文章目錄
- 1 Spark引數優化
- 1.1 num-executors
- 1.2 executor-memory
- 1.3 executor-cores
- 1.4 driver-memory
- 1.5 spark.default.parallelism
- 1.6 spark.shuffle.memoryFraction
- 1.7 spark.storage.memoryFraction
- 1.8 資源參考示例
- 2 RDD優化
- 2.1 RDD 復用
- 2.2 RDD 持久化
- 2.3 RDD 過濾
- 3 算子優化
- 4 Shuffle優化
- 5 資料傾斜優化
- 5.1 增大key的粒度
- 5.2 過濾導致傾斜的key
- 5.3 使用隨機的key
- 5.4 map join
- 5.5 序列化優化
- 5.6 廣播變數優化
1 Spark引數優化
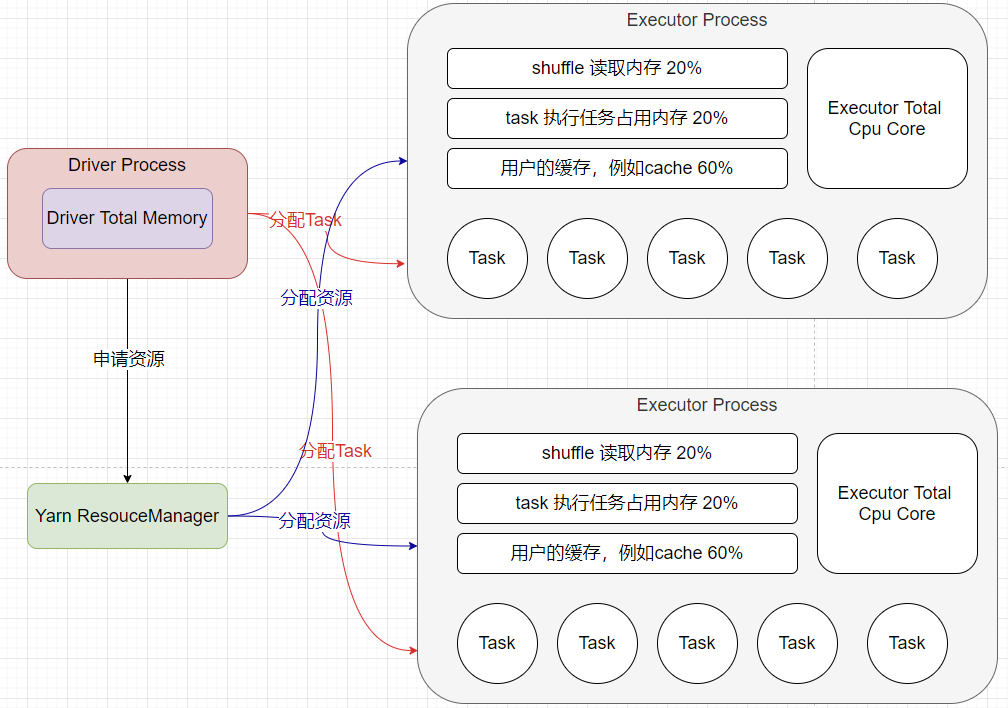
Executor端的記憶體主要分為三塊:第一塊就是讓Task執行我們自己撰寫的代碼時使用,默認占用總記憶體的20%;第二塊是讓task通過shuffle程序拉取上一個stage的task的輸出后,進行聚合等操作時使用,默認也是占用總記憶體的20%;第三塊是讓RDD持久化時使用,默認占用總記憶體的60%,
1.1 num-executors
引數建議:一般每個Spark作業的運行一般設定50~100個左右的Executor行程比較合適,設定太多和太少都不合適,太少的話,無法有效充分利用集群資源,太多的話,Yarn無法基于充分的資源,只能陷入等待或終止,
1.2 executor-memory
引數建議:一般每個Executor的記憶體設定為4G~8G,這里給的是一個參考值,還是得具體情況具體分析,num-exeutors*executor-memory應該等于你能夠呼叫的所有記憶體,如果是團隊公用的記憶體,那么最好不要超過最大記憶體的1/3 - 1/2
1.3 executor-cores
引數建議:一般每個Executor的cpu cores 數量設定2~4個較為合適,這里給的是一個參考值,還是得具體情況具體分析,num-exeutors*executor-cores應該等于你能夠呼叫的所有核數,如果是團隊公用的資源,那么最好不要超過最大核數的1/3 - 1/2
1.4 driver-memory
引數建議:一般默認就行,1G夠用了,但是如果在程式中使用了大的集合,或者呼叫collect算子,需要將driver-memory設定的大一點,否則很容易就溢位了,即OOM,
1.5 spark.default.parallelism
引數建議:Spark官網建議的設定原則:設定引數為num-exeutors*executor-cores的2-3倍,比如Executor的總CPU cores為300(75個executor*4個executor-cores),那么設定為1000個task是可以的,可以充分利用集群資源
1.6 spark.shuffle.memoryFraction
默認0.2(20%),如果shuffle操作較多,可以調高該記憶體值
1.7 spark.storage.memoryFraction
默認0.6(60%),如果你的快取的RDD比較多,可以調高該記憶體值
1.8 資源參考示例
bin/spark-submit \
--master yarn \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.shuffle.memoryFraction=0.3 \
--conf spark.storage.memoryFraction=0.5
2 RDD優化
2.1 RDD 復用
val filter1: RDD[(String, Int)] = words.map((_,1)).filter(_._1%2==0)
val filter2: RDD[(String, Int)] = words.map((_,1)).filter(_._1%2==1)
filter1.union(filter2).collect
val maprdd: RDD[(String, Int)] = words.map((_,1))
val filter1: RDD[(String, Int)] = maprdd.filter(_._1%2==0)
val filter2: RDD[(String, Int)] = maprdd.filter(_._1%2==1)
filter1.union(filter2).collect
2.2 RDD 持久化
對于多次用到的rdd最好進行持久化,減少計算次數
rdd.cache()
rdd.persist(StorageLevel.MEMORY_ONLY)
2.3 RDD 過濾
為了減少資料量,資料如果能提前過濾就提前過濾
3 算子優化
- mapPartitions:包裹在map外
- foreachPartition:包裹在foreach外,用于寫庫操作,創建連接
- filter+coalesce:過濾后資料分配不均勻,需要重磁區操作,多磁區變少磁區
- repartition:當少磁區邊多磁區的時候,和coalesce效果一樣
- reduceByKey本地聚合:能用reduceByKey的時候盡量不要使用groupByKey
4 Shuffle優化
spark shuffle演進的歷史
- Spark 0.8及以前Hash Based Shuffle
- Spark 0.8.1為Hash Based Shuffle引入File Consolidation機制
- Spark 0.9引入ExternalAppendOnlyMap
- Spark 1.1引入Sort Based Shuffle,但默認仍為Hash Based Shuffle
- Spark 1.2默認的Shuffle方式改為Sort Based Shuffle
- Spark 1.4引入Tungsten-Sort Based Shuffle
- Spark 1.6 Tungsten-sort并入Sort Based Shuffle. Spark 2.0 Hash Based Shuffle退出歷史舞臺
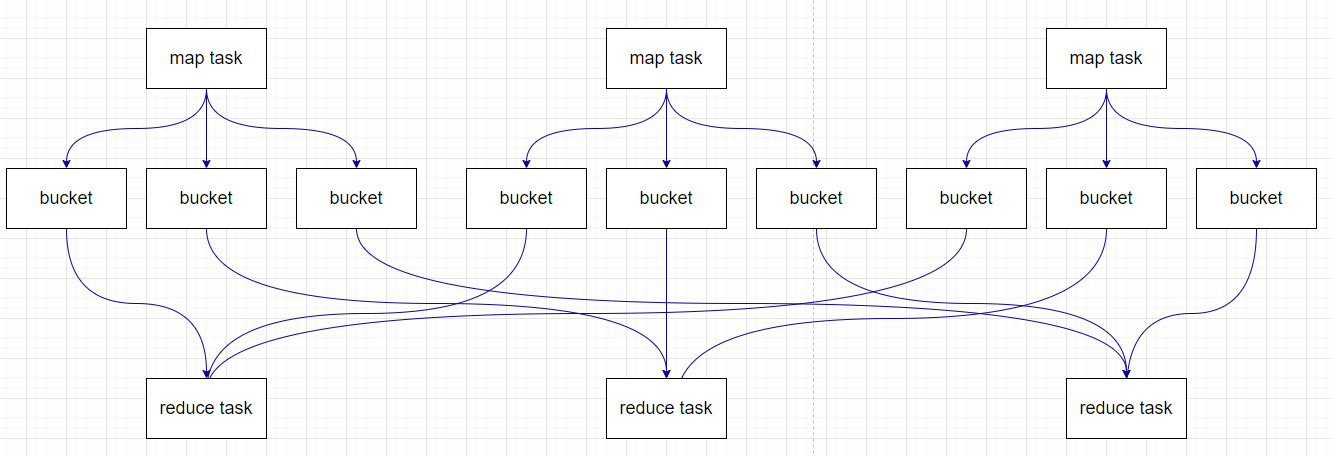
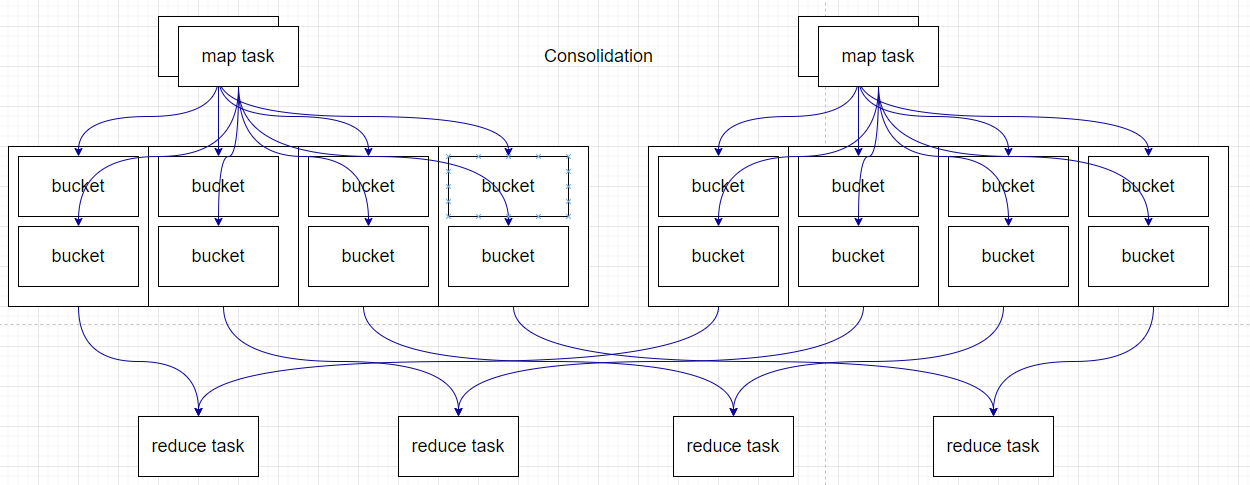
在之后引入了Sort Base Shuffle,map端會按照partitionId以及key對記錄進行排序,同時將全部結果寫到一個檔案中,同時帶有一個索引檔案,
5 資料傾斜優化
5.1 增大key的粒度
比如原來的key是(省份+城市),那么我們在滿足業務需求的前提下可以將key改為(省份),可以減少資料傾斜發生的概率
5.2 過濾導致傾斜的key
有時候資料傾斜是因為業務欄位為大量空值,導致了資料傾斜的發生,有時候這種空值對我們來說是沒有意義的,所以我們可以直接過濾掉
提高Shuffle中reduce的并行度,可以減少資料傾斜發生的概率,并沒有從本質上解決資料傾斜
假設有三個磁區,然后所有的key的hash值如下
123
456
789
333
224
前4個值對3取模都為0,會導致0號的task計算的數量過大,這里就可以增加并行度進行計算了
5.3 使用隨機的key
在沒有增加前綴時的shuffle階段,可以看出,大量的hello進入到了一個task中,導致運行速度不統一,有的快,有的慢
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-pD6McXkB-1631974248650)(K12題目自測推薦系統面試指導.pic/image-20210914084856902.png)]
在增加了隨機前綴之后,將key打散分配到不同的task里,進行聚合,然后再將前綴去掉,進行二次聚合,可以有效的避免資料傾斜
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-6kkcfe0E-1631974248651)(K12題目自測推薦系統面試指導.pic/image-20210914085110505-16315967549041.png)]
5.4 map join
普通的join是會走shuffle程序的,而一旦shuffle,就相當于會將相同key的資料拉取到一個shuffle read task中再進行join,此時就是reduce join,但是如果一個RDD是比較小的,則可以采用廣播小RDD全量資料+map算子來實作與join同樣的效果,也就是map join,此時就不會發生shuffle操作,也就不會發生資料傾斜,
(注意,RDD是并不能進行廣播的,只能將RDD內部的資料通過collect拉取到Driver記憶體然后再進行廣播)
不使用join算子進行連接操作,而使用Broadcast變數與map類算子實作join操作,進而完全規避掉shuffle類的操作,徹底避免資料傾斜的發生和出現,將較小RDD中的資料直接通過collect算子拉取到Driver端的記憶體中來,然后對其創建一個Broadcast變數;接著對另外一個RDD執行map類算子,在算子函式內,從Broadcast變數中獲取較小RDD的全量資料,與當前RDD的每一條資料按照連接key進行比對,如果連接key相同的話,那么就將兩個RDD的資料用你需要的方式連接起來,
根據上述思路,根本不會發生shuffle操作,從根本上杜絕了join操作可能導致的資料傾斜問題,
當join操作有資料傾斜問題并且其中一個RDD的資料量較小時,可以優先考慮這種方式,效果非常好,
5.5 序列化優化
默認情況下,Spark使用Java的序列化機制,Java的序列化機制使用方便,不需要額外的配置,在算子中使用的變數實作Serializable介面即可,但是,Java序列化機制的效率不高,序列化速度慢并且序列化后的資料所占用的空間依然較大,
Kryo序列化機制比Java序列化機制性能提高10倍左右,Spark之所以沒有默認使用Kryo作為序列化類別庫,是因為它不支持所有物件的序列化,同時Kryo需要用戶在使用前注冊需要序列化的型別,不夠方便,但從Spark 2.0.0版本開始,簡單型別、簡單型別陣列、字串型別的Shuffling RDDs 已經默認使用Kryo序列化方式了,
Kryo序列化注冊方式的實體代碼
public class MyKryoRegistrator implements KryoRegistrator
{
@Override
public void registerClasses(Kryo kryo)
{
kryo.register(StartupReportLogs.class);
}
}
配置Kryo序列化方式的實體代碼
//創建SparkConf物件
val conf = new SparkConf().setMaster(…).setAppName(…)
//使用Kryo序列化庫,如果要使用Java序列化庫,需要把該行屏蔽掉
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
//在Kryo序列化庫中注冊自定義的類集合,如果要使用Java序列化庫,需要把該行屏蔽掉
conf.set("spark.kryo.registrator", "com.kgc.MyKryoRegistrator");
5.6 廣播變數優化
默認情況下,task中的算子中如果使用了外部的變數,每個task都會獲取一份變數的復本,這就造成了記憶體的極大消耗,一方面,如果后續對RDD進行持久化,可能就無法將RDD資料存入記憶體,只能寫入磁盤,磁盤IO將會嚴重消耗性能;另一方面,task在創建物件的時候,也許會發現堆記憶體無法存放新創建的物件,這就會導致頻繁的GC,GC會導致作業執行緒停止,進而導致Spark暫停作業一段時間,嚴重影響Spark性能,
假設當前任務配置了20個Executor,指定500個task,有一個20M的變數被所有task共用,此時會在500個task中產生500個副本,耗費集群10G的記憶體,如果使用了廣播變數, 那么每個Executor保存一個副本,一共消耗400M記憶體,記憶體消耗減少了5倍,
廣播變數在每個Executor保存一個副本,此Executor的所有task共用此廣播變數,這讓變數產生的副本數量大大減少,
在初始階段,廣播變數只在Driver中有一份副本,task在運行的時候,想要使用廣播變數中的資料,此時首先會在自己本地的Executor對應的BlockManager中嘗試獲取變數,**如果本地沒有,BlockManager就會從Driver或者其他節點的BlockManager上遠程拉取變數的復本,**并由本地的BlockManager進行管理;之后此Executor的所有task都會直接從本地的BlockManager中獲取變數,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301245.html
標籤:其他