HBase概述
- HBase是一個高可靠、高性能、面向列、可伸縮的分布式資料庫
- 是谷歌Big Table的開源實作,主要用來存盤非結構化和半結構化的松散資料
Hadoop
-
Hadoop是什么
- Hadoop是一個開源的可運行于大規模集群上的分布式檔案系統和運行處理基礎框架
- Hadoop擅長于在廉價機器搭建的集群上進行海量資料(結構化與非結構化)的存盤與離線處理,
- Hadoop就是一種用來處理大資料的技術,用來解決并行計算與分布式計算中的技術難題,
-
Hadoop的發展
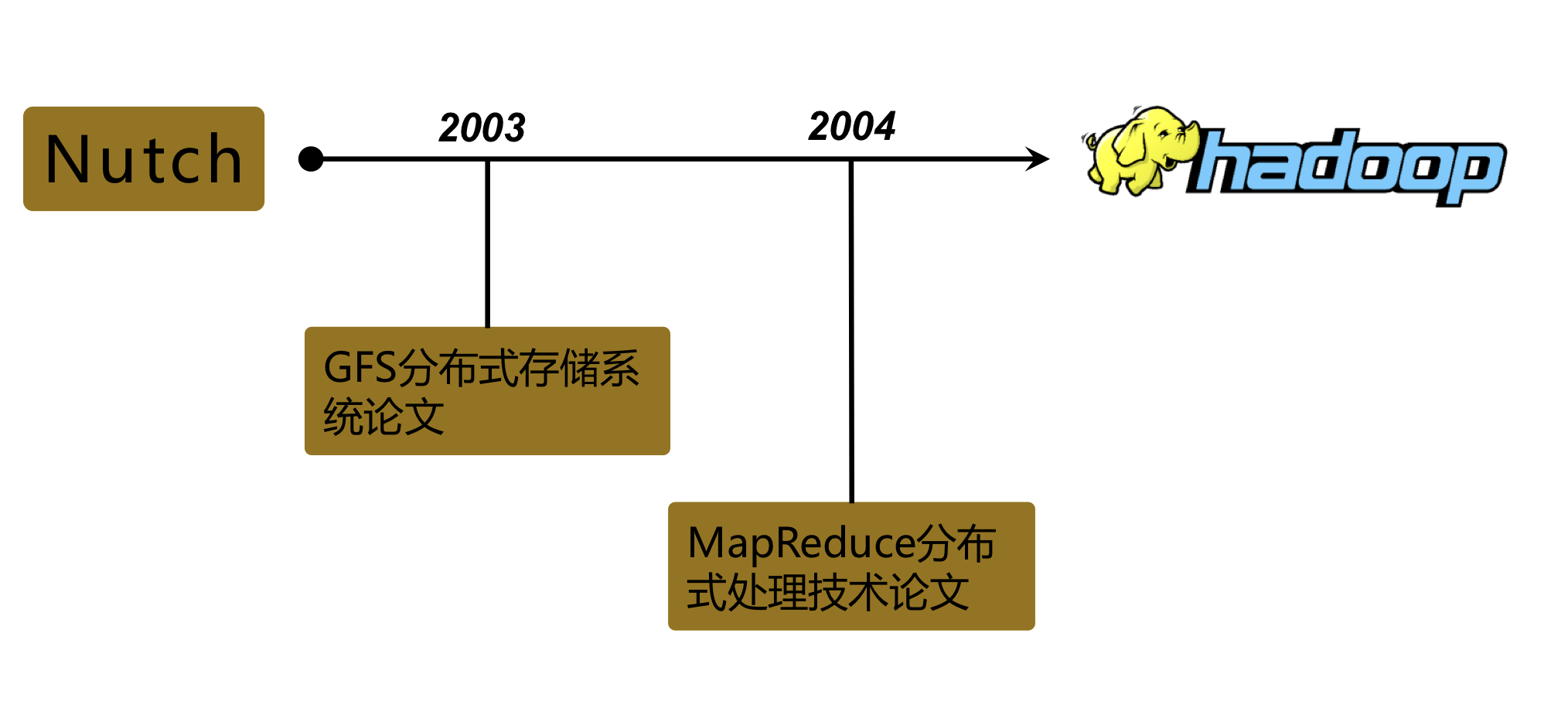
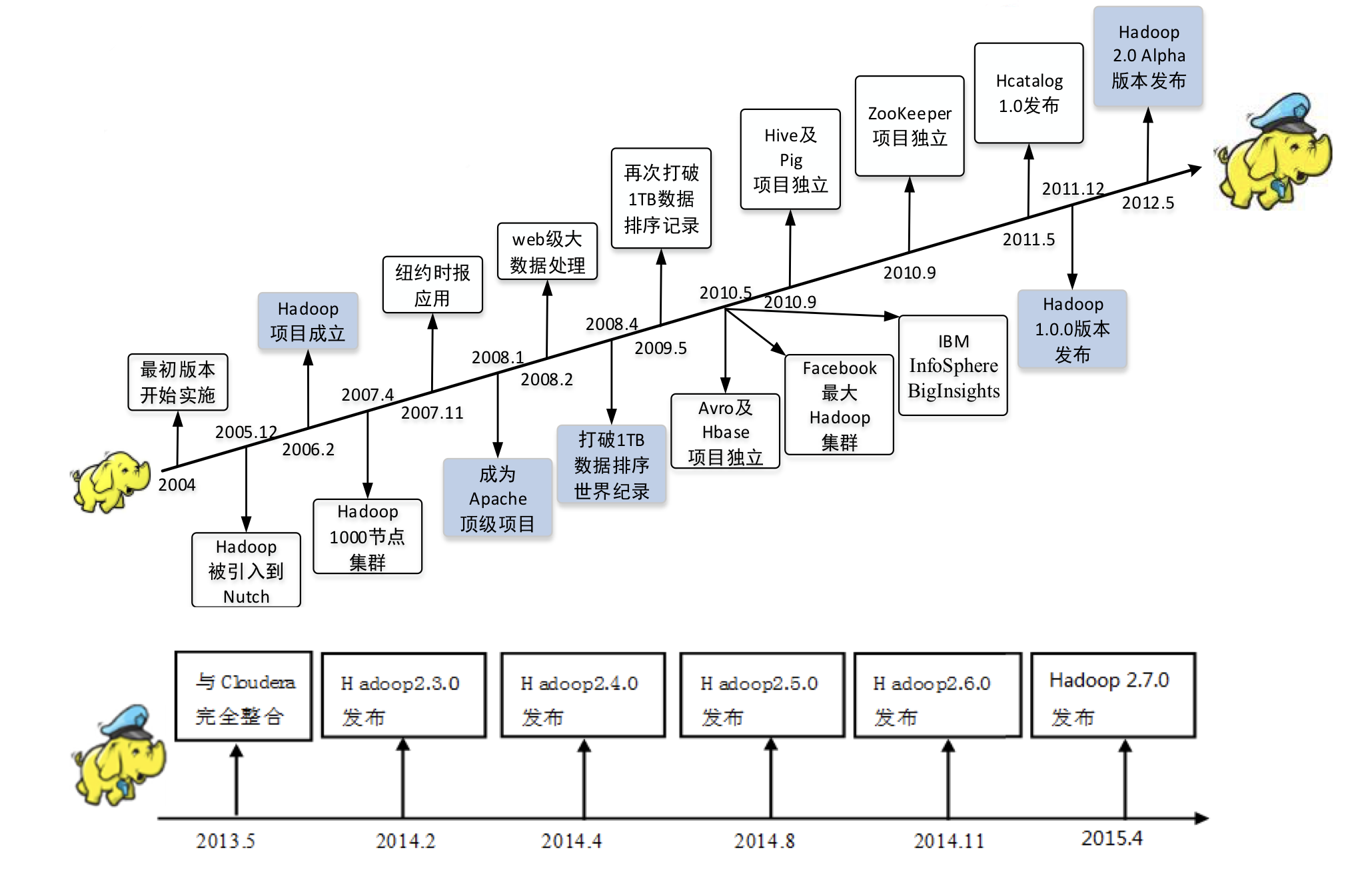
-
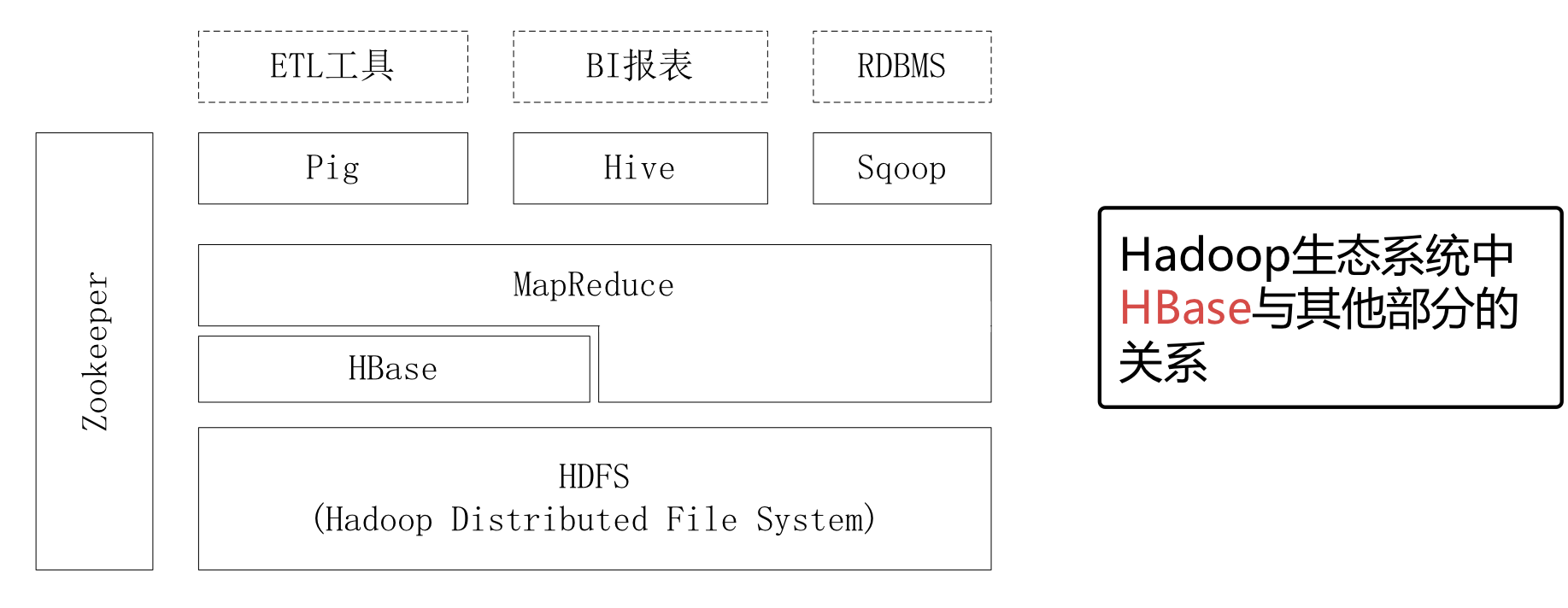
HBase所處系統生態概況
- Hadoop是一個能夠對大量資料進行分布式處理的軟體框架
- 具有可靠、高效、可伸縮的特點
- Hadoop的核心是HDFS和Mapreduce
- HDFS是Hadoop分布式檔案系統,用于將資料存盤在Hadoop集群上,
- Mapreduce是為集群提供Mapreduce功能的YARN應用程式框架
- YARN是另一種資源管理器,它為集群提供所有的調度和資源管理
HDFS
-
Hadoop分布式檔案系統即Hadoop Distributed File System
- 源自Google的GFS論文,HDFS是GFS開源版
- 是Hadoop體系中資料存盤管理的基礎,是一個高度容錯的系統,能檢測和應對硬體故障,用于在低成本的通用硬體上運行,
- HDFS簡化了檔案的一致性模型,通過流式資料訪問,提供高吞吐量應用程式資料訪問功能,適合帶有大型資料集的應用程式,
-
HDFS組成部分
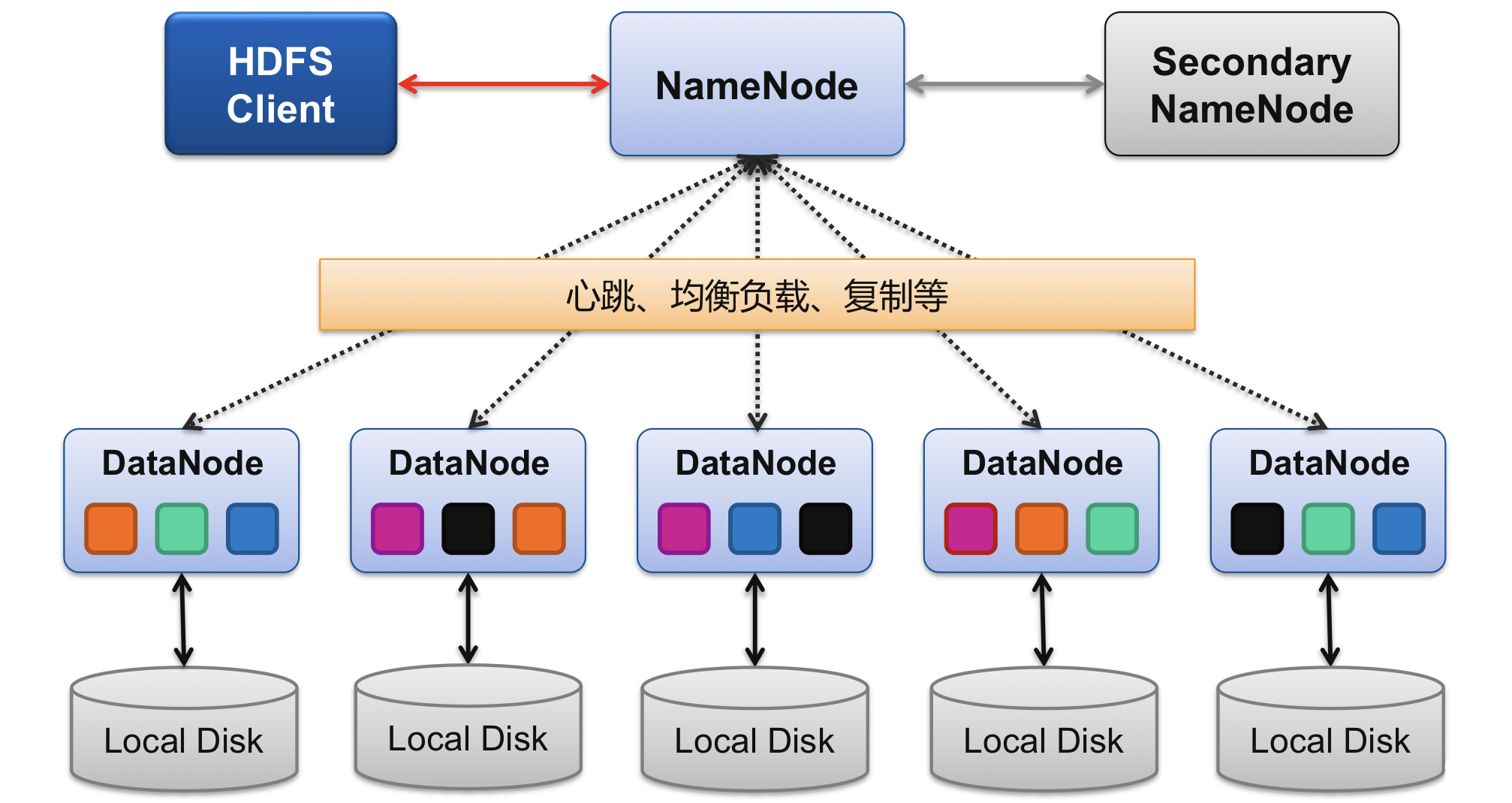
- Client:切分檔案;訪問HDFS;與NameNode互動,獲取檔案位置資訊;與DataNode互動,讀取和寫入資料,
- NameNode:Master節點,在hadoop1.X中只有一個,管理HDFS的名稱空間和資料塊映射資訊,配置副本策略,處理客戶端請求,
- DataNode:Slave節點,存盤實際的資料,匯報存盤資訊給NameNode
- Secondary NameNode:輔助NameNode,分擔其作業量;定期合并fsimage和fsedits,推送給NameNode;緊急情況下,可輔助恢復NameNode,但Secondary NameNode并非NameNode的熱備份
-
HDFS架構
- Active NameNode:主Master(只有一個),管理HDFS的名稱空間,管理資料塊映射資訊,配置副本策略;處理客戶端讀寫請求,
- Secondary NameNode:NameNode的備份,當Active NameNode出現故障時,快速切換為新的Active NameNode
- Datanode:Slave(有多個);存盤實際的資料塊;執行資料塊讀/寫
- Client:與NameNode互動,獲取檔案位置資訊;與DataNode互動,讀入或寫入資料,
MapReduce
-
并行計算框架:MapReduce
- 一個處理和生成超大資料集的演算法模型的相關實作
- 任務的分解與結果的匯總
-
程式員只要按照這個框架的要求,
- 設計Map和Reduce函式,分布式存盤、節點調度、負載均衡、節點通訊、容錯處理和故障和恢復等操作都由MapReduce框架自動完成
- 設計的程式有很高的擴展性
-
MapReduce程式流圖
-
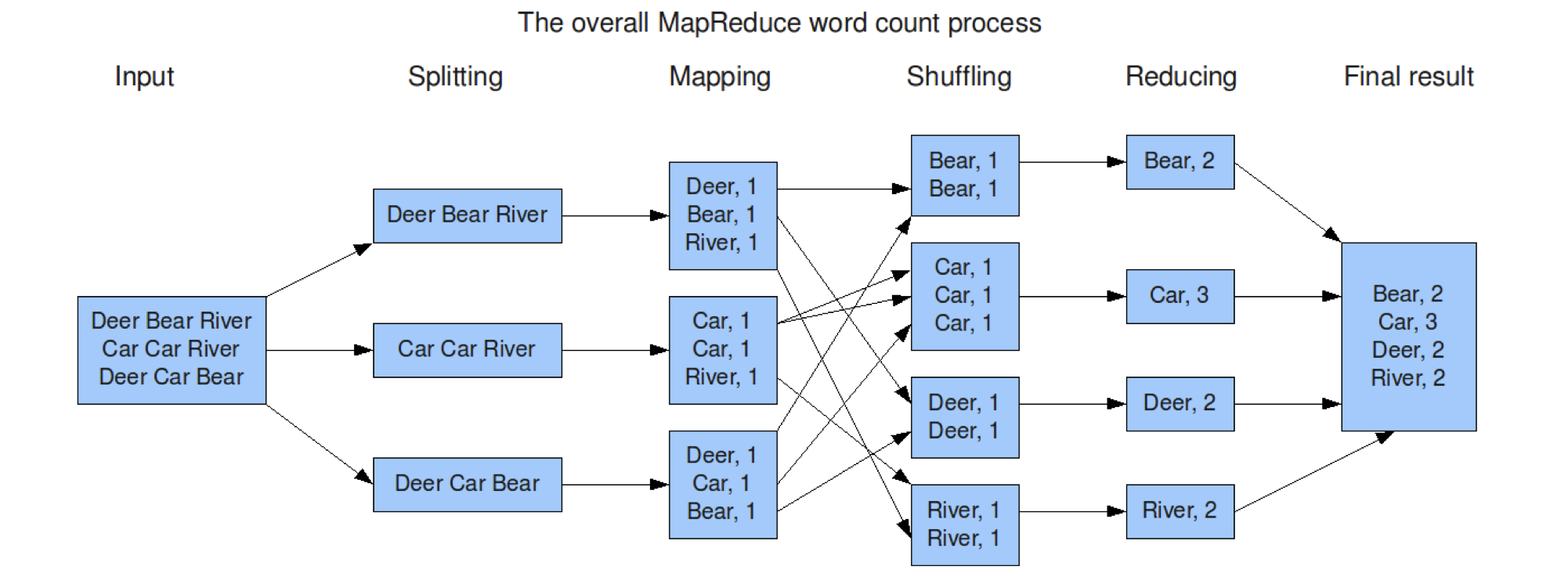
MapReduce實體:Wordcount
- 一批檔案(規模為TB級或者PB級),如何統計這些檔案中所有單詞出現的次數
- 方案:首先,分別統計每個檔案中單詞出現的次數,然后累加不同檔案中同一個單詞出現的次數
-
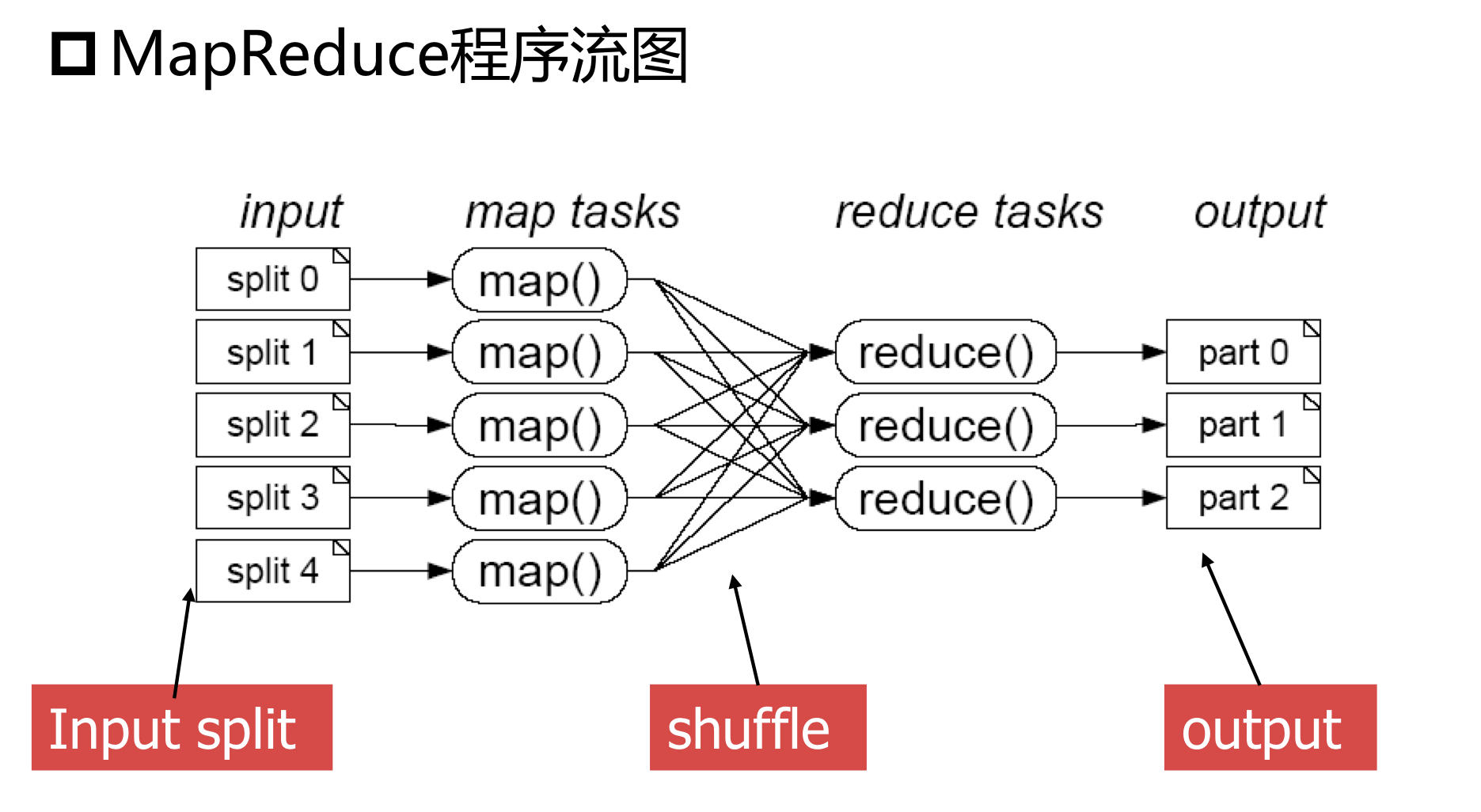
MapReduce將作業的整個運行程序分為兩個階段
- Map階段和Reduce階段
- Map階段由一定數量的Map Task組成
- 輸入資料格式決議:InputFormat
- 輸入資料處理:Mapper
- 資料分組:Partitioner
- Reduce階段由一定數量的Reduce Task組成
- 資料遠程拷貝
- 資料按照key排序
- 資料處理:Reducer
- 資料輸出格式:OutputFormat
-
處理流程
- 讀入資料:(key, value)對的記錄格式資料
- Map:從每個記錄里提取一些資料
- map(in_key, in_value) -> list(out_key, intermediate_value)
- 處理input key/ value pair
- 輸出中間結果key/ value pairs
- Shuffle:混排交換資料,把相同key的中間結果匯集到相同節點上
- Reduce:aggregate, summarize, filter, etc
- reduce(out_key, list(intermediate_value)) -> list(out_value)
- 歸并某一個key的所有values, 進行計算
- 輸出合并的計算結果(usually just one)
- 輸出結果
-
示例:Wordcount
-
輸入:one document per record
-
用戶實作map function,輸入為
- key = document URL
- value = document contents
-
map輸出(potentially many)key/ value pairs
- 對document中每一個出現的詞,輸出一個記錄<word, “1”>
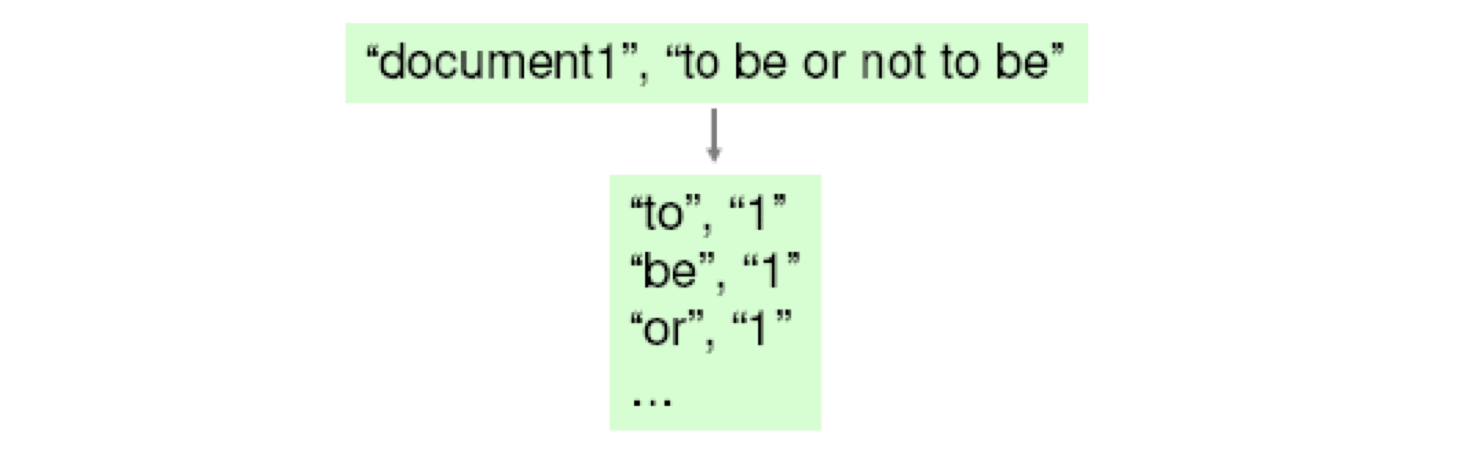
- 對document中每一個出現的詞,輸出一個記錄<word, “1”>
-
MapReduce運行系統(庫)把所有相同key的記錄收集到一起(shuffle/sort)
-
用戶實作reduce function對一個key對應的values計算
- 求和sum

- 求和sum
-
Reduce輸出<key, sum>
-
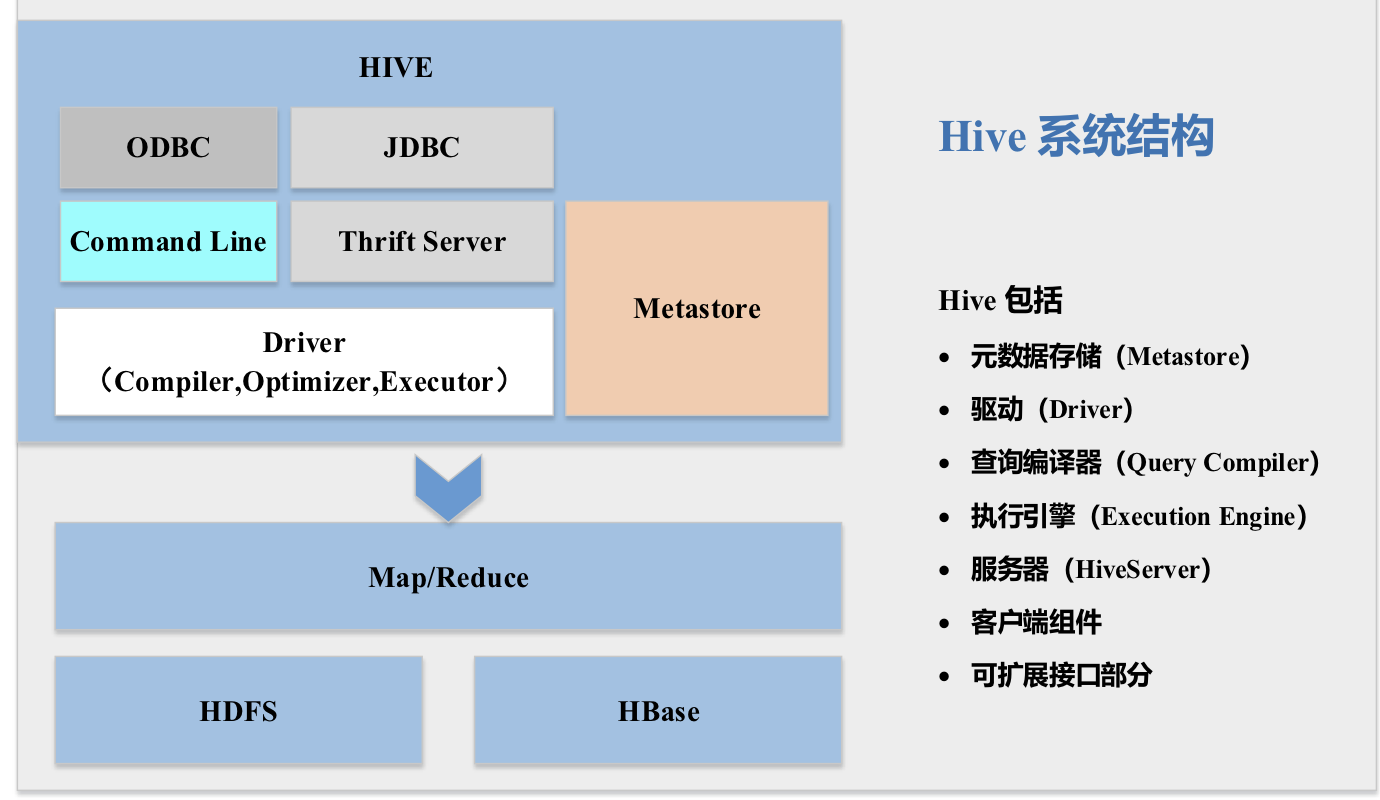
Hive
- Hive(基于Hadoop的資料倉庫)
- Hive由Facebook開源,最初用于解決海量結構化的日志資料統計問題
- Hive定義了一種類似SQL的查詢語言(HQL),將SQL轉化為MapReduce任務在Hadoop上執行
- 通常用于離線分析
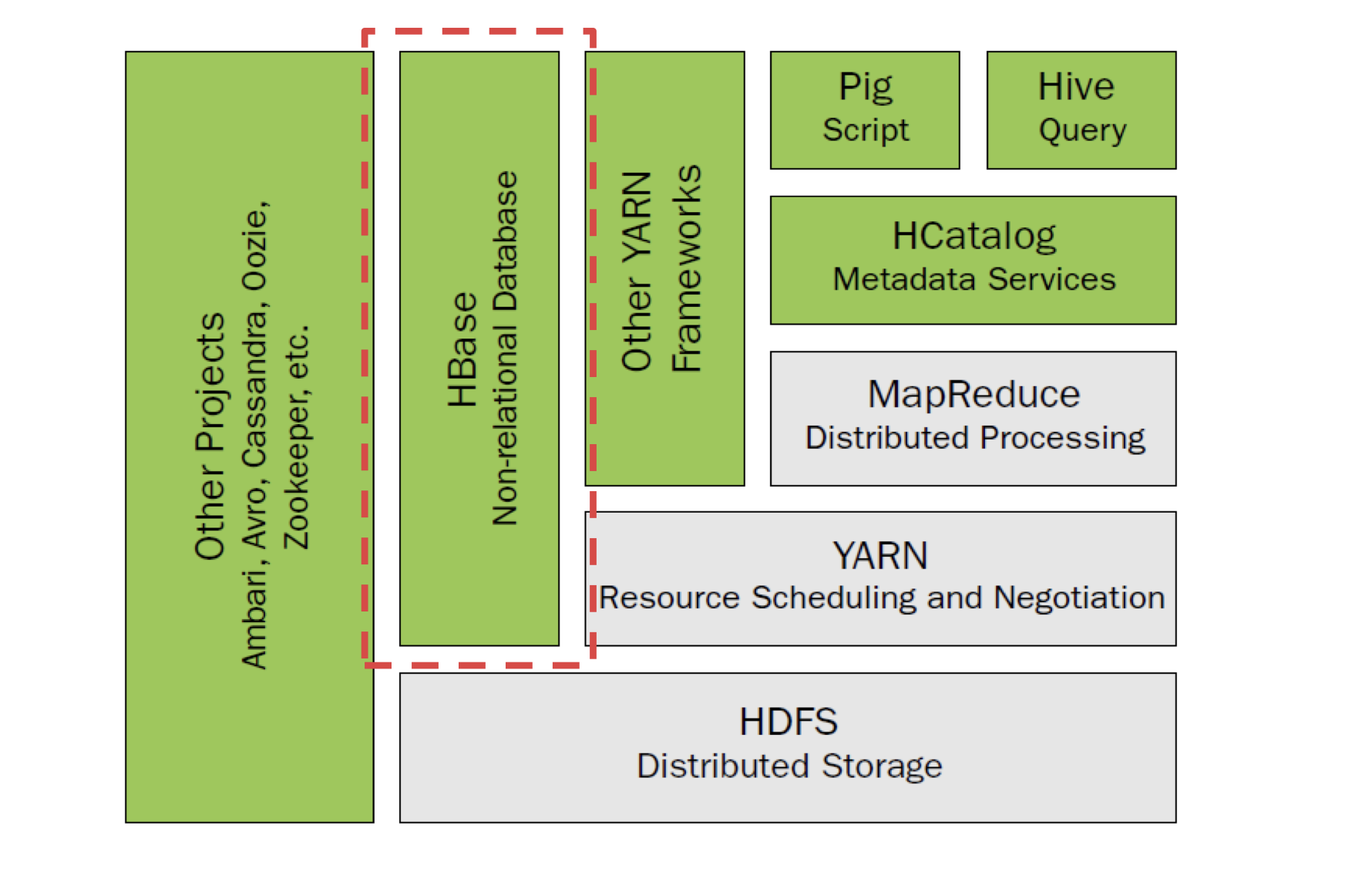
YARN
- 資源調度YARN(Yet Another Resource Negotiator)
- 應用程式框架是專門為YARN環境撰寫的應用程式
- YARN支持如下應用程式框架
- MapReduce
- Apache Giraph(圖形處理)
- Apache Spark(記憶體中處理)
- Apache Storm(流處理)
- 其它應用程式
其它組件
- Zookeeper(分布式協作服務)
- 源自Google的Chubby論文,發表于2006年11月,Zookeeper是Chubby克隆版
- 解決分布式環境下的資料管理問題:狀態同步,集群管理,配置同步等
- Sqoop(資料同步工具)
- Sqoop是SQL-to-Hadoop的縮寫,主要用于傳統資料庫和Hadoop之間傳輸資料
- 資料的匯入/匯出本質上是Mapreduce程式,充分利用了MR的并行化/容錯性
- Pig(基于Hadoop的資料流系統)
- 由yahoo!開源,設計動機是提供一種基于MapReduce的ac-hoc(計算在query時發生)資料分析工具
- 通常用于進行離線分析
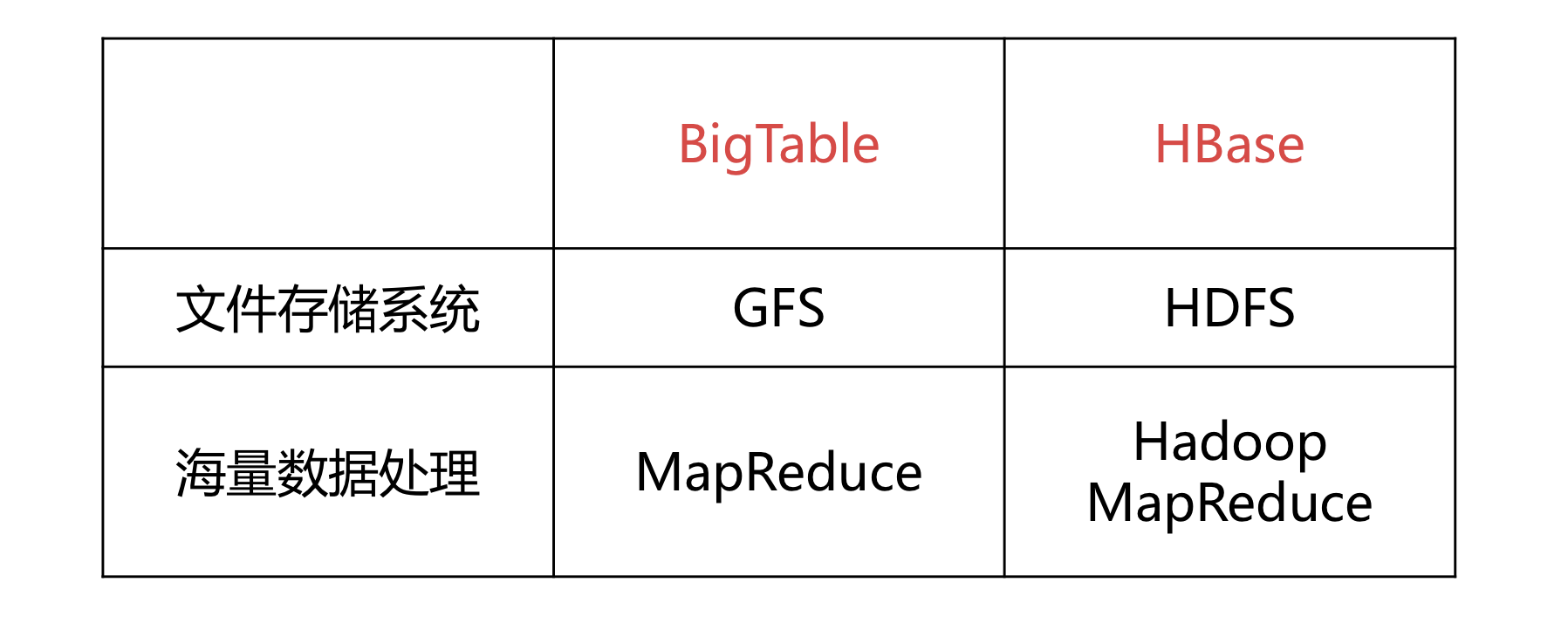
HBase和BigTable的底層技術對應關系
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301237.html
標籤:其他
上一篇:MySQL資料庫基礎操作
下一篇:【SpringBoot集成ElasticSearch 02】使用 spring-boot-starter-data-elasticsearch 集成并使用高級客戶端