
文 | 閑歡
來源:Python 技術「ID: pythonall」

對于學習 Python 爬蟲的人來說,Scrapy 這個框架是一個繞不過去的檻,它是一個非常重量級的 Python 爬蟲框架,如果你想要做一些復雜的爬蟲專案,可能就需要用到它,
但是,由于 Scrapy 框架很復雜,它的學習成本也非常高,學習的道路上布滿了很多坑,并且都很難找到解決辦法,對于初學者來說,學習 Scrapy 框架需要極大的耐心和勇氣,一般人很有可能在中途就放棄了,

不要擔心,既然有痛點,肯定就有人來撫慰,今天給大家介紹一個類似于 Scrapy 的開源爬蟲框架——feapder,它的架構邏輯和 Scrapy 類似,但是學習成本非常低,不需要繁瑣的配置,不需要復雜的專案架構,也可以輕松應對復雜爬蟲需求,
簡介
feapder 是一款上手簡單,功能強大的 Python 爬蟲框架,使用方式類似 scrapy,方便由 scrapy 框架切換過來,框架內置三種爬蟲:
AirSpider 爬蟲比較輕量,學習成本低,面對一些資料量較少,無需斷點續爬,無需分布式采集的需求,可采用此爬蟲,
Spider 是一款基于 redis 的分布式爬蟲,適用于海量資料采集,支持斷點續爬、爬蟲報警、資料自動入庫等功能
BatchSpider 是一款分布式批次爬蟲,對于需要周期性采集的資料,優先考慮使用本爬蟲,
feapder 支持斷點續爬、資料防丟、監控報警、瀏覽器渲染下載、資料自動入庫 Mysql 或 Mongo,還可通過撰寫 pipeline 對接其他存盤,
今天我主要介紹一下 AirSpider 這種爬蟲,
安裝
通用版
pip3 install feapder
完整版:
pip3 install feapder[all]
通用版與完整版區別在于完整版支持基于記憶體去重,
AirSpider 使用
我們今天通過爬取東方財富網的股票研報資料(http://data.eastmoney.com/report/stock.jshtml)來講解怎樣使用 AirSpider 進行資料爬取,
創建爬蟲
創建爬蟲的陳述句跟 Scrapy 類似:
feapder create -s report_spider
運行完成后,就會在當前目錄下生成一個 report_spider.py 的檔案,打開檔案后,我們可以看到一個初始化的代碼:
import feapder
class ReportSpider(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
ReportSpider().start()這代碼是可以直接運行的,運行之后,你會看到控制臺資訊:

默認生成的代碼繼承了feapder.AirSpider,包含 start_requests 及 parser 兩個函式,含義如下:
feapder.AirSpider:輕量爬蟲基類,
start_requests:初始任務下發入口,
feapder.Request:基于requests庫類似,表示一個請求,支持requests所有引數,同時也可攜帶些自定義的引數,
parser:資料決議函式,
response:請求回應的回傳體,支持xpath、re、css等決議方式,
自定義決議函式
開發程序中決議函式往往不止有一個,除了系統默認的parser外,還支持自定義決議函式,比如我要寫一個自己的決議函式,寫法如下:
def start_requests(self):
yield feapder.Request("http://reportapi.eastmoney.com/report/list?cb=datatable1351846&industryCode=*&pageSize=50&industry=*&rating=&ratingChange=&beginTime=2021-09-13&endTime=2021-09-14&pageNo=1&fields=&qType=0&orgCode=&code=*&rcode=&p=2&pageNum=2&_=1603724062679",
callback=self.parse_report_info)
def parse_report_info(self, request, response):
html = response.content.decode("utf-8")
if len(html):
content = html.replace('datatable1351846(', '')[:-1]
content_json = json.loads(content)
print(content_json)只需要在 Request 請求中加個 callback 引數,將自定義決議函式名放進去即可,
攜帶引數
如果你需要將請求中的一些引數帶到決議函式中,你可以這樣做:
def start_requests(self):
yield feapder.Request("http://reportapi.eastmoney.com/report/list?cb=datatable1351846&industryCode=*&pageSize=50&industry=*&rating=&ratingChange=&beginTime=2021-09-13&endTime=2021-09-14&pageNo=1&fields=&qType=0&orgCode=&code=*&rcode=&p=2&pageNum=2&_=1603724062679",
callback=self.parse_report_info, pageNo=1)
def parse_report_info(self, request, response):
print(request.pageNo)
html = response.content.decode("utf-8")
if len(html):
content = html.replace('datatable1351846(', '')[:-1]
content_json = json.loads(content)
print(content_json)在 Request 里面添加你需要攜帶的引數,在決議函式中通過 request.xxx 就可以獲取到(本例中我將請求的頁碼 pageNo 作為攜帶引數傳遞到決議函式中,運行程式就可以看到列印了1),
下載中間件
下載中間件用于在請求之前,對請求做一些處理,如添加cookie、header等,寫法如下:
def download_midware(self, request):
request.headers = {
"Connection": "keep-alive",
"Cookie": "qgqp_b_id=0f1ac887e1e3e484715bf0e3f148dbd8; intellpositionL=1182.07px; st_si=32385320684787; st_asi=delete; cowCookie=true; intellpositionT=741px; st_pvi=73966577539485; st_sp=2021-03-22%2009%3A25%3A40; st_inirUrl=https%3A%2F%2Fwww.baidu.com%2Flink; st_sn=4; st_psi=20210914160650551-113300303753-3491653988",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36",
"Host": "reportapi.eastmoney.com"
}
return request這里我主要添加了一些請求頭資訊,模擬真實瀏覽器訪問場景,
校驗
校驗函式, 可用于校驗 response 是否正確,若函式內拋出例外,則重試請求,若回傳 True 或 None,則進入決議函式,若回傳 False,則拋棄當前請求,可通過 request.callback_name 區分不同的回呼函式,撰寫不同的校驗邏輯,
def validate(self, request, response):
if response.status_code != 200:
raise Exception("response code not 200") # 重試失敗重試機制
框架支持重試機制,下載失敗或決議函式拋出例外會自動重試請求,默認最大重試次數為100次,我們可以引入組態檔或自定義配置來修改重試次數,上面的校驗中,我們拋出例外,就可以觸發重試機制,
爬蟲配置
爬蟲配置支持自定義配置或引入組態檔 setting.py 的方式,我們只需要在當前目錄下映入 setting.py 就可以了,我們可以在配置里面配置 資料庫資訊、Redis 資訊、日志資訊等等,
這里給出一份最全的配置:
import os
# MYSQL
MYSQL_IP = ""
MYSQL_PORT = 3306
MYSQL_DB = ""
MYSQL_USER_NAME = ""
MYSQL_USER_PASS = ""
# REDIS
# IP:PORT
REDISDB_IP_PORTS = "xxx:6379"
REDISDB_USER_PASS = ""
# 默認 0 到 15 共16個資料庫
REDISDB_DB = 0
# 資料入庫的pipeline,可自定義,默認MysqlPipeline
ITEM_PIPELINES = ["feapder.pipelines.mysql_pipeline.MysqlPipeline"]
# 爬蟲相關
# COLLECTOR
COLLECTOR_SLEEP_TIME = 1 # 從任務佇列中獲取任務到記憶體佇列的間隔
COLLECTOR_TASK_COUNT = 100 # 每次獲取任務數量
# SPIDER
SPIDER_THREAD_COUNT = 10 # 爬蟲并發數
SPIDER_SLEEP_TIME = 0 # 下載時間間隔 單位秒, 支持隨機 如 SPIDER_SLEEP_TIME = [2, 5] 則間隔為 2~5秒之間的亂數,包含2和5
SPIDER_MAX_RETRY_TIMES = 100 # 每個請求最大重試次數
# 瀏覽器渲染下載
WEBDRIVER = dict(
pool_size=2, # 瀏覽器的數量
load_images=False, # 是否加載圖片
user_agent=None, # 字串 或 無參函式,回傳值為user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 無參函式,回傳值為代理地址
headless=False, # 是否為無頭瀏覽器
driver_type="CHROME", # CHROME 或 PHANTOMJS,
timeout=30, # 請求超時時間
window_size=(1024, 800), # 視窗大小
executable_path=None, # 瀏覽器路徑,默認為默認路徑
render_time=0, # 渲染時長,即打開網頁等待指定時間后再獲取原始碼
)
# 重新嘗試失敗的requests 當requests重試次數超過允許的最大重試次數算失敗
RETRY_FAILED_REQUESTS = False
# request 超時時間,超過這個時間重新做(不是網路請求的超時時間)單位秒
REQUEST_LOST_TIMEOUT = 600 # 10分鐘
# 保存失敗的request
SAVE_FAILED_REQUEST = True
# 下載快取 利用redis快取,由于記憶體小,所以僅供測驗時使用
RESPONSE_CACHED_ENABLE = False # 是否啟用下載快取 成本高的資料或容易變需求的資料,建議設定為True
RESPONSE_CACHED_EXPIRE_TIME = 3600 # 快取時間 秒
RESPONSE_CACHED_USED = False # 是否使用快取 補采資料時可設定為True
WARNING_FAILED_COUNT = 1000 # 任務失敗數 超過WARNING_FAILED_COUNT則報警
# 爬蟲是否常駐
KEEP_ALIVE = False
# 設定代理
PROXY_EXTRACT_API = None # 代理提取API ,回傳的代理分割符為\r\n
PROXY_ENABLE = True
# 隨機headers
RANDOM_HEADERS = True
# requests 使用session
USE_SESSION = False
# 去重
ITEM_FILTER_ENABLE = False # item 去重
REQUEST_FILTER_ENABLE = False # request 去重
# 報警 支持釘釘及郵件,二選一即可
# 釘釘報警
DINGDING_WARNING_URL = "" # 釘釘機器人api
DINGDING_WARNING_PHONE = "" # 報警人 支持串列,可指定多個
# 郵件報警
EMAIL_SENDER = "" # 發件人
EMAIL_PASSWORD = "" # 授權碼
EMAIL_RECEIVER = "" # 收件人 支持串列,可指定多個
# 時間間隔
WARNING_INTERVAL = 3600 # 相同報警的報警時間間隔,防止刷屏; 0表示不去重
WARNING_LEVEL = "DEBUG" # 報警級別, DEBUG / ERROR
LOG_NAME = os.path.basename(os.getcwd())
LOG_PATH = "log/%s.log" % LOG_NAME # log存盤路徑
LOG_LEVEL = "DEBUG"
LOG_COLOR = True # 是否帶有顏色
LOG_IS_WRITE_TO_CONSOLE = True # 是否列印到控制臺
LOG_IS_WRITE_TO_FILE = False # 是否寫檔案
LOG_MODE = "w" # 寫檔案的模式
LOG_MAX_BYTES = 10 * 1024 * 1024 # 每個日志檔案的最大位元組數
LOG_BACKUP_COUNT = 20 # 日志檔案保留數量
LOG_ENCODING = "utf8" # 日志檔案編碼
OTHERS_LOG_LEVAL = "ERROR" # 第三方庫的log等級各位自己可以從這些配置中選一些自己需要的進行配置,
資料入庫
框架內封裝了MysqlDB、RedisDB,與pymysql不同的是,MysqlDB 使用了執行緒池,且對方法進行了封裝,使用起來更方便,RedisDB 支持 哨兵模式、集群模式,
如果你在 setting 檔案中配置了資料庫資訊,你就可以直接使用:
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.db = MysqlDB()如果沒有配置,你也可以在代碼里面進行配置:
db = MysqlDB(
ip="localhost",
port=3306,
user_name="feapder",
user_pass="feapder123",
db="feapder"
)建立資料庫連接后,你就可以使用這個框架內置的資料庫增刪改查函式進行資料庫操作了,具體方法可以根據代碼提示來查看:
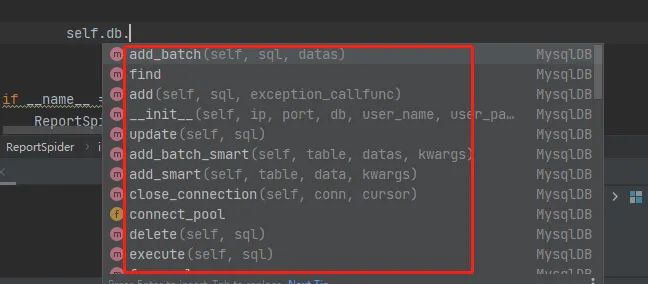
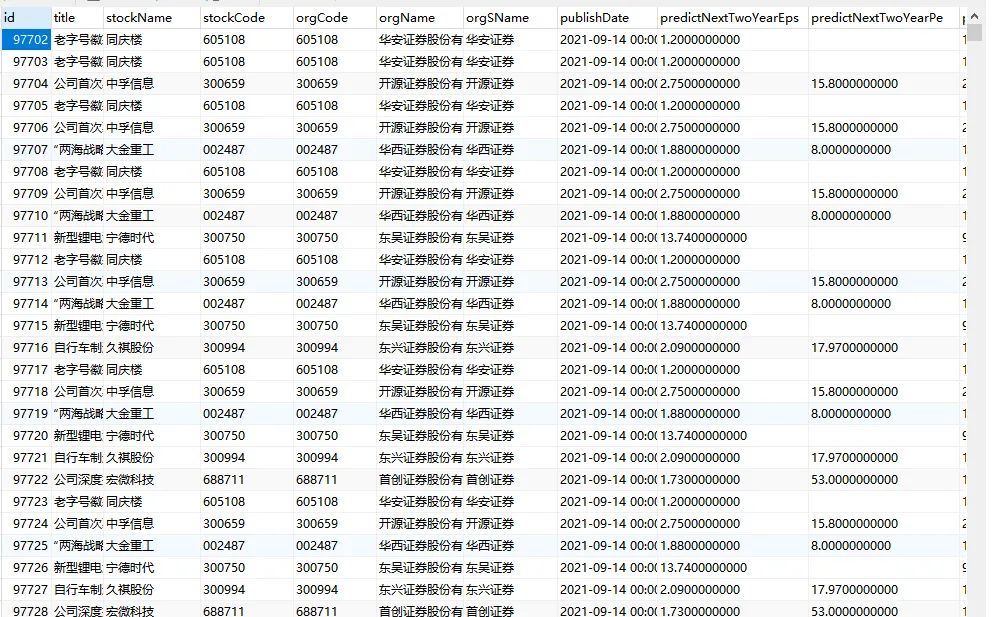
我們的示例程式,運行之后,就可以在資料表中看到資料了:
總結
今天主要給大家介紹了一下 feadper 框架的三劍客之一——AirSpider,這是這個框架最簡單的一種爬蟲方式,也是最容易入門的,當然,今天介紹的每一項里面還有一些更細節的東西,由于篇幅原因,這里沒有介紹,大家可以自己去探索和發現,碼文不易,點個在看送鼓勵~
PS:公號內回復「Python」即可進入Python 新手學習交流群,一起 100 天計劃!
老規矩,兄弟們還記得么,右下角的 “在看” 點一下,如果感覺文章內容不錯的話,記得分享朋友圈讓更多的人知道!

【代碼獲取方式】
識別文末二維碼,回復:閑歡

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301234.html
標籤:其他