環境背景:
Hadoop偽分布式已經搭建完成
Hadoop2.6.0
Hadoop偽分布搭建見:
Hadoop偽分布式的搭建詳情https://blog.csdn.net/m0_54925305/article/details/118650350?spm=1001.2014.3001.5502![]() https://blog.csdn.net/m0_54925305/article/details/118650350?spm=1001.2014.3001.5502
https://blog.csdn.net/m0_54925305/article/details/118650350?spm=1001.2014.3001.5502
案例實施:
1.啟動集群:


2.進入虛擬機瀏覽器地址欄localhost:50070和localhost:8088查看集群狀態:
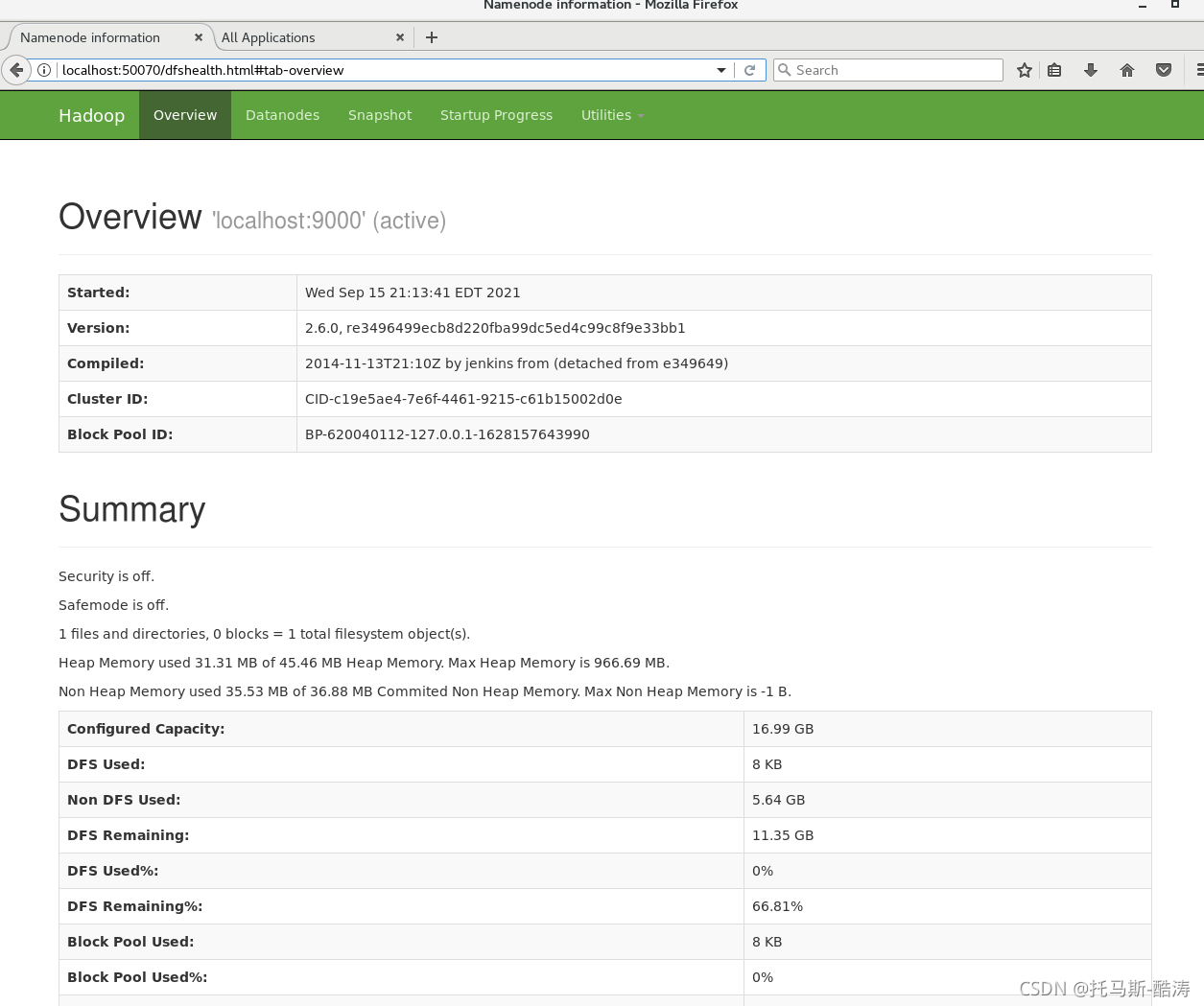

注:Wordcount是MapReduce的入門示例程式,相當于我們在學某個編程語言時寫的Hello World示例一樣,這個程式可以統計某個檔案中,各個單詞出現的次數,Wordcount程式自帶的jar包已經放置在hadoop安裝目錄下的 /share/hadoop/mapreduce 檔案夾中,
3.配置wordcount環境:
(1)進入Hadoop安裝路徑下可以看到:圖中的txt檔案為Hadoop自帶的測驗檔案,這里將進行自定義檔案進行操作,
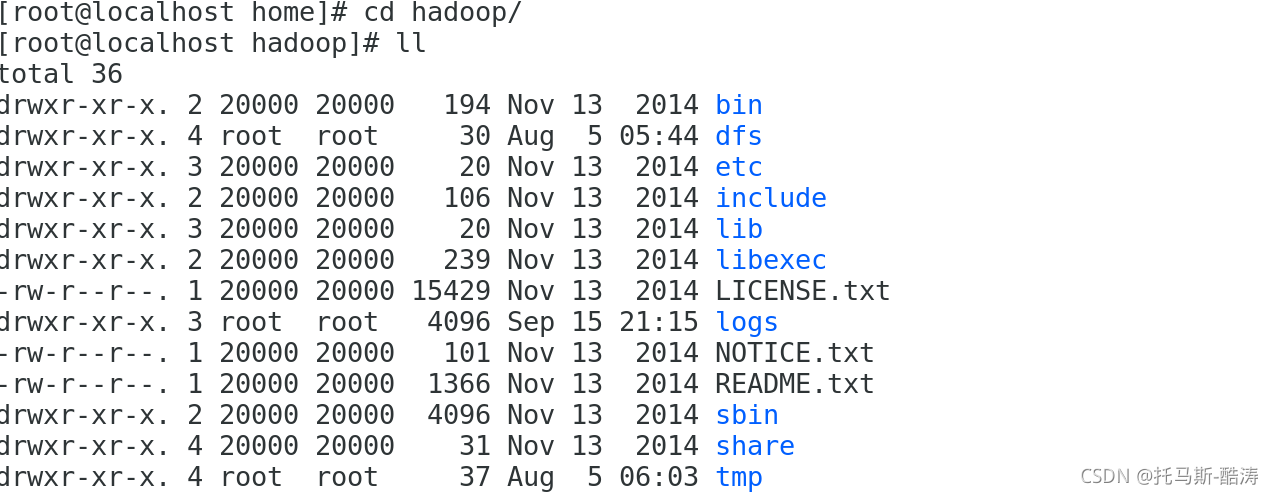
(2)在這里我們新建wordcount.txt檔案進行測驗,文本內容如下:


(3)在HDFS根目錄下新建input目錄:

(4)將本地的wordcount.txt上傳到HDFS的input目錄下:

(5)查看檔案是否上傳成功: 
注:如圖出現/input和/input/wordcount.txt檔案即為上傳成功
4.運行wordcount案例:

注:使用hadoop jar命令 +mapreduce自帶的jar包路徑(絕對路徑)+檔案名+輸入路徑+輸出路徑 #此處jar包根據自身實際情況進行修改
運行程序注意觀察這幾處字樣,即為運行成功:


5.查看運行結果:
再次查看運行結果檔案:
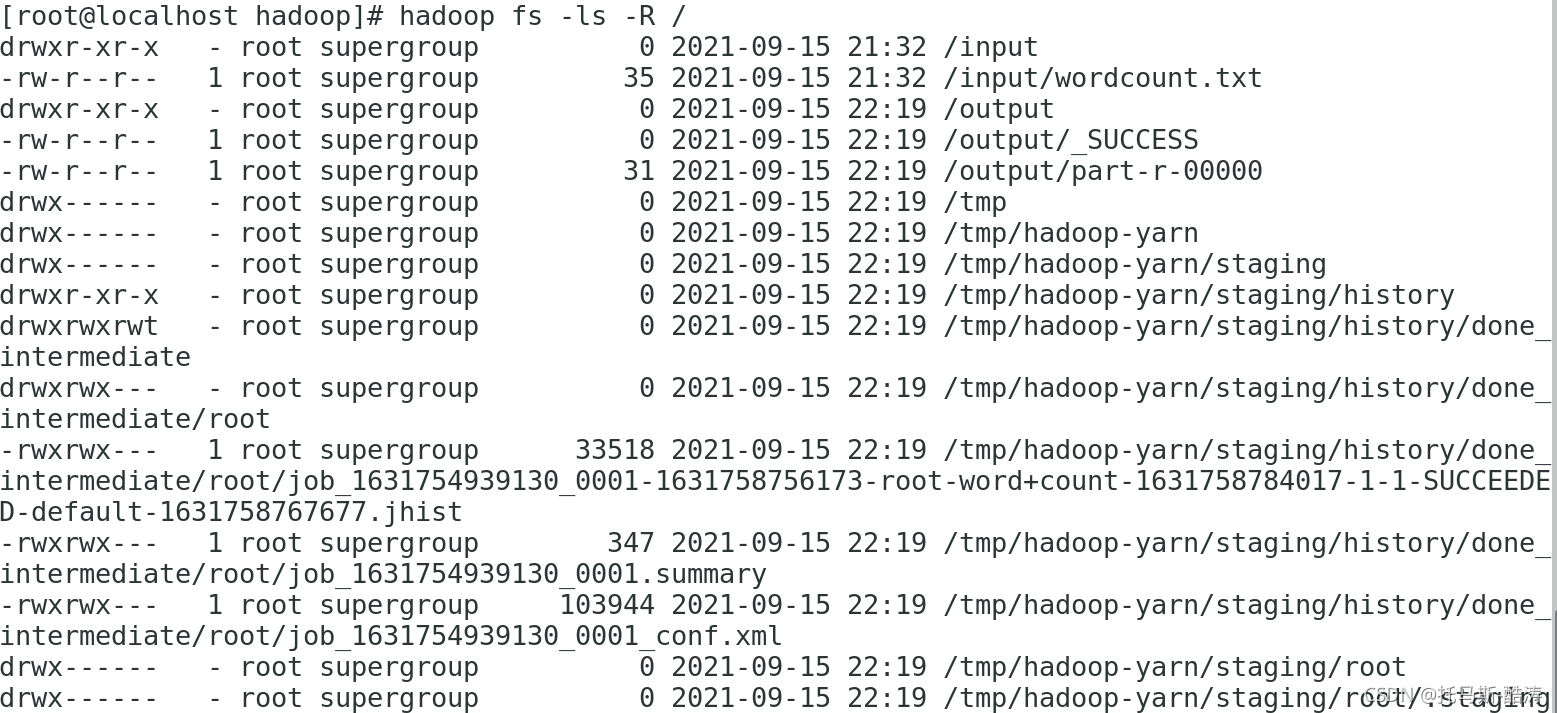
可以看到,程式運行產生了很多檔案,其中/output/part -r -00000即為程式運行完成時的結果檔案,如下圖:

基于Hadoop偽分布式運行Hadoop自帶wordcount案例完成
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/300996.html
標籤:其他
下一篇:Dubbo的原理與機制