RabbitMQ 如何保證訊息不丟失?
RabbitMQ一般情況很少丟失,但是不能排除意外,為了保證我們自己系統高可用,我們必須作出更好完善措施,保證系統的穩定性,
-
訊息持久化
-
ACK確認機制
-
設定集群鏡像模式
-
訊息補償機制
-
訊息入庫:顧名思義就是將要發送的訊息保存到資料庫中,
-
事務訊息機制:由于會嚴重降低性能,所以一般不采用這種方法
-
confirm訊息確認機制
訊息丟失是系統常見的故障,還建議這幾方面
-
監控 ,監控系統對訊息發送情況監控
-
核對 ,有核對系統對每筆資料核對有例外就報警(通過郵件、短信、微信 等等)
-
值班,每天值班 互聯網公司都有默認的值班制度
在推薦一篇文章比較詳細 https://blog.csdn.net/hsz2568952354/article/details/86559470
redis的場景資料型別和應用場景
1. String: 一般做一些復雜的計數功能的快取
2. List: 做簡單的訊息佇列的功能
3. Hash: 單點登錄
4. Set: 做全域去重的功能
5. SortedSet: 做排行榜應用,取TopN操作;延時任務;做范圍查找
應用場景
String型別是最基礎的一種key-value存盤形式,value其實不僅僅可以是String,也可以是數值型別,常常用來做計數器這類自增自減的功能,可用在B站或頭條上 粉絲數、關注數、點贊等,
也可以用在分布式session 用戶的登錄資訊快取在redis中
key:value
key加密過的簽名
value就是對應用戶資訊json格式存盤
一般專案訂單記錄就是放到redist里list中,需要支持分頁查詢,減少對mysql的查詢壓力
Java的模板設計模式
定義:一個操作演算法中的框架,而將這些步驟延遲加載到子類中,
本質就是固定演算法框架
解決問題:讓父類控制子類方法的呼叫順序,有種逆向思維
模板方法模式使得子類可以不改變一個演算法的結構即可重定義該演算法的某些特定步驟,
1)模板模式(Template Pattern),在一個抽象類定義類執行它的方法的模版,它的子類可以按需要重寫方法實作,但呼叫將以抽象類中定義的方式進行,
2)簡單來說,模板方法模式定義一個操作中的演算法的骨架,而將一些步驟延遲到子類中,使得子類可以不改變一個演算法的結構,就可以重定義該演算法的某些特定步驟
3)這種型別的設計模式屬于行為型模式,
模板類+鉤子介面+匿名內部類 (記住這3個模板核心你就懂了)
maven依賴包有沖突怎么解決
Maven沖突簡而言之就是需要的Maven版本和實際匯入的版本不一致,從而導致了各種問題,
列印依賴樹
mvn dependency:tree > tree.txt
使用Maven helper 查看依賴沖突 (插件都牛逼)
使用exclusion排除依賴 (這個單詞很重要)
推薦一個Idea的插件,Maven Helper,
-
提供可視化的Maven樹狀視圖,
-
可以一鍵搜索所有包含該包的父包,
-
右鍵直接排出
分布式缺點
1、架構設計變得復雜,事務不好處理(分布式事務)
2、部署服務復雜話,啟動需要很久
3、系統的吞吐量會變大,但是回應時間會變長
5、架構復雜導致學習曲線變大
6、測驗和查錯的復雜度大,因為鏈路太長環境太多,需要花時間定位具體在什么服務上在物理在什么機器上
8、最麻煩的是訊息不知道落地哪臺機器上了,大公司有分布式日志框架來解決這個問題TraceID
訊息佇列-如何保證訊息的順序性?
RabbitMQ:拆分多個queue,每個queue一個consumer,就是多一些queue而已,確實是麻煩,或者就是一個queue,但是對應一個consumer,然后這個consumer內部用記憶體佇列做排隊,然后分發給底層不同的worker來處理,
下圖為:一個consumer 對應 一個 queue,這樣就保證了訊息消費的順序性,
訊息佇列的優缺點
優點:異步、解耦、削峰
缺點:1)系統可用性降低
外部依賴的系統多了,增加了訊息佇列系統,
2)系統復雜度提高
怎么保證訊息沒有重復消費?怎么處理訊息丟失的情況?怎么保證訊息傳遞的順序性?
3)一致性問題
資料可能不一致,
如何保證訊息佇列的高可用?
鏡像集群模式
鏡像集群模式是RabbitMQ的高可用模式,和普通的集群模式不一樣的是,你創建的queue無論元資料還是queue里的訊息都會存在與多個實體中,然后每次你寫訊息到queu的時候,都會自動把訊息推送到多個實體的queue中進行訊息同步,
這樣的好處在于,你任何一個機器宕機了,別的機器都可以用,壞處在于,性能開銷提升,訊息同步所有的機器,導致網路帶寬壓力和消耗增加,第二就是沒有什么擴展性科研,如果某個queue負載很重,你加機器,新增的機器也包含了這個queue的所有資料,并沒有辦法線性擴展你的queue
如何保證訊息不被重復消費?如何保證訊息消費的冪等性?
讓每個訊息攜帶一個全域的唯一ID,即可保證訊息的冪等性,具體消費程序為:
1、消費者獲取到訊息后先根據id去查詢redis/db是否存在該訊息
2、如果不存在,則正常消費,消費完畢后寫入redis/db
3、如果存在,則證明訊息被消費過,直接丟棄,
如何保證訊息不丟失(可靠性傳輸)
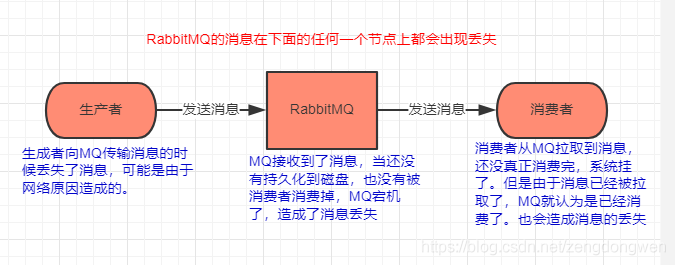
生產者沒有成功把訊息發送到MQ
a、丟失的原因:因為網路傳輸的不穩定性,當生產者在向MQ發送訊息的程序中,MQ沒有成功接收到訊息,但是生產者卻以為MQ成功接收到了訊息,不會再次重復發送該訊息,從而導致訊息的丟失,
b、解決辦法: 有兩個解決辦法:事務機制和confirm機制,最常用的是confirm機制,
具體解決辦法
RabbitMQ接收到訊息之后丟失了訊息
a、丟失的原因:RabbitMQ接收到生產者發送過來的訊息,是存在記憶體中的,如果沒有被消費完,此時RabbitMQ宕機了,那么再次啟動的時候,原來記憶體中的那些訊息都丟失了,
b、解決辦法:開啟RabbitMQ的持久化,當生產者把訊息成功寫入RabbitMQ之后,RabbitMQ就把訊息持久化到磁盤,結合上面的說到的confirm機制,只有當訊息成功持久化磁盤之后,才會回呼生產者的介面回傳ack訊息,否則都算失敗,生產者會重新發送,存入磁盤的訊息不會丟失,就算RabbitMQ掛掉了,重啟之后,他會讀取磁盤中的訊息,不會導致訊息的丟失,
c、持久化的配置:
第一點是創建 queue 的時候將其設定為持久化,這樣就可以保證 RabbitMQ 持久化 queue 的元資料,但是它是不會持久化 queue 里的資料的,
第二個是發送訊息的時候將訊息的 deliveryMode 設定為 2,就是將訊息設定為持久化的,此時 RabbitMQ 就會將訊息持久化到磁盤上去,
消費者弄丟了訊息
a、丟失的原因:如果RabbitMQ成功的把訊息發送給了消費者,那么RabbitMQ的ack機制會自動的回傳成功,表明發送訊息成功,下次就不會發送這個訊息,但如果就在此時,消費者還沒處理完該訊息,然后宕機了,那么這個訊息就丟失了,
b、解決的辦法:簡單來說,就是必須關閉 RabbitMQ 的自動 ack,可以通過一個 api 來呼叫就行,然后每次在自己代碼里確保處理完的時候,再在程式里 ack 一把,這樣的話,如果你還沒處理完,不就沒有 ack了?那 RabbitMQ 就認為你還沒處理完,這個時候 RabbitMQ 會把這個消費分配給別的 consumer 去處理,訊息是不會丟的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295352.html
標籤:其他
上一篇:Hadoop完全分布式集群搭建