作者|鄒晟 去哪兒網基礎平臺技術專家
背景
近幾年,云原生和容器技術非常火爆,且日趨成熟,眾多企業慢慢開始容器化建設,并在云原生技術方向上不斷的探索和實踐,基于這個大的趨勢, 2020 年底 Qunar 也向云原生邁出了第一步——容器化,
云原生是一系列可以為業務賦能的技術架構準則,遵循它可以使應用具有擴展性、伸縮性、移植性、韌性等特點,云原生也是下一代技術堆疊的必選項,它可以讓業務更敏捷,通過實踐 DevOps、微服務、容器化、可觀測性、反脆弱性(chaos engineering)、ServiceMesh、Serverless 等云原生技術堆疊,我們便可以享受到云原生帶來的技術紅利,
Qunar 容器化發展時間線
一項新技術要在企業內部落地從來都不是一蹴而就的,Qunar 的容器化落地也同樣如此,Qunar 的容器后落地主要經歷了 4 個時間節點:
2014 - 2015:
業務線同學開始嘗試通過 Docker、Docker-Compose 來解決聯調環境搭建困難的問題,不過由于 Docker-Compose 的編排能力有限、無法解決真實的環境問題,因此容器化最后也沒有推行起來,
2015 - 2017:
ops 團隊把為了提高 ELK 集群的運維效率,把 ES 集群遷移到了 Mesos 平臺上,后來隨著 K8s 生態的成熟,把 ES 集群從 Mesos 遷移到了 K8s 平臺,運維效率得到了進一步的提升,
2018 - 2019:
在業務需求不斷增加的程序中,業務對測驗環境的交付速度和質量有了更高的要求,為了解決 MySQL 的交付效率問題( 并發量大時,網路 IO 成為了瓶頸,導致單個實體交付時長在分鐘級),為了解這個問題,我們把 MySQL 容器化,通過 Docker on host 的模式可以在 10 秒之內就可以交付一個 MySQL 實體,
2020 - 2021:
云原生技術已經非常成熟了,Qunar 也決定通過擁抱云原生來為業務增加勢能,在各個團隊齊心協力的努力下,300+ 的 P1、P2 應用已經完成了容器化,并且計劃在 2021 年年底全部業務應用實作容器化,
落地程序與實踐
容器化整體方案介紹
Qunar 在做容器化程序中,各個系統 Portal 平臺、中間件、ops 基礎設施、監控等都做了相應的適配改造,改造后的架構矩陣如下圖所示,
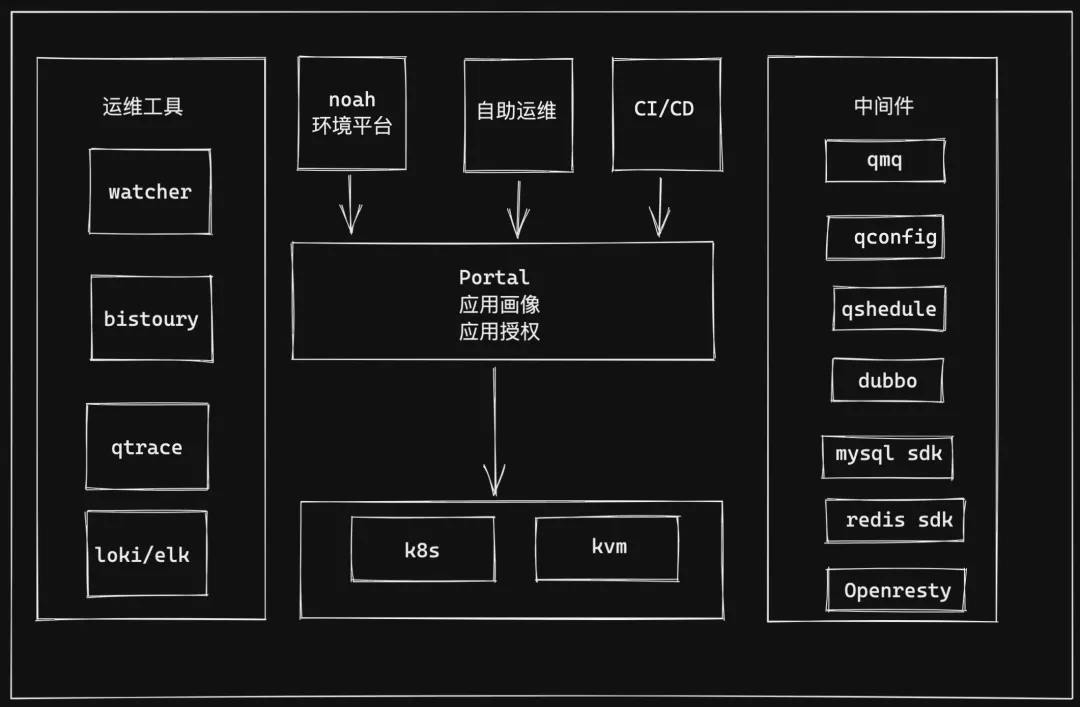
Portal:Qunar 的 PaaS 平臺入口,提供 CI/CD 能力、資源管理、自助運維、應用畫像、應用授權(db 授權、支付授權、應用間授權)等功能,
運維工具:提供應用的可觀測性工具, 包括 watcher(監控和報警)、bistoury (Java 應用在線 Debug)、qtrace(tracing 系統)、loki/elk(提供實時日志/離線日志查看),
中間件:應用用到的所有中間件,mq、配置中心、分布式調度系統 qschedule、dubbo 、mysql sdk 等,
虛擬化集群:底層的 K8s 和 OpenStack 集群,
Noah:測驗環境管理平臺,支持應用 KVM/容器混合部署,
CI/CD 流程改造
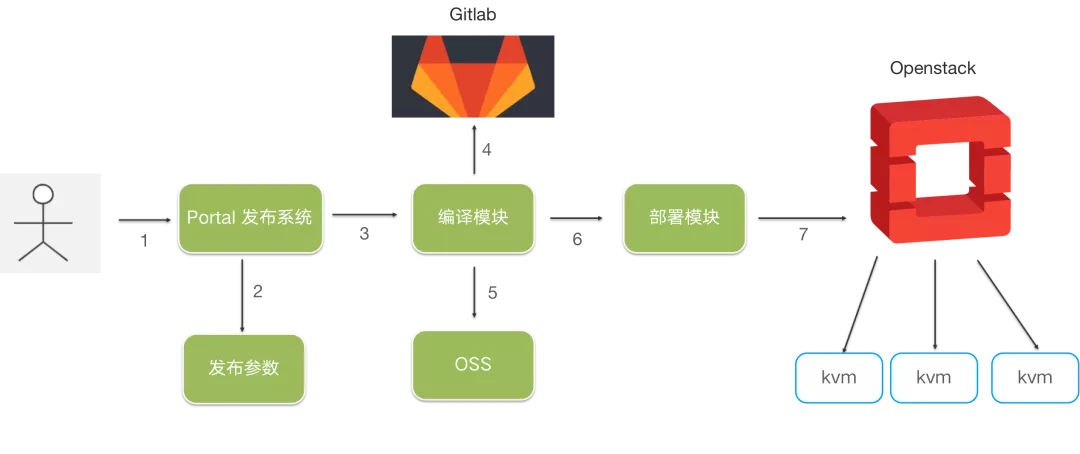
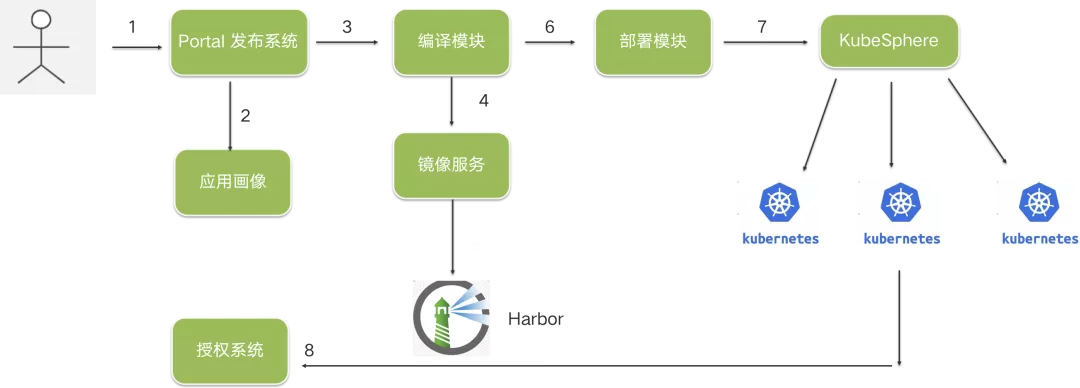
主要改造點:
應用畫像: 把應用相關的運行時配置、白名單配置、發布引數等收斂到一起,為容器發布提供統一的宣告式配置,
授權系統: 應用所有的授權操作都通過一個入口進行,并實作自動化的授權,
K8s 多集群方案: 通過調研對比,KubeSphere 對運維優化、壓測評估后也滿足我們對性能的要求,最終我們選取了 KubeSphere 作為多集群方案,
中間件適配改造
改造關注點:由于容器化后,IP 經常變化是常態,所以各個公共組件和中間件要適配和接受這種變化,

應用平滑遷移方案設計
為了幫助業務快速平滑地遷移到容器,我們制定了一些規范和自動化測驗驗證等操作來實作這個目標,
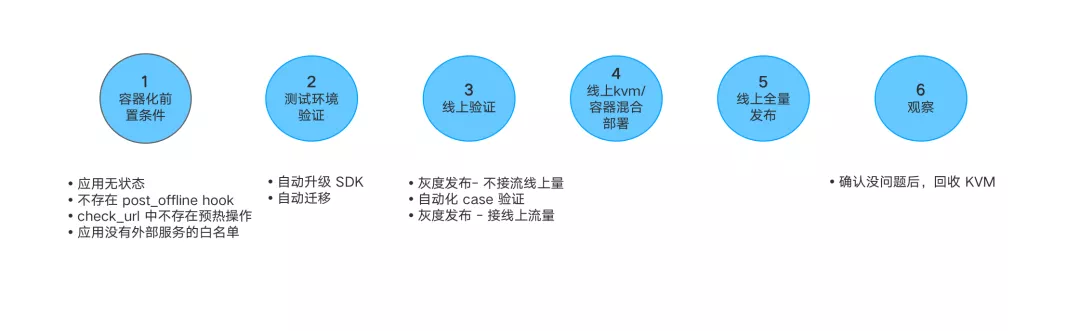
容器化的前置條件: 應用無狀態、不存在 post_offline hook(服務下線后執行的腳本)、check_url 中不存在預熱操作,
測驗環境驗證: 自動升級 SDK、自動遷移,我們會在編譯階段幫助業務自動升級和更改 pom 檔案來完成 SDK 的升級,并在測驗環境部署和驗證,如果升級失敗會通知用戶并提示,
線上驗證: 第一步線上發布,但不接線上流量,然后通過自動化測驗驗證,驗證通過后接入線上流量,
線上 KVM 與容器混部署:保險起見,線上的容器和 KVM 會同時在線一段時間,等驗證期過后再逐步下線 KVM,
線上全量發布: 確認服務沒問題后,下線 KVM,
觀察: 觀察一段時間,如果沒有問題則回收 KVM,
容器化落地程序中碰到的問題
如何兼容過去 KVM 的使用方式,并支持 preStart、preOnline hook 自定義腳本?
KVM 場景中 hook 腳本使用場景介紹:
preStart hook : 用戶在這個腳本中會自定義命令,比如環境準備,
preOnline hook:用戶會定義一些資料預熱操作等,這個動作需要在應用 checkurl 通過并且接入流量前執行,
問題點:
K8s 原生只提供了 preStop、postStart 2 種 hook, 它們的執行時機沒有滿足上述 2 個 KVM 場景下業務用到的 hook,
分析與解決程序:
preStart hook:在 entrypoint 中注入 preStart hook 階段,容器啟動程序中發現有自定義的 preStart 腳本則執行該腳本,至于這個腳本的位置目前規范是定義在代碼指定目錄下,
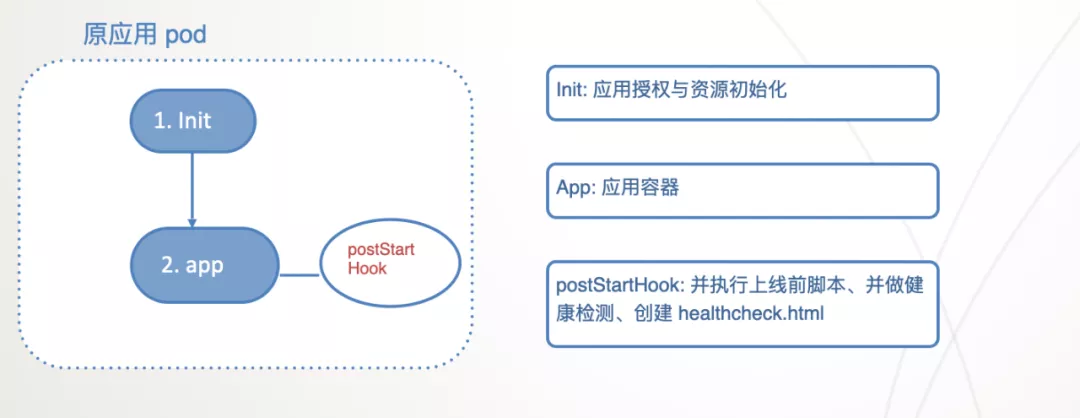
preOnline hook:由于 preOnline 腳本執行時機是在應用 checkurl 通過后,而應用容器是單行程,所以在應用容器中執行這個是行不通的,而 postStart hook 的設計就是異步的,與應用容器的啟動也是解耦的, 所以我們初步的方案選擇了 postStart hook 做這個事情,實施方案是 postStart hook 執行后會不斷輪詢應用的健康狀態,如果健康檢測 checkurl 通過了, 則執行 preOnline 腳本,腳本成功后則進行上線操作, 即在應用目錄下創建 healthcheck.html 檔案,OpenResty 和中間件發現這個檔案后就會把流量接入到這個實體中,
按照上面的方案,Pod 的組成設計如下:
發布程序讀不到標準輸入輸出
場景介紹:
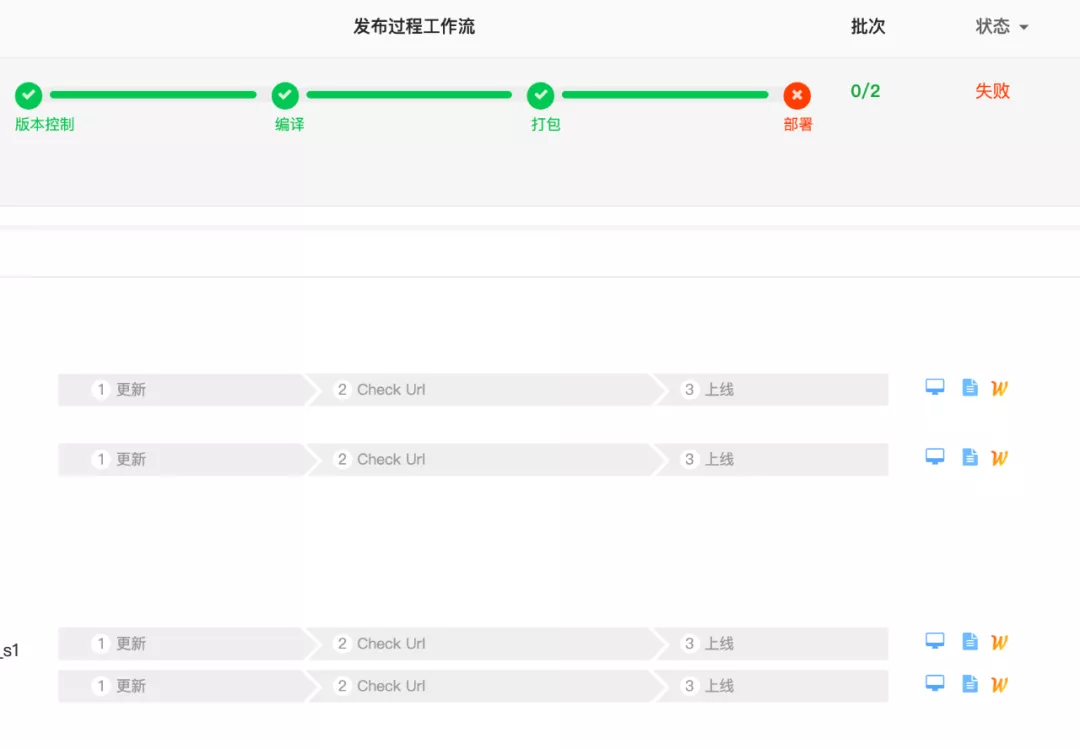
在容器發布程序中如果應用啟動失敗,我們通過 K8s API 是拿不到實時的標準輸入輸出流,只能等到發布設定的超時閾值,這個程序中發布人員心里是很焦急的,因為不確定發生了什么,如下圖所示,部署程序中應用的更新作業流中什么都看不到,
問題點:
K8s API 為什么拿不到標準輸入輸出?
分析與解決程序:
通過 kubectl logs 查看當時的 Pod 日志,什么都沒有拿到,超時時間過后才拿到,說明問題不在程式本身,而是在 K8s 的機制上;
查看 postStart Hook 的相關檔案,有一段介紹提到了 postHook 如果執行時間長或者 hang 住,容器的狀態也會 hang 住,不會進入 running 狀態, 看到這條資訊,大概猜測到罪魁禍首就是這個 postStart hook 了,

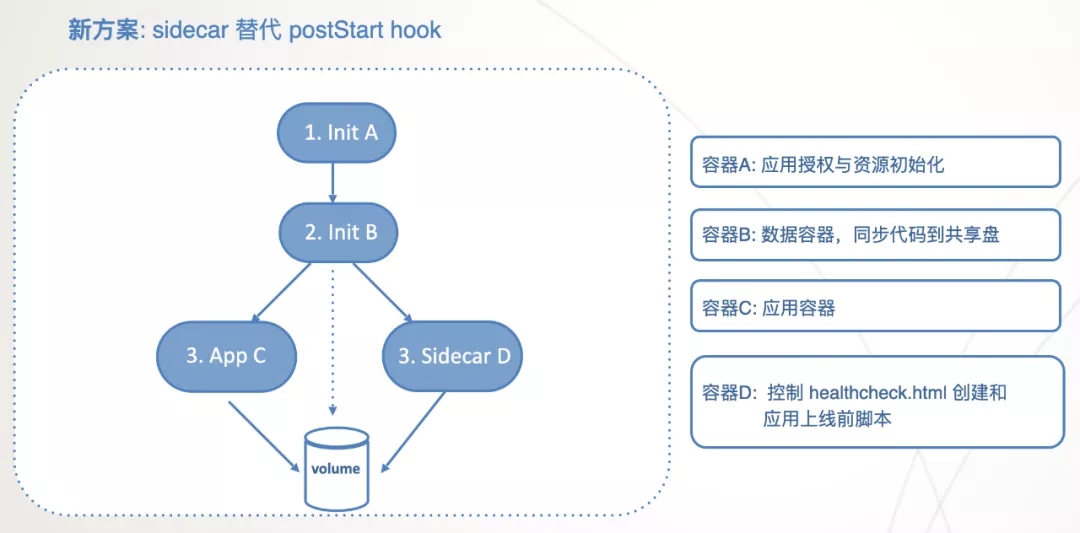
基于上面的猜測,把 postStart hook 去掉后測驗,應用容器的標準輸入可以實時拿到了,
找到問題后,解決方法也就簡單了,把 postStart hook 中實作的功能放到 Sidecar 中就可以解決,至于 Sidecar 如何在應用容器的目錄中創建 healthcheck.html 檔案,就需要用到共享卷了,新的方案設計如下:
使用上述方案后,發布流程的標準輸入輸出、自定義 hook 腳本的輸出、Pod 事件等都是實時可見的了, 發布程序更透明了,
并發拉取鏡像超時
場景介紹:
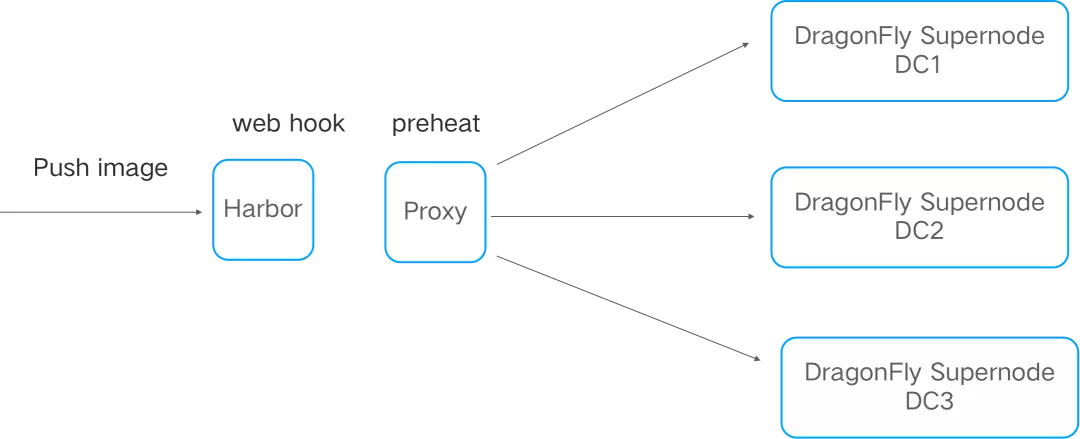
我們的應用是多機房多集群部署的,當一個應用的新版本發布時,由于應用的實體數較多,有 50+ 個并發從 harbor 拉取鏡像時,其中一些任務收到了鏡像拉取超時的報錯資訊,進而導致整個發布任務失敗,超時時間是 kubelet 默認設定的 1 分鐘,
分析與解決:
通過排查最終確認是 harbor 在并發拉取鏡像時存在性能問題,我們采取的優化方案是通用的 p2p 方案,DragonFly + Harbor,
并發大時授權介面抗不住
場景介紹:
應用發布程序中呼叫授權介面失敗,K8s 的自愈機制會不斷重建容器并重新授權,并發量比較大,最終把授權服務拖垮,
我們的容器授權方案如下:
Pod init 容器啟動時進行調研授權介面進行授權操作,包括 ACL 和 mysql 的白名單,
容器銷毀時會執行 Sidecar 容器的 preStop hook 中執行權限回收操作,
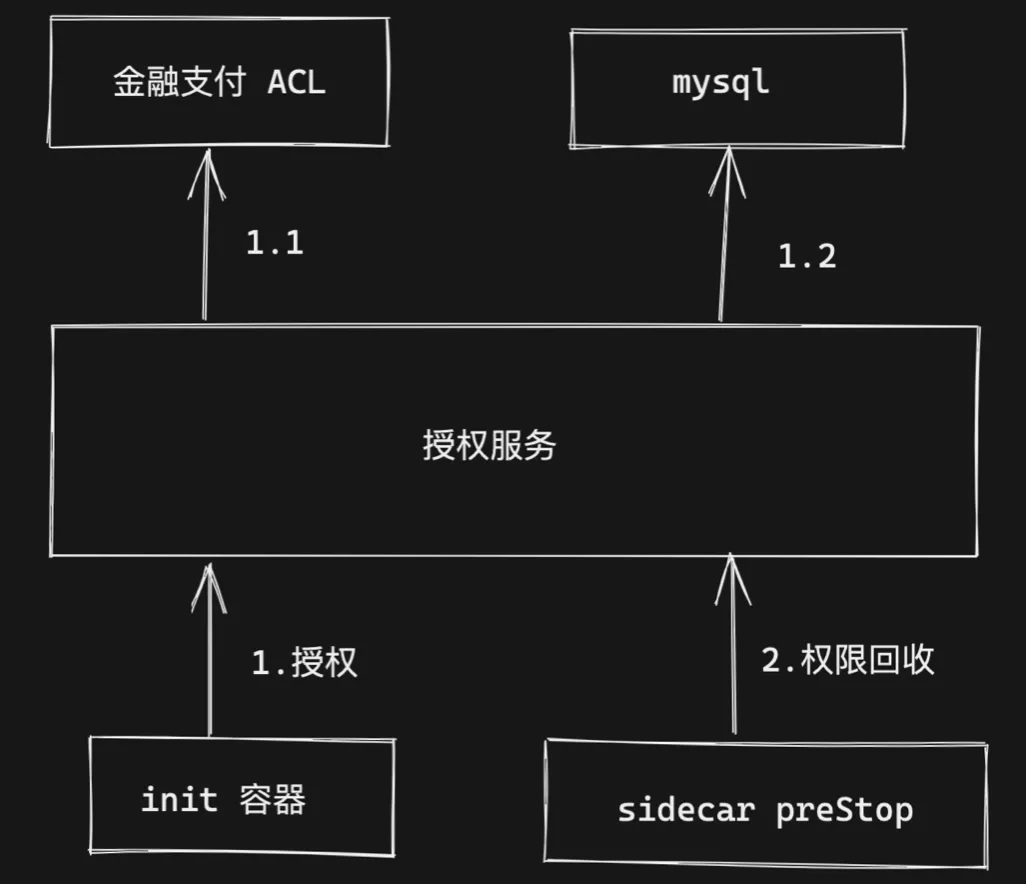
問題點:
ACL 授權介面涉及到了防火墻,QPS 比較低,大量容器進行 ACL 授權時把服務拖垮 ,
分析與解決:
為了解決上述的問題,限量和降低授權介面呼叫次數是有效的解決方式,我們采取了下面幾個措施:
init 容器中的重試次數限制為 1 次,
授權介面按應用和 IP 限流, 超過 3 次則直接回傳失敗,不會再進行授權操作,
ACL 中涉及的一些通用的埠,我們統一做了白名單,應用無需再進行授權操作,
Java 應用在容器場景下如何支持遠程 Debug
KVM 場景 Debug 介紹:
在開發 Java 應用的程序中,通過遠程 Debug 可以快速排查定位問題,因此是開發人員必不可少的一個功能,Debug 具體流程: 開發人員在 Noah 環境管理平臺的界面點擊開啟 Debug, Noah 會自動為該 Java 應用配置上 Debug 選項,-Xdebug -Xrunjdwp: transport=dt_socket, server=y, suspend=n, address=127.0.0.1:50005,并重啟該 Java 應用,之后開發人員就可以在 IDE 中配置遠程 Debug 并進入除錯模式了,
容器場景的 Debug 方案:
測驗環境的 Java 應用默認開啟 Debug 模式,這樣也避免了更改 Debug 重建 Pod 的程序,速度從 KVM 的分鐘級到現在的秒級,當用戶想開啟 Debug 時,Noah 會呼叫 K8s exec 介面執行 socat 相關命令進行埠映射轉發,讓開發人員可以通過 socat 開的代理連接到 Java 應用的 Debug 埠,
問題點:
容器場景下在用戶 Debug 程序中,當請求走到了設定的斷點后,Debug 功能失效,
分析與解決程序:
復現容器場景下 Debug,觀察該 Pod 的各項指標,發現 Debug 功能失效的時候系統收到了一個 liveness probe failed,kill pod 的事件,根據這個事件可以判斷出當時 liveness check 失敗,應用容器才被 kill 的,應用容器重啟代理行程也就隨之消失了,Debug 也就失效了,
關于 Debug 程序 checkurl 為什么失敗的問題,得到的答案是 Debug 時當請求走到斷點時,整個 JVM 是 hang 住的,這個時候任何請求過來也會被 hang 住,當然也包括 checkurl,于是我們也特地在 KVM 場景和容器場景分布做了測驗,結果也確實是這樣的,
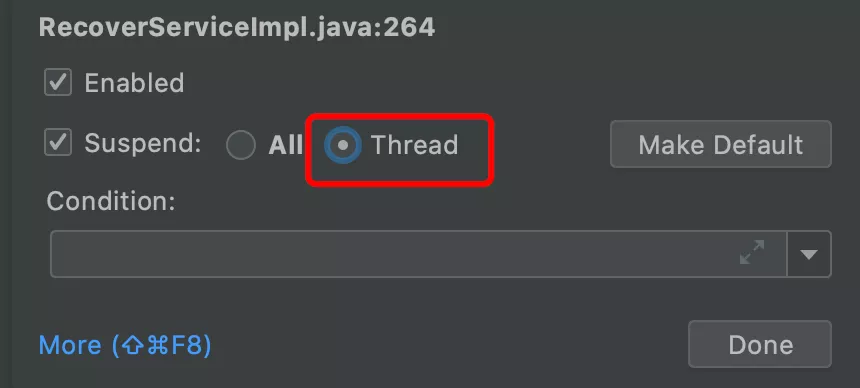
臨時解決方案是把斷點的阻斷級別改為執行緒級的,這樣就不會阻斷 checkurl 了, idea 中默認的選項是 Suspend All,改為 Suspend Thread 即可,不過這個也不是最優解,因為這個需要用戶手工配置阻斷級別,有認知學習成本,
回到最初的問題上,為什么容器場景下遇到這個問題,而 KVM 沒有,主要是因為容器場景 K8s 提供了自愈能力,K8s 會定時執行 liveness check, 當失敗次數達到指定的閾值時,K8s 會 kill 掉容器并重新拉起一個新的容器,
那我們只好從 K8s 的 liveness 探針上著手了,探針默認支持 exec、tcp 、httpGet 3 種模式,當前使用的是 httpGet,這種方式只支持一個 url, 無法滿足這個場景需求,經過組內討論, 最后大家決定用這個運算式 (checkurl == 200) || (socat process && java process alive) 在作為應用的 liveness 檢測方式,當 Debug 走到斷點的時候, 應用容器就不會阻斷了, 完美的解決了這個問題,
以上就是我們落地容器化程序中遇到的幾個問題與我們的解決思路,其中很重要的一點是從 KVM 遷移到容器時需要考慮用戶的使用習慣、歷史功能兼容等要點,要做好兼容和取舍,只有這樣容器化落地才會更順暢,
未來展望
多集群穩定性治理
讓可觀測性資料更全面、覆寫度更廣,進而完善我們的 APM 系統,提升排查問題效率,
通過實施混沌工程來驗證、發現和消除容器化場景的穩定性盲區,
提高資源利用率
根據業務指標實作彈性擴縮容,
根據應用的歷史資料智能的調整 requests,
ServiceMesh 方案落地
- 我們是基于 Istio 和 MOSN 以及當前的基礎架構做的 mesh 方案,目前在測驗階段,這套方案落地后相信會讓基礎架構更敏捷,
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301388.html
標籤:其他