今天帶來一個小小的PyTorch專案,利用PyTorch搭建卷積神經網路完成對CIFAR10資料集的分類
CIFAR10:由 10 個類中的 60000 張 32x32 彩色影像組成,每類 6000 張影像,有50000個訓練影像和10000個測驗影像,資料集分為五個培訓批次和一個測驗批次,每個測驗批次有 10000 張
影像,測驗批次包含來自每個類的 1000 個隨機選擇的影像,培訓批次隨機包含剩余影像,但某些培訓批次可能包含來自一個班級的影像,培訓批次包含每節課的 5000 張圖片
十個類分別是:【飛機,汽車,鳥,貓,鹿,狗,青蛙,馬,船,卡車】

------------------------------------------------------------------------------------------------------------
下面正式開始
首先我們先明確一下總體步驟:Load data->Build Model ->Train->Test
1.Load data
在這里還是利用torchvision.datasets直接完成CIFAR10資料集的下載
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
train_data = torchvision.datasets.CIFAR10(root='./CIFAR10data',train=True,
download=True,transform=transform )
train_loader = torch.utils.data.DataLoader(train_data,batch_size = 4,
shuffle = True,num_workers=2)
test_data = torchvision.datasets.CIFAR10(root='./CIFAR10data',train=False,
download=True,transform=transform)
test_loader = torch.utils.data.DataLoader(test_data,batch_size = 4,
shuffle = False,num_workers=2)在這里我們將對圖片的預處理直接整合好,對于shuffle和num_workers這兩個屬性在說明下:
shuffle:用于打亂資料集,每次以不同資料回傳(這里好像還有不少坑,但是我還沒親自掉里面 過,不過遲早的事,關于shuffle的坑以后有機會在進行詳細闡述)
num_workers:當dataloader加載資料時,一次性創建num_workers個作業行程,并用 batch_sampler將指定batch分配給指定worker,worker將它負責的batch加載進RAM,
(1)num_workers設定的很大:好處是處理速度快,尋找速度快,可以需要的資料之前已經加載過了;壞處就是記憶體開銷大,占用很多記憶體空間,加重CPU負擔
(2)num_workers設定為0:意味著每一輪迭代時,dataloader不再有自主加載資料到RAM這一步驟,而是在RAM中找batch,找不到時再加載相應的batch:缺點是速度降下來了
2.Build Model
定義卷積神經網路模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3,6,5)
self.pool = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(6,16,5)
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1,16*5*5) #拉成向量
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
return x關于Conv2d(),參考了nn.Conv2d卷積_落地生根-CSDN博客
二維卷積可以處理二維資料
nn.Conv2d(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True))
引數:
??in_channel: 輸入資料的通道數,例RGB圖片通道數為3;
??out_channel: 輸出資料的通道數,這個根據模型調整;
??kennel_size: 卷積核大小,可以是int,或tuple;kennel_size=2,意味著卷積大小(2,2), kennel_size=(2,3),意味著卷積大小(2,3)即非正方形卷積
??stride:步長,默認為1,與kennel_size類似,stride=2,意味著步長上下左右掃描皆為2, stride=(2,3),左右掃描步長為2,上下為3;
??padding:對影像矩陣周邊零填充
3.Train
Train之前定義一下優化器和損失函式
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(),lr = 0.001,momentum=0.9) #SGD(傳入引數,學習率,動量)start Training~
for epoch in range(1):
running_loss = 0.0
# 0 用于指定索引起始值
for i, data in enumerate(train_loader, 0):
input, target = data
input, target = Variable(input), Variable(target)
optimizer.zero_grad()
output = net(input)
loss = criterion(output, target) # out 和target的交叉熵損失
loss.backward()
optimizer.step()
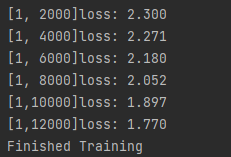
running_loss += loss.data
if i % 2000 == 1999: ## print every 2000 mini_batches,1999,because of index from 0 on
print('[%d,%5d]loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')訓練完畢:
4.Test
dataier = iter(test_loader)
images, labels = dataier.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth:', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
outputs = net(Variable(images))
_, pred = torch.max(outputs.data, 1)
print('Predicted: ', ' '.join('%5s' % classes[pred[j]] for j in range(4)))
correct = 0.0
total = 0
for data in test_loader:
images, labels = data
outputs = net(Variable(images))
_, pred = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (pred == labels).sum()
print('Accuracy of the network on the 10000 test images :%d %%' % (100 * correct / total))這里還定義了一個函式用于展示一下資料集識別的影像
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
# np.transpose :按需求轉置
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
因為CIFAR10中的影像像素都是32*32的,很小,所以這個觀賞效果很模糊,不過大概能看得出來
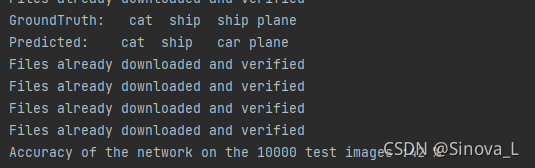
可以看得出來,識別的準確度還是有的,不過樣板資料少,其實真實的識別精度還不是很高
下面是對十類不同物體的分類分析
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
for data in test_loader:
images, labels = data
outputs = net(Variable(images))
_, pred = torch.max(outputs.data, 1)
c = (pred == labels).squeeze() # 1*10000*10-->10*10000
for i in range(4):
label = labels[i]
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))識別的結果會列印在Console
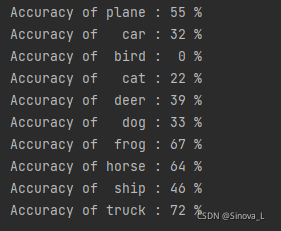 確實不算是很高啊,對于bird的識別竟然是0% !!!!
確實不算是很高啊,對于bird的識別竟然是0% !!!!
每次學習的結果都不一樣,如何正確提高識別精度,我還需要再努力學習!!
最后貼一下完整代碼:
import torch
import torchvision
import torchvision.transforms as transforms
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
#匯入資料并及進行標準化處理,轉換成需要的格式
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
#下載資料
train_data = torchvision.datasets.CIFAR10(root='./CIFAR10data',train=True,
download=True,transform=transform )
train_loader = torch.utils.data.DataLoader(train_data,batch_size = 4,
shuffle = True,num_workers=2)
test_data = torchvision.datasets.CIFAR10(root='./CIFAR10data',train=False,
download=True,transform=transform)
test_loader = torch.utils.data.DataLoader(test_data,batch_size = 4,
shuffle = False,num_workers=2)
classes = ('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
# np.transpose :按需求轉置
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
#定義卷積神經網路模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3,6,5)
self.pool = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(6,16,5)
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1,16*5*5) #拉成向量
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
return x
net = Net()
#定義loss函式和優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(),lr = 0.001,momentum=0.9) #SGD(傳入引數,學習率,動量)
#訓練網路
if __name__ == '__main__':
for epoch in range(1):
running_loss = 0.0
# 0 用于指定索引起始值
for i, data in enumerate(train_loader, 0):
input, target = data
input, target = Variable(input), Variable(target)
optimizer.zero_grad()
output = net(input)
loss = criterion(output, target) # out 和target的交叉熵損失
loss.backward()
optimizer.step()
running_loss += loss.data
if i % 2000 == 1999: ## print every 2000 mini_batches,1999,because of index from 0 on
print('[%d,%5d]loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
dataier = iter(test_loader)
images, labels = dataier.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth:', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
outputs = net(Variable(images))
_, pred = torch.max(outputs.data, 1)
print('Predicted: ', ' '.join('%5s' % classes[pred[j]] for j in range(4)))
correct = 0.0
total = 0
for data in test_loader:
images, labels = data
outputs = net(Variable(images))
_, pred = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (pred == labels).sum()
print('Accuracy of the network on the 10000 test images :%d %%' % (100 * correct / total))
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
for data in test_loader:
images, labels = data
outputs = net(Variable(images))
_, pred = torch.max(outputs.data, 1)
c = (pred == labels).squeeze() # 1*10000*10-->10*10000
for i in range(4):
label = labels[i]
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))
本片只是一味的貼了一下這個分類識別程序中具體實作代碼,對于卷積神經網路的理解以及測驗相關說明還不夠,尤其是對于卷積神經網路中卷積層Conv2d的資料說明還不夠透徹且網路最后識別精度不夠高,學習路漫漫,感覺這期不太含有什么營養,只是簡單的搬運專案代碼
但還是感謝觀看,如果有幫助到您,點個贊再走吧!
如果有錯誤,請立刻指出批評,盡快修改!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301126.html
標籤:其他
上一篇:Yolov5—nano部署
下一篇:Python修改圖片大小