Hive面試復習
- HIVE
- 一、資料傾斜優化或避免
- 1、資料傾斜產生的原因:
- 2、資料傾斜的表現
- 3、各場景hive優化方案
- 3.1map端處理的小檔案過多
- 3.2map端資料量大,需要擴充map的數量或reduce的數量
- 3.3大小表join
- 3.4大表與大表join
- 3.5避免用作join的欄位資料型別一定要相同
- 二、HIVE磁區與分桶
- 1、什么是磁區
- 2、什么是分桶
- 3、為什么要進行分桶
- 三、內部表與外部表
- 四、Hive 的函式:UDF、UDAF、UDTF 的區別
- 1、區別
- 2、UDTF函式
- ①對array型別資料
- ②對map型別的資料
- ③對于結構體型別的資料(map和array的集合)
- 3、UDAF函式
- ①count,回傳值為bigint
- ②sum,min,max,avg
- ③回傳值型別為array的函式
- 4、UDF函式
- ①數學函式
- ②日期函式
- ③條件函式
- ④字串函式
- 五、HIVE資料倉庫
- 1、資料倉庫搭建步驟
- 2、技術選型
- 3、資料流圖![\[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-K1bYOdH1-1631934050923)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20210917100311261.png)\]](https://img.uj5u.com/2021/09/20/266141201014492.png)
- 4、資料分層
- 5、資料分層的優點
- 6、維度建模
- ①事實表和維度表
HIVE
一、資料傾斜優化或避免
1、資料傾斜產生的原因:
①資料業務本身的特性,如某作為key值的欄位重復較多
②join時,大表與小表關聯小表欄位作為key值
③join時,大表與大表關聯,但是很多資料沒關聯上,導致產生了空值
④count(distinct) 后導致資料傾斜
⑤group by 時因為磁區不合理導致資料傾斜,如group by 的欄位某類值過多導致資料傾斜
2、資料傾斜的表現
而當其中每一組的資料量過大時,會出現其他組的計算已經完成而這里還沒計算完成,其他節點的一直等待這個節點的任務執行完成,所以會看到一直map 100% reduce 99%的情況,大概率是發生了資料傾斜,
3、各場景hive優化方案
3.1map端處理的小檔案過多
要合并小檔案,可以通過set hive.merge.mapfiles=true來解決,
3.2map端資料量大,需要擴充map的數量或reduce的數量
set mapred.map.tasks個數,set mapred.reduce.tasks個數
3.3大小表join
可以使用map join讓小表先進記憶體
設定 hive.mapjoin.smalltable.filesize = 25000000(25M,默認)
3.4大表與大表join
為了避免產生大量空值而導致資料傾斜,可以把空值設定為字串+亂數:concate(字串+rand())
3.5避免用作join的欄位資料型別一定要相同
二、HIVE磁區與分桶
1、什么是磁區
磁區的目的就是提高查詢效率,查詢磁區資料的方式就是指定磁區名,指定磁區名之后就不再全表掃描,直接從指定磁區中查詢,從hdfs的角度看就是從相應的檔案系統中你指定的磁區名會生成一個單獨的檔案,去這個指定檔案中查找特定的資料
這個磁區欄位形式上存在于資料表中,在查詢時會顯示到客戶端上,但并不真正在存盤在資料表檔案中,是所謂偽列,所以,千萬不要以為是對屬性表中真正存在的列按照屬性值的異同進行磁區,比如上面的磁區依據的列name并不真正的存在于資料表中,是我們為了方便管理添加的一個偽列,這個列的值也是我們人為規定的
2、什么是分桶
分桶是相對磁區進行更細粒度的劃分,分桶將整個資料內容安裝某列屬性值得hash值進行區分,如要安裝name屬性分為3個桶,就是對name屬性值的hash值對3取摸,按照取模結果對資料分桶,
與磁區不同的是,磁區依據的不是真實資料表檔案中的列,而是我們指定的偽列,但是分桶是依據資料表中真實的列而不是偽列,所以在指定磁區依據的列的時候要指定列的型別,因為在資料表檔案中不存在這個列,相當于新建一個列,而分桶依據的是表中已經存在的列,這個列的資料型別顯然是已知的,所以不需要指定列的型別,
3、為什么要進行分桶
可提高查詢效率,如:我們要對兩張在同一列上進行了分桶操作的表進行JOIN操作的時候,只需要對保存相同列值的桶進行JOIN操作即可,同時分桶也能讓取樣(Sampling)更高效,
三、內部表與外部表
未被external修飾的是內部表(managed table),被external修飾的為外部表(external table);
區別:
內部表資料由Hive自身管理,外部表資料由HDFS管理;
內部表資料存盤的位置是hive.metastore.warehouse.dir(默認:/user/hive/warehouse),外部表資料的存盤位置由自己制定(如果沒有LOCATION,Hive將在HDFS上的/user/hive/warehouse檔案夾下以外部表的表名創建一個檔案夾,并將屬于這個表的資料存放在這里);
洗掉內部表會直接洗掉元資料(metadata)及存盤資料;洗掉外部表僅僅會洗掉元資料,HDFS上的檔案并不會被洗掉,且洗掉后如果重新create相同的外部表資料不會變;
四、Hive 的函式:UDF、UDAF、UDTF 的區別
1、區別
UDF: 單行進入,單行輸出
UDAF: 多行進入,單行輸出
UDTF: 單行輸入,多行輸出
2、UDTF函式
①對array型別資料
hive> create table student_array(
> name string,
> course_score array<string>
> )
> row format delimited fields terminated by '\t'
> collection items terminated by ','
> stored as textfile;
hive> select * from student_array;
-chgrp: '*' does not match expected pattern for group
Usage: hadoop fs [generic options] -chgrp [-R] GROUP PATH...
OK
zs ["語文:86","數學:87.5","英語:90"]
ls ["語文:76","數學:93","英語:88"]
ww ["語文:88","數學:90","英語:95"]
對array型別的資料可以用explode函式將陣列中的元素拆分,按行輸出每個元素
hive> select explode(course_score) from student_array;
-chgrp: '*' does not match expected pattern for group
Usage: hadoop fs [generic options] -chgrp [-R] GROUP PATH...
OK
語文:86
數學:87.5
英語:90
語文:76
數學:93
英語:88
語文:88
數學:90
英語:95
select split(course_score,':')[1] from student_array
②對map型別的資料
hive> create table student_map(
> name string,
> course_score map<string ,float>
> )
> row format delimited fields terminated by '\t'
> collection items terminated by ','
> map keys terminated by ':'
> stored as textfile;
hive> select * from student_map;
-chgrp: '*' does not match expected pattern for group
Usage: hadoop fs [generic options] -chgrp [-R] GROUP PATH...
OK
zs {"語文":86.0,"數學":87.5,"英語":90.0}
ls {"語文":76.0,"數學":93.0,"英語":88.0}
ww {"語文":88.0,"數學":90.0,"英語":95.0}
對于map型別的資料,可以使用explode分開key和value型別的資料
hive> select explode(course_score) from student_map;
-chgrp: '*' does not match expected pattern for group
Usage: hadoop fs [generic options] -chgrp [-R] GROUP PATH...
OK
語文 86.0
數學 87.5
英語 90.0
語文 76.0
數學 93.0
英語 88.0
語文 88.0
數學 90.0
英語 95.0
③對于結構體型別的資料(map和array的集合)
hive> create table student_map(
> name string,
> course_score array<map<string ,float>>
> )
> row format delimited fields terminated by '\t'
> collection items terminated by ','
> map keys terminated by ':'
> stored as textfile;
hive> select * from student_struct_array;
-chgrp: '*' does not match expected pattern for group
Usage: hadoop fs [generic options] -chgrp [-R] GROUP PATH...
OK
zs [{"course":"語文","score":86.0},{"course":"數學","score":87.5},{"course":"英語","score":90.0}]
ls [{"course":"語文","score":76.0},{"course":"數學","score":93.0}]
ww [{"course":"語文","score":88.0},{"course":"數學","score":90.0},{"course":"英語","score":95.0}]
Time taken: 0.19 seconds, Fetched: 3 row(s)
可以使用inline函式進行拆分,注:不能使用UDTF函式進行嵌套
hive> select inline(course_score) from student_struct_array;
-chgrp: '*' does not match expected pattern for group
Usage: hadoop fs [generic options] -chgrp [-R] GROUP PATH...
OK
語文 86.0
數學 87.5
英語 90.0
語文 76.0
數學 93.0
語文 88.0
數學 90.0
英語 95.0
3、UDAF函式
①count,回傳值為bigint
count(*):回傳指定列檢索到的行數,包括空值
count(expr):expr運算式不是NULL的行的數量
count(distinct) :回傳去除重復后的行數
②sum,min,max,avg
常用函式,不予詳細介紹
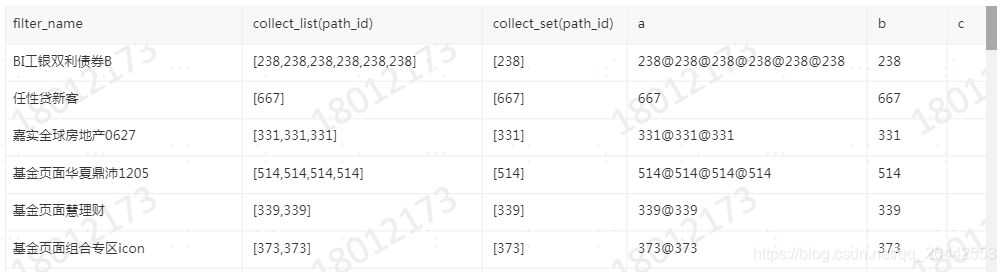
③回傳值型別為array的函式
select filter_name ,
collect_list(path_id),
collect_set(path_id),
concat_ws('@',collect_list(path_id)) a,
concat_ws('@',collect_set(path_id)) b,
concat_ws('@',collect_set(market_type)) c
from FDM_SOR.T_FIBA_MULTI_UBA_CFG_PATH_DETAIL_D
where path_id >89
group by filter_name
4、UDF函式
①數學函式
| 函式名稱 | 說明 |
|---|---|
| round(double d, int n) | 回傳保留n位小數的近似d值 |
| bin(int d) | 計算二進制值d的string值 |
| rand(int seed) | 回傳亂數,seed是隨機因子 |
| ceil(double d) | 回傳大于d的最小整值 |
| floor(double d) | 回傳小于d的最大整值 |
②日期函式
| 函式名稱 | 說明 |
|---|---|
| to_date(string timestamp) | 回傳時間字串中的日期部分,如to_date(‘1970-01-01 00:00:00’)=‘1970-01-01’ |
| current_date | 回傳當前日期 |
| year(date) | 回傳日期date的年,型別為int如year(‘2019-01-01’)=2019 |
| month(date) | 回傳日期date的月,型別為int,如month(‘2019-01-01’)=1 |
| day(date) | 回傳日期date的天,型別為int,如day(‘2019-01-01’)=1 |
| weekofyear(date1) | 回傳日期date1位于該年第幾周,如weekofyear(‘2019-03-06’)=10 |
| datediff(date1,date2) | 回傳日期date1與date2相差的天數,如datediff(‘2019-03-06’,‘2019-03-05’)=1 |
| date_add(date1,int1) | 回傳日期date1加上int1的日期,如date_add(‘2019-03-06’,1)=‘2019-03-07’ |
| date_sub(date1,int1) | 回傳日期date1減去int1的日期,如date_sub(‘2019-03-06’,1)=‘2019-03-05’ |
| months_between(date1,date2) | 回傳date1與date2相差月份,如months_between(‘2019-03-06’,‘2019-01-01’)=2 |
| add_months(date1,int1) | 回傳date1加上int1個月的日期,int1可為負數,如add_months(‘2019-02-11’,-1)=‘2019-01-11’ |
| last_day(date1) | 回傳date1所在月份最后一天,如last_day(‘2019-02-01’)=‘2019-02-28’ |
| next_day(date1,day1) | 回傳日期date1的下個星期day1的日期,day1為星期X的英文前兩字母如next_day(‘2019-03-06’,‘MO’) 回傳’2019-03-11’ |
| trunc(date1,string1) | 回傳日期最開始年份或月份,string1可為年(YYYY/YY/YEAR)或月(MONTH/MON/MM),如trunc(‘2019-03-06’,‘MM’)=‘2019-03-01’,trunc(‘2019-03-06’,‘YYYY’)=‘2019-01-01’ |
| unix_timestamp() | 回傳當前時間的unix時間戳,可指定日期格式,如unix_timestamp(‘2019-03-06’,‘yyyy-mm-dd’)=1546704180 |
| from_unixtime() | 回傳unix時間戳的日期,可指定格式,如select from_unixtime(unix_timestamp(‘2019-03-06’,‘yyyy-mm-dd’),‘yyyymmdd’)=‘20190306’ |
③條件函式
| 函式名稱 | 說明 |
|---|---|
| if(boolean,t1,t2) | 若布林值成立,則回傳t1,反正回傳t2,如if(1>2,100,200)回傳200 |
| case when boolean then t1 else t2 end | 若布林值成立,則t1,否則t2,可加多重判斷 |
| coalesce(v0,v1,v2) | 回傳引數中的第一個非空值,若所有值均為null,則回傳null,如coalesce(null,1,2)回傳1 |
| isnull(a) | 若a為null則回傳true,否則回傳false |
④字串函式
| 函式名稱 | 說明 |
|---|---|
| length(string1) | 回傳字串長度 |
| concat(string1,string2) | 回傳拼接string1及string2后的字串 |
| concat_ws(sep,string1,string2) | 回傳按指定分隔符拼接的字串 |
| lower(string1) | 回傳小寫字串 |
| upper(string1) | 回傳大寫字串 |
| trim(string1) | 去字串左右空格 |
| split(string1,pat1) | 以pat1字符分隔字串string1,回傳陣列,如split(‘a,b,c’,’,’)回傳[“a”,“b”,“c”] |
| substr(string1,index1,int1) | 以index位置起截取int1個字符,如substr(‘abcde’,1,2)回傳’ab’ |
五、HIVE資料倉庫
1、資料倉庫搭建步驟
①用戶行為資料采集平臺搭建
②業務資料采集平臺搭建
③資料倉庫維度建模
④采用即席查詢工具,隨時進行指標分析
⑤對集群性能進行監控,發生例外需要報警
2、技術選型
資料采集傳輸:Flume,Kafka,Sqoop
資料存盤: MySql,HDFS
資料計算:Hive,Spark
資料查詢: Presto,Kylin
資料可視化:Superset
任務調度: Azkaban
集群監控: Zabbix
3、資料流圖![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-K1bYOdH1-1631934050923)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20210917100311261.png)]](https://img.uj5u.com/2021/09/20/266141201014492.png)
4、資料分層
ODS(原始資料層):原始資料層,存放原始資料,直接加載原始日志、資料,資料保持原貌不做處理,
DWD層(明細資料層):對ODS層資料進行清洗(去除空值,臟資料,超過極限范圍的資料)、脫敏等,保存明細資料,一行資訊代表一次業務行為, 例如一次下單,
DWS層(服務資料層):以DWD為基礎,按天進行輕度匯總,一行資訊代表一個主題物件一天的匯總行為, 例如一個用戶一天下單次數
DWT層(資料主題層):以DWS為基礎,對資料進行累積匯總,一行資訊代表一個主題物件的累積行為,例如一個用戶從注冊那天開始至今-共下了多少次單
ADS層(資料應用層):為各種統計報表提供資料
ODS層是原始資料層也可被稱為介面層
中間三層也被稱為資料倉庫層,每一層都是對上一層的累積和匯總,一般都是對資料關聯的日期進行拆分,使得其更具體的分類,如拆分成年、月、日等,
5、資料分層的優點
?1)把復雜問題簡單化 將復雜的任務分解成多層來完成,每一層只處理簡單的任務,方便定位問題,
?2) 減少重復開發 規范資料分層,通過的中間層資料,能夠減少極大的重復計算,增加一次計算結果的復用性,
?3) 隔離原始資料 不論是資料的例外還是資料的敏感性,使真實資料與統計資料解耦開,
6、維度建模
①事實表和維度表
**事實表(Fact Table)**是指存盤有事實記錄的表,如系統的日志、銷售記錄、用戶訪問日志等資訊,事實表的記錄是動態的增長的,所以體積是大于維度表,
如:用戶訪問日志(事實表):用戶名、url、時間…
維度表(Dimension Table)也稱為查找表(Lookup Table)是與事實表相對應的表,這個表保存了維度的屬性值,可以跟事實表做關聯,相當于是將事實表中經常重復的資料抽取、規范出來用一張表管理,常見的有日期(日、周、月、季度等屬性)、地區表等,所以維度表的變化通常不會太大,
常見的維度表有:地市維表、區縣維表、資費維表、活動維表、渠道維表等
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301463.html
標籤:其他