這幾天碰到一個事情,有必要記錄一下,
在一個專案中,壓力測驗工具中一個業務回應時間變長,資料庫(Oracle)CPU 使用率 99 %以上,

從 AWR 報告上看到如下資訊:
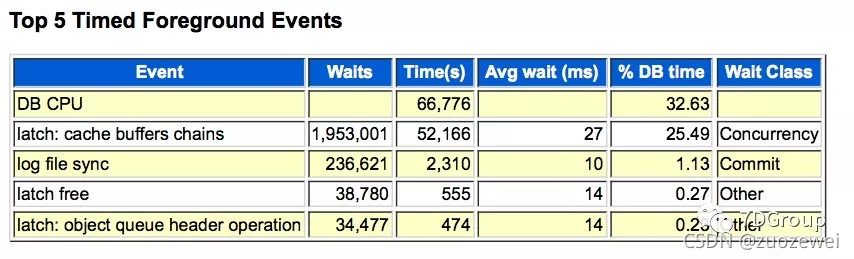
在性能專案的溝通中,經常是在這樣的時候,我們就去告訴開發說現在的狀態是 CPU 使用率高,把 AWR 報告往開發那里一發,性能團隊的人員就喝咖啡去了,
但是性能如果只是做到這里,溝通其實沒有在同一個界面上,
在這個典型的溝通程序中,上述結果也確實發給開發了,
開發反饋說,是因為在場景執行程序中表的資料量發生了變化,導致了 SQL 的執行計劃發生了變化,進而導致了SQL慢,進而導致了latch: cache buffers chains的出現,所以要解決的話,要對資料庫進行一次analyze,然后再測驗,
?
在上述的背景中,看似沒有漏洞,合情合理,
但是,恰好碰到我這偏執的人,我要看到 證據鏈,
在溝通的來往中,我并沒有看到證據鏈,這是我覺得不好的地方,哪里沒有證據呢?就是資料量發生了變化導致了SQL的執行計劃發生了變化,
如果有這樣的懷疑,就要去證明這個懷疑是對的,
于是我查了 SQL 計劃的歷史變更記錄,
?
根據 SQLID 查看執行計劃的變更記錄:
selectDISTINCT SQL_ID,PLAN_HASH_VALUE,TO_CHAR(TIMESTAMP,'yyyymmdd hh24:mi:ss') TIMESTAMPfrom dba_hist_sql_plan where sql_id='1wfsd2q8wc5uu'orderbyTIMESTAMP;
SQL_ID PLAN_HASH_VALUE TIMESTAMP
1 1wfsd2q8wc5uu 4188019746 2018040118:08:09
?
查詢更詳細的執行記錄變更記錄(我把結果中的時間戳刪掉了,為了格式整齊點):
select plan_hash_value,id,operation,options,object_name,depth,cost,TO_CHAR(TIMESTAMP,'yyyymmdd hh24:mi:ss') from dba_hist_sql_plan where sql_id='1wfsd2q8wc5uu'and plan_hash_value in (4188019746) orderbyID,TIMESTAMP;
PLAN_HASH_VALUE ID OPERATION OPTIONS OBJECT_NAME DEPTH COST
1 4188019746 0 SELECT STATEMENT 0 2
2 4188019746 1 FILTER 1
3 4188019746 2 FAST DUAL 2 2
4 4188019746 3 TABLE ACCESS BY INDEX ROWID TABLE1 2 0
5 4188019746 4 INDEX RANGE SCAN TABLE1_IDX1 3 0
這個 SQL 的執行計劃,只有 4 月 1 日一條記錄,在最近幾天的測驗中,并沒有發生變更,
這就是我要說的證據鏈,當給出執行計劃發生變化這個結論時,就必須給出證明,而實際的資料證明這個結論是錯的,
?
下面我們就來分析下怎么才是對的,
既然是 latch: cache buffers chains,首先我們得知道這個值是什么意思,
簡單回憶下 latch 的原理(如下部分是在網上抄的):
當一個資料塊讀入到SGA中時,該塊的塊頭(BUFFERHEADER)會放置一個HASHBUCKET的鏈表(HASHCHAIN)中,該記憶體結構由一系列cachebuffers chains的子latch保護,對BUFFERCACHE中的塊,要SELECT/UPDATE/INSERT/DELETER等操作都得先獲得cachebuffers chains的子latch,以保證對CHAIN的排他訪問,若在程序中發生爭用,就會出現latch:cache buffers chains事件,
這個值的出現有兩個含義:
- SQL的執行效率低(因為 SQ L低效,在并發會話時,無法得到相同的資料集,SQ L執行時帶有高 BUFFER_GETS 會導致 latch爭用),
- 資料熱塊,
?
這是兩個完全不同的處理方向,
第一個處理方向,考慮到近期場景執行得比較頻繁,資料庫變更較多,所以先把資料庫做個整體的分析,再來測驗下,經過證明之后,發現果然分析了整庫之后,時間刷刷的降低了很多,然后就把存盤的IO壓到80%以上了,
雖然開發說執行計劃變更是錯的,但是分析整庫的處理方法是對的,
套用大話西游里說的:我猜中了結尾,但是沒有蒙對程序,
看到這里,是不是覺得問題解決了?可以收工了?很開心的喝咖啡去了?
但是,我又偏執了,我考慮了下引數化的邏輯,我覺得資料熱塊應該是存在的,現在之所以沒有暴露出來,是因為 IO 跟不上了,所以我要判斷下,如果 IO 夠用的話,熱塊會不會成為下一個瓶頸,于是,接著查,
先看看爭用是否嚴重:
selectround ((misses / gets) * 100) || '%',
round(
100 * immediate_misses / (
immediate_gets + immediate_misses
)
) || '%'
FROM
v$latch wherename = 'cache buffers chains';
round((misses / gets) * 100) || '%'的值是 3%,可見還是有一些熱度的,
再來查下子鎖存器視圖,看是否有熱塊,看看傾斜度,
?
select * from (select addr,child#,gets,misses,sleepsfrom v$latch_children
wherename='cachebuffers chains'orderby sleeps desc) whererownum<=20;
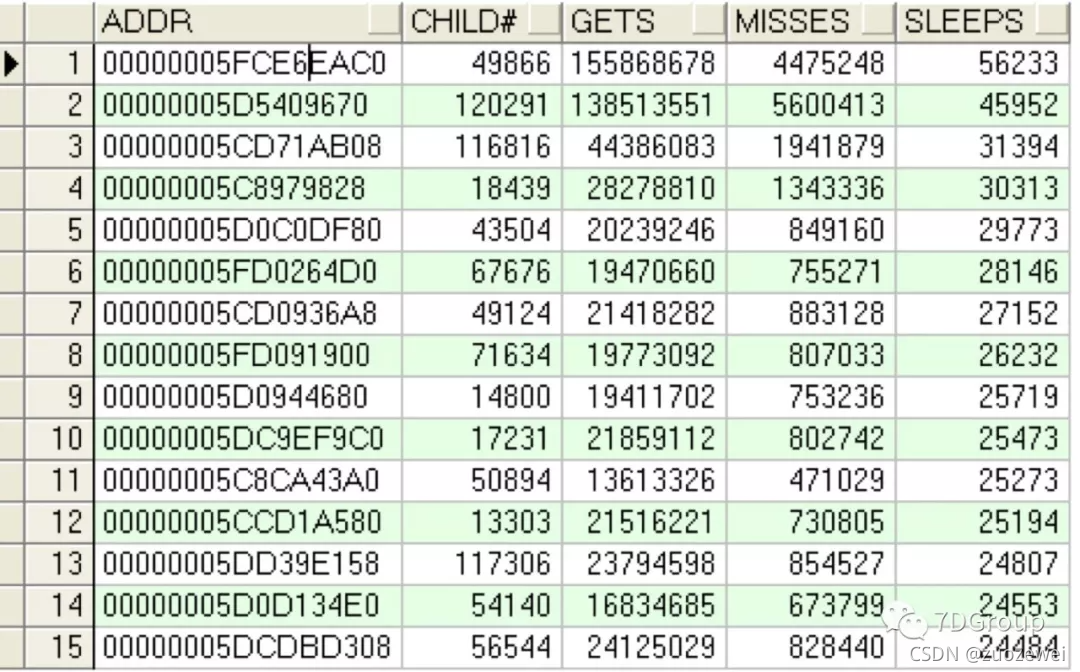
傾斜度是有的,再看下物件的熱度:
select hladdr,
obj,
(select object_name
from dba_objects
where (data_object_id isnull
andobject_id = x.obj) or data_object_id = x.obj andrownum = 1) as object_name, dbablk, tch
from x$bh x
where hladdr in ('00000005FCE6EAC0')
orderby tch desc;
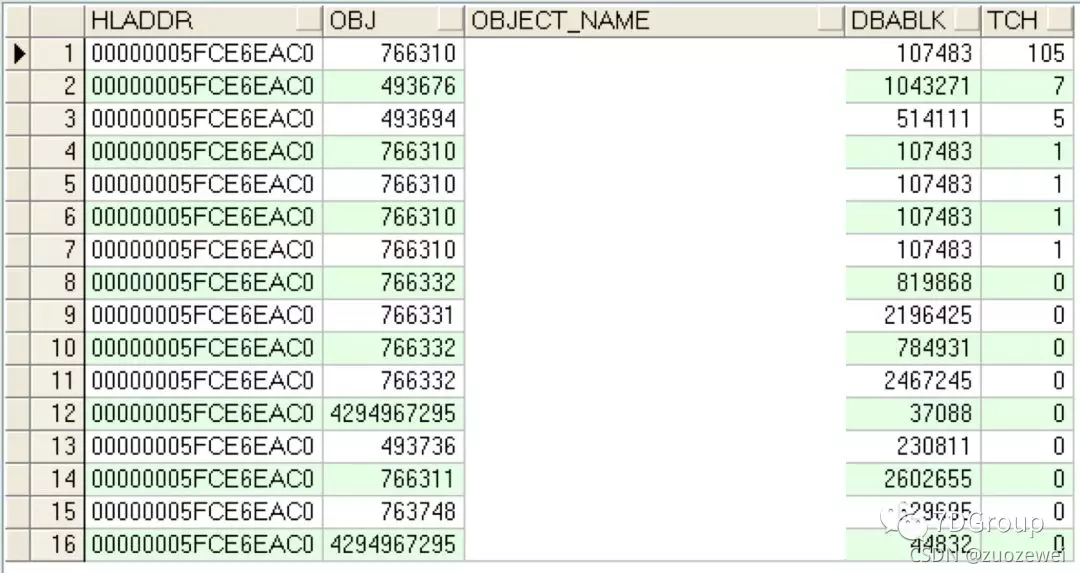
TCH 是 touch count,此值越高,則熱度越高,
查找引起熱塊的 SQL,
select *
from (selectcount(*),
sql_id,
nvl(o.object_name, ash.current_obj#) objn,
substr(o.object_type, 0, 10) otype,
CURRENT_FILE# fn,
CURRENT_BLOCK# blockn
from v$active_session_history ash, all_objects o
where event like'latch: cache buffers chains'
ando.object_id(+) = ash.CURRENT_OBJ#
GROUPBY SQL_ID,
current_obj#,
current_file#,
current_block#,
o.object_name,
o.object_type
orderbycount(*) desc)
whererownum <= 10;
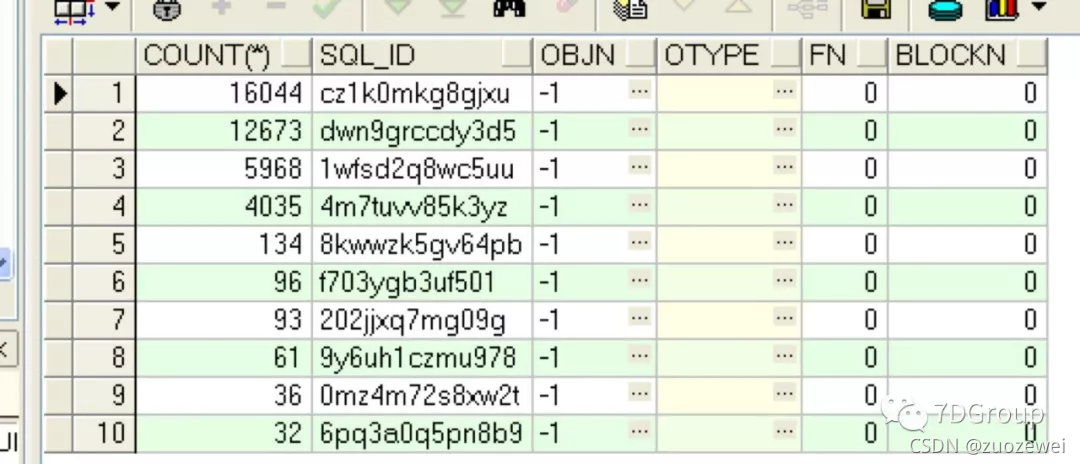
根據 SQLID 查一下 SQL 的文本,果然就是我們用到的那個查詢業務 QL,
在性能分析中,我們太容易給自己定個范圍或圈套了,有時覺得這個事情不該是自己做的,
如果單從職場的角度說,這樣想并無不妥,
但是如果從技術角度說,這樣想就必然會導致自己的能力受限,
所以不用給技術下個定義,在個人能力能達到的地方,都盡量去做,學無止境,
而從現象到瓶頸的性能分析是最需要一個人有足夠的知識寬度的,因為你不知道在尋找瓶頸的程序中會遇到什么樣的知識弱點,
今天碰到的是 Oracle,明天碰到 MySQL、HBase怎么辦?啥也別想,二話不說,辦它就對了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301260.html
標籤:其他