牛人博客
Linux(內核剖析)
趣談Linux作業系統 學習
記憶體管理
理解Linux記憶體管理
作業系統的設計與實作
Linux行程管理與調度
嵌入式軟開筆試面試題目匯總(超全)
力扣、牛客刷題
2021.6.4
2021.6.4
1 IPC --------3天
一. 行程間通信(IPC)
我們知道行程之間都是相互獨立的,任何一個行程的全域變數在另一個行程中是看不到的,如果行程之間需要交換資料就要通過內核,行程間通信(InterProcess
Communication)的本質就是讓兩個行程看到共同的資源,
行程間通信的目的
- 資料傳輸:一個行程需要將它的資料發送給另一個行程
- 資源共享:多個行程之間共享同樣的資源
- 通知事件:一個行程需要向另一個行程發送訊息,通知其發生了某種事情(比如行程終止父行程告訴子行程)
- 行程控制:有些行程希望完全控制另一個行程的執行,此時控制行程希望能夠攔截另一個行程的所有陷入和例外,能夠及時知道它的狀態改變,
PIPE
Linux行程通信(一)——pipe管道 10:36
Linux管道的實作機制11:16
pipe sample 12:09
Pipe內核實作細節
IPC統一管理結構(msg, shm, sem)
【Linux】Linux行程通信與System V IPC機制
key_t鍵和ftok函式
shm 共享記憶體 (內核分配page + mmap到各行程虛擬地址空間)
行程間通信方式——共享記憶體
【Linux】Linux的共享記憶體 23:00
shm sample 13:30 (通過命令 ipcs 查看shm管理,cat /proc/pid/maps查看shm如何mmap )
shmsg: message Queue
【Linux】Linux的訊息佇列(內核資料結構)
shsem: semaphore set
【Linux】Linux的信號量集 system V
- waitpid()/wait()
2 內核同步
英文總結
Synchronization (computer science)專題集錦
同步機制
Linux(內核剖析)
Linux(內核剖析):28—內核同步之(臨界區、競爭條件、同步、鎖、常見的內核并發、SMNP和UP配置選項、鎖的爭用和擴展性(鎖粒度))
spinlock
Linux內核同步(二):自旋鎖(Spinlock)
Linux(內核剖析):30—內核同步之(自旋鎖(spin lock)、讀-寫自旋鎖(spin wrlock))
struct spinlock_t sp_lock
spin_lock_init(&sp_lock);
DEFINE_SPINLOCK(sp_lock);
struct spinlock_t //up 時為空,smp時owner和next
{
#if SMP
struct __raw_tickets {
u16 owner;
u16 next;
} tickets;
#endif
}
spin_lock(&sp_lock); //up上只關閉強占preempt_disable(); smps上next++,busy testing owner==next時進入
//critical section
spin_unlock(&sp_lock);// up上preempt_enable(); smp還要count++
//有中斷訪問共享資料的情況,需要屏蔽中斷
int flag;
spin_lock_irqsave(&sp_lock, flag); // preempt_disable();lock_irq_save();
spin_lock_irqstore(&sp_lock, flag); //lock_irq_restore(); preempt_enable();
//有bh訪問共享資料的情況,需要屏蔽bh
spin_lock_bh(&sp_lock); // lock_bh_disable();preempt_disable();
spin_unlock_bh(&sp_lock); // lock_bh_enable();preempt_enable();
semaphore
應用:互斥:sema_lock(&sem,x); 若x==1等同于mutex,若有幾個資源可使用則x等于幾
tong
Linux(內核剖析):31—內核同步之(信號量(semaphore)、讀寫信號量(rw_semaphore))
Linux內核信號量(semaphore)使用與原始碼分析
Linux 內核同步(五):信號量(semaphore)
/*------init semaphore--------*/
struct semaphore sema_lock
sema_lock(&sem_lock, count); //count 表示共有幾個可用資源,count=1時和mutex效果一樣
/*------lock critical section(can lead to sleep of current thread)--------*/
down(&sem_lock); //等待時對信號不回應
//critical section;
up(&sem_lock);
/*------lock critical section(can lead to sleep of current thread)--------*/
ret = down_interruptible(&sem_lock); //該函式回傳可能因為1.有可用資源ret=0;2 ctrl+c等信號例外回傳ret=-EINTR
if(0 != ret);
{
//例外喚醒
return ret; //ret = -EINTR or -ETIMEOUT
}
//critical section;
up(&sem_lock);
Mutex
- 互斥量, count=1的輕量級semaphore,可能睡眠(行程中使用)
- Linux(內核剖析):32—內核同步之(互斥體(mutex))
- Linux內核同步(六):互斥體(mutex)
/*------init mutex lock--------*/
struct mutex mt_lock
mutex_init(&mt_lock)
DEFINE_MUTEX(mt_lock)
/*------lock critical section--------*/
mutex_lock(&mt_lock);
//critical area
mutex_unlock(&mt_lock);
mutex_trylock(&mt_lock); //鎖成功回傳1
mutex_islocked(&mt_lock);
順序鎖seqlock
- 一寫多讀應用,寫優先于讀(隨時寫,不等讀完成),寫互斥(一個寫者spinlock互斥其他寫者),讀者沒有鎖互斥或保護,讀者通過反復讀+判斷是否有寫打斷來保證資料完整性(讀執行緒忙測,cup若忙也可以將read執行緒switchout)
- Linux內核同步(四):順序鎖(seqlock)
/*------init seqlock--------*/
struct seqlock_t lock;
seqlock_init(&lock);
DEFINE_SEQLOCK(lock);
/*------write thread--------*/
write_seqlock(&lock);
//write data
write_sequnlock(&lock);
/*------read thread--------*/
int count;
do{
count = read_seqbegin(&lock);
//read data
}while(read_seqretry(&lock, count))
Barrier
禁止compiler和cup執行時對指令順序的改變(優化),確保硬體要求的指令執行順序
//保證讀的先后順序
if(enable)
rmb();
do_something(attr);
//保證寫的先后順序
attr = x;
wmb();
enable = 1;
//保證讀寫的先后順序
attr = get(oldattr)+1;
mb();
enable = 1;
//smp上讀寫屏障
smp_rmb();
smp_wmb();
smp_mb();
smp_
內核中核心的調度函式的使用(休眠,喚醒)
P1
schedule_timeout() ---P1主動調度(將本行程換出,選擇一個新行程執行,P1睡眠(在cpu狀態為task_uninterruptable 不接收信號or task_interruptable接收信號的等待佇列中)
P3
wake_up_process(P1) ---將待喚醒的P1行程掛入running行程佇列,cpu在后續某時刻選中P1后即執行P1
使用以上函式的其他內核機制
P1
**struct semaphore sem_t
down(&sem_t)**
{
...
struct semaphore_waiter waiter;
前半部分:掛起本行程:
list_add_tail(&waiter.list, &sem->wait_list); 1將本行程掛入semaphore自己的等待佇列中
waiter.task = current;
waiter.up = false;
timeout = schedule_timeout(currnet); 2block在本函式中(cup中換出本進城,掛入cpu睡眠等待佇列),
后半部分:從schedule_timeout函式中回傳cup中喚醒得到執行,
if(waiter.up == true) return 0;
...
}
P3
**up(&sem_t)**
{
waiter = list_del_first(sem_list); //P3釋放了一個資源,從sama等待佇列頭取一個等待該資源的行程P1(waiter.task == P1)
waiter.up = true; //置標志,使得P1在down函式的schedule_timeout中回傳后,認為獲得了資源并成功回傳
wake_up_process(waiter.task); // 將待喚醒的P1行程掛入cpu的running行程佇列,cpu在后續某時刻選中P1后即執行P1
}
wait_queue s: 內核同步機制,執行緒A需要等待某個條件C滿足再繼續執行,執行緒B確保條件C滿足然后喚醒wq中等待的執行緒A
本質及內核實作都和semaphore非常類似,semaphore可以看做wait_queue的特例,conditiaon就是sem->count == 0.
Linux內核等待佇列(wait_queue)使用與原始碼分析
等待佇列的簡單使用
LDD3 Chapter6 阻塞型IO
#include <linux/sched.h>
int condition = 0 //global variable
DECLARE_WAIT_QUEUE_HEAD(wq); //global variable
struct task_struct *task1 = NULL;
struct task_struct *task2 = NULL;
struct task_struct *task3 = NULL;
void* T1(void* arg)
{
...
wait_event_interruptable(&wq, condition);
condition = 0;
}
void* T2(void* arg)
{
...
sleep(1);
wait_event_interruptable(&wq, condition); //每次加入到wq鏈表節點頭,所以wq->T2->T1
condition = 0;
...
}
void* T3(void* arg)
{
...
condition = 1;
wake_up_interruptable(&wq); //每一次喚醒wq中鏈表的第一個節點記住的行程,此處會喚醒T2,無法精確指定喚醒某一個任務,
condition = 1;
wake_up_interruptable(&wq); //,此處會喚醒T1
}
int __init initFun(void)
{
condition = 0;
task1 = kthread_run(T1, NULL, "T1", arg1);
task2 = kthread_run(T2, NULL, "T1", arg1);
task3 = kthread_run(T3, NULL, "T1", arg1);
}
void __exit exitFun(void)
{
kthread_stop(task1);
kthread_stop(task2);
kthread_stop(task3);
}
module_init(initFun);
module_exit(exitFun);
Select Poll
poll/select機制的用戶層驅動層使用總結
Linux驅動基本理論之——poll機制圖解
Linux select的實作原理到底是怎樣的?
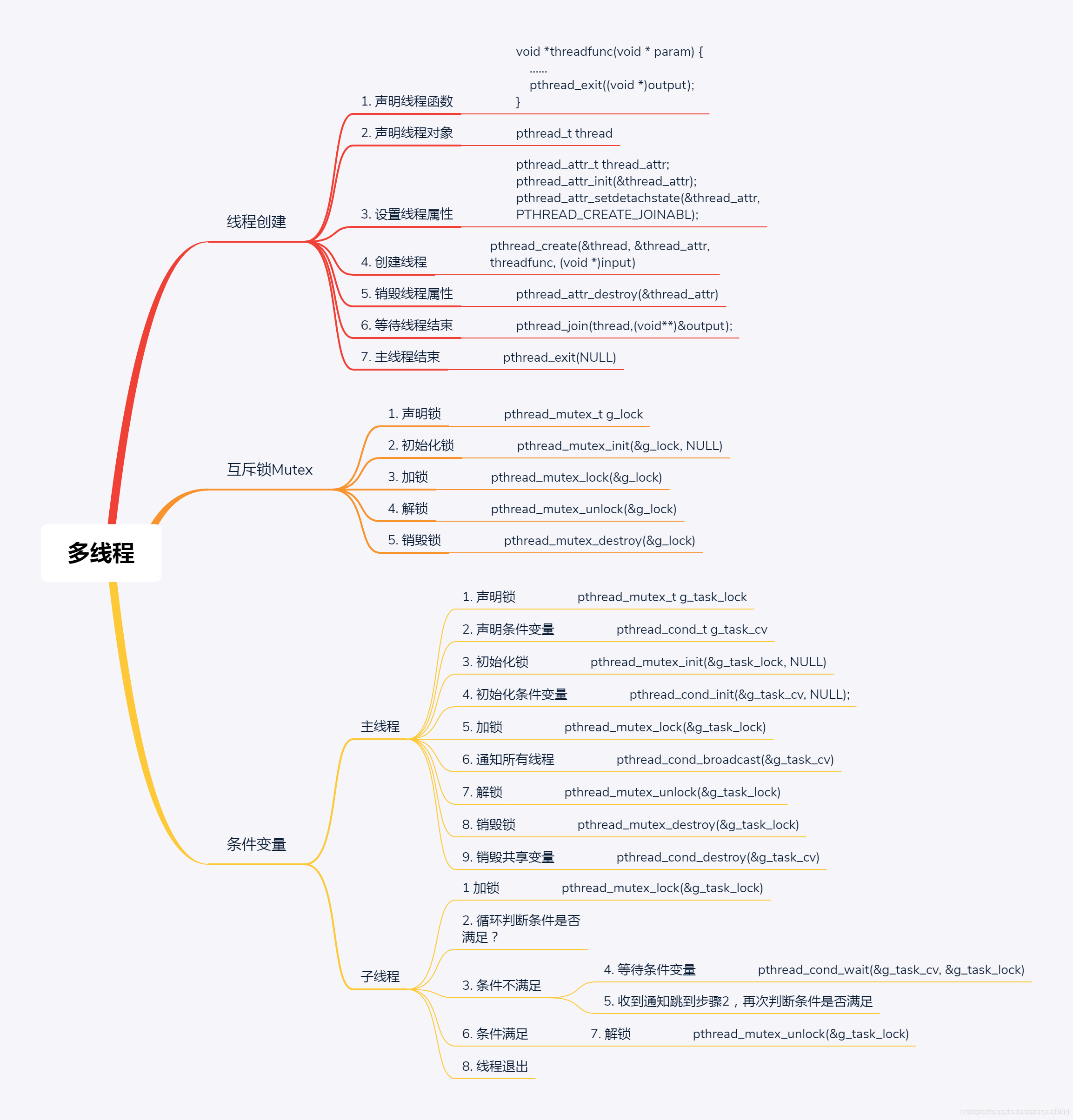
Pthread
- Linux多執行緒編程—執行緒間同步(互斥鎖、條件變數、信號量和讀寫鎖)
- 一步一步學linux作業系統: 08 多執行緒與互斥鎖、條件變數
- 執行緒屬性pthread_attr_t簡介
pthread_mutex
- 僅實作互斥
- pthread包的mutex實作分析
- glibc nptl庫pthread_mutex_lock和pthread_mutex_unlock淺析
pthread_mutex_t mt_lock;
pthread_mutex_init(&mt_lock, NULL);
pthread_mutex_lock(&mt_lock);
f(sharedata);
pthread_mutex_unlock(&mt_lock);
pthread_mutex_destroy(&mt_lock);
sem (pthread semaphore)
- 互斥: sem_init(&sem, pshare, 1); //pshare=0 是執行緒間sema, phshare !=0是進城間sema
- 同步: sem_init(&sem, pshare, 0); //
//互斥
sem_t sem;
sem_init(&sem, count); //count = 1 互斥; count = 0同步
sem_wait(&sem);
f(sharedata);
sem_post(&sem);
//一對一同步
sem_t sem_rd;
sem_t sem_wr;
sem_init(&sem_wr, 1);
sem_init(&sem_rd, 0);
pthread_create(tid_wr, NULL, writer, arg);
pthread_create(tid_rd, NULL, reader, arg);
pthread_join(tid_wr);
pthread_join(tid_rd);
sem_destroy(&sem_rd);
sem_destroy(&sem_wr);
//thread writer
sem_wait(&sem_wr);
write data;
sem_post(&sem_rd);
//thread reader
sem_wait(&sem_rd);
write_data;
sem_post(&sem_wr);
pthread_cond_t 條件變數
- 1寫多讀的同步,寫之間互斥,讀互相爭搶&回圈檢測(要判斷寫是否完成)
- 要配合pthread_mutex_t使用
- 深入決議條件變數(condition variables)
int canRd; //條件
pthread_cond_t cond;
pthread_cond_init(&cond);
pthread_mutex_t mutex;
pthread_mutex_init(&mutex);
pthread_create(tid_wr, NULL, writer, arg);
pthread_create(tid_rd1, NULL, reader, arg);
pthread_create(tid_rd2, NULL, reader, arg);
pthread_join(tid_wr);
pthread_join(tid_rd1);
pthread_join(tid_rd2);
pthread_cond_destroy(&cond);
//thread writer
pthread_mutex_lock(&mutex);
write data;
canRd = true;
pthread_cond_brodcast(&cond); //喚醒所有等待的讀者
or pthread_cond_signal(&cond); //按序喚醒第一個等待的讀者
pthread_mutex_unlock(&mutex);
//thread reader
pthread_mutex_lock(&mutex);
while( canRd != true)
{
pthread_cond_wait(&cond, &mutex);
}
read data;
pthread_mutex_unlock(&mutex);
偽代碼:執行緒間同步(pthread + pthread_mutex_t + pthread_cond_t)
#include <pthread.h>
struct msg
{
void* content;
struct msg* next;
}
struct msg *msglist;
pthread_mutex_t mymutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t mycond = PTHREAD_COND_INITIALIZER;
bool quit = false;
void* consumer(void* arg)
{
pthread_t selftid = pthread_self();
//pthread_detach(selftid); //if no sycronization with main thread.
while(quit) //main thread control when the consumer to withdraw
{
//判斷是否有新資料,需訪問共享資料msg,所以必須加鎖互斥訪問msg
pthread_mutex_lock(&mymutex);
while(msglist == NULL) //若果無msg,則進入睡眠等待,但睡眠前必須解鎖(pthread_cond_wait),
{
if(quit)
{
pthread_mutex_unlock(&mymutex);
pthread_exit();
return;
}
/*
1 pthread_cond_wait執行步驟:put current thread to cond wait queue->mutex_unlock->current thread swith out(in waiting queue to be waken up)->(once signal from producer thread) mutex_lock
2 有2種情況會被喚醒(寫執行緒cond_signal):
a有新資料(msg!= null,對應處理:判斷是否有新資料,若無,則繼續cond_wait(解鎖后睡眠,等待下一次喚醒)
b quit==true 對應處理:解鎖,執行緒退出
*/
pthread_cond_wait(&mycond, &mymutex);
}
//read msglist
pthread_mutex_unlock(&mymutex);
}
pthread_exit();
}
void* producer(void* arg)
{
pthread_t selftid = pthread_self();
//pthread_detach(selftid);
while(!endoffile())
{
pthread_mutex_lock(&mymutex);
//write msglist
pthread_cond_signal(&mycond); //unlock 之前喚醒所有讀執行緒
pthread_mutex_unlock(&mymutex);
}
//write ends, and notify all readers to withdraw.
pthread_mutex_lock(&mymutex);
quit = true;
pthread_cond_broadcast(&mycond, &mymutex); //必須喚醒所有讀執行緒,否則因為寫執行緒退出了寫回圈而沒有新資料了,也就不會cond_signal任何讀執行緒了,而讀執行緒都會睡眠在cond_wait上無法退出,所以此處必須有一個額外的cond_signal喚醒所有的讀執行緒
pthread_mutex_unlock(&mymutex);
pthread_exit();
}
//main thread
int main()
{
pthread_t readPid1 = -1, readPid1 = -1, writePid;
//pthread_mutex_init(&mymutex, NULL); 靜態分配的mutex在編譯階段初始化為解鎖狀態
//pthread_cond_init(&mycond, NULL);
ret = pthread_create(&readPid1, NULL, consumer, void*arg);
if(0 != ret) goto err;
ret = pthread_create(&readPid2, NULL, consumer, void*arg);
if(0 != ret) goto err;
ret = pthread_create(&writePid, NULL, producer, void*arg);
if(0 != ret) goto err;
void* retval;
pthread_join(readPid1, &retval);
pthread_join(readPid2, &retval);
pthread_join(writePid, &retval);
//pthread_mutex_destroy(&mymutex); // only for dynamic allocted mutex pthread_mutex_init(&mymutex, NULL);
//pthread_cond_destroy(&mycond);
pthread_exit();
return 0;
}
偽代碼:執行緒間互斥(pthread + pthread_mutex_t + pthread_cond_t)
#include <pthread.h>
#include <semaphor.h>
struct Printer{
}
#define MAX_PRINT_TASK_NUM
#define PRINTER_NUM
struct Printer prints[PRINTER_NUM];
sem_t mysem;
int main()
{
sem_init(&mysem, 0, PRINTER_NUM);
pthread_t pid[MAX_PRINT_TASK_NUM];
cint cnt = 0;
while(q != gechar() && cnt < MAX_PRINT_TASK_NUM)
{
printf("please press any key to submit a print task\n");
scanf("")
pthread_create(&pid[cnt], NULL, exect_print_func, (void*)file );
}
sem_destroy(&mysem);
}
2 TCP/IP,socket, rtsp/rtp -----------3天
Linux網路編程
TCP/IP
- 太厲害了,終于有人能把TCP/IP 協議講的明明白白了
socket編程
- Linux的SOCKET編程詳解
深入理解socket中的recv函式和send函式
todo: inet_pton() inet_ntop()實作
#include <sys/socket.h>
#define SERVER_PORT 554
#define SERVER_MAX_CONNC 100
#define BUFF_SIZE 1024
main()
{
int sockfd = socket(AF_INET, SOCK_STREAM, IPPORTO_TCP);
if(-1 == sockfd) error;
struct sockaddr_in svaddr;
svaddr.sin_family = AF_INET;
svaddr.sin_addr.s_addr = htonl(INADDR_ANY);
svaddr.sin_port = htons(SEVER_PORT);
if(-1 == bind(sockfd, (struct sockaddr*)svaddr, sizeof(svaddr))
error;
if( -1 == listen(sockfd, SERVER_MAX_CONNC))
error;
pthread_t pid[SERVER_MAX_CONNC];
struct sockaddr_in cliaddr[SERVER_MAX_CONNC];
int clisock[SERVER_MAX_CONNC];
int cliaddrlen = 0;
int clinum = 0;
while(1)
{
clisock[clinum] = accept(sockfd, (struct sockaddr*)&cliaddr[clinum],&cliaddrlen);
if(-1 == clisock[clinum])
{
error;
continue;
}
if(0 == pthread_create(&(pid[clinum]), NULL, SeverNetService, &(clisock[clinum])))
{
error;
}
pthread_detach(pid[clinum]);
clinum++;
}
close(sockfd);
}
void* SeverNetService(void* arg)
{
int recvlen = 0, sendlen = 0;
char recvbuff[BUFF_SIZE], sendbuff[BUFF_SIZE];
clisock = *((int*)arg);
while(1)
{
//失敗時,回傳值小于0;超時或對端主動關閉,回傳值等于0;成功時,回傳值是回傳接收資料的長度
recvlen = recv(clisock, recvbuff, BUFF_SIZE, 0);
if(recvlen <= 0)
{
goto error;
}
recvbuff[recvlen] = 0;
//to deal with received data
//to prepare send data
//失敗時,回傳值小于0;超時或對端主動關閉,回傳值等于0;成功時,回傳值是回傳發送資料的長度
sendlen = send(clisock, sendbuff, strlen(sendbuff), 0);
if(sendlen <= 0)
{
goto error;
}
}
error:
close(clisock);
pthread_exit(0);
}
大小端:endian 表示數的結尾即存盤該數的低地址,cpu存盤和讀取記憶體都是從低地址--》高地址
如int a = 0x12345678 在大端和小端的機器的記憶體中存盤如下:
0x8000 0001 0x8000 0002 0x8000 0003 0x8000 0004
big endian: 12 34 56 78
little endian: 78 56 34 12
big endian: 最重要(大)的部分存在 endian(低地址) == 網路位元組序
little endian: 最不重要(小)的部分存在 endian(低地址)
大小端轉換:
(( a&0x000000ff)<< 24 ) | ( ( a&0x0000ff00 ) << 8 ) | ( ( a&0x00ff0000 ) >> 8 ) | ( ( a&0xff000000 ) >> 24 )
// check cup is little or big endian
int main()
{
union {
int i;
char c;
}temp;
temp.i = 0x12345678;
if(temp.c == 0x78)
{
printf("little endian\n");
}
else
{
printf("big endian\n");
}
return 0
}
//convert little to big endian
int LE2BE(int val)
{
return ( ((val&0xff)<<24) | ((val&0xff00)<<8) | ((val&0xff0000)>>8) | ((val&0xff000000)>>24) )
}
HTTP
- 一篇文章帶你詳解 HTTP 協議(網路協議篇一)
RTSP、RTP、RTCP
- RTSP over UDP與RTSP over TCP取流對比
RTSP訊息格式
網路攝像頭Rtsp直播方案(一)- socket code
網路攝像頭Rtsp直播方案(二)- rtsp code
網路攝像頭Rtsp直播方案(三)- rtp code訊息決議sscanf()
1 OPTION:
Client(192.168.1.1) -->Server(10.10.10.1)
Request: OPTIONS rtsp://10.10.10.1:554/h264/ch1/sub/av_stream RTSP/1.0\r\n
Cseq: 2\r\n
User-Agent: LibVLC/2.2.4\r\n
\r\n
Response: RTSP/1.0 200 OK\r\n
Cseq: 2\r\n
Public: OPTIONS, DESCRIBE, SETUP, PLAY, TEARDOWN, GET_PAMAMETER SET_PAMAMETER\r\n
Date: Fri, SEP 10 2021 10:03:30 GMT\r\n
\r\n
2 DESCRIBE
Request: DESCRIBE rtsp://10.10.10.1:554/h264/ch1/sub/av_stream RTSP/1.0\r\n
Cseq: 3\r\n
User-Agent: LibVLC/2.2.4\r\n
Accept: application/sdp\r\n
\r\n
3 boot移植 --------3天
4 mmap ---------2天
認真分析mmap:是什么 為什么 怎么用
mmap記憶體映射
mmap本身其實是一個很簡單的操作,在行程的頁表中添加一個頁表項,該頁表項是物理記憶體的地址,呼叫mmap的時候,內核會在改行程的虛擬空間的映射區域查找一塊滿足需求的空間用于映射該檔案,然后生成該虛擬地址的頁表項,該頁表項此時的有效位(標志是否已經在物理記憶體中)為0,頁表項的內容是檔案的磁盤地址,此時mmap的任務已經完成,
當mmap建立完頁表的映射后,就可以操作改塊記憶體了,進行的所有改動都會自動寫會磁盤檔案,第一次訪問該塊記憶體的時候,因為頁表項的有效位還是0,就會發生缺頁中斷,然后CPU會使用該頁表項的內容也就是磁盤的檔案地址,該將地址指向的內容加載到物理記憶體,并需改頁表項的內容為該物理地址,有效位置為1.
todo:仿寫 mmap實作映射mem字符驅動的記憶體
Linux驅動mmap記憶體映射詳解及例子實作
一步一步學linux作業系統: 22 記憶體管理_用戶態記憶體映射
/proc/$pid/maps檔案格式決議
一步一步學linux作業系統: 26 檔案系統_虛擬檔案系統、掛載檔案系統與打開檔案
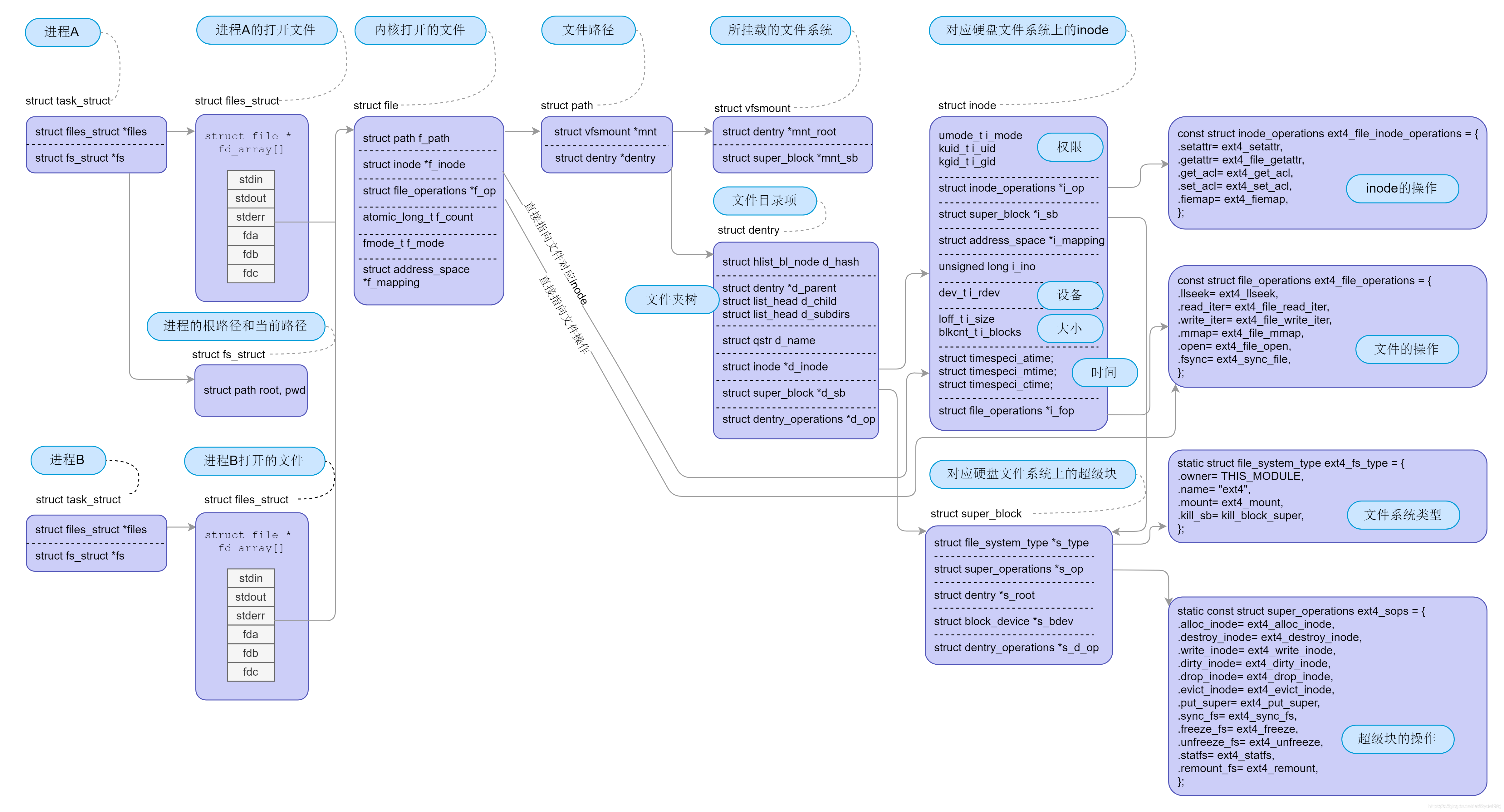
5 fs
一口氣搞懂「檔案系統」,就靠這 25 張圖了
從內核檔案系統看檔案讀寫程序
Linux 字符設備驅動開發基礎(六)—— VFS 虛擬檔案系統決議
6 char device driver mode
一步一步學linux作業系統: 28 輸入與輸出系統_輸入與輸出設備的管理
一步一步學linux作業系統: 29 輸入與輸出系統_ 字符設備一_打開、讀寫與IOCTL 控制
Linux 字符設備驅動開發
Linux 字符設備驅動結構(一)—— cdev 結構體、設備號相關知識決議
Linux 字符設備驅動結構(三)—— file、inode結構體及chardevs陣列等相關知識決議
mknod創建設備檔案
一步一步學linux作業系統: 26 檔案系統_虛擬檔案系統、掛載檔案系統與打開檔案
嵌入式Linux根檔案系統和掛載 — to read
Linux 檔案系統與設備檔案系統 (二)—— sysfs 檔案系統與Linux設備模型
5 多媒體:H264 / VO/ FB/ ---------3天
H264
入門理解H264編碼
h264理論
H264句法語法詳解專題
- slice header、 MB組成(motion vector) slice的ABC三種型別
DaveBobo的多媒體編程
6 面試問題
star原則
一 編程題
1 Linked list題
1.2 leetcode
參考
如何判斷單鏈表里面是否有環?
如何判斷單鏈表是否有環、環的入口、環的長度和總長
反轉單鏈表 1
反轉部分單鏈表 1
判段Linked list是否有環 1
求Linked list中環的入口點 1
兩Linked list的交點 1
合并兩升序鏈表 1
sorted list洗掉后續重復節點 1
sorted list洗掉所有重復節點 1
洗掉距結尾的第N個節點 1
middle of linked list 1
rotate list 1
insertionSortList 插入法排序鏈表 1
Convert Binary Number in a Linked List to Integer 1
判斷list是否回文串 1
交換成對節點swap-nodes-in-pairs 1
Partition List 1
1.3 二叉樹
參考:二叉樹的非遞回前序、中序、后序遍歷演算法詳解及代碼實作(C語言)
preorder iterative遍歷 1
inorder iterative遍歷 1
postorder iterative遍歷
1.4 排序
參考:快速排序演算法心得
【C語言】快速排序函式qsort()
quicksort 有重復元素 1
找陣列的第K大元素 — quicksort變型
1.3 string
atoi itoa strlen strcpy strcat strcmp memmove 1
atoi
1 sum超出范圍的判斷,兩種方法,
1.1 用 long long 計算,再判斷是否超出范圍
isInRange(int sum, int digit)
{
long long temp = sum*10 + digit;
return temp <= INT_MAX;
}
1.2 用INT_MAX反推本次sum*10+digit是否超出范圍
1/ 如果sum*10 > INT_MAX,肯定超出范圍
2/ 如果sum == INT_MAX/10 (214748364x),但INT_MAX % 10 < digit也超出范圍(2147483648,2147483649)
isInRange(int sum, int digit)
{
return (INT_MAX/10 < sum) || (INT_MAX/10 == sum && INT_MAX % 10 < digit))
}
注意:僅檢測正數,對于負數邊界值-2147483648,判斷它的正數2147483648超出范圍,又因為sign = -1,所以回傳INT_MIN.
2 int最大最小值 <limit.h> INT_MAX(0x7fffffff = 2147483647) INT_MIN(0x80000000 = -2147483648)
3 int sign = 1 (+), -1(-).
3 最后return sign*sum; or return sign == 1? sum : (~(sum) + 1);
4 主干
while(space) p++; //空格合法:跳過前面的所有空格
if(*p == '+' || *p == '-') //符合合法:取正確符號
{
if(*p == '-') sign = -1;
}
while(*p != '\0') // read until end of string
{
//只要不是0-9就跳出 此階段'','+' '-' 其他非數字字符均不合法
//for "w470" sum = 0; for "470-" '470 ' '470w' sum=470
if(is not digit(*p)) break;
digit = *p - '0';
if(!isInRange(sum, digit))
{
return sign == 1? INT_MAX:INT_MIN;
}
sum = sum*10 + digit;
p++;
}
return sign*sum;
reverse string 1
reverse string II 1
reverse vowels of string 1
strstr 1
最長公共前綴 1
有效的括號 --stack 1
1.4 search
binary search
> **二分法思想**:對有規律的一組數進行某種二分,選擇一半丟棄一半(log2^n),不斷縮小范圍,最后從有限的數中選擇答案
>
> 條件:陣列(根據下標可判斷數的趨勢),數有一定規律(有序,00xx),答案默認是在[start,end]范圍內
>
> 模板要點:
> 1 while( start + 1 < end)
> 回圈跳出時[start|end]為相鄰兩元素,while回圈作用是縮小范圍的,步驟4是選擇答案
>
> 2 mid = start + (end -start)/2
> 寫成mid = (start + end)/2;不好,因為start + end 可能超出int范圍
> 成mid = start + (end - start)>>1;不對,因為>>優先級最低,即=(start + (end - start))>>1,
> mid = start + ((end - start)>>1) 可能超出int范圍
> 3 if(nums[mid] < target)
> start = mid;
> else if(nums[mid] == target)
> start = mid; //求第一個target位置end = mid 求最后一個target位置start = mid;
> else end = mid;
> 4 最后根據題目要求在相鄰的2個數內選擇一個答案
九章二分法模板
binary search
firstBadVersion- binary search 1
sqrt(x)
Search Insert Position 1
Find one Peak Element 1
Find K Closest Elements BS+背向雙指標 1
Find Minimum in Rotated Sorted Array 1
find-first-and-last-position BS+背向雙指標 1
雙指標
一類 相向雙指標
-
Two sum 類
Two Sum --雙指標 / hashmap 1
add-two-numbers o(n + m) -
partition類
二類 背向雙指標
longest-palindromic-substring o(n^2) 1
三類 同向雙指標
longest-substring-without-repeating O(n^2) hashtable+ 同向雙指標 1 ??debug
找出占一半的元素 --特殊簡單演算法
1.5 hash
Design HashMap --包括list_head操作
topKFrequent --hashtable+quicksort
1.6 BST
binary-tree-level-order-traversal
minimum-depth-of-binary-tree
maximum-depth-of-binary-tree
1.4 編程技巧
字串
char str1[] = "abcd"; char*p = str1;
q = p+n: 指向第n個元素的下一個地址空間,如p+strlen(str1)指向'\0'
start end分別是陣列的開始和結束元素的下標,則[start,end]間元素的個數l= end - start + 1
start是開始元素的下標 l是元素個數,則結束元素的下標end = start + l -1;
求q指標和p指標間的字符長度: q-p+1,若q指向'\0', q-p=strlen(str1); 若q指向'd',q-p+1==strlen(str1)
回圈處理until string結束
while(*p) // equals to while('\0' != *p)
{
.....
p++;
}
判斷條件中++/-- 和在block中++/--的不同 (保險起見prefer后一種)
判斷p串是否和q串的子串(內容是否相同) (假設p和q分別指向str1和str2)
A:無論*p,*q是否相等, p,q都指向下一個字符
while(*p && *p++ = *q++)
{}
if(*p)
{
是子串;
}
B:若*p,*q不相等,p,q就停留在最后一個相等的字符上
while(*p && *p = *q)
{
++p;
++q;
}
if(*p)
{
是子串
}
A錯誤,B正確,例如p=“ab” q=“ac”
二 C語言
-
static / dynamic link
如何在linux下寫靜態鏈接庫并賣給別人?
static link _E -
創建靜態庫.a檔案:
ar rcs libclass.a class1.o class2.o class3.o -
查看靜態庫中包含的檔案:
nm -o libclass.a或者nm -s libclass.a -
comple x.c時指定用到的.a庫:
gcc x.c libclass.a或者gcc x.c -lclass -
link 時指定用到的.a庫:
ld x.o -lclass -
dynamic link
如何在linux下寫元件并賣給別人? -
malloc/free實作
-
C++ 參考
-
boolean TRUE FALSE
c中邏輯判斷: 0 為假, 非0均為真(不是只有1才為真)
c語言沒有布爾型別,c99庫才支持布爾型,
#include <stdbool.h>
bool flag = true; flag = false;
- 位運算應用
&:只有1&1=1 ,用于判斷哪一位為1
判斷奇偶數: `(n&1)? 奇數:偶數`
給n,表示-n:-n = ~n + 1 = ~(n - 1);
如代碼中寫n = -5 效率比較低,寫成n = ~5 + 1 (補碼); 或n = ~ (5-1);
n & (n-1) 清除n最右邊的1
n & (-n) 取得n最右邊的1
- int 的最大、最小定義
#include <limit.h>
INT_MAX = 2147483647=0x7fffffff
INT_MIN = -2147483648 = 0x10000000
INI_MAX + 1 = INI_MIN (二進制溢位)
-1 = 0xffffffff
- #include < > 和 #include " "
關于C語言include尖括號和雙引號的對話
linux作業系統
- 一、 系統呼叫 Linux(內核剖析):13—系統呼叫的實作與決議
一步一步學linux作業系統: 06 系統呼叫
Linux內核中的fastcall和asmlinkage宏
在行程A中通過系統呼叫sethostname(const char *name,seze_t len)設定計算機在網路中的“主機名”.
在該情景中我們勢必涉及到從用戶空間向內核空間傳遞資料的問題,name是用戶空間中的地址,它要通過系統呼叫設定到內核中的某個地址中,讓我們看看這個 程序中的一些細節問題:系統呼叫的具體實作是將系統呼叫的引數依次存入暫存器ebx,ecx,edx,esi,edi(最多5個引數,該情景有兩個 name和len),接著將系統呼叫號存入暫存器eax,然后通過中斷指令“int 80”使行程A進入系統空間,由于行程的CPU運行級別小于等于為系統呼叫設定的陷阱門的準入級別3,所以可以暢通無阻的進入系統空間去執行為int 80設定的函式指標system_call(),由于system_call()屬于內核空間,其運行級別DPL為0,CPU要將堆疊切換到內核堆疊,即 行程A的系統空間堆疊,我們知道內核為新建行程創建task_struct結構時,共分配了兩個連續的頁面,即8K的大小,并將底部約1k的大小用于 task_struct(如#define alloc_task_struct() ((struct task_struct ) __get_free_pages(GFP_KERNEL,1))),而其余部分記憶體用于系統空間的堆疊空間,即當從用戶空間轉入系統空間時,堆疊指標 esp變成了(alloc_task_struct()+8192),這也是為什么系統空間通常用宏定義current(參看其實作)獲取當前行程的 task_struct地址的原因,每次在行程從用戶空間進入系統空間之初,系統堆疊就已經被依次壓入用戶堆疊SS、用戶堆疊指標ESP、EFLAGS、 用戶空間CS、EIP,接著system_call()將eax壓入,再接著呼叫SAVE_ALL依次壓入ES、DS、EAX、EBP、EDI、ESI、 EDX、ECX、EBX,然后呼叫sys_call_table+4%EAX,本情景為sys_sethostname(),
- 二、stack overflow_E
a stack overflow occurs if the call stack pointer exceeds the stack bound.
行程fork 函式/分配哪些資源/如何調度/
執行緒pthread函式/分配哪些資源/
堆疊幀詳解
三、內核執行緒創建
kernel_thread() kthread_create()/kthread_run()創建內核執行緒的區別與使用
//包含的頭檔案
#include <linux/sched.h>
#include <linux/kthread.h>
//執行緒執行主函式
int threadFn(void *p)
{
}
第一種
kthread_run(threadFn, threadFnArg, "mythead");
注釋:
第二種
struct task_struct *task1 = kthread_create(threadFn, threadFnArg, "mythead");
if(NULL != task1) wake_up_process(task1);
四 記憶體管理
-
buddy system 管理所有物理記憶體?存放所有頁描述符(struct page)的mem_map存放在哪里,何時init,初始化時各page的資訊?
-
alloc_pages()只分配High-mem?__get_free_pages(gfp_mask, order)分配LowMemory page 直接映射?
-
用戶行程對應的物理記憶體分配在哪個區域,Zone_NOMAL or Zone_HIGH?
-
行程pgd的初始化程序
對于32位的Linux,其每一個行程都有4G的尋址空間,但當一個行程訪問其虛擬記憶體空間中的某個地址時又是怎樣實作不與其它行程的虛擬空間混淆 的呢?每個行程都有其自身的頁面目錄PGD,Linux將該目錄的指標存放在與行程對應的記憶體結構task_struct.(struct mm_struct)mm->pgd中,每當一個行程被調度(schedule())即將進入運行態時,Linux內核都要用該行程的PGD指標設 置CR3(switch_mm()),
當創建一個新的行程時,都要為新行程創建一個新的頁面目錄PGD,并從內核的頁面目錄swapper_pg_dir中復制內核區間頁面目錄項至新建行程頁面目錄PGD的相應位置,具體程序如下:
do_fork() –> copy_mm() –> mm_init() –> pgd_alloc() –> set_pgd_fast()
–> get_pgd_slow() –> memcpy(&PGD + USER_PTRS_PER_PGD, swapper_pg_dir +
USER_PTRS_PER_PGD, (PTRS_PER_PGD - USER_PTRS_PER_PGD) * sizeof(pgd_t))
這樣一來,每個行程的頁面目錄就分成了兩部分,第一部分為“用戶空間”,用來映射其整個行程空間(0x0000 0000-0xBFFF
FFFF)即3G位元組的虛擬地址;第二部分為“系統空間”,用來映射(0xC000 0000-0xFFFF
FFFF)1G位元組的虛擬地址,可以看出Linux系統中每個行程的頁面目錄的第二部分是相同的,所以從行程的角度來看,每個行程有4G位元組的虛擬空間,
較低的3G位元組是自己的用戶空間,最高的1G位元組則為與所有行程以及內核共享的系統空間,
行程的頁目錄PGD(屬于內核資料結構)就處于內核空間中,在行程切換時,要將暫存器CR3設定成指 向新行程的頁目錄PGD,而該目錄的起始地址在內核空間中是虛地址,但CR3所需要的是物理地址,這時候就要用__pa()進行地址轉換,在 mm_context.h中就有這么一行陳述句:
asm volatile(“movl %0,%%cr3”: :”r” (__pa(next->pgd));
這是一行嵌入式匯編代碼,其含義是將下一個行程的頁目錄起始地址next_pgd,通過__pa()轉換成物理地址,存放在某個暫存器中,然后用mov指令將其寫入CR3暫存器中,經過這行陳述句的處理,CR3就指向新行程next的頁目錄表PGD了,
- load kernel image
我們把內核的代碼和資料就叫內核映像(kernel image),當系統啟動時,Linux內核映像被安裝在物理地址0x00100000開始的地方,即1MB開始的區間(第1M留作它用),然而,在正常 運行時, 整個內核映像應該在虛擬內核空間中,因此,連接程式在連接內核映像時,在所有的符號地址上加一個偏移量PAGE_OFFSET,這樣,內核映像在內核空間 的起始地址就為0xC0100000,
內核虛擬地址空間布局
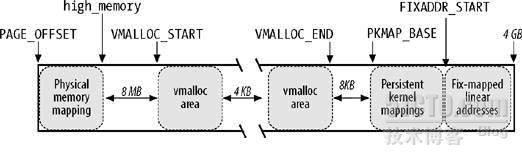
內核線性地址空間部分從PAGE_OFFSET(通常定義為3G)開始,為了將內核裝入記憶體,從PAGE_OFFSET開始8M線性地址用來映射內核所在的物理記憶體地址(也可以說是內核所在虛擬地址是從PAGE_OFFSET開始的);接下來是mem_map陣列,mem_map的起始線性地址與體系結構相關,比如對于UMA結構,由于從PAGE_OFFSET開始16M線性地址空間對應的16M物理地址空間是DMA區,mem_map陣列通常開始于PAGE_OFFSET+16M的線性地址;從PAGE_OFFSET開始到VMALLOC_START – VMALLOC_OFFSET的線性地址空間直接映射到物理記憶體空間(一一對應影射,物理地址<==>線性地址-PAGE_OFFSET),這段區域的大小和機器實際擁有的物理記憶體大小有關,這兒VMALLOC_OFFSET在X86上為8M,主要用來防止越界錯誤;在記憶體比較小的系統上,余下的線性地址空間(還要再減去空白區即VMALLOC_OFFSET)被vmalloc()函式用來把不連續的物理地址空間映射到連續的線性地址空間上,在記憶體比較大的系統上,vmalloc()使用從VMALLOC_START到VMALLOC_END(也即PKMAP_BASE減去2頁的空白頁大小PAGE_SIZE(解釋VMALLOC_END))的線性地址空間,此時余下的線性地址空間(還要再減去2頁的空白區即VMALLOC_OFFSET)又可以分成2部分:第一部分從PKMAP_BASE到FIXADDR_START用來由kmap()函式來建立永久映射高端記憶體;第二部分,從FIXADDR_START到FIXADDR_TOP,這是一個固定大小的臨時映射線性地址空間,(參考:Fixed virtual addresses are needed for subsystems that need to know the virtual address at compile time such as the APIC),在X86體系結構上,FIXADDR_TOP被靜態定義為0xFFFFE000,此時這個固定大小空間結束于整個線性地址空間最后4K前面,該固定大小空間大小是在編譯時計算出來并存盤在__FIXADDR_SIZE變數中,
正是由于vmalloc()使用區、kmap()使用區及固定大小區(kmap_atomic()使用區)的存在才使ZONE_NORMAL區大小受到限制,由于內核在運行時需要這些函式,因此在線性地址空間中至少要VMALLOC_RESERVE大小的空間,VMALLOC_RESERVE的大小與體系結構相關,在X86上,VMALLOC_RESERVE定義為128M,這就是為什么ZONE_NORMAL大小通常是16M到896M的原因,
896M之謎
內核空間0-896M直接映射,如果物理記憶體為256M呢?highMem開始地址為3G+256M+8M
物理記憶體低于896M各個區到底是怎么映射的
- pgd_alloc()實作?行程pgd實際使用的物理記憶體在哪里?
- 描述內核pgd的swapper_pg_dir何時init,根據什么引數init,存在哪里?
當創建一個新的行程時,都要為新行程創建一個新的頁面目錄PGD,并從內核的頁面目錄swapper_pg_dir中復制內核區間頁面目錄項至新建行程頁面目錄PGD的相應位置,具體程序如下:
do_fork() –> copy_mm() –> mm_init() –> pgd_alloc() –> set_pgd_fast() –> get_pgd_slow() –> memcpy(&PGD + USER_PTRS_PER_PGD, swapper_pg_dir + USER_PTRS_PER_PGD, (PTRS_PER_PGD - USER_PTRS_PER_PGD) * sizeof(pgd_t))
這樣一來,每個行程的頁面目錄就分成了兩部分,第一部分為“用戶空間”,用來映射其整個行程空間(0x0000 0000-0xBFFF FFFF)即3G位元組的虛擬地址;第二部分為“系統空間”,用來映射(0xC000 0000-0xFFFF FFFF)1G位元組的虛擬地址,可以看出Linux系統中每個行程的頁面目錄的第二部分是相同的,所以從行程的角度來看,每個行程有4G位元組的虛擬空間, 較低的3G位元組是自己的用戶空間,最高的1G位元組則為與所有行程以及內核共享的系統空間,
- copy_from_user()的程序和實作細節?
呼叫copy_from_user(to,from,n),其中to指向內核空間 system_utsname.nodename,譬如0xE625A000,from指向用戶空間譬如0x8010FE00,現在行程A進入了內核,在 系統空間中運行,MMU根據其PGD將虛擬地址完成到物理地址的映射,最終完成從用戶空間到系統空間資料的復制,準備復制之前內核先要確定用戶空間地址和 長度的合法性,至于從該用戶空間地址開始的某個長度的整個區間是否已經映射并不去檢查,如果區間內某個地址未映射或讀寫權限等問題出現時,則視為壞地址, 就產生一個頁面例外,讓頁面例外服務程式處理,程序如 下:copy_from_user()->generic_copy_from_user()->access_ok()+__copy_user_zeroing().
BOOT
深入理解uboot 2016 - 基礎篇(處理器啟動流程分析)
- 系統引導時記憶體管理
bootmem分配器
1 使用一個位圖來管理頁, 以位圖代替原來的空閑鏈表結構來表示存盤空間, 位圖的位元位的數目與系統中物理記憶體頁面數目相同. 若位圖中某一位是1, 則標識該頁面已經被分配(已用頁), 否則表示未被占有(未用頁)
內核啟動時獲取引數方式----Uboot傳遞引數給內核
uboot環境變數(設定bootargs向linux內核傳遞正確的引數
五、build Linux平臺/工具
- buildroot 認識Buildroot buildroot使用介紹
- Yocto
- OpenWRT 從零開始學習OpenWrt完美教程
其他
你知道這些標點符號用英語怎么說嗎?
開發程序管理
1 Agil
2 version control cvs > svn (集中式) > Git (分布式)
clearcase
3 開發程序管理工具
jira系統:
confuence:
21天:
1、專案介紹-TDE
IPCAM
Hi3521/Hi3520
sagemcom
2、leetcode--復習、新題
3、驅動開發技術點(偽碼)--用戶態- 執行緒創建及同步
行程創建及通信
網路特性及socket編程
rtsp/rtp
內核態-同步,互斥
-中斷&BH(tasklet,workqueue)
-行程、執行緒
-字符驅動
-記憶體(內核態分配函式,mmap,驅動記憶體分配)
-system call
-fs
-boot,kernel生成
-除錯技術
4、開發程序-1 Agil
-2 version control cvs > svn (集中式) > Git (分布式)
clearcase
- 3 開發程序管理工具
jira系統:
confuence:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301012.html
標籤:其他