您或許知道,作者后續分享網路安全的文章會越來越少,但如果您想學習人工智能和安全結合的應用,您就有福利了,作者將重新打造一個《當人工智能遇上安全》系列博客,詳細介紹人工智能與安全相關的論文、實踐,并分享各種案例,涉及惡意代碼檢測、惡意請求識別、入侵檢測、對抗樣本等等,只想更好地幫助初學者,更加成體系的分享新知識,該系列文章會更加聚焦,更加學術,更加深入,也是作者的慢慢成長史,換專業確實挺難的,系統安全也是塊硬骨頭,但我也試試,看看自己未來四年究竟能將它學到什么程度,漫漫長征路,偏向虎山行,享受程序,一起加油~
前一篇文章分享了張超大佬的兩次報告,帶領大家了解Fuzzing,第一篇是學術論文相關的“資料流敏感的漏洞挖掘方法”,第二篇是安全攻防實戰相關的“智能軟體漏洞攻防”,這篇文章將分享機器學習在安全領域的應用,并復現一個基于機器學習(邏輯回歸)的惡意請求識別,本文參考學習了大神們的總結,并復現總結相關知識,參考文獻見后,基礎性入門文章,只希望對初學者有所幫助,
文章目錄
- 一.安全領域中的機器學習
- 1.身份識別與認證
- 2.社會工程學
- 3.網路安全
- 4.Web安全
- 5.安全漏洞與惡意代碼
- 6.入侵檢測與防御
- 二.基于機器學習的惡意代碼檢測
- 1.傳統的惡意代碼檢測
- 2.基于機器學習的惡意代碼檢測
- 3.機器學習在安全領域的特點及難點
- 三.邏輯回歸識別網站惡意請求
- 1.資料集
- 2.N-grams和TF-IDF結合構造特征矩陣
- 3.訓練模型
- 4.檢測新資料集是惡意請求還是正常請求
- 5.完整代碼
- 四.總結
作者作為網路安全的小白,分享一些自學基礎教程給大家,主要是在線筆記,希望您們喜歡,同時,更希望您能與我一起操作和進步,后續將深入學習AI安全和系統安全知識并分享相關實驗,總之,希望該系列文章對博友有所幫助,寫文不易,大神們不喜勿噴,謝謝!如果文章對您有幫助,將是我創作的最大動力,點贊、評論、私聊均可,一起加油喔!
前文推薦:
- [當人工智能遇上安全] 1.人工智能真的安全嗎?浙大團隊外灘大會分享AI對抗樣本技術
- [當人工智能遇上安全] 2.清華張超老師 - GreyOne: Discover Vulnerabilities with Data Flow Sensitive Fuzzing
- [當人工智能遇上安全] 3.安全領域中的機器學習及機器學習惡意請求識別案例分享
一.安全領域中的機器學習
機器學習方法是計算機利用已有的資料(經驗),訓練得出某種模型,并利用此模型預測未來的一種方法,機器學習學科融合了數學中的多個領域,主要包括統計學、概率論、線性代數以及數學計算,機器學習中的“訓練”與“預測”程序可以對應到人類的“歸納”和“推測”程序,如下圖所示,
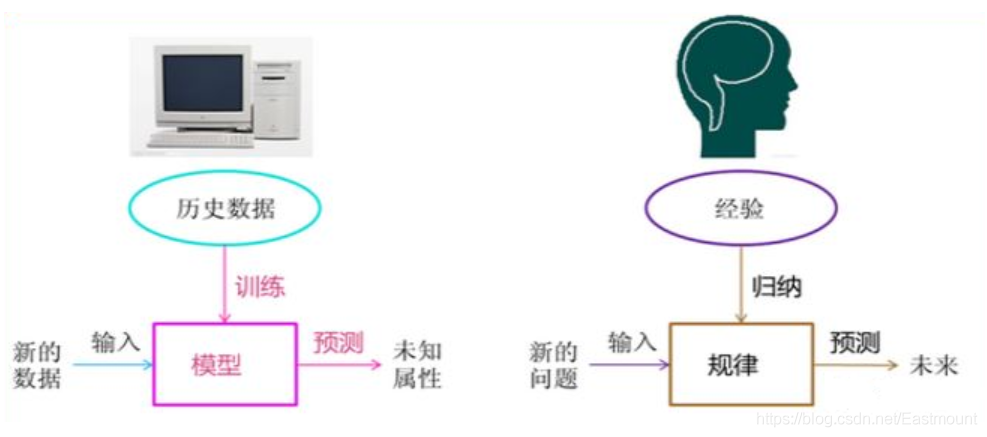
機器學習和模式識別、統計學習、資料挖掘、計算機視覺,語音識別,自然語言處理等領域有著很深的聯系,從范圍上來說,機器學習跟模式識別、統計學習、資料挖掘是類似的,同時,機器學習與其他領域的處理技術的結合,形成了計算機視覺、語音識別、自然語言處理等交叉學科,一般說資料挖掘時,可以等同于說機器學習,我們平常所說的機器學習應用,應該是通用的,不僅僅局限在結構化資料,還有影像、音頻、視頻等應用,
- 模式識別 ≈ 機器學習 + 工業應用
- 資料挖掘 ≈ 機器學習 + 資料庫
- 統計學習 ≈ 機器學習 + 數理統計
- 計算機視覺 ≈ 機器學習 + 影像處理 + 視頻處理
- 語音識別 ≈ 機器學習 + 語音處理
- 自然語言處理 ≈ 機器學習 + 文本處理

機器學習能夠深入挖掘大資料價值,被廣泛用于各個領域,同時在網路安全領域也有相關的應用,為了更清晰地闡述機器學習在安全攻防領域的實際應用與解決方案,如下圖所示,FreeBuf官網匯總了六大安全領域,分別是身份識別與認證、社會工程學、網路安全、 Web安全、安全漏洞與惡意代碼、入侵檢測與防御,且在每一領域列舉了典型的應用案例,
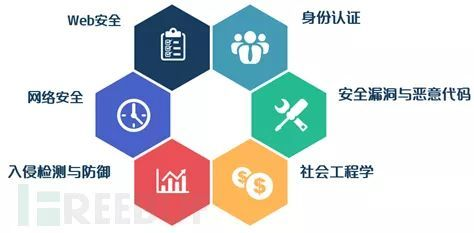
PS:下面這小部分內容參考FreeBuf的文章,推薦大家閱讀,作者也嘗試了總結,但總不盡如人意,看看大牛寫得吧!
- 機器學習在安全攻防場景的應用與分析 - 騰訊云FreeBuf官方
1.身份識別與認證
身份識別與認證是AI運用較為多的領域,除了現有的各種人臉影像識別,語音聲波識別,例外行為檢測等AI應用之外,本部分將列舉“驗證碼破解”與“惡意用戶識別”兩例,
身份認證——驗證碼破解
2017年6月,騰訊守護者計劃安全團隊協助警方打掉市面上最大打碼平臺“快啊答題”,挖掘出一條從撞庫盜號、破解驗證碼到販賣公民資訊、實施網路詐騙的全鏈條黑產,在驗證時識別時,黑產運用 AI,極大提升了單位時間內識別驗證碼的數量, 2017年一季度打碼量達到259億次,且識別驗證碼的精準度超過 80%,
在網路黑產中,不法分子竊取網站資料庫后,需要確認帳號對應的密碼是否正確,用撞庫將有價值的資料通過驗證的方式篩選出來,在這一程序中,最核心的障礙就是驗證碼安全體系,打碼平臺的AI系統,能將一張驗證碼圖片作為一個整體,將單字識別轉換成單圖多標簽、端到端的識別出驗證碼中的所有字符,此外還會通過搜集反饋回來的失敗樣本,以及人工打碼的標定資料,來實時訓練和更新識別網路,不斷迭代訓練進行優化,進一步提高神經網路模型的識別能力,因此,在面對網站驗證時,還需要多種不同型別的驗證方式,如圖片選取,文字選擇,圖片填補等等,才能應對黑客日新月異的攻擊破解手段,

行為分析——惡意用戶識別
在分析用戶行為時,從用戶點擊流資料中分析惡意用戶的請求,特別地,可采用孤立森林(Isolation Forest)演算法進行分類識別,在用戶點擊流資料中,包括請求時間、IP、平臺等特征,孤立森林模型首先隨機選擇用戶行為樣本的一個特征,再隨機選擇該特征取值范圍中的一個值,對樣本集做拆分,迭代該程序,生成一顆孤立樹;樹上葉子節點離根節點越近,其例外值越高,迭代生成多顆孤立樹,生成孤立森林,識別時,融合多顆樹的結果形成最終的行為分類結果,
由于惡意用戶僅占總體用戶的少部分,具有例外樣本“量少”和“與正常樣本表現不一樣”的兩個特點,且不依賴概率密度,因此此例外檢測模型不會導致高維輸入的下溢位問題,該模型可識別例外用戶盜號、LBS/加好友、欺詐等行為,隨著樣本增加,惡意請求的uin、型別、發生時間通過分析端通過線下人工分析和線上打擊,達到良好的檢測效果,

2.社會工程學
社會工程學是指攻擊者利用某些手段使他人受騙的行為,除了現有的信用卡欺詐,信貸風險評估等AI應用,本部分將列舉“魚叉式網路釣魚”與“欺詐電話識別”兩例,
反釣魚——魚叉式網路釣魚
2017年5月,Google利用機器學習技術,其垃圾郵件和網路釣魚郵件的識別率已經達到了 99.9%,Google建立了一個系統,該系統可通過延遲Gmail資訊的時間以執行更詳細的網路釣魚分析,當用戶在瀏覽郵件的程序中,有關網路釣魚的資訊會更快被檢測出來,利用 Google的機器學習,該系統還能隨著時間的推移實時更新演算法,從而可對資料和資訊進行更深入的分析,不過,該系統僅適用于0.05%的資訊,
區別于普通網路釣魚,魚叉式網路釣魚是針對特定目標進行定制的網路釣魚攻擊,黑客會從社交媒體、新聞報道等資料中對攻擊目標的資訊中,采用機器學習的方法進行前期的分析,包括姓名、郵箱地址、社交媒體賬號或者任何在網上參與過的內容等,攻擊物件通常不對于普通用戶,而是特定的公司或者組織的成員,竊取的資料也并非個人的資料,而是其他高度敏感性資料,面對魚叉釣魚,一方面企業會加強網站的資料保護,防各種爬蟲工具,通過逆向分析,并采用機器學習進行垃圾/釣魚郵件的檢測過濾,另一方面用戶自身提高安全意識注意個人隱私泄露,保持警惕性,
反欺詐——欺詐電話識別
這幾年,在通信詐騙方面的犯罪愈演愈烈,僅2015年的報案資料,如“猜猜我是誰”,“冒充公檢法”此類涉及電話詐騙的案件,全國用戶損失就約220億左右,在應對通信欺詐,通常分為事后處置與實時阻斷兩種解決方法,而由于事后處置的時效性太低,詐騙資金往往已被轉移,無法很好地起到保護公民財產的作用,因此實時阻斷十分必要,當用戶接打電話,通過機器學習,能夠實時發現是否屬于詐騙電話,并立刻發出實時告警,
從號碼活躍特征資料、號碼的社交網路、號碼的行為事件流、號碼的行為特征、號碼信用度、號碼例外度等方面來進行特征抽取,根據機器學習架構檢測,此外,再結合事件模型與行為模式的關聯分析,能更準確地對欺詐電話進行監測,
3.網路安全
網路安全是指網路系統軟硬體受保護,網路服務不中斷,除了現有的隱藏信號識別等AI應用,本部分將列舉“大資料DDoS檢測”與“偽基站短信識別”兩例,
抗DDoS——大資料DDoS檢測
近年來,基于機器學習演算法的分布式拒絕服務(distributeddenial-of-service,簡稱DDoS)攻擊檢測技術已取得了很大的進展,在攻擊感知方面,可從宏觀攻擊流感知與微觀檢測方法兩個角度,分別基于IP流序列譜分析的泛洪攻擊與低速率拒絕服務(Low-rate Denial of Service,LDoS)方法進行感知,在此基礎上,將DDoS攻擊檢測轉化為機器學習的二分類問題,
從概率點判別角度,基于多特征并行隱馬爾科夫模型(Multi-FeatureParallel Hidden Markov Model,MFP-HMM)的DDoS攻擊檢測方法,利用HMM隱狀態序列與特征觀測序列的對應關系,將攻擊引起的多維特征例外變化轉化為離散型隨機變數,通過概率計算來刻畫當前滑動視窗序列與正常行為輪廓的偏離程度,從分類超平面判別角度,基于最小二乘孿生支持向量機(LSTSVM)的DDoS攻擊分類超平面檢測方法,采用IP包五元組熵、 IP標識、TCP頭標志和包速率等作為LSTSVM模型的多維檢測特征向量,以體現DDoS攻擊存在的流分布特性,
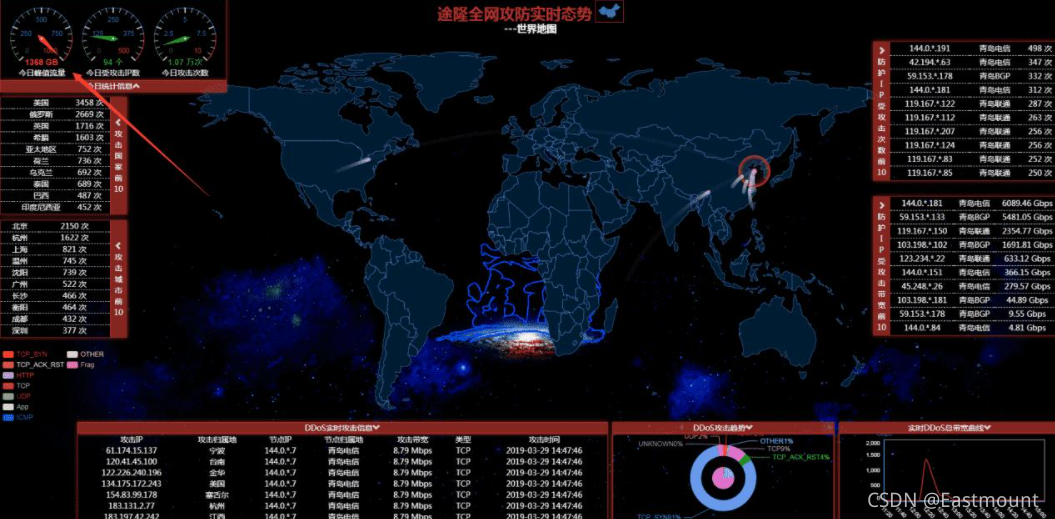
無線網路攻擊——偽基站短信識別
為了解決“犯罪分子通過冒充10086、95533等機構發送短信來獲得用戶的賬號、密碼和身份證等資訊”這一問題, 2016年,360 手機依托 360公司研發的偽基站追蹤系統,率先在全球推出了偽基站詐騙短信識別功能,攔截準確度達 98%,可有力的確保用戶財產安全,360偽基站追蹤系統的核心價值就在于它解決上述偽基站打擊難題,依托海量的資料、高效的資料分析處理和資料可視化,可以為追查偽基站供精確的資訊與準確的判斷,
2015年12月,360手機在全球率先推出了偽基站垃圾、詐騙短信精準識別功能,由于垃圾和詐騙短信的識別和分類涉及到自然語言處理技術與機器學習模型, 360使用語言學規則與統計學方法相結合的方式來定義偽基站短信特征,可從海量資料中精確識別出偽基站短信,因而其識別精度可達 98%,對于360偽基站追蹤系統的發布、部署,以及其在360手機中的成功運用,有力遏制猖獗的偽基站詐騙活動,有助于維護廣大手機用戶及其他群眾的財產安全,

4.Web安全
Web安全是指個人用戶在Web相關操作時不因偶然或惡意的原因受到破壞、更改、泄露,除了現有的SQL注入檢測、XSS攻擊檢測等 AI應用,本部分將列舉“惡意URL檢測”與“ Webshell檢測”兩例,后續實驗部分,作者將詳細描述Python實作該程序,
安全網站檢測——惡意URL檢測
在市面上,Google的Chrome已將檢測模型與機器學習相結合,支持安全瀏覽,向用戶警示潛在的惡意網址,結合成千上萬的垃圾郵件、惡意軟體、有啟發式信號的含勒索軟體的附件和發送者的簽名(已被標識為惡意的),對新的威脅進行識別和分類,
目前大多數網站檢測方式是通過建立URL黑白名單的資料庫匹配進行排查,雖然具有一定的檢測效果,但有一定滯后性,不能夠對沒有記錄在案的URL進行識別,而基于機器學習,從 URL特征,域名特征, Web特征的關聯分析,使惡意URL識別具有高準確率,并具有學習推斷的能力,一些開源工具如Phinn提供了另個角度的檢測方法,如果一個頁面看起來非常像Google的登錄頁面,那么這個頁面就應該托管在Google域名,Phinn使用了機器學習領域中的卷積神經網路演算法來生成和訓練一個自定義的Chrome擴展,這個 Chrome擴展可以將用戶瀏覽器中呈現的頁面與真正的登錄頁面進行視覺相似度分析,以此來識別出惡意URL(釣魚網站),
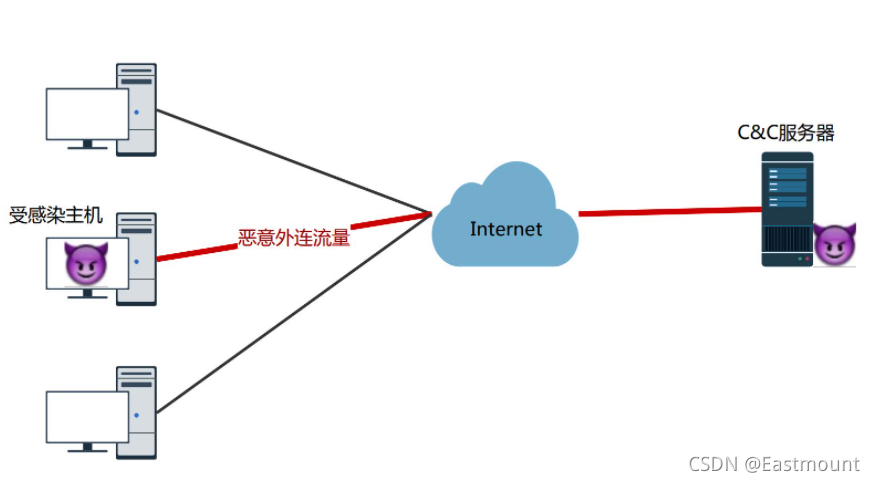
注入攻擊檢測——Webshell檢測
Webshell常常被稱為匿名用戶(入侵者)通過網站埠對網站服務器的某種程度上操作的權限,由于Webshell其大多是以動態腳本的形式出現,也有人稱之為網站的后門工具,在攻擊鏈模型中,整個攻擊程序分為:踩點、組裝、投送、攻擊、植入、控制、行動,在針對網站的攻擊中,通常是利用上傳漏洞,上傳Webshell,然后通過Webshell進一步控制web服務器,
常見傳統的Webshell檢測方法主要有靜態檢測、動態檢測、語法檢測、統計學檢測等,隨著AI的興起,基于AI的Webshell檔案特征檢測技術要較之傳統技術更勝一籌,通過詞袋&TF-IDF模型、Opcode&N-gram模型、Opcode呼叫序列模型等特征抽取方式,采用合適的模型,如樸素貝葉斯和深度學習的MLP、CNN等,實作Webshell的檢測,類似地,也可進行SQL注入、 XSS攻擊檢測等,

5.安全漏洞與惡意代碼
安全漏洞是指漏洞是在硬體、軟體、協議的具體實作或系統安全策略上存在的缺陷;惡意代碼是指具有安全威脅的代碼,除了現有的惡意軟體檢測與識別等AI應用,本部分將列舉“惡意代碼分類”與“系統自動化漏洞修補”兩例,
代碼安全——惡意代碼分類
早期反病毒軟體無論是特征碼掃描、查找廣譜特征、啟發式掃描,這三種查殺方式均沒有實際運行二進制檔案,因此均可歸為惡意代碼靜態檢測的方法,隨著反惡意代碼技術的逐步發展,主動防御技術、云查殺技術已越來越多的被安全廠商使用,但惡意代碼靜態檢測的方法仍是效率最高,被運用最廣泛的惡意代碼查殺技術,
2016年在Kaggle上微軟發起了一個惡意代碼分類比賽,冠軍隊采用了一種惡意代碼影像繪制方法,將一個二進制檔案轉換為一個矩陣(矩陣元素對應檔案中的每一個位元組,矩陣的大小可根據實際情況進行調整),該矩陣又可以非常方便的轉換為一張灰度圖,再基于N-gram,統計概率模型,最后代入分類決策樹與隨機森林進行訓練與測驗,這個方法能夠發現一些靜態方法發現不了的變種,并且也可推廣應用到Android和IOS平臺的惡意代碼檢測中,
漏洞修復——系統自動化漏洞修補
2016年8月,DARPA在DEFCON黑客大會上舉辦Cyber Grand Challenge挑戰賽,要求參賽者在比賽中構建一套智能化的系統,不僅要檢測漏洞,還要能自動寫補丁、并且完成部署,當今的軟體漏洞平均發現周期長達312 天,發現后還需要對漏洞研究、開發補丁程式,到最后公布,在這期間,攻擊者很有可能已經利用這個漏洞發起網路攻擊,因此系統自動化漏洞修復十分必要,
2017年10月,MIT研究團隊研發了一個稱為“創世紀”的系統,能夠對以前的補丁進行自動學習,生成補丁模板,并對候選補丁進行評估,據研究者說,“創世紀是第一個自動推理補丁生成轉換或根據先前成功的補丁搜索候選補丁空間的系統”,它修復的 bug幾乎是最好的手編模板系統的兩倍,同時也更精確,這些模板是根據真實補丁的特定型別“訂制”而成,因此不會產生盡可能多的無用備選,

6.入侵檢測與防御
入侵檢測與防御是指對入侵行為的發現并采取相應的防御行動,除了現有的內網入侵檢測等AI應用,本部分將列舉“APT檢測與防范”與“C2鏈接分析”兩例,
高級攻擊入侵檢測——APT檢測與防范
進行APT攻擊的攻擊者從偵查目標,制作攻擊工具,傳遞攻擊工具,利用漏洞或者弱點來進行突防,拿下全線運行工具,后期遠端的維護這個工具,到最后達到了長期控制目標的目的,針對這種現在日益廣泛的APT 攻擊,威脅情報存在于整個攻擊的各個環節,
威脅情報是基于證據的描述威脅的一組關聯的資訊,包括威脅相關的環境資訊,如具體的攻擊組織、惡意域名,惡意域名又包括遠控的IOC、惡意檔案的HASH和URL以及威脅指標之間的關聯性,時間緯度上攻擊手法的變化,這些資訊匯總在一起形成高級威脅情報,除此之外,所關注的情報,還包括傳統威脅種類的擴充,包括木馬遠控,僵尸網路,間諜軟體, Web后門等,利用機器學習來處理威脅情報,檢測并識別出APT攻擊中的惡意載荷,提高APT攻擊威脅感知系統的效率與精確性,讓安全研究人員能更快實作 APT攻擊的發現和溯源,

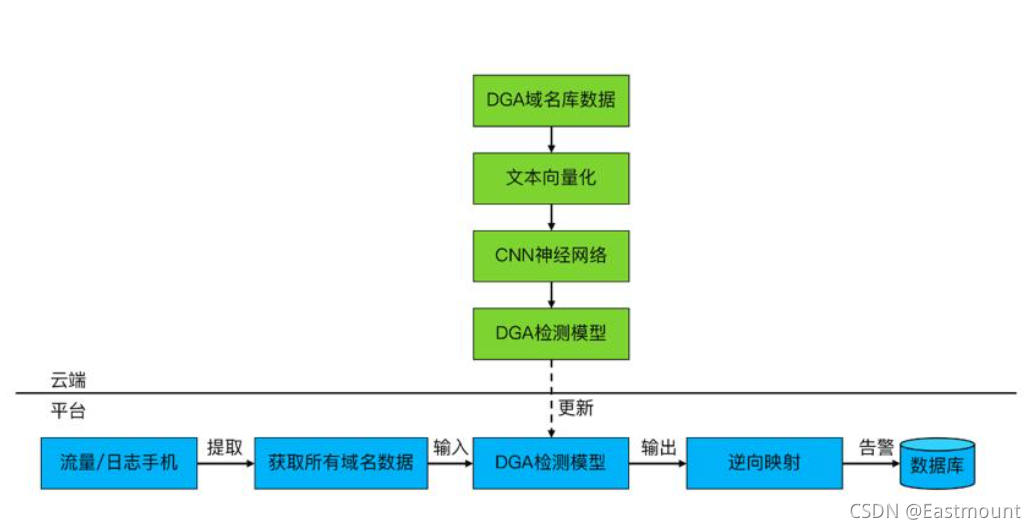
DGA域名檢測——C2鏈接分析
DGA(域名生成演算法)是一種利用隨機字符來生成C2域名,從而逃避域名黑名單檢測的技術手段,而有了DGA域名生成演算法,攻擊者就可以利用它來生成用作域名的偽隨機字串,這樣就可以有效的避開黑名單串列的檢測,偽隨機意味著字串序列似乎是隨機的,但由于其結構可以預先確定,因此可以重復產生和復制,該演算法常被運用于遠程控制軟體上,
首先攻擊者運行演算法并隨機選擇少量的域(可能只有一個),然后攻擊者將該域注冊并指向其C2服務器,在受害者端惡意軟體運行DGA并檢查輸出的域是否存在,如果檢測為該域已注冊,那么惡意軟體將選擇使用該域作為其命令和控制( C2)服務器,如果當前域檢測為未注冊,那么程式將繼續檢查其它域,因此,安全人員可以通過收集樣本以及對DGA進行逆向,來預測哪些域將來會被生成和預注冊并將它們列入黑名單中,
二.基于機器學習的惡意代碼檢測
1.傳統的惡意代碼檢測
傳統的惡意代碼檢測包括基于簽名特征碼 ( signature )的檢測和基于啟發式規則(heuristic)的檢測,在應對數量繁多的未知惡意代碼時,正面臨越來越大的挑戰,
(1) 基于簽名特征碼的檢測
簽名特征碼檢測方法通過維護一個已知的惡意代碼庫,將待檢測代碼樣本的特征碼與惡意代碼庫中的特征碼進行比對,如果特征碼出現匹配,則樣本為惡意代碼,該方法需要耗費大量的人力、物力對惡意代碼進行研究并要求用戶及時更新惡意代碼庫,檢測效率和效果越來越力不從心,并且很難有效抵御未知惡意代碼,
(2) 基于啟發式規則的檢測
啟發式規則檢測方法通過專業的分析人員對現有的惡意代碼進行規則提取,并依照提取出的規則對代碼樣本進行檢測,但面對現階段惡意代碼爆炸式的增長趨勢,僅依賴人工進行惡意代碼分析,在實施上變得愈發困難,
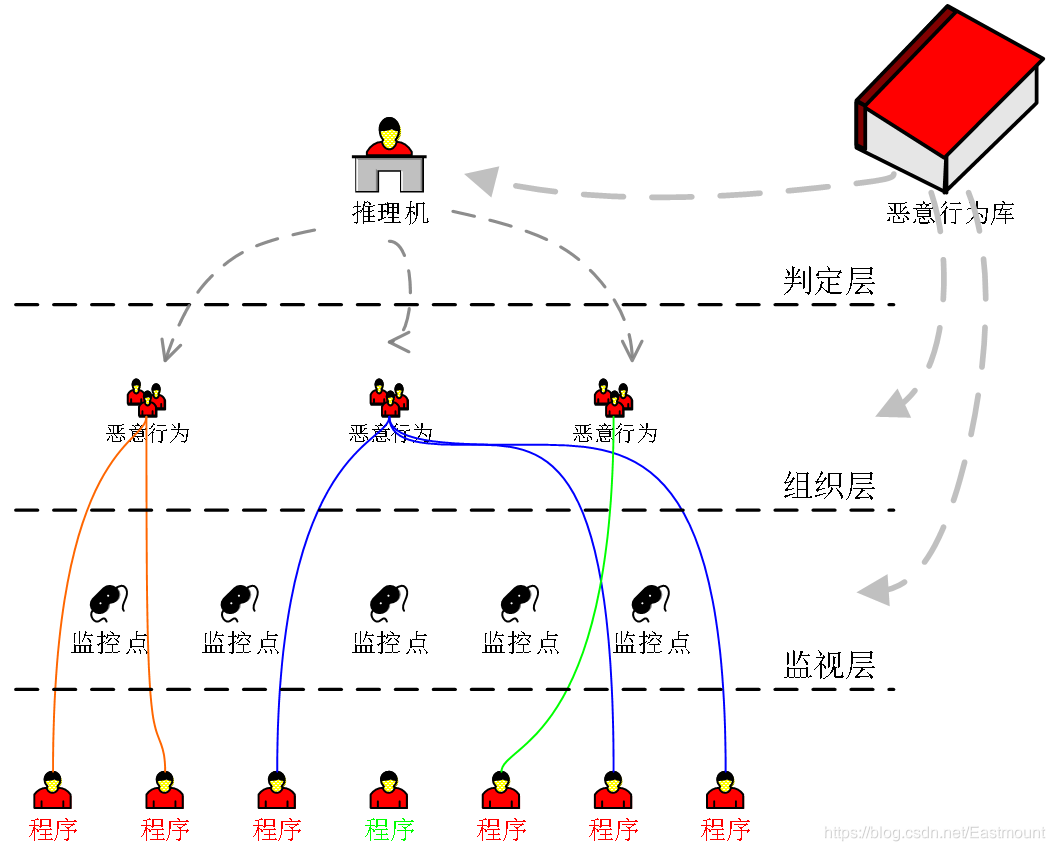
2.基于機器學習的惡意代碼檢測
基于機器學習演算法的防護技術為實作高準確率、自動化的未知惡意代碼檢測提供了行之有效的技術途徑,已逐漸成為業內研究的熱點,根據檢測程序中樣本資料采集角度的不同,可以將檢測分為:靜態分析與動態分析,
靜態分析不運行待檢測程式,而是通程序式(如反匯編后的代碼)進行分析得到資料特征,而動態分析在虛擬機或仿真器中執行程式,并獲取程式執行程序中所產生的資料(如行為特征),進行檢測和判斷,
根據 Cohen 對惡意代碼的研究結果,可知惡意代碼檢測的本質是一個分類問題,即把待檢測樣本區分成惡意或合法的程式,其核心步驟為:
- 采集數量充分的惡意代碼樣本
- 對樣本進行有效的資料處理,提取特征
- 進一步選取用于分類的主要資料特征
- 結合機器學習演算法的訓練,建立分類模型
- 通過訓練后的分類模型對未知樣本進行檢測
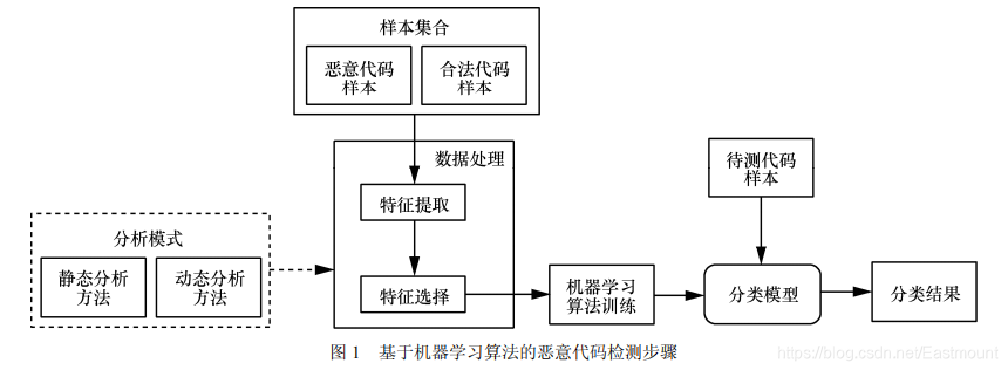
詳見作者文章:論文之基于機器學習演算法的主機惡意代碼
3.機器學習在安全領域的特點及難點
機器學習是個多元學科,其本質是在資料中進行學習,通過合適的演算法建模,最終在無規則的情況下,實作分類、聚類或是預測,從第一部分的案例可以看出,機器學習在安全攻防最常應用于在于惡意代碼識別、社工安全防范,入侵攻擊檢測這三大方向,
- 在惡意代碼識別方面: 區別傳統的黑白名單庫、特征檢測、啟發式等方法機器學習的安全應用從反病毒的代碼分類、惡意檔案檢測、惡意URL的網頁代碼識別等
- 在社工安全防范方面: 區別傳統的技術與業務經驗分析、安全宣傳、金融模型等評估方法,機器學習的安全應用從魚叉式網路釣魚檢測,惡意用戶點擊流識別,欺詐電話與短信分析,到金融信用欺詐等
- 在入侵攻擊檢測方面: 區別傳統的基于規則與策略、正則匹配等,機器學習的安全應用從DDoS防御,webshell檢測, DGA防范到APT檢測等等,
總體上,即使機器學習在訓練模型后無法達到百分百的效果,但相比傳統手段,均有不同程度地檢測效果提升,
雖然機器學習技術在安全領域已有諸多場景應用,為現有的用戶安全防護策略提供了新的視角,從上述的案例中不難看出,機器學習在安全與風控方面應用難點主要包括如:
- 機器學習需要盡可能平衡的高質量資料集,而在安全領域,無論是風險欺詐、網路釣魚、惡意軟體等,通常包含大量的正常樣本與極少量的安全隱患,因此惡意訪問、攻擊樣本的不充分,導致模型訓練后的檢測準確率有待提高,
- 機器學習的模型一般均為黑盒分析,無法得到足夠的資訊,不像其他AI應用(如商品推薦系統),在應用安全領域的模型分類錯誤具有極高的成本,并且在面對網路威脅與隱患時,安全分析人員希望在網路對抗中取得對形勢的了解與情報的掌握,以作出相應的人工干預,
- 現階段所有需監督學習的機器學習模型,均需要輸入合理且高相關的特征集,即需要從源資料到特征空間映射的特征工程,在安全領域,會產生網路監控到實際的檢測物件之間的抽象成本,如軟體缺陷與底層實作代碼與結構之間的對應關系有一個抽象、翻譯的難度,
與此同時,機器學習作為新興的前沿技術,即使解決或克服傳統安全攻防技術的問題與難點,在一些場景與環境下,仍有無法避免的缺陷或者是即使解決了問題也無法滿足實際需求,即無法采用機器學習演算法進行安全攻防的盲點,
- 無法發現未知模式的惡意行為
- 誤報大量測驗例外的正常行為
- 對資料數量與質量有強依賴性
三.邏輯回歸識別網站惡意請求
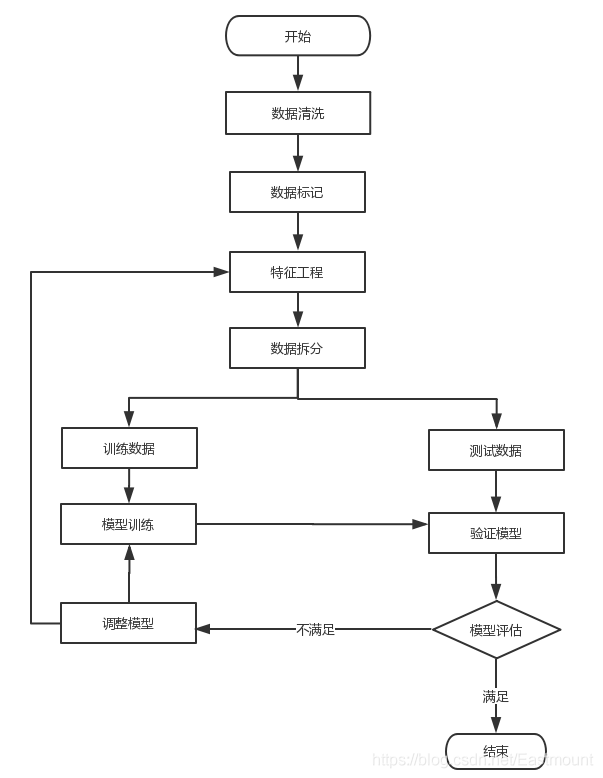
接下來作者復現了Github上exp-db大神的代碼,推薦大家閱讀之前的參考文獻中大神的作品,該代碼的基本思想是通過機器學習(邏輯回歸)建立檢測模型,從而識別網站的惡意請求和正常請求,基本流程如下圖所示:
- 讀取正常請求和惡意請求資料集,預處理設定類標y和資料集x
- 通過N-grams處理資料集,并構建TF-IDF特征矩陣,每個請求對應矩陣的一行資料
- 資料集拆分為訓練資料和測驗資料
- 使用機器學習邏輯回歸演算法對特征矩陣進行訓練,得出對應的模型
- 使用訓練的模型對 未知URL請求進行檢測,判斷其是惡意請求或正常請求
1.資料集
在 https://github.com/foospidy/payloads 中收集了常見的網站惡意請求,如SQL注入、XSS攻擊等的Payload,實驗資料包括:
- 正常請求:goodqueries.txt ,1265974條,來自http://secrepo.com網站日志請求
- 惡意請求:badqueries.txt,44532條,XSS、SQL注入等攻擊的payload
注意,資源和精力有限,資料集假定http://secrepo.com網站的日志請求全部都是正常的請求,有精力可以進行降噪處理,去除例外的標簽資料,

該部分的核心代碼為:
import os
import urllib
# 獲取文本中的請求串列
def get_query_list(filename):
directory = str(os.getcwd())
print(directory)
filepath = directory + "/" + filename
data = open(filepath, 'r', encoding='UTF-8').readlines()
query_list = []
for d in data:
# 解碼
d = str(urllib.parse.unquote(d)) #converting url encoded data to simple string
#print(d)
query_list.append(d)
return list(set(query_list))
# 主函式
if __name__ == '__main__':
# 獲取正常請求
good_query_list = get_query_list('goodqueries.txt')
print(u"正常請求: ", len(good_query_list))
for i in range(0, 5):
print(good_query_list[i].strip('\n'))
print("\n")
# 獲取惡意請求
bad_query_list = get_query_list('badqueries.txt')
print(u"惡意請求: ", len(bad_query_list))
for i in range(0, 5):
print(bad_query_list[i].strip('\n'))
print("\n")
# 預處理 good_y標記為0 bad_y標記為1
good_y = [0 for i in range(0, len(good_query_list))]
print(good_y[:5])
bad_y = [1 for i in range(0, len(bad_query_list))]
print(bad_y[:5])
queries = bad_query_list + good_query_list
y = bad_y + good_y
2.N-grams和TF-IDF結合構造特征矩陣
本段代碼的一個亮點是將N-grams和TF-IDF結合來構造特征矩陣,作者前文:
- [python] 使用scikit-learn工具計算文本TF-IDF值
TF-IDF(Term Frequency-InversDocument Frequency)是一種常用于資訊處理和資料挖掘的加權技術,該技術采用一種統計方法,根據字詞的在文本中出現的次數和在整個語料中出現的檔案頻率來計算一個字詞在整個語料中的重要程度,它的優點是能過濾掉一些常見的卻無關緊要本的詞語,同時保留影響整個文本的重要字詞,計算方法如下面公式所示,
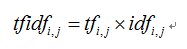
其中,式中tfidf表示詞頻tf和倒文本詞頻idf的乘積,TF-IDF值越大表示該特征詞對這個文本的重要性越大,其基本思想是將文本轉換為特征矩陣,并且降低常用詞(如we、all、www等)的權重,從而更好地表達一個文本的價值,如下圖示例:
# coding:utf-8
from sklearn.feature_extraction.text import CountVectorizer
#語料
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
#將文本中的詞語轉換為詞頻矩陣
vectorizer = CountVectorizer()
#計算個詞語出現的次數
X = vectorizer.fit_transform(corpus)
#獲取詞袋中所有文本關鍵詞
word = vectorizer.get_feature_names()
print word
#查看詞頻結果
print X.toarray()
from sklearn.feature_extraction.text import TfidfTransformer
#類呼叫
transformer = TfidfTransformer()
print transformer
#將詞頻矩陣X統計成TF-IDF值
tfidf = transformer.fit_transform(X)
#查看資料結構 tfidf[i][j]表示i類文本中的tf-idf權重
print tfidf.toarray()
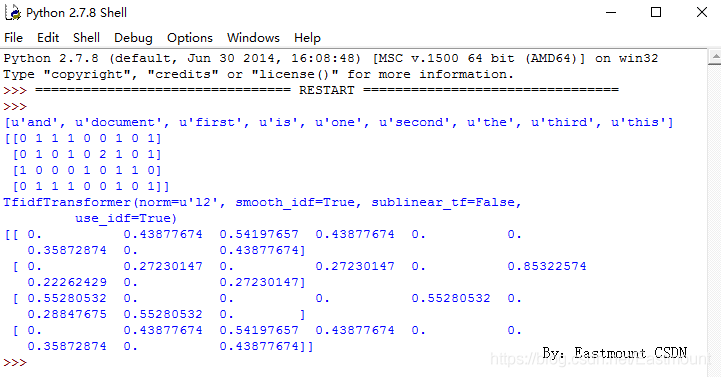
無論是惡意請求資料集還是正常請求資料集,都是不定長的字串串列,很難直接用邏輯回歸演算法對這些不規律的資料進行處理,需要找到這些文本的數字特征,用來訓練我們的檢測模型,在這里,使用TD-IDF來作為文本的特征,并以數字矩陣的形式進行輸出,在計算TD-IDF之前,首先需要對每個檔案(URL請求)的內容進行分詞處理,也就是需要定義檔案的詞條長度,這里我們選擇長度為3的N-grams,可以根據模型的準確度對這個引數進行調整,
該部分的核心代碼如下,詳見注釋:
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
# tokenizer function, this will make 3 grams of each query
# www.foo.com/1 轉換為 ['www','ww.','w.f','.fo','foo','oo.','o.c','.co','com','om/','m/1']
def get_ngrams(query):
tempQuery = str(query)
ngrams = []
for i in range(0, len(tempQuery)-3):
ngrams.append(tempQuery[i:i+3])
return ngrams
# 主函式
if __name__ == '__main__':
....
# 定義矢量化 converting data to vectors
# TfidfTransformer + CountVectorizer = TfidfVectorizer
vectorizer = TfidfVectorizer(tokenizer=get_ngrams)
# 把不規律的文本字串串列轉換成規律的 ( [i,j], tdidf值) 的矩陣X
# 用于下一步訓練邏輯回歸分類器
X = vectorizer.fit_transform(queries)
print(X.shape)
3.訓練模型
通過構建的特征矩陣作為訓練集,呼叫邏輯回歸進行訓練和測驗,Python中機器學習兩個核心函式為fit()和predict(),這里,呼叫train_test_split()函式將資料集隨機劃分,核心代碼如下所示:
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
# 主函式
if __name__ == '__main__':
....
# 使用 train_test_split 分割 X y 串列
# X_train矩陣的數目對應 y_train串列的數目(一一對應) -->> 用來訓練模型
# X_test矩陣的數目對應 (一一對應) -->> 用來測驗模型的準確性
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=20, random_state=42)
# 定理邏輯回歸方法模型
LR = LogisticRegression()
# 訓練模型
LR.fit(X_train, y_train)
# 使用測驗值 對 模型的準確度進行計算
print('模型的準確度:{}'.format(LR.score(X_test, y_test)))
print("\n")
4.檢測新資料集是惡意請求還是正常請求
模型訓練好之后,發現其精確度挺高的,真實的實驗還需要通過準確率、召回率和F值判斷,接下來呼叫Predict()函式對新的RUL進行判斷,檢測其是惡意請求還是正常請求
,核心代碼如下:
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
# 主函式
if __name__ == '__main__':
....
# 對新的請求串列進行預測
new_queries = ['www.foo.com/id=1<script>alert(1)</script>',
'www.foo.com/name=admin\' or 1=1','abc.com/admin.php',
'"><svg οnlοad=confirm(1)>',
'test/q=<a href="javascript:confirm(1)>',
'q=../etc/passwd',
'/stylesheet.php?version=1331749579',
'/<script>cross_site_scripting.nasl</script>.idc',
'<img \x39src=x οnerrοr="javascript:alert(1)">',
'/jhot.php?rev=2 |less /etc/passwd']
# 矩陣轉換
X_predict = vectorizer.transform(new_queries)
res = LR.predict(X_predict)
res_list = []
# 結果輸出
for q,r in zip(new_queries, res):
tmp = '正常請求' if r == 0 else '惡意請求'
q_entity = html.escape(q)
res_list.append({'url':q_entity,'res':tmp})
for n in res_list:
print(n)
最終輸出結果如下圖所示,可以發現其判斷較為準確,

5.完整代碼
完整代碼如下,并推薦大家去Github學習很多有些的代碼,也推薦大家去FreeBuf、安全客、CVE等網站學習,作者Github有完整代碼(第23個檔案夾):
- https://github.com/eastmountyxz/NetworkSecuritySelf-study
# coding: utf-8
import os
import urllib
import time
import html
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
# 獲取文本中的請求串列
def get_query_list(filename):
directory = str(os.getcwd())
print(directory)
filepath = directory + "/" + filename
data = open(filepath, 'r', encoding='UTF-8').readlines()
query_list = []
for d in data:
# 解碼
d = str(urllib.parse.unquote(d)) #converting url encoded data to simple string
#print(d)
query_list.append(d)
return list(set(query_list))
# tokenizer function, this will make 3 grams of each query
# www.foo.com/1 轉換為 ['www','ww.','w.f','.fo','foo','oo.','o.c','.co','com','om/','m/1']
def get_ngrams(query):
tempQuery = str(query)
ngrams = []
for i in range(0, len(tempQuery)-3):
ngrams.append(tempQuery[i:i+3])
return ngrams
# 主函式
if __name__ == '__main__':
# 獲取正常請求
good_query_list = get_query_list('goodqueries.txt')
print(u"正常請求: ", len(good_query_list))
for i in range(0, 5):
print(good_query_list[i].strip('\n'))
print("\n")
# 獲取惡意請求
bad_query_list = get_query_list('badqueries.txt')
print(u"惡意請求: ", len(bad_query_list))
for i in range(0, 5):
print(bad_query_list[i].strip('\n'))
print("\n")
# 預處理 good_y標記為0 bad_y標記為1
good_y = [0 for i in range(0, len(good_query_list))]
print(good_y[:5])
bad_y = [1 for i in range(0, len(bad_query_list))]
print(bad_y[:5])
queries = bad_query_list + good_query_list
y = bad_y + good_y
# 定義矢量化 converting data to vectors
# TfidfTransformer + CountVectorizer = TfidfVectorizer
vectorizer = TfidfVectorizer(tokenizer=get_ngrams)
# 把不規律的文本字串串列轉換成規律的 ( [i,j], tdidf值) 的矩陣X
# 用于下一步訓練邏輯回歸分類器
X = vectorizer.fit_transform(queries)
print(X.shape)
# 使用 train_test_split 分割 X y 串列
# X_train矩陣的數目對應 y_train串列的數目(一一對應) -->> 用來訓練模型
# X_test矩陣的數目對應 (一一對應) -->> 用來測驗模型的準確性
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=20, random_state=42)
# 定理邏輯回歸方法模型
LR = LogisticRegression()
# 訓練模型
LR.fit(X_train, y_train)
# 使用測驗值 對 模型的準確度進行計算
print('模型的準確度:{}'.format(LR.score(X_test, y_test)))
print("\n")
# 對新的請求串列進行預測
new_queries = ['www.foo.com/id=1<script>alert(1)</script>',
'www.foo.com/name=admin\' or 1=1','abc.com/admin.php',
'"><svg οnlοad=confirm(1)>',
'test/q=<a href="javascript:confirm(1)>',
'q=../etc/passwd',
'/stylesheet.php?version=1331749579',
'/<script>cross_site_scripting.nasl</script>.idc',
'<img \x39src=x οnerrοr="javascript:alert(1)">',
'/jhot.php?rev=2 |less /etc/passwd']
# 矩陣轉換
X_predict = vectorizer.transform(new_queries)
res = LR.predict(X_predict)
res_list = []
# 結果輸出
for q,r in zip(new_queries, res):
tmp = '正常請求' if r == 0 else '惡意請求'
q_entity = html.escape(q)
res_list.append({'url':q_entity,'res':tmp})
for n in res_list:
print(n)
四.總結
寫到這里,一篇基于機器學習的惡意代碼請求識別講述完畢,希望讀者喜歡,不喜勿噴,該代碼的亮點是N-grams融合到TF-IDF,當然也可以換成其他分類模型,雖然代碼很基礎,但也花費了作者三個小時時間,并且查閱了大量網頁文章復現的(如下圖所示),
一步一個腳印前行,接下來希望通過深度學習實作更多的惡意代碼識別和對抗樣本,作為安全領域的菜鳥,感覺自己要學習的知識好多、好雜,而且很多收費資料很貴,這系列文章都是作者自學且免費分享給博友們的,希望你們喜歡和點贊,未來繼續加油!因為有你的閱讀,才有我寫作的動力,秀璋共勉,
獨在異鄉為異客,每逢佳節倍思親,

(By:Eastmount 2021-09-19 深夜11點于武漢 http://blog.csdn.net/eastmount/ )
該篇文章參考了以下文獻,非常推薦大家閱讀這些大牛的文章和視頻:
- 機器學習在安全攻防場景的應用與分析 - 騰訊云FreeBuf官方
- 入侵某網站引發的安全防御思考 - 騰訊云“我是小三”大神
- 用機器學習玩轉惡意URL檢測 - 騰訊云FreeBuf官方
- https://github.com/exp-db/AI-Driven-WAF
- https://github.com/foospidy/payloads
- http://www.secrepo.com/
- https://github.com/eastmountyxz
- 張思思, 左信, 劉建偉. 深度學習中的對抗樣本問題[J]. 計算機學報,2019(8).
- http://fsecurify.com/fwaf-machine-learning-driven-web-application-firewall/
- 黑產用“未來武器”破解驗證碼,打碼小工都哭了 - FreeBuf
- [轉載] 機器學習科普文章:“一文讀懂機器學習,大資料/自然語言處理/演算法全有了”
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301443.html
標籤:其他
上一篇:Windows基本資訊收集
下一篇:PHP加密演算法