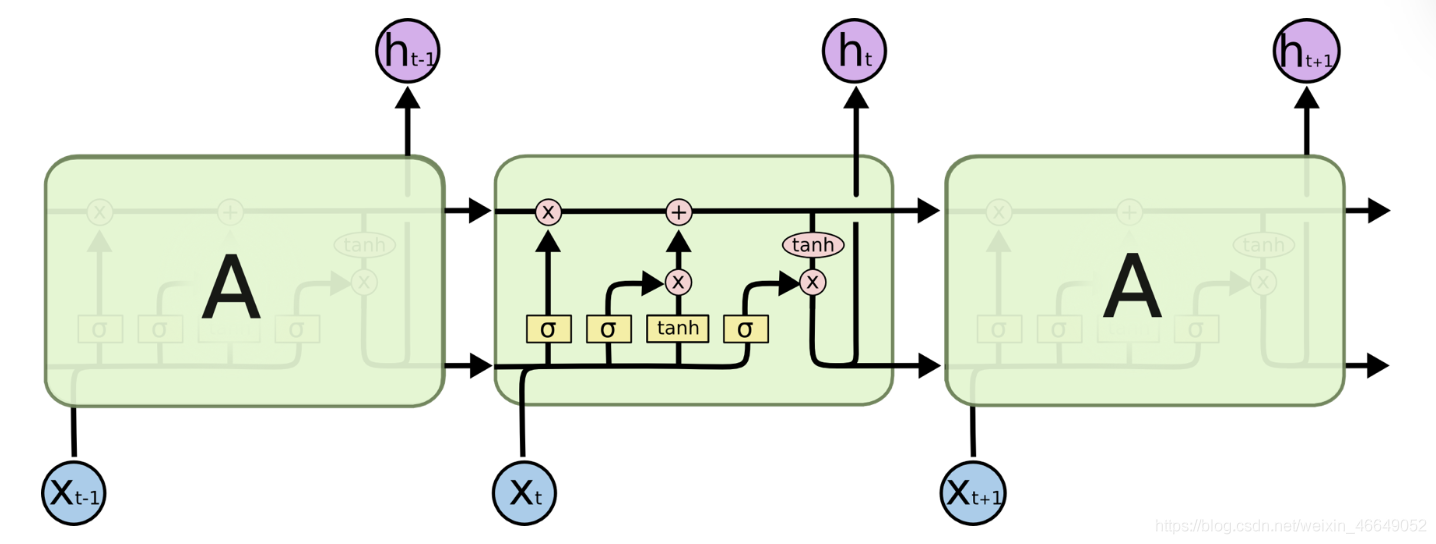
????LSTM 有三個門,分別是“遺忘門”(forget gate)、“輸入門”(input gate)和“輸出門”(output gate),
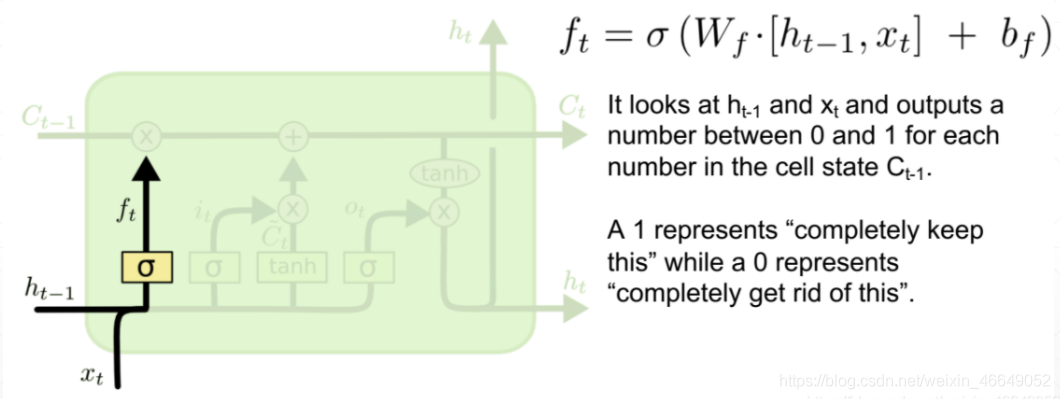
“遺忘門”的作用是讓回圈神經網路“忘記”之前沒有用的資訊,控制以前記憶的資訊到底需要保留多少
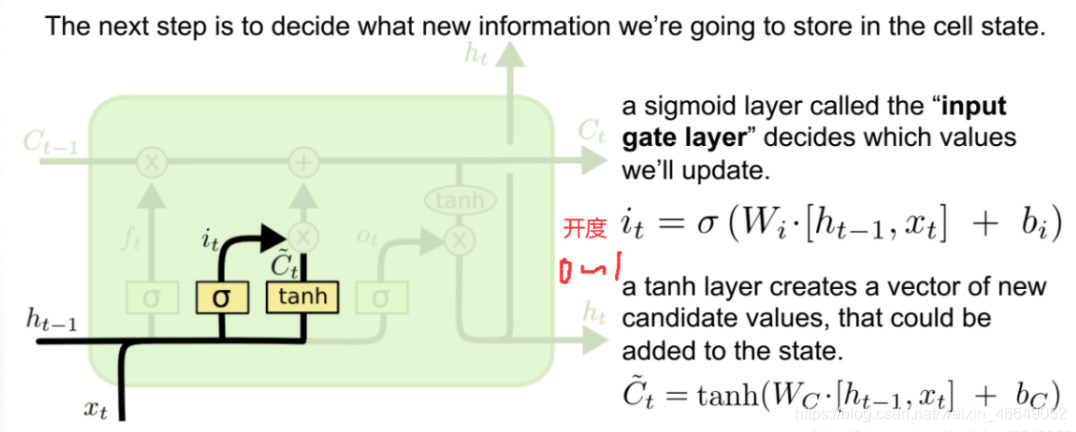
“輸入門”決定哪些資訊進入當前時刻的狀態,分為以前保留的資訊加上當前輸入有意義的資訊
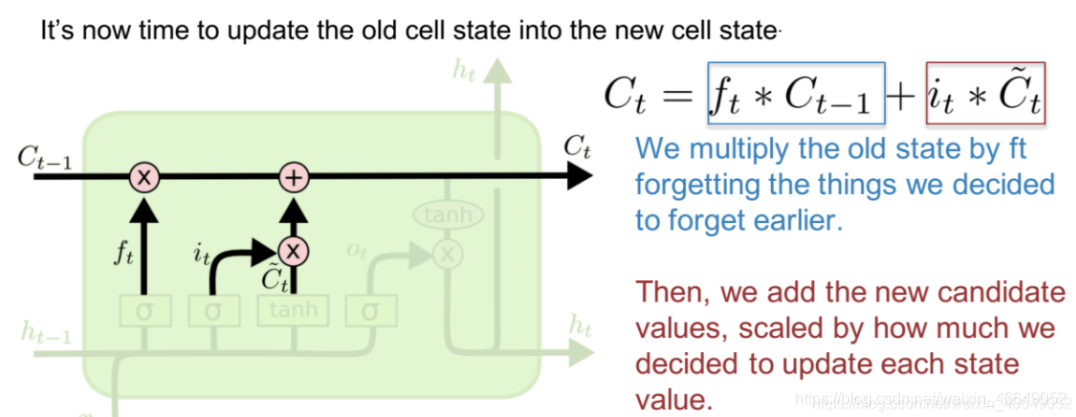
通過“遺忘門”和“輸入門”,LSTM 結構可以很有效地決定哪些資訊應該被遺忘,哪些資訊應該得到保留,且更新當前時刻狀態Ct,輸入與輸入門對應元素相乘表示當前時刻需要添加到Ct的記憶,前一時間步的記憶 Ct-1 與遺忘門 ft 對應元素相乘就表示了需要保留或遺忘的歷史資訊是多少,最后將這兩部分的資訊相加在一起就更新了記憶Ct的資訊,
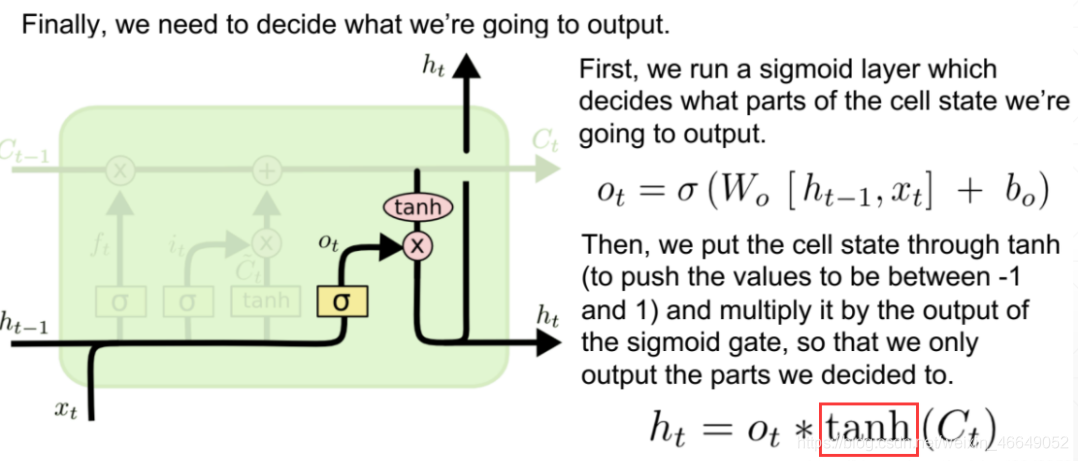
LSTM 在得到當前時刻狀態 Ct 之后,需要產生當前時刻的輸出,該程序通過“輸出門”完成,
LSTM 的內部狀態向量𝒄𝑡并不會直接用于輸出,這一點和基礎的RNN 不一樣,基礎的RNN 網路的狀態向量 既用于記憶,又用于輸出,所以基礎的RNN 可以理解為狀態向量𝒄和輸出向量 是同一個物件,在LSTM 內部,狀態向量并不會全部輸出,而是在輸出門的作用下有選擇地輸出,
LSTM計算公式總結如下:
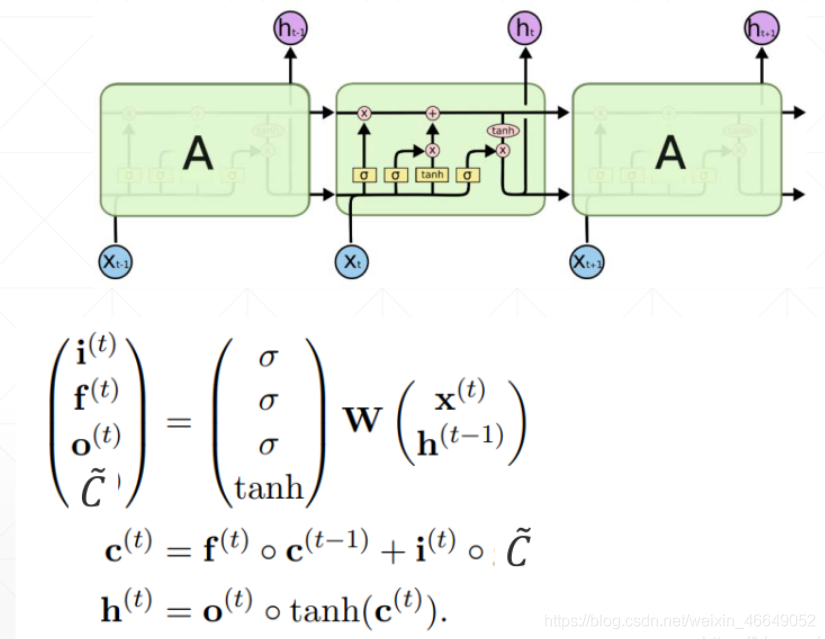
三個門總結:遺忘門控制以前的輸入,輸入門控制當前的輸入,輸出門產生當前時刻的輸出,
直觀比較LSTM與RNN的梯度求導,會發現
RNN中有權重的n次方,易出現梯度彌散與梯度爆炸
而LSTM中是權重的累加,幾個門的相互制約不會出現梯度彌散與梯度爆炸現象
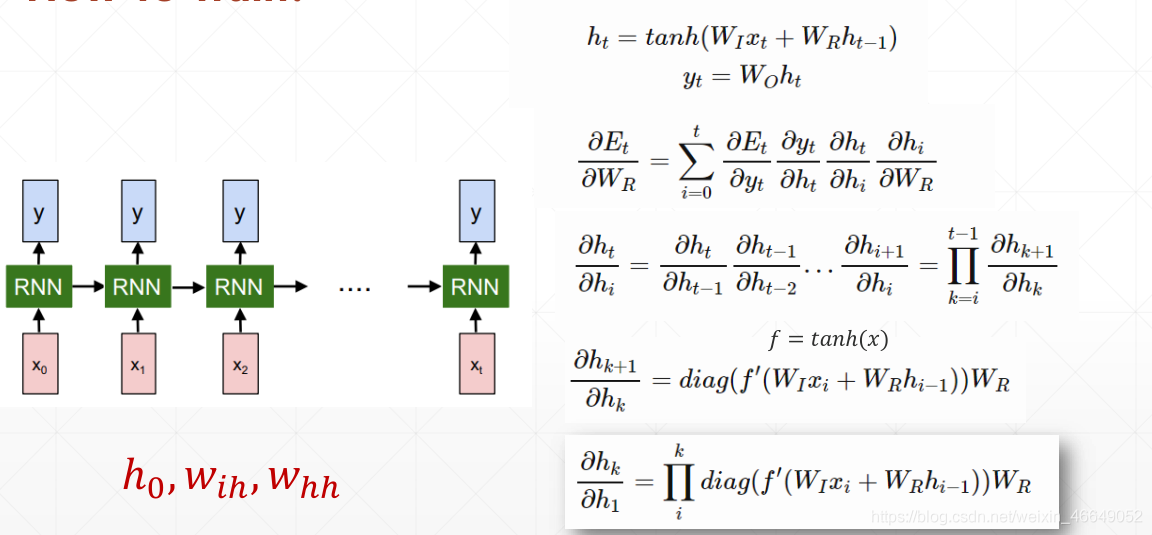
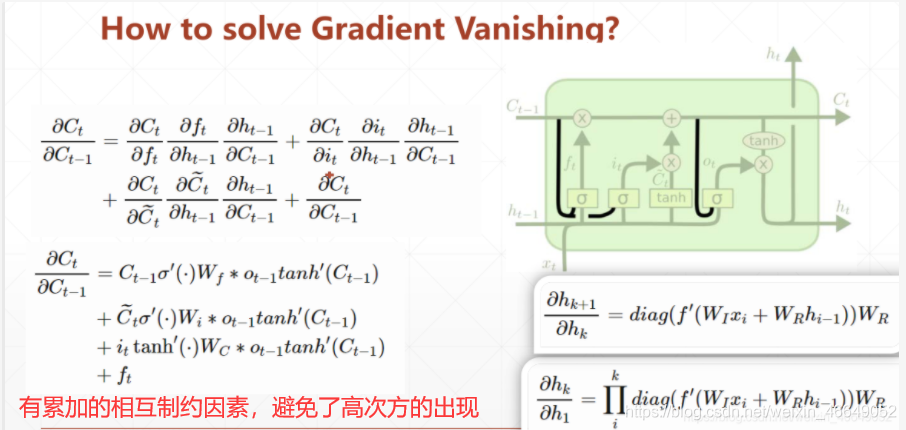
六、Gated Recurrent Unit—GRU
????LSTM 具有更長的記憶能力,在大部分序列任務上面都取得了比基礎的RNN 模型更好的性能表現,更重要的是,LSTM 不容易出現梯度彌散現象,但是LSTM 結構相對較復雜,計算代價較高,模型引數量較大,因此,科學家們嘗試簡化LSTM 內部的計算流程,特別是減少門控數量,研究發現,遺忘門是LSTM 中最重要的門控 ,甚至發現只有遺忘門的簡化版網路在多個基準資料集上面優于標準LSTM 網路,在眾多的簡化版LSTM中,門控回圈網路(Gated Recurrent Unit,簡稱GRU)是應用最廣泛的RNN 變種之一,GRU把內部狀態向量和輸出向量合并,統一為狀態向量 ,門控數量也減少到2 個:復位門(Reset Gate)和更新門(Update Gate),
????GRU 的兩個門:一個是“更新門”(update gate),它將 LSTM 的“遺忘門”和“輸入門”融合成了一個“門”結構;另一個是“重置門”(reset gate),
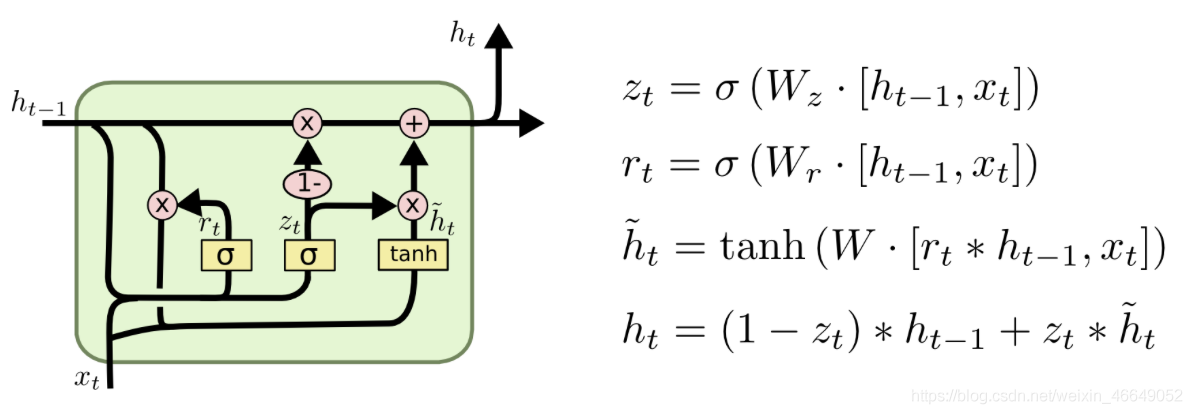
??這兩個門控機制的特殊之處在于,它們能夠保存長期序列中的資訊,且不會隨時間而清除或因為與預測不相關而移除,從直觀上來說,重置門決定了如何將新的輸入資訊與前面的記憶相結合,更新門定義了前面記憶保存到當前時間步的量,如果我們將重置門設定為 1,更新門設定為 0,那么我們將再次獲得標準 RNN 模型,使用門控機制學習長期依賴關系的基本思想和 LSTM 一致,但還是有一些關鍵區別:
- GRU 有兩個門(重置門與更新門),而 LSTM 有三個門(輸入門、遺忘門和輸出門),
- GRU 并不會控制并保留內部記憶 ( c t ) (c_t) (ct?),且沒有 LSTM 中的輸出門,
- LSTM 中的輸入與遺忘門對應于 GRU 的更新門,重置門直接作用于前面的隱藏狀態,
????重置門強制隱藏狀態遺忘一些歷史資訊,并利用當前輸入的資訊,這可以令隱藏狀態遺忘任何在未來發現與預測不相關的資訊,同時也允許構建更加緊致的表征,而更新門將控制前面隱藏狀態的資訊有多少會傳遞到當前隱藏狀態,這與 LSTM 網路中的記憶單元非常相似,它可以幫助 RNN 記住長期資訊,由于每個單元都有獨立的重置門與更新門,每個隱藏單元將學習不同尺度上的依賴關系,那些學習捕捉短期依賴關系的單元將趨向于激活重置門,而那些捕獲長期依賴關系的單元將常常激活更新門,
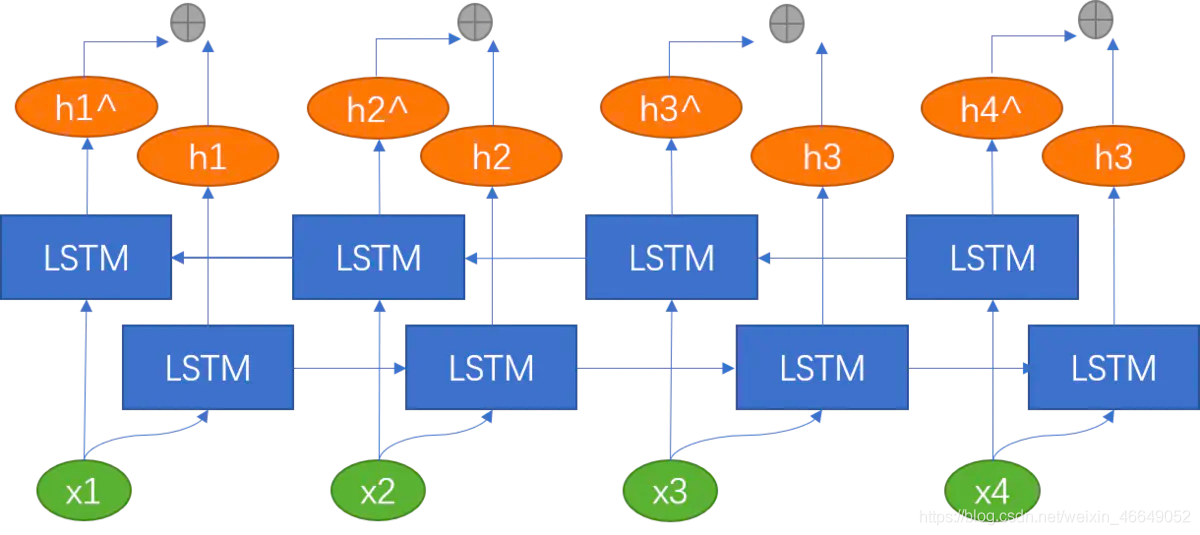
七、BI-LSTM
??諸如在詞性標注下游任務中,我們不僅考慮上文資訊,而且還要考慮下文資訊,此時,就需要雙向LSTM,雙向LSTM可以理解為同時訓練兩個LSTM,兩個LSTM的方向、引數都不同,當前時刻的
h
t
h_t
ht?就是將兩個方向不同的LSTM得到的兩個
h
t
h_t
ht?向量拼接到一起,我們使用雙向LSTM捕捉到當前時刻
t
t
t的過去和未來的特征,通過反向傳播來訓練雙向LSTM網路,
??如果是雙向LSTM+Attention,這里是靜態的Attention,則網路結構如下:
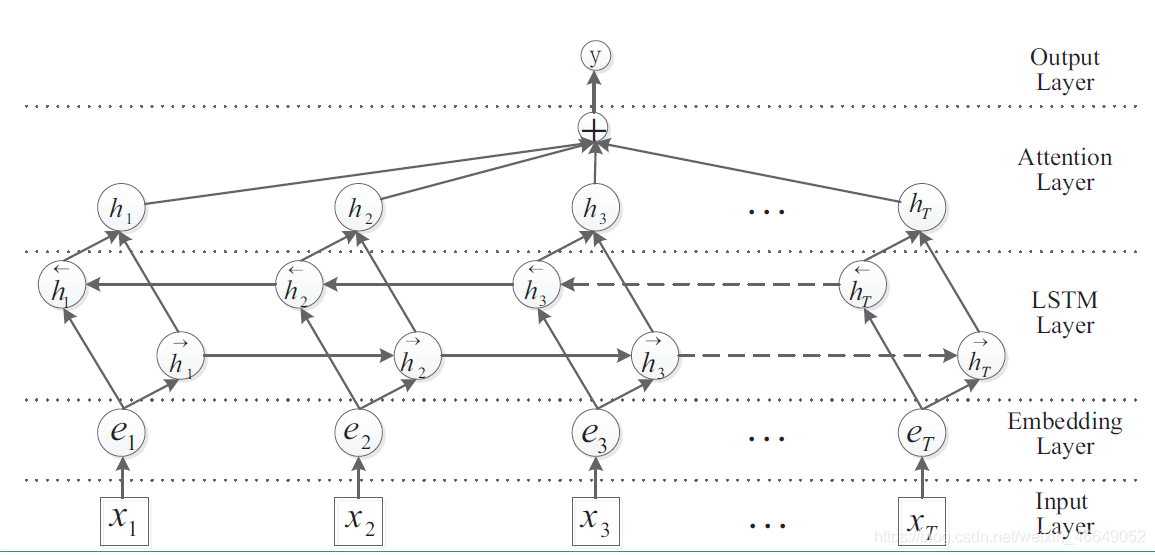 h
t
h_t
ht?是每一個詞的hidden state,而
h
s
 ̄
\overline{h_s}
hs??是向量,開始是隨機生成的,后面經過反向傳播可以得到
?
L
o
s
s
?
h
s
 ̄
\frac{\partial{Loss}}{\partial{\overline{h_s}}}
?hs???Loss?,通過梯度不斷迭代更新,得到標準,
h
t
h_t
ht?是每一個詞的hidden state,而
h
s
 ̄
\overline{h_s}
hs??是向量,開始是隨機生成的,后面經過反向傳播可以得到
?
L
o
s
s
?
h
s
 ̄
\frac{\partial{Loss}}{\partial{\overline{h_s}}}
?hs???Loss?,通過梯度不斷迭代更新,得到標準,
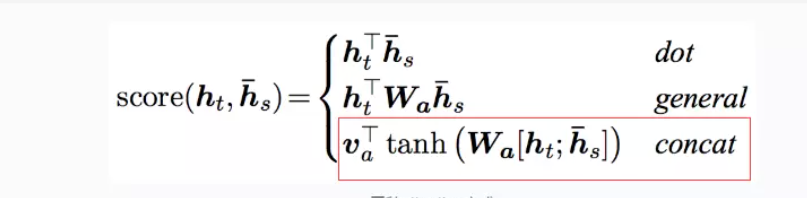
score是標量,每句話進行拼接,然后做softmax得到概率,然后對hidden state進行加權平均,得到總向量,然后經過一個分類層,經softmax得到每一個類別的得分,
1.雙向LSTM的模型代碼實作
import torch
import torch.nn as nn
import torch.nn.functional as F
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, pretrained_weight, update_w2v, hidden_dim,
num_layers, drop_keep_prob, n_class, bidirectional, **kwargs):
super(LSTMModel, self).__init__()
self.hidden_dim = hidden_dim # 隱藏層節點數
self.num_layers = num_layers # 神經元層數
self.n_class = n_class # 類別數
self.bidirectional = bidirectional # 控制是否為雙向LSTM
self.embedding = nn.Embedding.from_pretrained(pretrained_weight) # 讀取預訓練好的引數
self.embedding.weight.requires_grad = update_w2v # 控制加載的預訓練模型在訓練中引數是否更新
# LSTM
self.encoder = nn.LSTM(input_size=embedding_dim, hidden_size=self.hidden_dim,
num_layers=num_layers, bidirectional=self.bidirectional,
dropout=drop_keep_prob)
# 解碼部分
if self.bidirectional:
self.decoder1 = nn.Linear(hidden_dim * 4, hidden_dim)
self.decoder2 = nn.Linear(hidden_dim, n_class)
else:
self.decoder1 = nn.Linear(hidden_dim * 2, hidden_dim)
self.decoder2 = nn.Linear(hidden_dim, n_class)
def forward(self, inputs):
"""
前向傳播
:param inputs: [batch, seq_len]
:return:
"""
# [batch, seq_len] => [batch, seq_len, embed_dim][64,75,50]
embeddings = self.embedding(inputs)
# [batch, seq_len, embed_dim] = >[seq_len, batch, embed_dim]
# 這里要結合batch_first引數的設定
states, hidden = self.encoder(embeddings.permute([1, 0, 2]))
# 張量拼接[32,512]
encoding = torch.cat([states[0], states[-1]], dim=1)
# 解碼
outputs = self.decoder1(encoding)
# outputs = F.softmax(outputs, dim=1)
outputs = self.decoder2(outputs)
return outputs
2.雙向LSTM+Attention的模型代碼實作
import torch
import torch.nn as nn
import torch.nn.functional as F
class LSTM_attention(nn.Module):
def __init__(self, vocab_size, embedding_dim, pretrained_weight, update_w2v, hidden_dim,
num_layers, drop_keep_prob, n_class, bidirectional, **kwargs):
super(LSTM_attention, self).__init__()
self.hidden_dim = hidden_dim # 隱藏層節點數
self.num_layers = num_layers # 神經元層數
self.n_class = n_class # 類別數
self.bidirectional = bidirectional # 控制是否雙向LSTM
self.embedding = nn.Embedding.from_pretrained(pretrained_weight) # 讀取預訓練好的引數
self.embedding.weight.requires_grad = update_w2v # 控制加載的預訓練模型在訓練中引數是否更新
# LSTM
self.encoder = nn.LSTM(input_size=embedding_dim, hidden_size=self.hidden_dim,
num_layers=num_layers, bidirectional=self.bidirectional,
dropout=drop_keep_prob,batch_first=True)
# weiht_w即為公式中的h_s(參考系)
# nn. Parameter的作用是引數是需要梯度的
self.weight_W = nn.Parameter(torch.Tensor(2 * hidden_dim, 2 * hidden_dim))
self.weight_proj = nn.Parameter(torch.Tensor(2 * hidden_dim, 1))
# 對weight_W、weight_proj進行初始化
nn.init.uniform_(self.weight_W, -0.1, 0.1)
nn.init.uniform_(self.weight_proj, -0.1, 0.1)
if self.bidirectional:
# self.decoder1 = nn.Linear(hidden_dim * 2, n_class)
self.decoder1 = nn.Linear(hidden_dim * 2, hidden_dim)
self.decoder2 = nn.Linear(hidden_dim, n_class)
else:
self.decoder1 = nn.Linear(hidden_dim * 2, hidden_dim)
self.decoder2 = nn.Linear(hidden_dim, n_class)
def forward(self, inputs):
"""
前向傳播
:param inputs: [batch, seq_len]
:return:
"""
# 編碼
embeddings = self.embedding(inputs) # [batch, seq_len] => [batch, seq_len, embed_dim][64,75,50]
# 經過LSTM得到輸出,state是一個輸出序列
states, hidden = self.encoder(embeddings.permute([0, 1, 2])) # [batch, seq_len, embed_dim]
# attention
# states與self.weight_W矩陣相乘,然后做tanh
u = torch.tanh(torch.matmul(states, self.weight_W))
# u與self.weight_proj矩陣相乘,得到score
att = torch.matmul(u, self.weight_proj)
# softmax
att_score = F.softmax(att, dim=1)
# 加權求和
scored_x = states * att_score
encoding = torch.sum(scored_x, dim=1)
# 線性層
outputs = self.decoder1(encoding)
outputs = self.decoder2(outputs)
return outputs
其中代碼實作中的score與上述公式略有不同:
s
c
o
r
e
(
h
t
,
h
s
 ̄
)
=
w
p
r
o
j
T
t
a
n
h
(
h
t
T
h
s
 ̄
)
score(h_t,\overline{h_s})=w_{proj}^Ttanh(h_t^T\overline{h_s})
score(ht?,hs??)=wprojT?tanh(htT?hs??)
八、Deep-BILSTM
?? Deep-BILSTM可以理解為同時訓練兩個深度的LSTM,然后將兩個深度的LSTM拼接到一起,在詞性標注領域、命名物體識別領域用的較多,
如果對您有幫助,麻煩點贊關注,這真的對我很重要!!!如果需要互關,請評論或者私信!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295321.html
標籤:AI