本章目錄
- 溫馨提示
- 本章重點
- 1. 結構體的宣告
- 1.1 了解結構體
- 1.2 結構體型別的宣告(創建)
- 1.3 結構成員的型別
- 1.4 結構體變數的定義和初始化
- 2. 結構體成員的訪問
- 3. 結構體傳參
- 全文結束
溫馨提示
大家好我是Cbiltps,在我的博客中如果有難以理解的句意,難以用文字表達的重點,我會有配圖,所以我的博客配圖非常重要!!!
如果你對我感興趣請看我的第一篇博客!
本章重點
- 結構體型別的宣告
- 結構體初始化
- 結構體成員訪問
- 結構體傳參
1. 結構體的宣告
1.1 了解結構體
結構體是怎么來的呢?
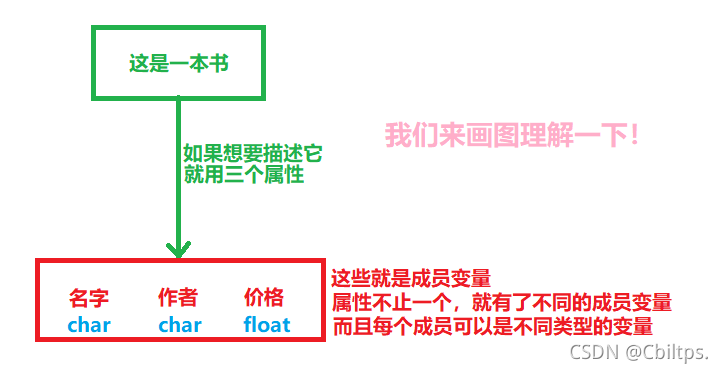
如果描述一個復雜物件,這不僅僅是一個變數值(型別)就可以描述的,它是有很多屬性組和在一起,這時為了表述這個復雜物件就引入了結構體,
結構是一些值的集合,這些值稱為成員變數,
結構的每個成員可以是不同型別的變數,
1.2 結構體型別的宣告(創建)
struct tag
{
member_list;
}variable_list;
//sturct 是結構體關鍵字
//tag 是結構體的名字(標簽)
//member_list 是成員變數
//variable_list 是變數串列
//注意:這里的變數串列可以寫,也可以不寫,
//如果寫了:相當于拿前面的結構體型別創建了全域變數
例如描述一本書:
#include <stdio.h>
//結構體型別——因為不是在創建變數,所以不會占用記憶體
struct Book
{
char name[20];//下面的三個屬性就是成員變數,每個成員可以是不同型別的
char author[15];
float price;
}b1,b2;//b1和b2是全域變數,相當于拿前面結構體型別所創建的變數——放在記憶體的靜態區
//這里的變數串列也可以省略
int main()
{
struct Book b;//這里的b雖然是結構體變數,但是是區域變數——放在記憶體的堆疊區
return 0;
}
還有一種方法來創建結構體型別:
typedef struct Stu
{
char name[20];
int age;
char id[10];
}Stu;//在使用typedef的時候,對這個結構體型別重新起名字叫Stu
//注意:在沒有typedef的時候,分號前面的是結構體變數,
// 有typedef的時候,分號前面的是結構體型別(重新起名字的),
int main()
{
//那么對這個結構體型別有兩種寫法:
struct Stu B;//用的是沒有重新起名字的結構體型別
Stu N;//用的是重新起名字的結構體型別,這種寫法更加簡潔一些
return 0;
}

1.3 結構成員的型別
結構的成員可以是變數、陣列、指標,甚至是其他結構體,
1.4 結構體變數的定義和初始化
在前面代碼的注釋中我們可以看到,結構體變數的定義其實有兩種:
1. 區域變數
2. 全域變數

所以,我們直接來講講初始化:
typedef struct Stu
{
char name[20];
int age;
char id[10];
}Stu;
int main()
{
struct Stu B = { "張三", 20, "123456" };//就是這樣初始化的
Stu N = { "李四", 23, "7654323" };
return 0;
}
有的時候結構體里面包含了結構體:
struct S
{
int a;
char c;
double d;
};
struct T
{
struct S s;
char name[20];
int num;
};
int main()
{
struct T t = { {100,'c', 3.14}, "lisi", 30 };//結構體中的結構體這樣初始化
return 0;
}
2. 結構體成員的訪問
- 結構體變數訪問成員
結構變數的成員是通過點運算子.訪問的,點運算子接受兩個運算元, - 結構體指標訪問指向變數的成員
有時候我們得到的不是一個結構體變數,而是指向一個結構體的指標,
struct S
{
int a;
char c;
double d;
};
struct T
{
struct S s;
char name[20];
int num;
};
int main()
{
//結構體變數訪問成員
struct T t = { {100, 'w', 3.14}, "zhangsan", 200 };
printf("%d %c %f %s %d\n", t.s.a, t.s.c, t.s.d, t.name, t.num);
//結構體指標訪問指向變數的成員
struct T* pt = &t;
printf("%d %c %f %s %d\n", pt->s.a, pt->s.c, pt->s.d, pt->name, pt->num);
return 0;
}
3. 結構體傳參
#include <stdio.h>
struct S
{
int arr[100];
int num;
char ch;
double d;
};
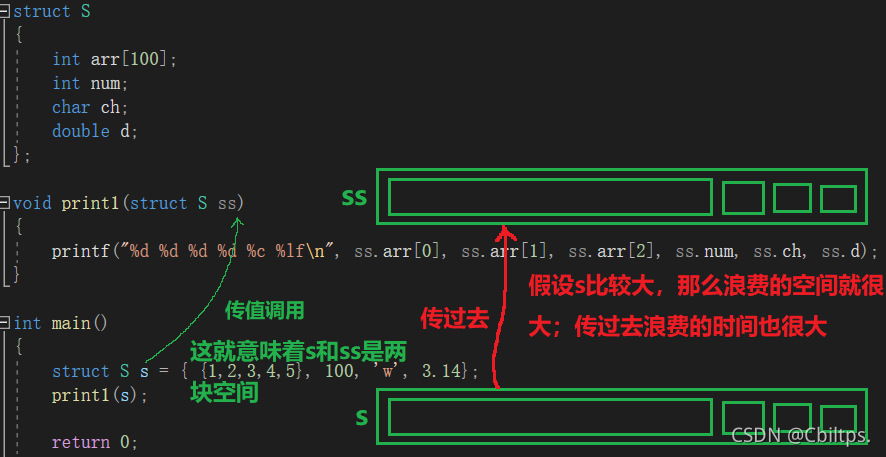
void print1(struct S ss)
{
printf("%d %d %d %d %c %lf\n", ss.arr[0], ss.arr[1], ss.arr[2], ss.num, ss.ch, ss.d);
}
int main()
{
struct S s = { {1,2,3,4,5}, 100, 'w', 3.14};
print1(s);
return 0;
}
#include <stdio.h>
struct S
{
int arr[100];
int num;
char ch;
double d;
};
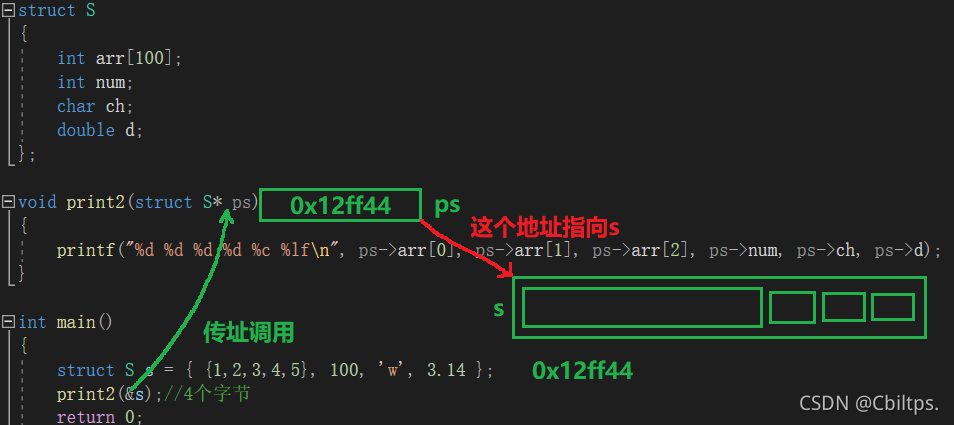
void print2(struct S* ps)
{
printf("%d %d %d %d %c %lf\n", ps->arr[0], ps->arr[1], ps->arr[2], ps->num, ps->ch, ps->d);
}
int main()
{
struct S s = { {1,2,3,4,5}, 100, 'w', 3.14 };
print2(&s);//4個位元組
return 0;
}
上面的print1和print2函式哪個好些?
答案是:首選print2函式,
首選print2函式原因:
函式傳參的時候,引數是需要壓堆疊的,
如果傳遞一個結構體物件的時候,結構體過大,引數壓堆疊的的系統開銷比較大,所以會導致性能
的下降,
我們來畫圖理解一下:
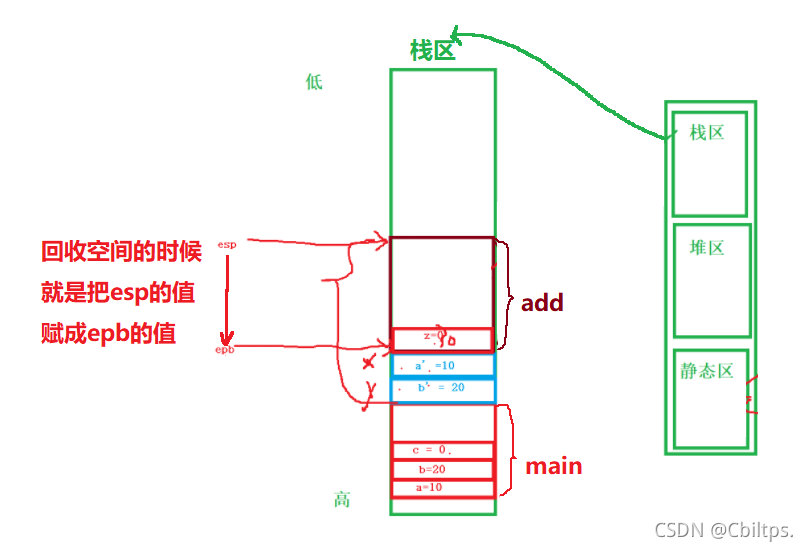
對于上面的壓堆疊不理解的話,我們舉例講解一下:
//以這段代碼為例:
#include <stdio.h>
int Add(int x, int y)
{
int z = 0;
z = x + y;
return z;
}
int main()
{
int a = 10;
int b = 20;
int c = 0;
c = Add(a, b);
return 0;
}
結論:結構體傳參的時候,最好傳結構體的地址,
全文結束
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301285.html
標籤:其他