這篇文章是自己之前學習論文的一點心得,是源于AI+無線通信這個比賽,
論文百度搜這個,去IEEE官網就可以下載了,【C. Wen, W. Shih and S. Jin, “Deep Learning for Massive MIMO CSI Feedback”, in IEEE Wireless Communications Letters, vol. 7, no. 5, pp. 748-751, Oct. 2018, doi: 10.1109/LWC.2018.2818160.】
那我們正式開始!
首先拿到的是比賽官網給的示例代碼,直接看可能會摸不著頭腦,我們就從code去尋找paper

文章不是很長,我們逐段分析!




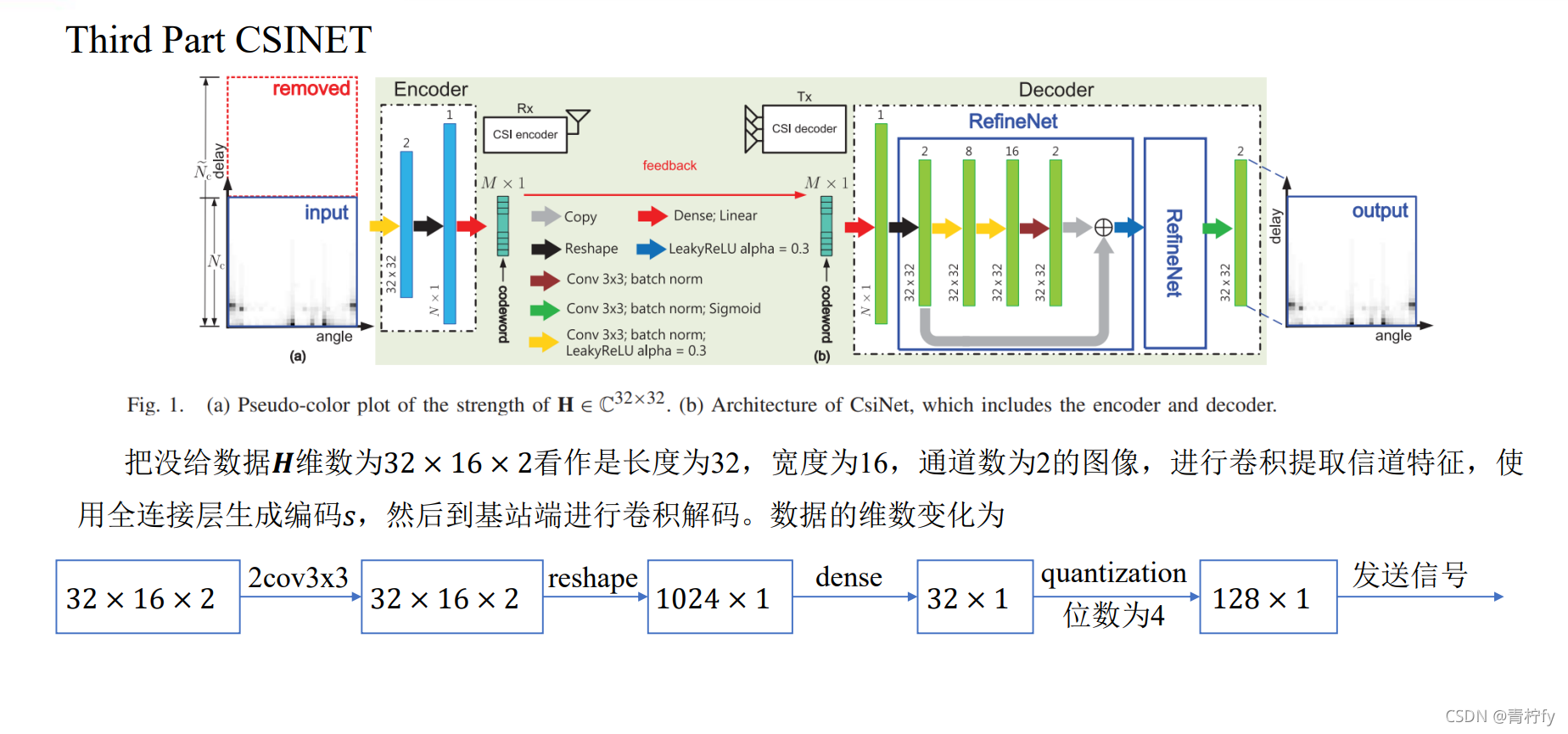
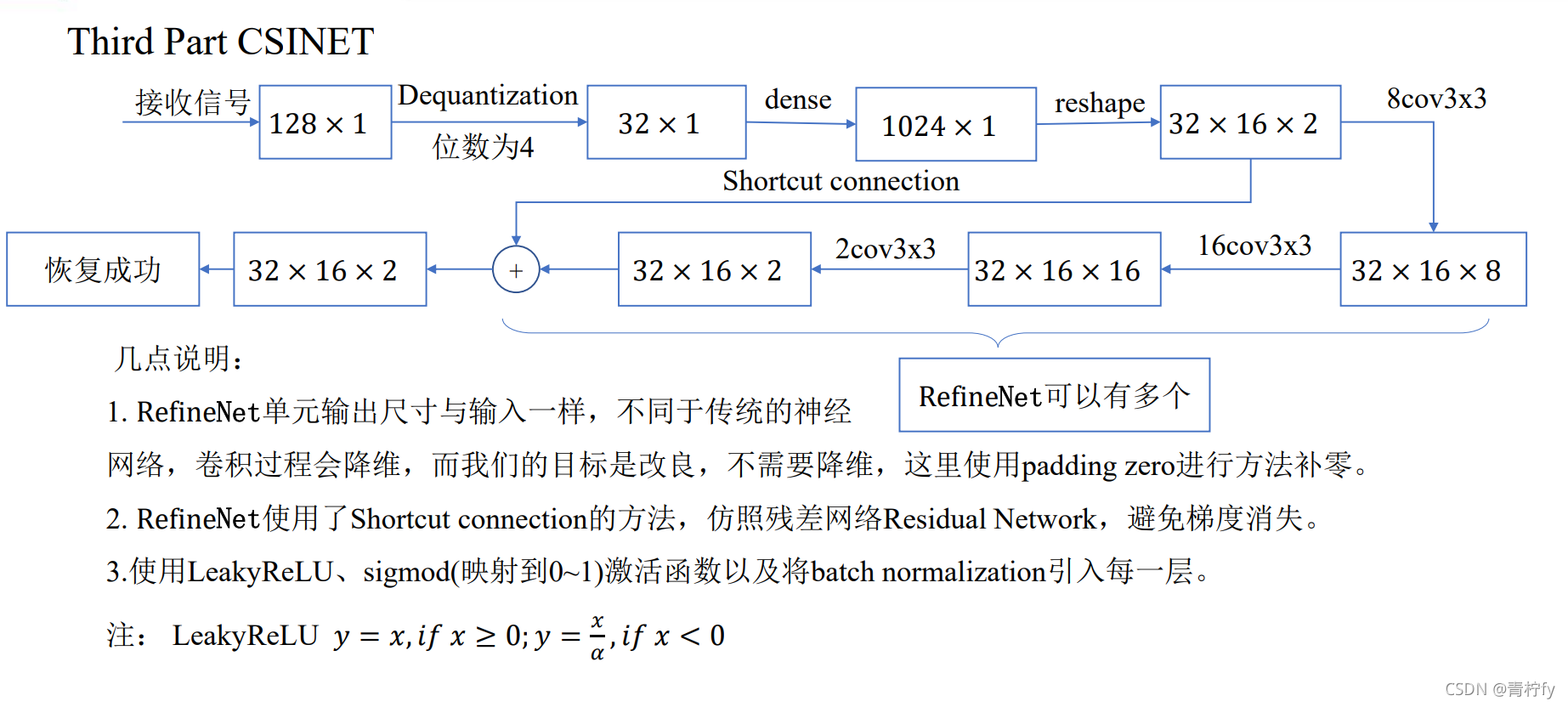


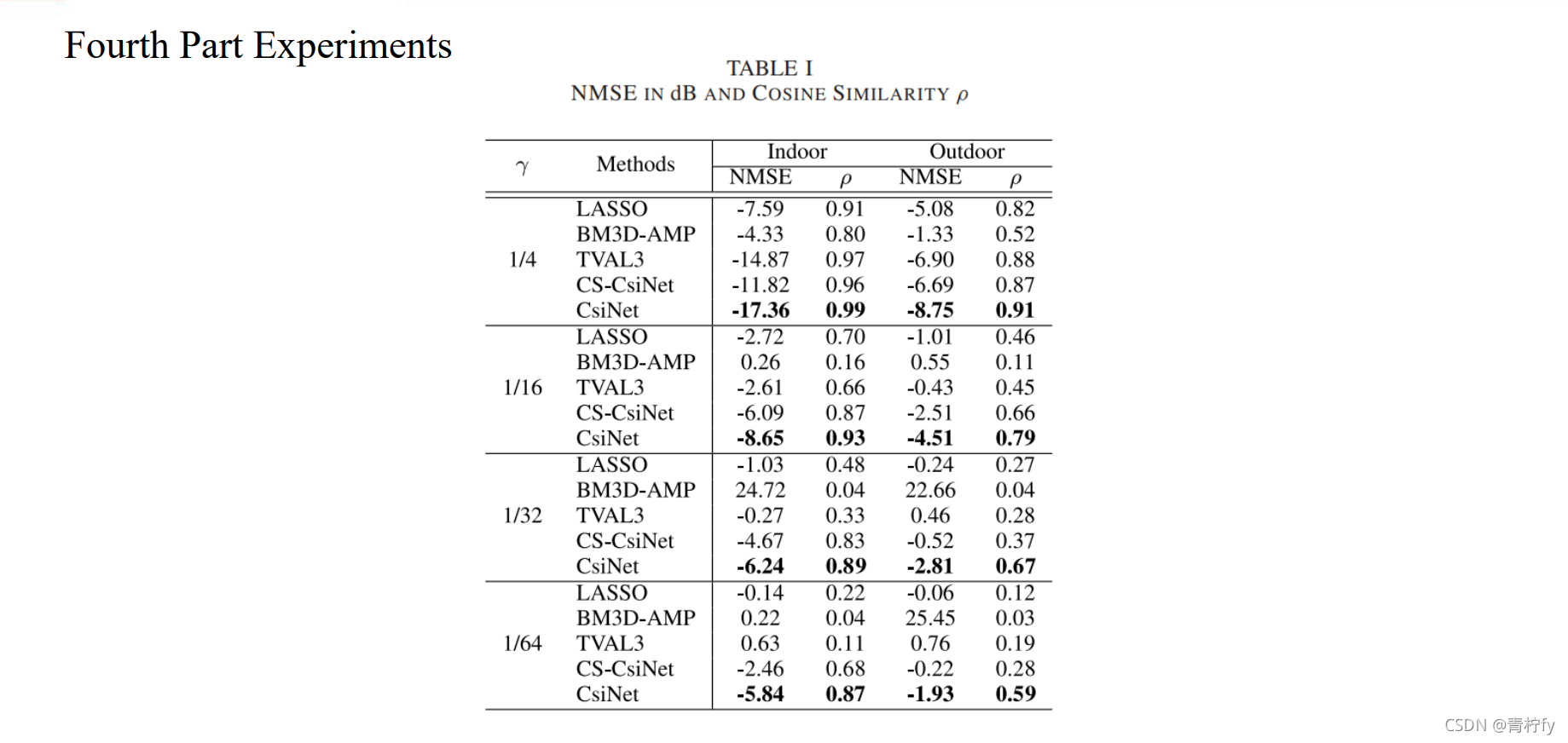


代碼分為Torch版本和TensorFlow版本,如下:
Torch版本代碼沒問題,TensorFlow版本好像有點問題,本人也是初學者,很久沒有解決,
# TensorFlow版本如下
# modelDesign 模塊
"""
Note:
1.This file is used for designing the structure of encoder and decoder.
2.The neural network structure in this model file is CsiNet, more details about CsiNet can be found in [1].
[1] C. Wen, W. Shih and S. Jin, "Deep Learning for Massive MIMO CSI Feedback", in IEEE Wireless Communications Letters, vol. 7, no. 5, pp. 748-751, Oct. 2018, doi: 10.1109/LWC.2018.2818160.
3.The output of the encoder must be the bitstream.
"""
#=======================================================================================================================
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
#=======================================================================================================================
# Number to Bit Defining Function Defining
def Num2Bit(Num, B):
# 數字轉為位元 B是位數,即十進制數轉成B位的二進制數
Num_ = Num.numpy()
bit = (np.unpackbits(np.array(Num_, np.uint8), axis=1).reshape(-1, Num_.shape[1], 8)[:, :, (8-B):]).reshape(-1,Num_.shape[1] * B)
# 直接調函式轉np.array(Num_, np.uint8)8位
bit.astype(np.float32)
return tf.convert_to_tensor(bit, dtype=tf.float32)
# Bit to Number Function Defining
def Bit2Num(Bit, B):
# 位元轉為數字 B是位數,即B位的二進制轉成十進制
Bit_ = Bit.numpy()
Bit_.astype(np.float32)
Bit_ = np.reshape(Bit_, [-1, int(Bit_.shape[1] / B), B])
num = np.zeros(shape=np.shape(Bit_[:, :, 1]))
for i in range(B):
num = num + Bit_[:, :, i] * 2 ** (B - 1 - i)
return tf.cast(num, dtype=tf.float32)
#=======================================================================================================================
#=======================================================================================================================
# Quantization and Dequantization Layers Defining
@tf.custom_gradient # 修飾函式
def QuantizationOp(x, B):
# 量化操作函式 均勻量化,四舍五入,位數為B
step = tf.cast((2 ** B), dtype=tf.float32)
result = tf.cast((tf.round(x * step - 0.5)), dtype=tf.float32)
result = tf.py_function(func=Num2Bit, inp=[result, B], Tout=tf.float32)
e = tf.exp(x)
def custom_grad(dy):
# grad = dy * (1 - 1 / (1 + e))
grad = dy
# grad = dy
return (grad, grad)
# num = tf.size(result)[0]
# result.set_shape((int(num/128),128))
# result = tf.reshape(result, (-1, 128))
return result, custom_grad
class QuantizationLayer(tf.keras.layers.Layer):
def __init__(self, B,**kwargs):
self.B = B
super(QuantizationLayer, self).__init__()
def call(self, x):
# 呼叫量化操作
return QuantizationOp(x, self.B)
def get_config(self):
# 得到配置
# Implement get_config to enable serialization. This is optional.
base_config = super(QuantizationLayer, self).get_config()
base_config['B'] = self.B
return base_config
@tf.custom_gradient
def DequantizationOp(x, B):
# 解量化操作 位數為B
x = tf.py_function(func=Bit2Num, inp=[x, B], Tout=tf.float32)
step = tf.cast((2 ** B), dtype=tf.float32)
result = tf.cast((x + 0.5) / step, dtype=tf.float32)
# 除以step是歸一化
# e = tf.exp(x)
def custom_grad(dy):
# grad = dy * (1 - 1 / (1 + e))
grad = dy
return (grad, grad)
# result = tf.reshape(result, (-1, 128))
return result, custom_grad
class DeuantizationLayer(tf.keras.layers.Layer):
# 解量化層,位數為B
def __init__(self, B,**kwargs):
self.B = B
super(DeuantizationLayer, self).__init__()
def call(self, x):
# 調用解量化操作
return DequantizationOp(x, self.B)
def get_config(self):
base_config = super(DeuantizationLayer, self).get_config()
base_config['B'] = self.B
return base_config
#=======================================================================================================================
#=======================================================================================================================
# Encoder and Decoder Function Defining
def Encoder(enc_input,num_feedback_bits):
num_quan_bits = 4 # 量化位數
def add_common_layers(y):
y = keras.layers.BatchNormalization()(y) # 批量歸一化
y = keras.layers.LeakyReLU()(y)
return y
# Leaky ReLUs
# ReLU是將所有的負值都設為零,相反,Leaky ReLU是給所有負值賦予一個非零斜率,
# 以數學的方式我們可以表示為:
# yi = xi if xi>=0
# yi = xi/ai if xi<0
# ai是(1,+∞)區間內的固定引數,
h = layers.Conv2D(3, (3, 3), padding='SAME', data_format='channels_last')(enc_input)
# 通道數(卷積核數)為3,3x3卷積核卷積,padding zeros 保持矩陣大小不變,data_format 資料格式最后一個數為通道數
# 生成三個特征層
h = add_common_layers(h) # 批量歸一化 + 激活函式leakyRULU激活
h = layers.Flatten()(h) # 把矩陣展為向量
h = layers.Dense(1024, activation='sigmoid')(h)
# 實作神經網路里的全連接層
# 將h的最后一維改成1024,并且使用'sigmoid'函式激活
h = layers.Dense(units=int(num_feedback_bits / num_quan_bits), activation='sigmoid')(h)
# 將h的最后一維改成 反饋信號最大容量位元數/量化位數 ,并且使用'sigmoid'函式激活
enc_output = QuantizationLayer(num_quan_bits)(h)
# 將h量化 位數為4 得到編碼輸出 資料總量=num_feedback_bits
return enc_output
def Decoder(dec_input,num_feedback_bits):
num_quan_bits = 4 # 量化位數4
def add_common_layers(y):
y = keras.layers.BatchNormalization()(y) # 批量歸一化
y = keras.layers.LeakyReLU()(y) # 激活函式leakyRELU
return y
h = DeuantizationLayer(num_quan_bits)(dec_input) # 解量化,量化的位數為4
# h = tf.keras.layers.Reshape((-1, int(num_feedback_bits/num_quan_bits)))(h)
h = tf.keras.layers.Reshape((-1,int(num_feedback_bits / num_quan_bits)))(h)
# 一個數是4位,總傳輸的位元數 / 4 = 傳輸的十進制數的個數,-1的含義是自動計算列數,結果應該是1,這是一個列向量
h = layers.Dense(1024, activation='sigmoid')(h)
# 使用全連接層,將列向量維度拉伸為1024,并使用激活函式'sigmoid'
h = layers.Reshape((32, 16, 2))(h)
# 將1024x1的向量,reshape成32x16x2的矩陣,相當于有兩個特征層,每一層是32x16
res_h = h
# 保留32x16x2的矩陣,之后進行shortcut connecttion操作,殘差網路,防止梯度消失
#===========================================================================
h = layers.Conv2D(8, (3, 3), padding='SAME', data_format='channels_last')(h)
# 通道數(卷積核數)為3,3x3卷積核卷積,padding zeros 保持矩陣大小不變,data_format 資料格式最后一個數為通道數
# 生成三個特征層
h = keras.layers.LeakyReLU()(h)
h = layers.Conv2D(16, (3, 3), padding='SAME', data_format='channels_last')(h)
# 通道數(卷積核數)為3,3x3卷積核卷積,padding zeros 保持矩陣大小不變,data_format 資料格式最后一個數為通道數
# 生成三個特征層
h = keras.layers.LeakyReLU()(h)
# leakyReLU 激活
# ==================================================================================
# h = layers.Conv2D(3, (3, 3), padding='SAME', data_format='channels_last')(h)
# h = keras.layers.LeakyReLU()(h)
# for i in range(1):
# x = layers.Conv2D(3, kernel_size=(3, 3), padding='same', data_format='channels_last')(h)
# x = add_common_layers(x)
# 進行3個卷積核,卷積核尺寸為3x3的卷積操作,padding補0,保持矩陣大小不變,卷積完批量歸一化,以及激活函式leakyRELU
# ===========================================================================
h = layers.Conv2D(2, kernel_size=(3, 3), padding='same', data_format='channels_last')(h)
# 2卷積核,卷積核尺寸為3x3的卷積操作,padding補0,保持矩陣大小不變,此時大小應該為32x16x2
dec_output = keras.layers.Add()([res_h, h])
# 與之前的h相加,殘差網路,防止梯度消失
return dec_output
#=======================================================================================================================
#=======================================================================================================================
# NMSE Function Defining
def NMSE(x, x_hat):
# 計算NMSE均方誤差,x為實際值,x_hat為估計值
x_real = np.reshape(x[:, :, :, 0], (len(x), -1))
# 取x的實部層 len(x)是回傳矩陣長度,不是元素個數
x_imag = np.reshape(x[:, :, :, 1], (len(x), -1))
# 取x的虛部層
x_hat_real = np.reshape(x_hat[:, :, :, 0], (len(x_hat), -1))
x_hat_imag = np.reshape(x_hat[:, :, :, 1], (len(x_hat), -1))
x_C = x_real - 0.5 + 1j * (x_imag - 0.5)
# 實部虛部同時減0.5是將(0,1)的數搬移至(-0.5,0.5),使其中心為0
x_hat_C = x_hat_real - 0.5 + 1j * (x_hat_imag - 0.5)
power = np.sum(abs(x_C) ** 2, axis=1)
# axis= 1行方向相加
mse = np.sum(abs(x_C - x_hat_C) ** 2, axis=1)
nmse = np.mean(mse / power)
return nmse
def get_custom_objects():
return {"QuantizationLayer":QuantizationLayer,"DeuantizationLayer":DeuantizationLayer}
# 得到量化層和得到解量化層
# modeltrain 模塊
#==================================================================================
import numpy as np
from tensorflow import keras
from modelDesign import Encoder, Decoder, NMSE#*
import scipy.io as sio
#==================================================================================
# Parameters Setting
NUM_FEEDBACK_BITS = 128 # 反饋位元數為128 = M 壓縮率為128/1024=0.125 即1/8
CHANNEL_SHAPE_DIM1 = 32 # 32x16x2=1024 N = 1024
CHANNEL_SHAPE_DIM2 = 16
CHANNEL_SHAPE_DIM3 = 2
#=======================================================================================================================
import h5py
mat = h5py.File('./channelData/Hdata.mat',"r")
data = np.transpose(mat['H_train']) # shape=(320000, 1024)
# Data Loading
# mat = sio.loadmat('./channelData/Hdata.mat') # 讀取信道資料
# data = mat
# data = mat['Hdata.mat']
data = data.astype('float32')
data = np.reshape(data, (len(data), CHANNEL_SHAPE_DIM1, CHANNEL_SHAPE_DIM2, CHANNEL_SHAPE_DIM3))
# print(np.size(data,1))
# 重新改變資料的維數 reshape
#=======================================================================================================================
# Model Constructing
# Encoder
encInput = keras.Input(shape=(CHANNEL_SHAPE_DIM1, CHANNEL_SHAPE_DIM2, CHANNEL_SHAPE_DIM3))
# 設定編碼輸入
encOutput = Encoder(encInput, NUM_FEEDBACK_BITS)
# 進行編碼,反饋資料為512個bit
encModel = keras.Model(inputs=encInput, outputs=encOutput, name='Encoder')
print(encModel.summary())
# 設定編碼模型,對應輸入和輸出l
# Decoder
decInput = keras.Input(shape=(NUM_FEEDBACK_BITS,))
# 設定解碼輸入,輸入為512個bit數
decOutput = Decoder(decInput, NUM_FEEDBACK_BITS)
# 進行解碼
decModel = keras.Model(inputs=decInput, outputs=decOutput, name="Decoder")
print(decModel.summary())
# 設定解碼模型,對應輸入和輸出
# Autoencoder 設定自動編碼器模型
autoencoderInput = keras.Input(shape=(CHANNEL_SHAPE_DIM1, CHANNEL_SHAPE_DIM2, CHANNEL_SHAPE_DIM3))
# 設定自動編碼器模型的輸入
autoencoderOutput = decModel(encModel(autoencoderInput))
# 進行自動編碼,即先編碼再解碼
autoencoderModel = keras.Model(inputs=autoencoderInput, outputs=autoencoderOutput, name='Autoencoder')
# 設定自動編碼模型,對應輸入和輸出
# Comliling
autoencoderModel.compile(optimizer='adam', loss='mse')
# 配置訓練函式,優化器選用'adam',損失函式選用mse即均方誤差
print(autoencoderModel.summary())
# 輸出模型各層的引數狀況
#==================================================================================
# Model Training 開始訓練模型
autoencoderModel.fit(x=data, y=data, batch_size=16, epochs=2, verbose=1, validation_split=0.05)
# 模型擬合 批量數為64 代數為2 verbose = 1 為輸出進度條記錄 95%訓練 5%檢驗
#==================================================================================
# Model Saving
# Encoder Saving
encModel.save('./modelSubmit/encoder.h5')
# Decoder Saving
decModel.save('./modelSubmit/decoder.h5')
#==================================================================================
# Model Testing
H_test = data
H_pre = autoencoderModel.predict(H_test, batch_size=512) # 之前為512
print('NMSE = ' + np.str(NMSE(H_test, H_pre)))
print('Training finished!')
#==================================================================================
# modelEvalEnc.py
#==================================================================================
import numpy as np
import tensorflow as tf
from modelDesign import *
import scipy.io as sio
#==================================================================================
# Parameters Setting
NUM_FEEDBACK_BITS = 128
CHANNEL_SHAPE_DIM1 = 32
CHANNEL_SHAPE_DIM2 = 16
CHANNEL_SHAPE_DIM3 = 2
#==================================================================================
# Data Loading
import h5py
# MATLAB v7版本,之前那個函式無法讀資料
data = h5py.File('./channelData/Hdata.mat')['H_train'].value
data = data.astype('float32')
data = np.reshape(data, (len(data), CHANNEL_SHAPE_DIM1, CHANNEL_SHAPE_DIM2, CHANNEL_SHAPE_DIM3))
H_test = data # 原始的data作為測驗集
#==================================================================================
# Model Loading and Encoding
# 模型加載和編碼
encoder_address = './modelSubmit/encoder.h5'
_custom_objects = get_custom_objects()
# 以字典形式來指定目標層layer或目標函式loss,相當于目標層是量化之后
encModel = tf.keras.models.load_model(encoder_address, custom_objects=_custom_objects)
# 加載模型,即模型從編碼到量化完成這部分
encode_feature = encModel.predict(H_test)
# 使用模型進行訓練
print("Feedback bits length is ", np.shape(encode_feature)[-1])
# 看輸出是不是512維的向量
np.save('./encOutput.npy', encode_feature)
# 以npy格式保存Feedback bits,即編碼量化后的資料
print('Finished!')
#==================================================================================
# modelEvalDec.py
#==================================================================================
import numpy as np
import tensorflow as tf
from modelDesign import *
import scipy.io as sio
#==================================================================================
# Parameters Setting
NUM_FEEDBACK_BITS = 128
CHANNEL_SHAPE_DIM1 = 32
CHANNEL_SHAPE_DIM2 = 16
CHANNEL_SHAPE_DIM3 = 2
#==================================================================================
# Data Loading
import h5py
data = h5py.File('./channelData/Hdata.mat')['H_train'].value
data = data.astype('float32')
data = np.reshape(data, (len(data), CHANNEL_SHAPE_DIM1, CHANNEL_SHAPE_DIM2, CHANNEL_SHAPE_DIM3))
H_test = data
# encOutput Loading
encode_feature = np.load('./encOutput.npy')
# 加載編碼后的資料
#==================================================================================
# Model Loading and Decoding
decoder_address = './modelSubmit/decoder.h5'
_custom_objects = get_custom_objects()
# 以字典形式來指定目標層layer或目標函式loss,相當于模型是從解量化開始
model_decoder = tf.keras.models.load_model(decoder_address, custom_objects=_custom_objects)
# 加載模型,即模型從解量化到解碼完成這部分
H_pre = model_decoder.predict(encode_feature)
# 用模型進行解碼
# NMSE 求解均方誤差
if (NMSE(H_test, H_pre) < 0.1):
print('Valid Submission')
print('The Score is ' + np.str(1.0 - NMSE(H_test, H_pre)))
print('Finished!')
#==================================================================================
# Torch版本如下
# modelDesign.py
#=======================================================================================================================
#=======================================================================================================================
import numpy as np
import torch.nn as nn
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
NUM_FEEDBACK_BITS = 128 #pytorch版本一定要有這個引數
CHANNEL_SHAPE_DIM1 = 16 # Nc
CHANNEL_SHAPE_DIM2 = 32 # Nt 發射天線數
CHANNEL_SHAPE_DIM3 = 2 # 實部虛部
BATCH_SIZE = 128 # 原始為128
#=======================================================================================================================
#=======================================================================================================================
# Number to Bit Defining Function Defining
def Num2Bit(Num, B):
# 十進制數轉為二進制數,位數為B
Num_ = Num.type(torch.uint8)
def integer2bit(integer, num_bits=B * 2):
dtype = integer.type()
exponent_bits = -torch.arange(-(num_bits - 1), 1).type(dtype)
# 7 6 5 4 3 2 1 0
exponent_bits = exponent_bits.repeat(integer.shape + (1,))
out = integer.unsqueeze(-1) // 2 ** exponent_bits
# integer的最后一個維度增加一維
# 整數除以2的冪次取商,商模2取余數
# 例如 整數5 5/1=5 5/2=2 5/4=1 5/8=0
# 5%2=1 2%2=0 1%2=1 0%2=0
# 倒序排列 0101 轉為了二進制
return (out - (out % 1)) % 2
bit = integer2bit(Num_)
bit = (bit[:, :, B:]).reshape(-1, Num_.shape[1] * B) # 數的個數 x B
return bit.type(torch.float32)
def Bit2Num(Bit, B):
# B位二進制數轉為十進制數
Bit_ = Bit.type(torch.float32)
Bit_ = torch.reshape(Bit_, [-1, int(Bit_.shape[1] / B), B])
num = torch.zeros(Bit_[:, :, 1].shape).cuda()
for i in range(B):
num = num + Bit_[:, :, i] * 2 ** (B - 1 - i)
# 0101 轉為 十進制
# 1*1+0*2+1*4+0*8 = 0
return num
#=======================================================================================================================
#=======================================================================================================================
# Quantization and Dequantization Layers Defining
class Quantization(torch.autograd.Function):
# 創建torch.autograd.Function類的一個子類
# 必須是staticmethod
@staticmethod # 靜態方法
# 第一個是ctx,第二個是input,其他是可選引數,
# ctx在這里類似self,ctx的屬性可以在backward中呼叫,保存前向傳播的變數,
# 自己定義的Function中的forward()方法,
# 所有的Variable引數將會轉成tensor!因此這里的input也是tensor.在傳入forward前,
# autograd engine會自動將Variable unpack成Tensor,張量
def forward(ctx, x, B):
ctx.constant = B
step = 2 ** B
out = torch.round(x * step - 0.5) # 四舍五入 0-1轉為0-16 再減0.5 相當于向下取值
out = Num2Bit(out, B) # 轉為二進制
return out
@staticmethod
def backward(ctx, grad_output):
# return as many input gradients as there were arguments.
# Gradients of constant arguments to forward must be None.
# Gradient of a number is the sum of its B bits.
b, _ = grad_output.shape
grad_num = torch.sum(grad_output.reshape(b, -1, ctx.constant), dim=2) / ctx.constant
return grad_num, None
class Dequantization(torch.autograd.Function):
# 解量化
@staticmethod
def forward(ctx, x, B):
ctx.constant = B
step = 2 ** B
out = Bit2Num(x, B) # 轉為數字 0-16
out = (out + 0.5) / step # 補償0.5,歸一化到0-1
return out
@staticmethod
def backward(ctx, grad_output):
# return as many input gradients as there were arguments.
# Gradients of non-Tensor arguments to forward must be None.
# repeat the gradient of a Num for B time.
b, c = grad_output.shape
grad_output = grad_output.unsqueeze(2) / ctx.constant
grad_bit = grad_output.expand(b, c, ctx.constant)
return torch.reshape(grad_bit, (-1, c * ctx.constant)), None
class QuantizationLayer(nn.Module):
def __init__(self, B):
super(QuantizationLayer, self).__init__()
self.B = B
def forward(self, x):
out = Quantization.apply(x, self.B)
return out
class DequantizationLayer(nn.Module):
def __init__(self, B):
super(DequantizationLayer, self).__init__()
self.B = B
def forward(self, x):
out = Dequantization.apply(x, self.B)
return out
#=======================================================================================================================
#=======================================================================================================================
# Encoder and Decoder Class Defining
# 編碼和解碼
def conv3x3(in_channels, out_channels, stride=1):
# 定義3x3卷積,輸入通道,輸出通道,即有幾個卷積核,步長為1
return nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=True)
# 卷積核為3x3 步長為1 padding使卷積后維數相同 加偏置bias
class Encoder(nn.Module):
num_quan_bits = 4 # 量化位數為4
def __init__(self, feedback_bits): # 反饋位數為128
super(Encoder, self).__init__()
self.conv1 = conv3x3(2, 2) # 定義輸入為2通道輸出為2通道的卷積
self.conv2 = conv3x3(2, 2) # 定義輸入為2通道輸出為2通道的卷積
self.fc = nn.Linear(1024, int(feedback_bits / self.num_quan_bits))
# 定義全連接網路,1024轉為128/4=32
self.sig = nn.Sigmoid()
# 定義激活函式
self.quantize = QuantizationLayer(self.num_quan_bits)
# 定義量化函式
def forward(self, x):
x = x.permute(0, 3, 1, 2)
# 維數換位,將通道數換到前面
########################################
# 第一次
x = self.conv1(x) # 卷積
# x = nn.BatchNorm2d(x).to(device=device)
x = F.leaky_relu(x, negative_slope=0.3)
#########################################
# 第二次
x = self.conv2(x) # 卷積
# x = nn.BatchNorm2d(x).to(device=device)
out = F.leaky_relu(x, negative_slope=0.3)
#########################################
# out = F.relu() # 卷積 加 relu
# out = F.relu(self.conv2(out)) # 卷積 加 relu
out = out.contiguous().view(-1, 1024)
# 不改變資料維數,只是換一種索引方法,展成1024
# 需使用contiguous().view(),或者可修改為reshape
out = self.fc(out) # 呼叫全連接網路轉為32
out = self.sig(out) # 呼叫SIGMOD函式激活
out = self.quantize(out) # 量化
return out
class Decoder(nn.Module):
num_quan_bits = 4 # 量化位數為4
def __init__(self, feedback_bits):
super(Decoder, self).__init__()
self.feedback_bits = feedback_bits # 定義反饋位元數為128
self.dequantize = DequantizationLayer(self.num_quan_bits) # 定義解量化操作
self.multiConvs = nn.ModuleList() # 多次卷積函式
self.fc = nn.Linear(int(feedback_bits / self.num_quan_bits), 1024)
# 定義從32到1024的全連接層
self.out_cov = conv3x3(2, 2) # 定義輸入2通道 輸出2通道的卷積
self.sig = nn.Sigmoid() # 定義sigmod
for _ in range(3):
self.multiConvs.append(nn.Sequential(
conv3x3(2, 8),
# nn.BatchNorm2d(num_features=BATCH_SIZE*8*CHANNEL_SHAPE_DIM1*CHANNEL_SHAPE_DIM2, affine=True),
nn.LeakyReLU(negative_slope=0.3),
conv3x3(8, 16),
# nn.BatchNorm2d(num_features=BATCH_SIZE*8*CHANNEL_SHAPE_DIM1*CHANNEL_SHAPE_DIM2, affine=True),
nn.LeakyReLU(negative_slope=0.3),
conv3x3(16, 2)))
# nn.BatchNorm2d(num_features=BATCH_SIZE*8*CHANNEL_SHAPE_DIM1*CHANNEL_SHAPE_DIM2, affine=True)))
# 進行三次卷積通道數 2->8->16->2
def forward(self, x):
out = self.dequantize(x) # 先解量化
out = out.contiguous().view(-1, int(self.feedback_bits / self.num_quan_bits))
# 轉成32
# 需使用contiguous().view(),或者可修改為reshape
out = self.sig(self.fc(out))
# 32轉1024
out = out.contiguous().view(-1, 2, 16, 32)
# 將通道提前到最前面
# 需使用contiguous().view(),或者可修改為reshape
#############################################
# 第一次refine net
residual = out
for i in range(3):
out = self.multiConvs[i](out)
out = residual + out
out = F.leaky_relu(out, negative_slope=0.3)
# 第二次refine net
residual = out
for i in range(3):
out = self.multiConvs[i](out)
out = residual + out
################################################
out = self.out_cov(out)
# out = F.batch_norm(out)
# 輸入2 輸出2 卷一次
out = self.sig(out)
# 歸一化
out = out.permute(0, 2, 3, 1)
# 將通道換到最后一維
return out
class AutoEncoder(nn.Module):
def __init__(self, feedback_bits):
super(AutoEncoder, self).__init__()
self.encoder = Encoder(feedback_bits) # 定義編碼函式
self.decoder = Decoder(feedback_bits) # 定義解碼函式
def forward(self, x):
feature = self.encoder(x) # 呼叫編碼
out = self.decoder(feature) # 呼叫解碼
return out
#=======================================================================================================================
#=======================================================================================================================
# NMSE Function Defining
def NMSE(x, x_hat):
# 計算NMSE均方誤差,x為實際值,x_hat為估計值
x_real = np.reshape(x[:, :, :, 0], (len(x), -1))
# 取x的實部層 len(x)是回傳矩陣長度,不是元素個數
x_imag = np.reshape(x[:, :, :, 1], (len(x), -1))
# 取x的虛部層
x_hat_real = np.reshape(x_hat[:, :, :, 0], (len(x_hat), -1))
# 實部虛部同時減0.5是將(0,1)的數搬移至(-0.5,0.5),使其中心為0
x_hat_imag = np.reshape(x_hat[:, :, :, 1], (len(x_hat), -1))
x_C = x_real - 0.5 + 1j * (x_imag - 0.5)
x_hat_C = x_hat_real - 0.5 + 1j * (x_hat_imag - 0.5)
power = np.sum(abs(x_C) ** 2, axis=1)
# axis= 1表示對第二外層[]里的最大單位塊做塊與塊之間的運算,同時移除第二外層[]
mse = np.sum(abs(x_C - x_hat_C) ** 2, axis=1)
nmse = np.mean(mse / power)
return nmse
def Score(NMSE):
score = 1 - NMSE
return score
#=======================================================================================================================
#=======================================================================================================================
# Data Loader Class Defining
class DatasetFolder(Dataset):
def __init__(self, matData):
self.matdata = matData # 矩陣類資料
def __getitem__(self, index):
return self.matdata[index] # 索引得到元素
def __len__(self):
return self.matdata.shape[0]# 求len
# modelTrain.py
#=======================================================================================================================
#=======================================================================================================================
import numpy as np
import torch
from modelDesign import AutoEncoder,DatasetFolder #*
import os
import torch.nn as nn
import scipy.io as sio # 無法匯入MATLABv7版本的mat
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#=======================================================================================================================
#=======================================================================================================================
# Parameters Setting for Data
NUM_FEEDBACK_BITS = 128 # 反饋資料位元數
CHANNEL_SHAPE_DIM1 = 16 # Nc
CHANNEL_SHAPE_DIM2 = 32 # Nt 發射天線數
CHANNEL_SHAPE_DIM3 = 2 # 實部虛部
# Parameters Setting for Training
BATCH_SIZE = 128 # 原始為128
EPOCHS = 1000
LEARNING_RATE = 1e-3
PRINT_RREQ = 100 # 每100個資料輸出一次
torch.manual_seed(1) # 隨機種子初始化神經網路
#=======================================================================================================================
#=======================================================================================================================
# Data Loading
# mat = sio.loadmat('channelData/Hdata.mat')
# # data = mat['H_4T4R']
import h5py
mat = h5py.File('./channelData/Hdata.mat',"r") # 讀資料
data = np.transpose(mat['H_train']) # shape=(320000, 1024)
data = data.astype('float32')
data = np.reshape(data, (len(data), CHANNEL_SHAPE_DIM1, CHANNEL_SHAPE_DIM2, CHANNEL_SHAPE_DIM3))
# data 320000x32x16x2
# data = np.transpose(data, (0, 3, 1, 2))
split = int(data.shape[0] * 0.7)
# 70% 資料訓練,30% 資料測驗
data_train, data_test = data[:split], data[split:]
train_dataset = DatasetFolder(data_train)
# 將data_train轉為DatasetFolder類,可以呼叫其中的方法
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0, pin_memory=True)
# 320000*0.7/16 = 14000
# 每個batch加載多少個資料 設定為True時會在每個epoch重新打亂資料 用多少個子行程加載資料,0表示資料將在主行程中加載(默認: 0)
# 如果設定為True,那么data loader將會在回傳它們之前,將tensors拷貝到CUDA中的固定記憶體(CUDA pinned memory)中
test_dataset = DatasetFolder(data_test)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0, pin_memory=True)
#=======================================================================================================================
#=======================================================================================================================
# Model Constructing
autoencoderModel = AutoEncoder(NUM_FEEDBACK_BITS).to(device) # 呼叫自動編碼解碼函式
autoencoderModel = autoencoderModel.cuda().to(device) # 轉為GPU
criterion = nn.MSELoss().cuda().to(device) # 用MSE作為損失函式 轉為GPU
optimizer = torch.optim.Adam(autoencoderModel.parameters(), lr=LEARNING_RATE)
# 優化器 :Adam 優化演算法 # 呼叫網路引數
#=======================================================================================================================
#=======================================================================================================================
# Model Training and Saving
bestLoss = 1 # 最大損失,小于最大損失才會保存模型
for epoch in range(EPOCHS):
autoencoderModel.train().to(device)
# 開始訓練 啟用 Batch Normalization 和 Dropout,
# Dropout是隨機取一部分網路連接來訓練更新引數
for i, autoencoderInput in enumerate(train_loader):
# 遍歷訓練資料
autoencoderInput = autoencoderInput.cuda().to(device) # 轉為GPU格式
autoencoderOutput = autoencoderModel(autoencoderInput).to(device) # 使用模型求輸出
loss = criterion(autoencoderOutput, autoencoderInput).to(device) # 輸入輸出傳入評價函式 求均方誤差
optimizer.zero_grad() # 清空過往梯度;
loss.backward() # 反向傳播,計算當前梯度;
optimizer.step() # 根據梯度更新網路引數
if i % PRINT_RREQ == 0:
print('Epoch: [{0}][{1}/{2}]\t' 'Loss {loss:.4f}\t'.format(epoch, i, len(train_loader), loss=loss.item()))
# Model Evaluating 模型評估
autoencoderModel.eval().to(device)
# 不啟用 Batch Normalization 和 Dropout
# 是保證BN層能夠用全部訓練資料的均值和方差,即測驗程序中要保證BN層的均值和方差不變,
totalLoss = 0
# torch.no_grad()內的內容,不被track梯度
# 該計算不會在反向傳播中被記錄,
with torch.no_grad():
for i, autoencoderInput in enumerate(test_loader):
# 加載測驗資料
autoencoderInput = autoencoderInput.cuda().to(device) # 轉為GPU格式
autoencoderOutput = autoencoderModel(autoencoderInput).to(device) # 求輸出
totalLoss += criterion(autoencoderOutput, autoencoderInput).item() * autoencoderInput.size(0)
# size(0)就是batch size的大小
# 用測驗資料來測驗模型的損失
averageLoss = totalLoss / len(test_dataset) # 求每一個EPOCHS后的平均損失
if averageLoss < bestLoss: # 平均損失如果小于1才會保存模型
# Model saving
# Encoder Saving
torch.save({'state_dict': autoencoderModel.encoder.state_dict(), }, './modelSubmit/encoder.pth.tar')
# Decoder Saving
torch.save({'state_dict': autoencoderModel.decoder.state_dict(), }, './modelSubmit/decoder.pth.tar')
print("Model saved")
bestLoss = averageLoss # 更新最大損失,使損失小于該值是才保存模型
#=======================================================================================================================
#=======================================================================================================================
# modelEvalEnc.py
#=======================================================================================================================
#=======================================================================================================================
import numpy as np
from modelDesign import *
import torch
import scipy.io as sio
#=======================================================================================================================
#=======================================================================================================================
# Parameters Setting
NUM_FEEDBACK_BITS = NUM_FEEDBACK_BITS #128
CHANNEL_SHAPE_DIM1 = 16
CHANNEL_SHAPE_DIM2 = 32
CHANNEL_SHAPE_DIM3 = 2
#=======================================================================================================================
#=======================================================================================================================
# Data Loading
import h5py
mat = h5py.File('./channelData/Hdata.mat',"r")
data = np.transpose(mat['H_train']) # shape=(320000, 1024)
data = data.astype('float32')
data = np.reshape(data, (len(data), CHANNEL_SHAPE_DIM1, CHANNEL_SHAPE_DIM2, CHANNEL_SHAPE_DIM3))
# reshape 到320000x32x16x2
H_test = data
test_dataset = DatasetFolder(H_test)
# 轉成DatasetFolder類
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=512, shuffle=False, num_workers=0, pin_memory=True)
# 轉成方便訓練的資料格式 一次編碼512組資料 每次不打亂資料 用多少個子行程加載資料,0表示資料將在主行程中加載(默認: 0)
# 如果設定為True,那么data loader將會在回傳它們之前,將tensors拷貝到CUDA中的固定記憶體(CUDA pinned memory)中
#=======================================================================================================================
#=======================================================================================================================
# Model Loading
autoencoderModel = AutoEncoder(NUM_FEEDBACK_BITS).cuda()
model_encoder = autoencoderModel.encoder # 取編碼的這個屬性
model_encoder.load_state_dict(torch.load('./modelSubmit/encoder.pth.tar')['state_dict'])
# load_state_dict是net的一個方法
# 是將torch.load加載出來的資料加載到net中
# load
# 加載的是訓練好的模型
print("weight loaded")
#=======================================================================================================================
#=======================================================================================================================
# Encoding
model_encoder.eval()
encode_feature = []
with torch.no_grad():
for i, autoencoderInput in enumerate(test_loader):
# 一次處理512組資料 一共處理625次 共計320000組資料
autoencoderInput = autoencoderInput.cuda()
autoencoderOutput = model_encoder(autoencoderInput)
autoencoderOutput = autoencoderOutput.cpu().numpy()
if i == 0:
encode_feature = autoencoderOutput
else:
encode_feature = np.concatenate((encode_feature, autoencoderOutput), axis=0)
# concatenate陣列拼接 把每一次得到的結果合并起來 按列的方向合并
print("feedbackbits length is ", np.shape(encode_feature)[-1])
np.save('./encOutput.npy', encode_feature)
print('Finished!')
#=======================================================================================================================
#=======================================================================================================================
# modelEvalDec.py
#=======================================================================================================================
#=======================================================================================================================
import numpy as np
from modelDesign import *
import torch
import scipy.io as sio
#=======================================================================================================================
#=======================================================================================================================
# Parameters Setting
NUM_FEEDBACK_BITS = NUM_FEEDBACK_BITS #128
CHANNEL_SHAPE_DIM1 = 16
CHANNEL_SHAPE_DIM2 = 32
CHANNEL_SHAPE_DIM3 = 2
#=======================================================================================================================
#=======================================================================================================================
# Data Loading
import h5py
mat = h5py.File('./channelData/Hdata.mat',"r")
data = np.transpose(mat['H_train']) # shape=(320000, 1024)
data = data.astype('float32')
data = np.reshape(data, (len(data), CHANNEL_SHAPE_DIM1, CHANNEL_SHAPE_DIM2, CHANNEL_SHAPE_DIM3))
H_test = data
# encOutput Loading
encode_feature = np.load('./encOutput.npy')
test_dataset = DatasetFolder(encode_feature)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=512, shuffle=False, num_workers=0, pin_memory=True)
#=======================================================================================================================
#=======================================================================================================================
# Model Loading and Decoding
autoencoderModel = AutoEncoder(NUM_FEEDBACK_BITS).cuda()
model_decoder = autoencoderModel.decoder
model_decoder.load_state_dict(torch.load('./modelSubmit/decoder.pth.tar')['state_dict'])
print("weight loaded")
model_decoder.eval()
H_pre = []
with torch.no_grad():
for i, decoderOutput in enumerate(test_loader):
# convert numpy to Tensor
# 一次解碼512組資料 一共解碼625次
decoderOutput = decoderOutput.cuda()
output = model_decoder(decoderOutput)
output = output.cpu().numpy()
if i == 0:
H_pre = output
else:
H_pre = np.concatenate((H_pre, output), axis=0)
# axis=0 按列的方向合并
# if (NMSE(H_test, H_pre) < 0.1):
# # 計算均方誤差
# print('Valid Submission')
# print('The Score is ' + np.str(1.0 - NMSE(H_test, H_pre)))
# print('Finished!')
print(np.str(1.0 - NMSE(H_test, H_pre)))
#=======================================================================================================================
#=======================================================================================================================
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301426.html
標籤:AI