導讀 :人工智能是計算機科學的一個分支,它企圖了解智能的實質,并生產出一種新的能以人類智能相似的方式做出反應的智能機器,
整理了一份關于python基礎,影像處理opencv\自然語言處理、機器學習、數學基礎等資源庫,想學習人工智能或者轉行到高薪資行業的,大學生都非常實用,無任何套路免費提供,,加我裙966367816 也可以領取的內部資源,人工智能題庫,大廠面試題 學習大綱 自學課程大綱還有200GAI資料大禮包免費送哦~
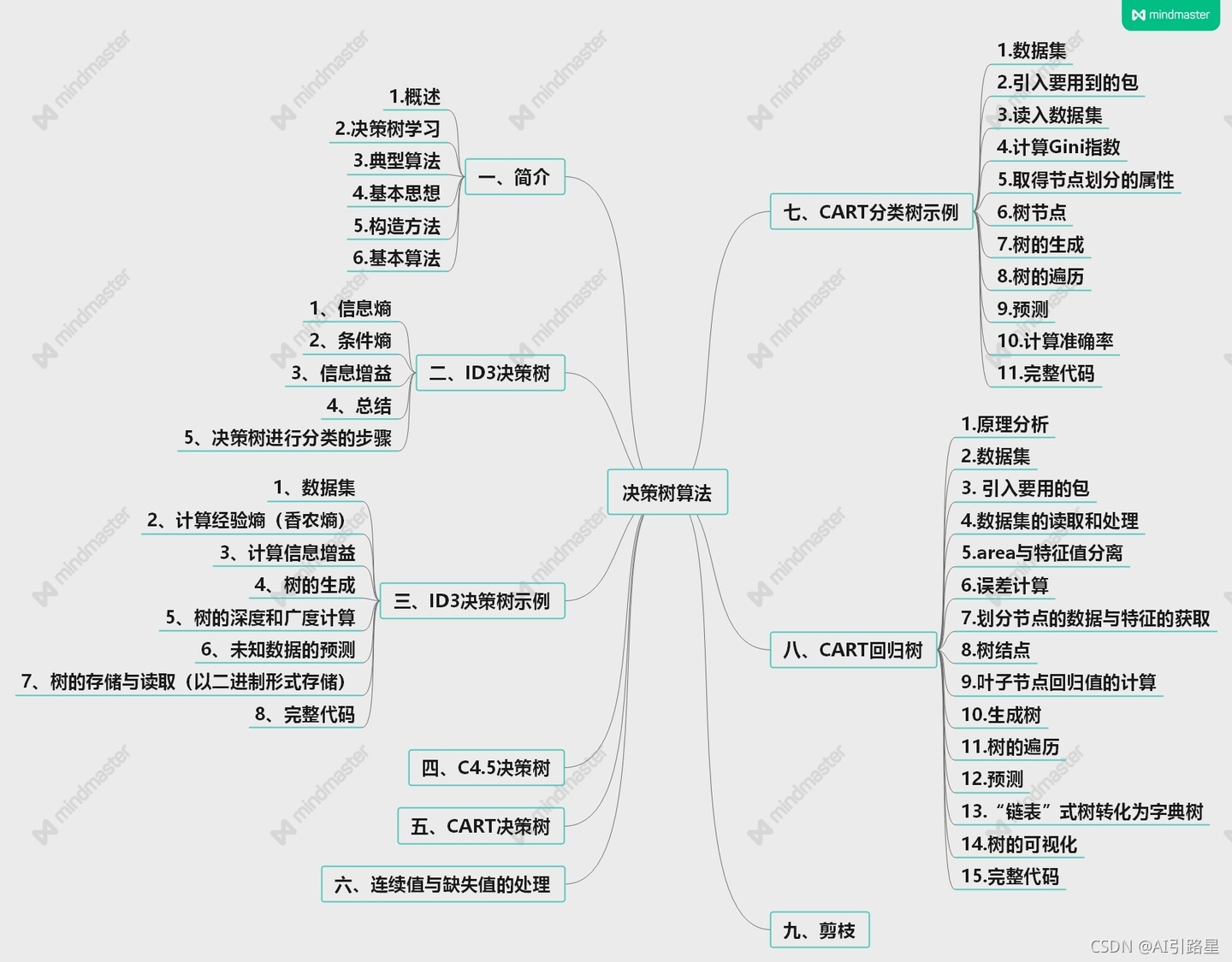
1、決策樹
根據一些feature(特征)進行分類,每個節點提一個問題,通過判斷,將資料分為兩類,再繼續提問,這些問題是根據已有資料學習出來的,再投入新資料的時候,就可以根據這棵樹上的問題,將資料劃分到合適的葉子上,
2、隨機森林
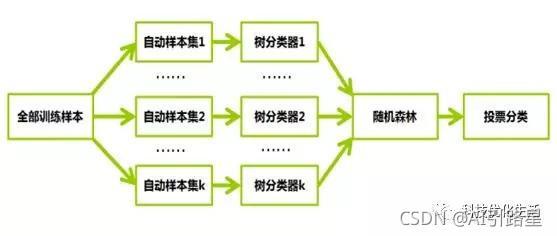
隨機森林是集成學習的一個子類,它依靠于決策樹的投票選擇來決定最后的分類結果,集成學習通過建立幾個模型組合的來解決單一預測問題,集成學習的簡單原理是生成多個分類器/模型,各自獨立地學習和作出預測,這些預測最后結合成單預測,因此優于任何一個單分類的做出預測,
隨機森林的構建程序:
假設N表示訓練用例(樣本)個數,M表示特征數目,隨機森林的構建程序如下:
- 輸入特征數目m,用于確定決策樹上一個節點的決策結果;其中m應遠小于M,
- 從N個訓練用例(樣本)中以有放回抽樣的方式,取樣N次,形成一個訓練集,并用未抽到的用例(樣本)作預測,評估其誤差,
- 對于每一個節點,隨機選擇m個特征,決策樹上每個節點的決定都是基于這些特征確定的,根據m個特征,計算其最佳的分裂方式,
- 每棵樹都會完整成長而不會剪枝,這有可能在建完一棵正常樹狀分類器后會被采用,
- 重復上述步驟,構建另外一棵棵決策樹,直到達到預定數目的一群決策樹為止,即構建好了隨機森林,其中,預選變數個數(m)和隨機森林中樹的個數是重要引數,對系統的調優非常關鍵,這些引數在調節隨機森林模型的準確性方面也起著至關重要的作用,科學地使用這些指標,將能顯著的提高隨機森林模型作業效率,
3、 邏輯回歸
基本上,邏輯回歸模型是監督分類算法族的成員之一, Logistic 回歸通過使用邏輯函式估計概率來測量因變數和自變數之間的關系,
邏輯回歸與線性回歸類似,但邏輯回歸的結果只能有兩個的值,如果說線性回歸是在預測一個開放的數值,那邏輯回歸更像是做一道是或不是的判斷題,
邏輯函式中Y值的范圍從 0 到 1,是一個概率值,邏輯函式通常呈S 型,曲線把圖表分成兩塊區域,因此適合用于分類任務,
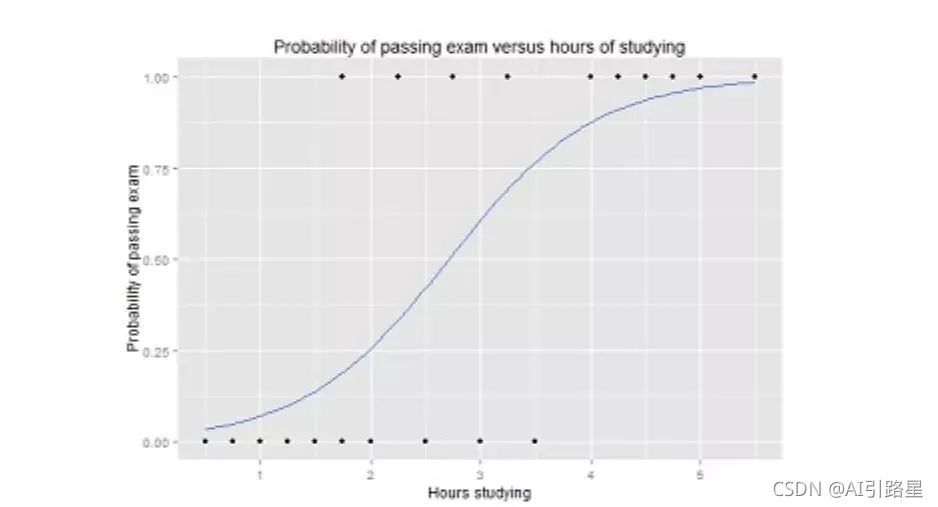
比如上面的邏輯回歸曲線圖,顯示了通過考試的概率與學習時間的關系,可以用來預測是否可以通過考試,
4、線性回歸
所謂線性回歸,就是利用數理統計中的回歸分析,來確定兩種或兩種以上變數間,相互依賴的定量關系的一種統計分析方法,
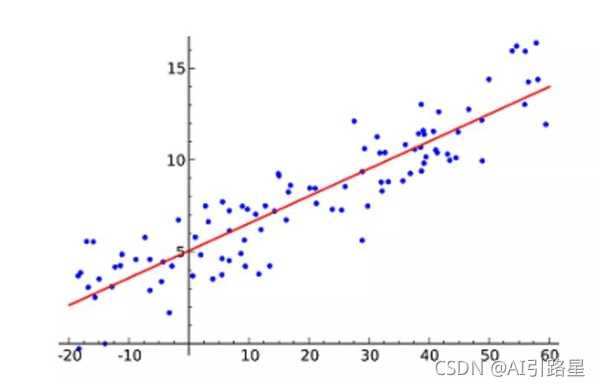
線性回歸(Linear Regression)可能是最流行的機器學習演算法,它試圖通過將直線方程與該資料擬合來表示自變數(x 值)和數值結果(y 值),然后就可以用這條線來預測未來的值!
這種演算法最常用的技術是最小二乘法(Least of squares),這個方法計算出最佳擬合線,以使得與直線上每個資料點的垂直距離最小,總距離是所有資料點的垂直距離(綠線)的平方和,其思想是通過最小化這個平方誤差或距離來擬合模型,
5、樸素貝葉斯
樸素貝葉斯(Naive Bayes)是基于貝葉斯定理,即兩個條件關系之間,它測量每個類的概率,每個類的條件概率給出 x 的值,這個演算法用于分類問題,得到一個二進制“是 / 非”的結果,
樸素貝葉斯分類器是一種流行的統計技術,經典應用是過濾垃圾郵件,
6、神經網路
Neural Networks適合一個input可能落入至少兩個類別里:NN由若干層神經元,和它們之間的聯系組成,第一層是input層,最后一層是output層,在hidden層和output層都有自己的classifier,
input輸入到網路中,被激活,計算的分數被傳遞到下一層,激活后面的神經層,最后output層的節點上的分數代表屬于各類的分數,下圖例子得到分類結果為class 1;同樣的input被傳輸到不同的節點上,之所以會得到不同的結果是因為各自節點有不同的weights和bias,這也就是forward propagation,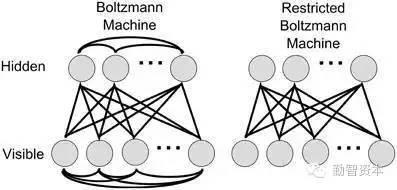
7、K- 均值
K- 均值(K-means)是通過對資料集進行分類來聚類的,例如,這個演算法可用于根據購買歷史將用戶分組,它在資料集中找到 K 個聚類,K- 均值用于無監督學習,因此,我們只需使用訓練資料 X,以及我們想要識別的聚類數量 K,
先要將一組資料,分為三類,粉色數值大,黃色數值小,最開始先初始化,這里面選了最簡單的3,2,1作為各類的初始值,剩下的資料里,每個都與三個初始值計算距離,然后歸類到離它最近的初始值所在類別,
欺詐檢測中應用廣泛,例如醫療保險和保險欺詐檢測領域
8、支持向量機
要將兩類分開,想要得到一個超平面,最優的超平面是到兩類的 margin達到最大,margin就是超平面與離它最近一點的距離,
是一種用于分類問題的監督演算法,支持向量機試圖在資料點之間繪制兩條線,它們之間的邊距最大,為此,我們將資料項繪制為 n 維空間中的點,其中,n 是輸入特征的數量,在此基礎上,支持向量機找到一個最優邊界,稱為超平面(Hyperplane),它通過類標簽將可能的輸出進行最佳分離,
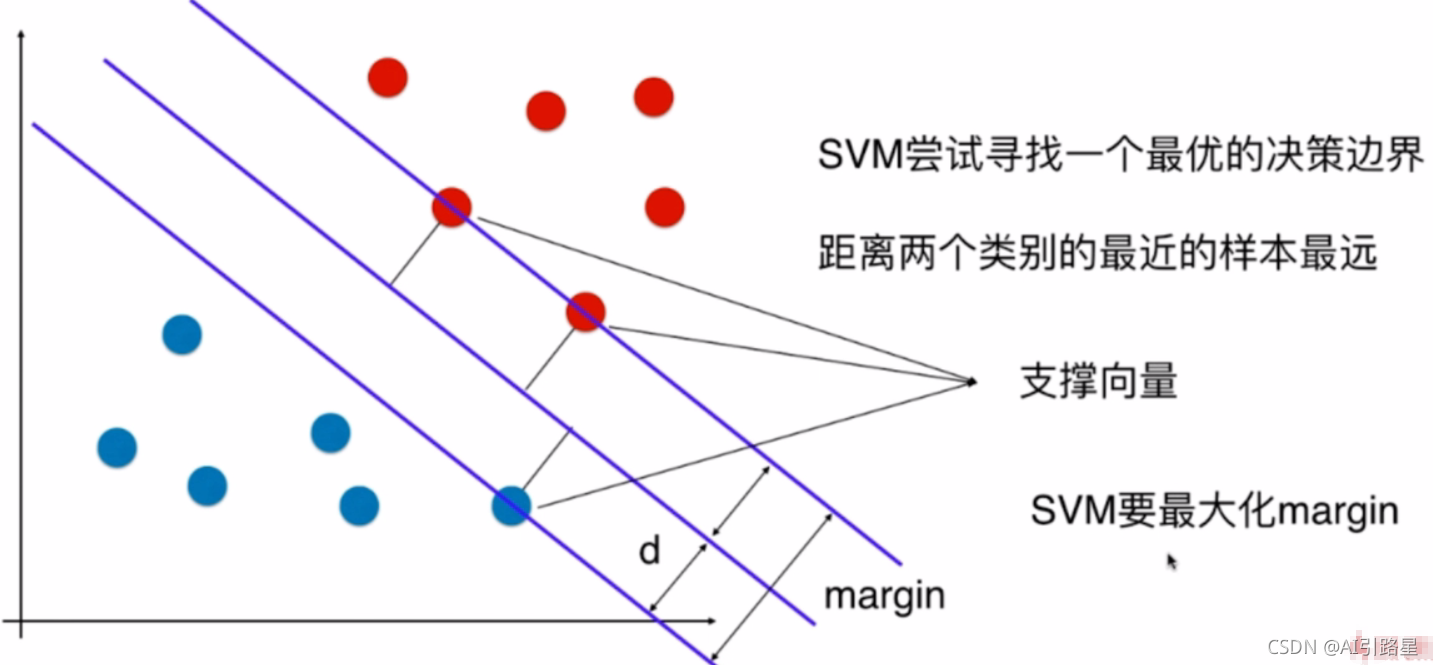
應用于面部識別、文本分類等
9、K- 最近鄰演算法
給一個新的資料時,離它最近的k個點中,哪個類別多,這個資料就屬于哪一類,
例子∶要區分“貓”和“狗”,通過“claws”和“sound”兩個feature來判斷的話,圓形和三角形是已知分類的了,那么這個“star”代表的是哪一類呢?
10、降維
降維(Dimensionality reduction)試圖在不丟失最重要資訊的情況下,通過將特定的特征組合成更高層次的特征來解決這個問題,主成分分析(Principal Component Analysis,PCA)是最流行的降維技術,
主成分分析通過將資料集壓縮到低維線或超平面 / 子空間來降低資料集的維數,這盡可能地保留了原始資料的顯著特征,
整理了一份關深度學習 和機器視覺的資料,有python基礎,影像處理opencv\自然語言處理、機器學習、數學基礎等資源庫,想學習人工智能或者轉行到高薪資行業的,大學生都非常實用,無任何套路免費提供,,加我裙966367816下載,+vx也可以領取的內部資源,人工智能題庫,大廠面試題 學習大綱 自學課程大綱還有200GAI資料大禮包免費送哦~
有什么問題都可以來問我
歡迎大家掃碼 獲取AI免費視頻資料

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/300954.html
標籤:AI
上一篇:【CSDN】【從800+CSDN支持的Emoji表情中篩選出文章標題可用的 1?? 2?? 4?? 個表情并進行分類】(文章標題如何使用Emoji表情)??