作者:張海立,馭勢科技云平臺研發總監
行業背景
馭勢科技(UISEE)是國內領先的自動駕駛公司,致力于為全行業、全場景提供 AI 駕駛服務,交付賦能出行和物流新生態的 AI 駕駛員,由于需要保障各個場景下 “真 · 無人”(即無安全員在車上或跟車)的業務運作,我們比較注重在 “云端大腦” 上做了一些保障其高可用和可觀察性方面的實踐,
讓我們假設有這樣一個場景:在一個廠區運行了幾十臺的無人物流拖車,考慮到 “真無人” 環境下的安全運營,我們會采取車云連接長時間斷開(一般為秒級)即停車的策略;如果在運營的程序中,云端出現故障且缺乏高可用能力,這將造成所有車輛停運,顯然這對業務運營會造成巨大影響,因此云平臺的穩定性和高可用性是非常重要和關鍵的,
為什么選擇 KubeSphere

我們和 KubeSphere 的結緣可以說是 “始于顏值,陷于才華”,早在 KubeSphere 2.0 發布之時,我們因緣際會在社區的新聞中留意到這個產品,并馬上被它 “小清新” 的界面所吸引,于是,從 2.0 開始我們便開始在私有云上進行小范圍試用,并在 2.1 發布之后開始投入到我們公有云環境的管理中使用,
KubeSphere 3.0 是一個非常重要的里程碑發布,它帶來了 Kubernetes 多集群管理的能力、進一步增強了在監控和告警方面的能力,并在 3.1 中持續對這些能力進行夯實,由此,我們也開始更大范圍地將 KubeSphere 應用到我們自有的和客戶托管的集群(及在其中運行的作業負載)的管理上,同時我們也在進一步探索如何將現有的 DevOps 環境和 KubeSphere 做整合,最終的目標還是希望將 KubeSphere 打造成我們內部面向云原生各應用、服務、平臺的統一入口和集中管理的核心,
正是由于 KubeSphere 提供了這樣優秀的管控能力,使得我們有了更多時間從業務角度去提升云平臺的可用性,這次分享的兩個內容就是我們早期和現在正在推進的兩項可用性相關的實踐,
“高可用”實踐:提供熱備能力的 Operator
“高可用” 方面,我們期望解決的問題是如何確保云端服務出現故障時可以用最快的速度重新恢復到穩定運行的狀態,
限定區域 L4 無人駕駛場景的 “高可用” 訴求

“高可用” 從時間量化的角度通常就是幾個 9 級別選擇,但落到具體的業務場景,所面臨的問題和挑戰卻是各不相同的,如上圖所列舉的,對于我們 “限定區域 L4 無人駕駛場景” 而言,以 toB 業務為主所造成的客戶私有云種類繁多、對于恢復程序容忍度不同、以及客戶定制服務產生的歷史包袱較多是制約我們構建高可用方案的幾個主要問題,面對這些限制,我們選擇了一個比較 “簡單粗暴” 的思路,試圖 “化繁為簡” 跳出跨云高可用成本高、為服務附加高可用能力融合風險高的常見問題包圍圈,
一種通過 Operator 實熱備切換的高可用方法
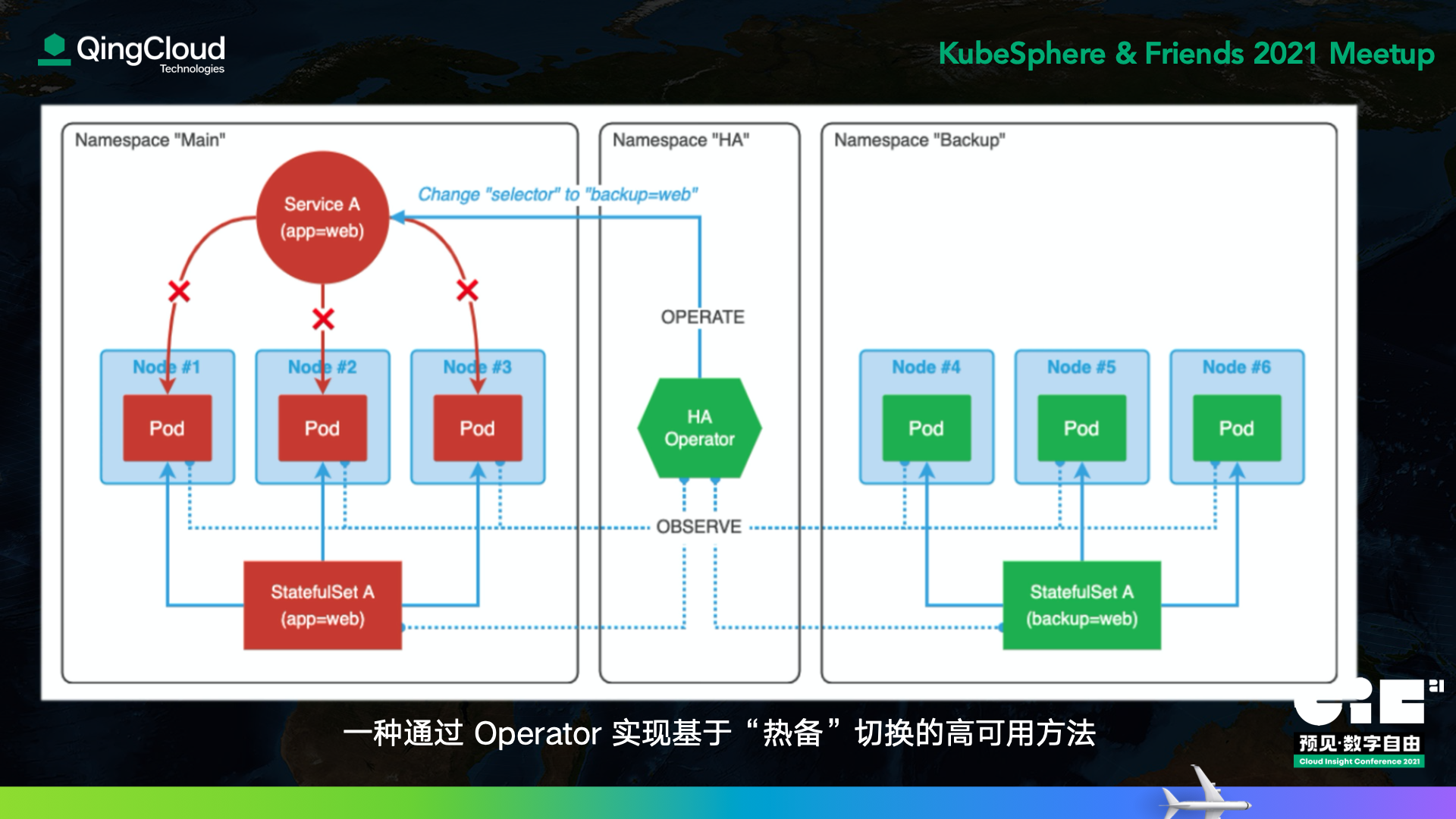
如上圖所示,這個方案的思路很直接 —— 實作服務 Pod 狀態監測并在狀態例外時進行主備 Pod 切換,如果我們從 Controller 的 “Observe - Analyze - Act” 體系來看,它做了如下作業:
- 監測:同時能夠監測 Pod / Deployment / StatefulSet / Service 的變化(包括能夠監控特定的 Namespace);監測到有變化則觸發 Reconcile 調協程序(即以下兩個操作)
- 判斷:遍歷所有 Service,獲取 Deployment / StatefulSet,將其
status中的服務的總數量與可用數量進行比較;如果有副本不可用,則再遍歷 dp/sts 里面的 Pod,通過容器的狀態及重啟次數來找到不健康的 Pod,當一個 dp/sts 下所有的 Pod 都不健康,則認為這個服務整體不健康 - 切換:同一個服務部署主備兩套 dp/sts,在當前服務的 dp/sts 指向的 Pod 全都不健康時(即整個服務不健康),若另一套 dp/sts 健康,切換至另一套 dp/sts

在這個 Operator 的開發框架上,我們選用了 Kubernetes 官方社區的 Operator SDK,即 Kubebuilder,從技術上看,它對于撰寫 Controller 通常需要的核心組件 client-go 有比較好的封裝,可以幫助開發者更專注于業務邏輯的開發;從社區的支持角度看,發展也比較平穩,這里也向大家推薦在使用中可以參考云原生社區組織翻譯的 Kubebuilder 中文檔案,
行百里者半九十:高可用功能落地的長尾在于測驗

由于 “高可用” 功能的特殊性,它的測驗尤其重要,但常規的測驗手段可能并不是很適用(這里存在一個有意思的 “悖論”:測驗是為了發現問題,而高可用的啟用會避免發生問題),所以我們在完成這個 Operator 的開發后,其實更多的時間是花在測驗方面,在這里我們主要實施了三個方面的測驗作業:
- 端到端的 BDD 測驗:這塊作為基礎功能驗證和測驗,我們使用了支持 Cucumber BDD 測驗框架的 Godog 專案(支持 Cucmber Gherkin 語法),BDD 也適合業務方直接匯入需求
- 針對運行環境的混沌測驗:這塊我們使用 ChaosBlade 對 Kubernetes 物理節點的系統運行環境進行相關混沌測驗,以檢驗出現基建故障時的高可用表現
- 針對業務層面的混沌測驗:這里我們使用 Chaos Mesh 對主備服務進行 Pod 級別的測驗,使用 Chaos Mesh 一方面是由于它在這個層面功能覆寫比較全面,另一方面也是因為它的 Dashboard 便于管理測驗所用到的各項測驗用例
簡單總結一下,在這個 “高可用” 方面的早期實踐程序中,我們有幾點體會:首先,還是需要熟悉 Kubernetes Controller 以及 client-go 類別庫的核心機制;其次,找一個趁手的 Operator 開發框架會大大提升你的研發效率;最后但也是最重要的一點,高可用這塊的研發作業其實是由 “20% 時間的開發 + 80% 的全方位測驗” 組成的,做好測驗、做好全面測驗非常非常重要,
“可觀察”實踐:車云端到端 SkyWalking 接入
“可觀察” 方面,我們期望解決的問題是在服務故障恢復后,如何確保我們能夠盡可能快的定位到問題的根源,以便盡早真正消除問題隱患,
無人駕駛車云一體化架構下的 “可觀察” 訴求

“車云一體化” 架構是無人駕駛的一個重要核心,從云端視角來看,它的一個巨大挑戰就是業務鏈路非常長,遠長于傳統的互聯網純云端的業務鏈路,這個超長鏈路上任意一點的問題都有可能引發故障,輕則告警、重則導致車輛例外離線,所以對于鏈路上的點點滴滴、各式各樣的資訊我們總是希望能夠應收盡收,以便于定位問題,同時,純粹的日志類資料也是不夠的,因為鏈路太長且又分布在車云的不同地方,單靠日志不便于快速定位問題發生的區間從而進行有針對性的問題挖掘,
為了便于大家更具象的了解鏈路之長,下圖我們給出了一個抽象的 “車云一體化” 架構圖,感興趣的朋友可以數一下這 “7 x 2” 的呼叫鏈路,
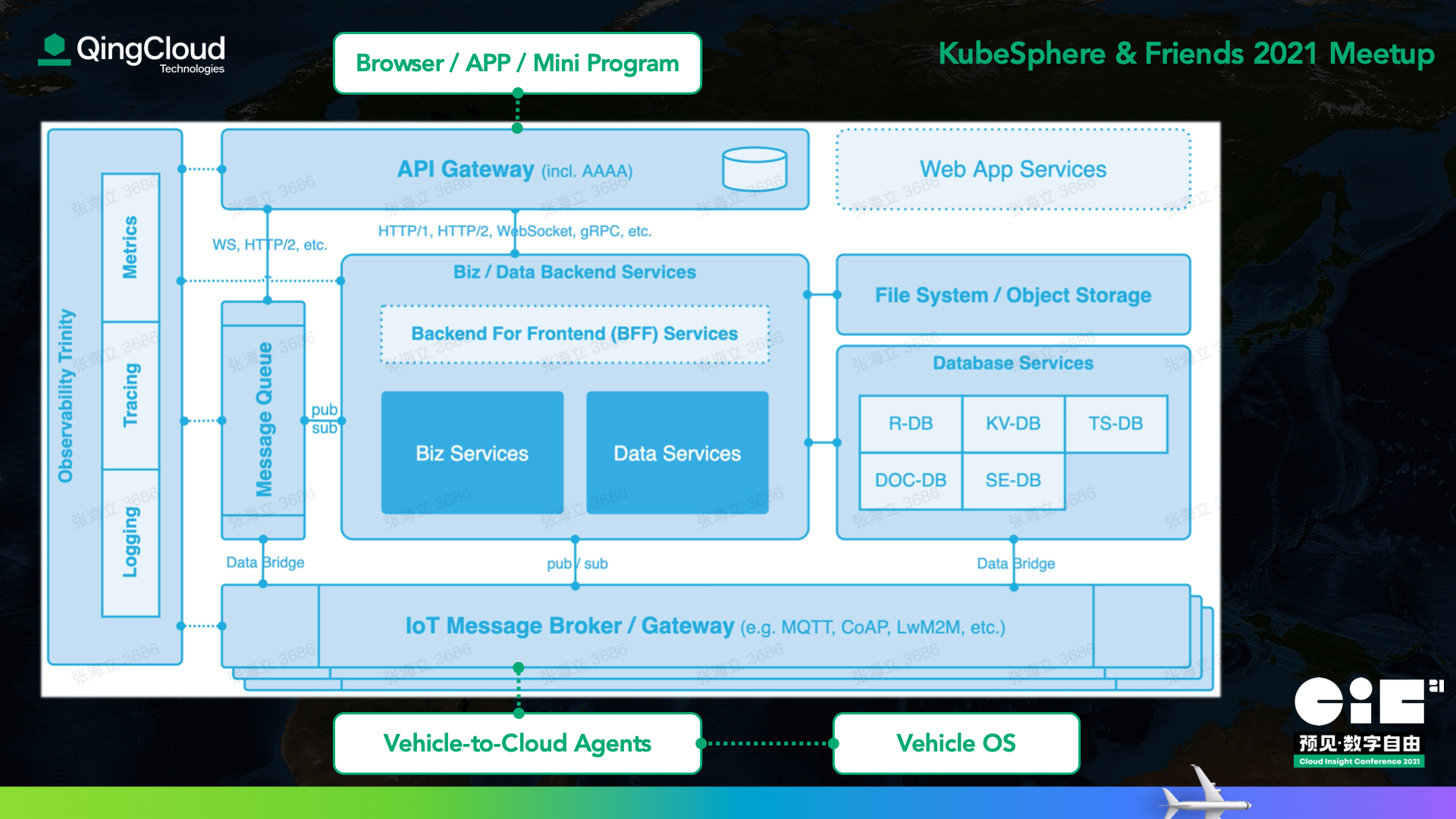
通過 SkyWalking 實作車云全鏈路追蹤
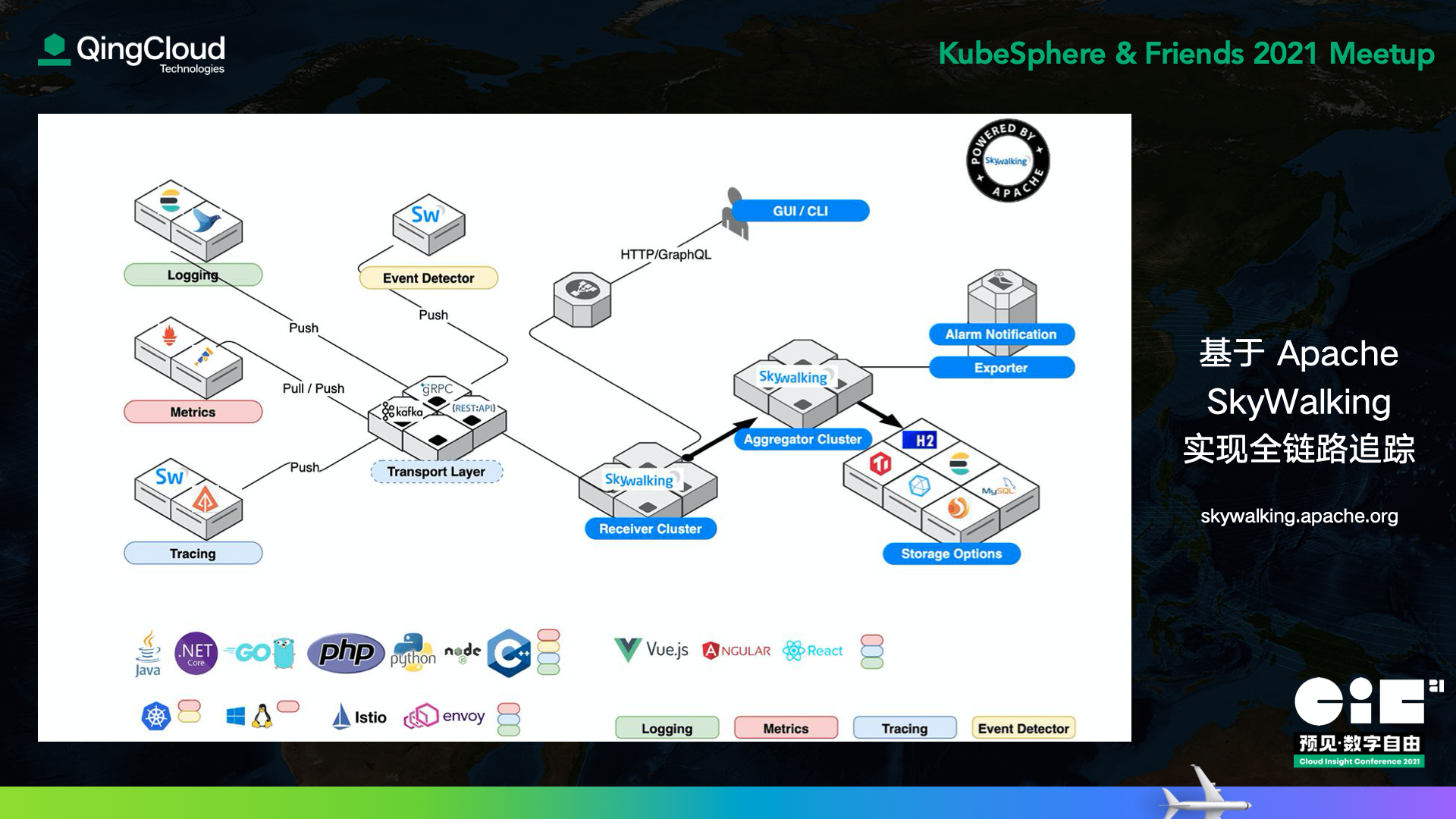
Apache SkyWalking 是社區中一個優秀而且活躍的可觀察性平臺專案,它同時提供了 Logging、Metrics、Tracing 可觀察性三元組的功能,其中尤以追蹤能力最為扎實,關于追蹤系統的一些基本概念推薦可以參看吳晟老師翻譯的 OpenTracing 概念和術語,為了方便大家對后續內容有更好的把握,也彌補一下演講時無法展開的細節,這邊也簡單整理幾個關鍵點供大家參考:
- Trace:一個 Trace 代表一個潛在的,分布式的,存在并行資料或并行執行軌跡(潛在的分布式、并行)的系統,一個 Trace 可以認為是多個 Span 的有向無環圖(DAG),
- Span:在服務中埋點時,最需要關注的內容,一個 Span 代表系統中具有開始時間和執行時長的邏輯運行單元,Span 之間通過嵌套或者順序排列建立邏輯因果關系,在 SkyWalking 中,Span 被區分為:
- LocalSpan:服務內部呼叫方法時創建的 Span 型別
- EntrySpan:請求進入服務時會創建的 Span 型別(例如處理其他服務對于本服務介面的呼叫)
- ExitSpan:請求離開服務時會創建的 Span 型別(例如呼叫其他服務的介面)
- SkyWalking 中,創建一個 ExitSpan 就相當于創建了一個 Parent Span,以 HTTP 請求為例,此時需要將 ExitSpan 的背景關系編碼后,放到請求的 Header 中;在另一個服務接收到請求后,需要創建一個 EntrySpan,并從 Header 中解碼背景關系資訊,以決議出它的 Parent 是什么,通過這樣的方式,ExitSpan 和 EntrySpan 就可以串聯在一起,
- SkyWalking 中未對 ChildOf 和 FollowsFrom 兩種型別的 Span 作區分
- TraceSegment:SkyWalking 中的概念,介于 Trace 和 Span 之間,是一條 Trace 的一段,可以包含多個 Span,一個 TraceSegment 記錄了一個執行緒中的執行程序,一個 Trace 由一個或多個 TraceSegment 組成,一個 TraceSegment 又由一個或多個 Span 組成,
- SpanContext:代表跨越行程背景關系,傳遞到下級 Span 的狀態,在 Go 中,通過
context.Context在同一個服務中進行傳遞, - Baggage:存盤在 SpanContext 中的一個鍵值對集合,它會在一條追蹤鏈路上的所有 Span 內全域傳輸,包含這些 Span 對應的 SpanContext,Baggage 會隨著 Trace 一同傳播,
- SkyWalking 中,背景關系資料通過名為
sw8的頭部項進行傳遞,值中包含 8 個欄位,由-進行分割(包括 Trace ID,Parent Span ID 等等) - 另外 SkyWalking 中還提供名為
sw8-correlation的擴展頭部項,可以傳遞一些自定義的資訊
- SkyWalking 中,背景關系資料通過名為
- 與 Jaeger / Zipkin 相比,雖然都是對 OpenTracing 的實作,但是 ExitSpan、EntrySpan 的概念是在 SkyWalking 中獨有的,使用下來體驗較好的點在于:
- 使用語意化的 ExitSpan 和 EntrySpan,使代碼邏輯更為清晰
- 希望邏輯清晰的原因是,有時候創建 Span 確實容易出錯,尤其是在對服務鏈路不熟悉的情況下,所以進行埋點時,對 OpenTracing 的理解是基礎,也需要了解服務的鏈路,
SkyWalking 的插件體系是保障我們得以在一個龐大的微服務架構中進行埋點的基礎,官方為 Java、Python、Go、 Node.js 等語言都提供了插件,對 HTTP 框架、SQL、NoSQL、MQ、RPC 等都有插件支持(Java 的插件最為豐富,有 50+,其他語言的插件可能沒有這么全面 ),我們基于 Go 和 Python 官方插件的研發思路,又進一步擴展和自制了一些插件,例如:
- Go · GORM:GORM 支持為資料庫操作注冊插件,只需在插件中創建 ExitSpan
- Go · gRPC:利用 gRPC 攔截器,在 metadata(類似 HTTP 的 Header) 中寫入背景關系
- Go · MQTT:沒有找到可以使用的中間件,所以直接寫了函式,在發布和收到訊息時手動呼叫
- Python · MQTT:在 Payload 中寫入 Carrier(可參考 OpenTracing 中 Baggage 的概念,攜帶包含 Trace 背景關系資訊的鍵值對) 中的背景關系資料
- Python · Socket:由于比較底層,按照官方做法自定義 Socket 插件后,HTTP 請求、MQTT 收發訊息都會被記錄,輸出資訊過多;所以又自定義了兩個函式結合業務手動呼叫
前途是光明的,道路是曲折的 —— 記一些我們踩過的坑
由于微服務架構中涉及的語言環境、中間件種類以及業務訴求通常都比較豐富,這導致在接入全鏈路追蹤的程序中難免遇到各種主觀和客觀的坑,這里給大家介紹幾個常見場景,
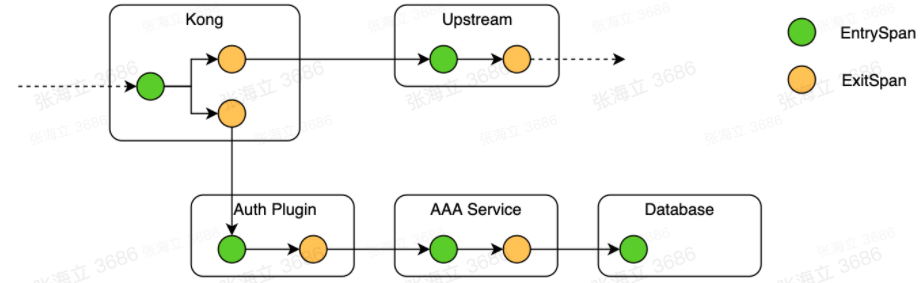
案例一:Kong 網關的插件鏈路接入問題
找不到官方插件是最常見的一種接入問題,比如我們在接入 SkyWalking 時,官方還未發布 SkyWalking 的 Kong 插件(5 月才發布),我們因為業務需要在
Kong 中接入了自定義的一個權限插件,用于對 API 和資源的授權;這個插件會呼叫權限服務的介面進行授權,那么這個插件中的呼叫,也應屬于呼叫鏈中的一環
,所以我們的解決思路是直接在權限插件中進行了埋點,具體形成的鏈路如下圖所示,
案例二:跨執行緒/跨行程的鏈路接入問題
對于跨執行緒,這里給大家一個提示:可以使用函式 capture() 以及 continued();使用 Snapshot,為 Context 背景關系創建快照,
對于跨行程,我們遇到一個比較坑的坑是 Python 版本問題:Python 服務中新起一個行程后,原先行程的 SkyWalking Agent 在新行程中無法被使用;需要重新啟動一個 Agent 才能正常使用,實踐后發現 Python 3.9 可行,Python 3.5 中則會報錯 “agent can only be started once”(找誰說理去,,,)
案例三:官方 Python Redis 插件 Pub/Sub 斷路問題
這個案例是一個典型的官方插件不能覆寫現實業務場景的問題,官方提供的 Python 庫中,有提供 Redis 插件;一開始我們認為安裝了 Redis 插件,對于一切 Redis 操作,都能互相連接;但是實際上,對于 Pub/Sub 操作,鏈路是會斷開的,
查看代碼后發現,對于所有的 Redis 操作,插件都創建一個 ExitSpan,但是在我們的場景中,需要進行 Pub/Sub 操作;這導致兩個操作都會創建 ExitSpan,而使鏈路無法相連,對于這種情況,最后我們通過改造了一下插件來解決問題,大家如果遇到類似情況也需要注意官方插件的功能定位,
案例四:MQTT Broker 的多種 Data Bridge 接入問題
一般來說,對 MQTT Broker 的追蹤鏈路是 Publisher => Subscriber;但是也存在場景,MQTT Broker 接收到訊息后,通過規則引擎呼叫通知中心的介面;而規則引擎呼叫介面時,沒有辦法把 Trace 資訊放到 Header 中,
這是一個典型的中間件高級能力未被插件覆寫的問題,通常這種情況還是得就坡下驢,按實際情況做定制,比如這個案例中我們通過約定好引數名稱,放到請求體中,在通知中心收到請求后,從請求體中抽取鏈路的 Context 的方式最終實作了下圖的鏈路貫通,
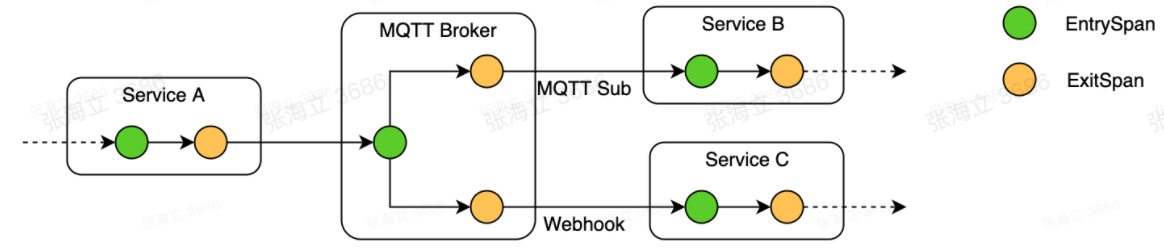
最后也總結一下我們在 “可觀察” 這部分的一些實踐體會:首先,還是需要依托一個成熟的持續演進的工具/平臺
;其次,就是依靠它,同時也要和它一起不斷成長、不斷自我完善;最后,
斷路不可怕,偉人說過 “星星之火,可以燎原”,明確目標、堅持努力,一定有機會解決問題的,
最后的最后,再次感謝 KubeSphere 團隊為中國乃至全球的開源社區貢獻了這么一個卓越的云原生產品,我們也希望能盡自己所能多參與社區建設,與 KubeSphere 社區共成長!

本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/300912.html
標籤:其他
上一篇:Qunar 云原生容器化落地實踐