全網最詳細的大資料ELK文章系列,強烈建議收藏加關注!
新文章都已經列出歷史文章目錄,幫助大家回顧前面的知識重點,
目錄
系列歷史文章
美文搜索案例
一、需求
二、準備作業
1、創建IDEA專案
2、創建父工程
3、添加lucene模塊
4、匯入Maven依賴
5、創建包和類
6、匯入文章資料
三、建立索引庫
1、實作步驟
2、參考代碼
3、執行效果
四、關鍵字查詢
1、需求
2、準備作業
3、開發步驟
4、參考代碼
5、執行效果
五、搜索詞語問題
六、分詞器與中文分詞器
七、使用IK分詞器重構案例
1、準備作業
2、實作步驟
3、參考代碼
4、執行效果
5、問題
八、句子搜索
1、實作步驟
2、參考代碼
3、執行效果
??????????????
系列歷史文章
2021年大資料ELK(五):Elasticsearch中的核心概念
2021年大資料ELK(四):Lucene的美文搜索案例
2021年大資料ELK(三):Lucene全文檢索庫介紹
2021年大資料ELK(二): Elasticsearch簡單介紹
2021年大資料ELK(一):集中式日志協議堆疊Elastic Stack簡介
美文搜索案例
一、需求
在資料中的文章檔案夾中,有很多的文本檔案,這里面包含了一些非常有趣的軟文,而我們想要做的事情是,通過搜索一個關鍵字就能夠找到哪些文章包含了這些關鍵字,例如:搜索「hadoop」,就能找到hadoop相關的文章,
需求分析:
要實作以上需求,我們有以下兩種辦法:
- 用戶輸入搜索關鍵字,然后我們挨個讀取檔案,并查找檔案中是否包含關鍵字
- 我們先挨個讀取檔案,對檔案的文本進行分詞(例如:按標點符號),然后建立索引,用戶輸入關鍵字,根據之前建立的索引,搜索關鍵字,
很明顯,第二種方式要比第一種效果好得多,性能也好得多,所以,我們下面就使用Lucene來建立索引,然后根據索引來進行檢索,
二、準備作業
1、創建IDEA專案
此處在IDEA中的工程模型如下:
2、創建父工程
| groupId | cn.it |
| artifactId | es_parent |
3、添加lucene模塊
??????????????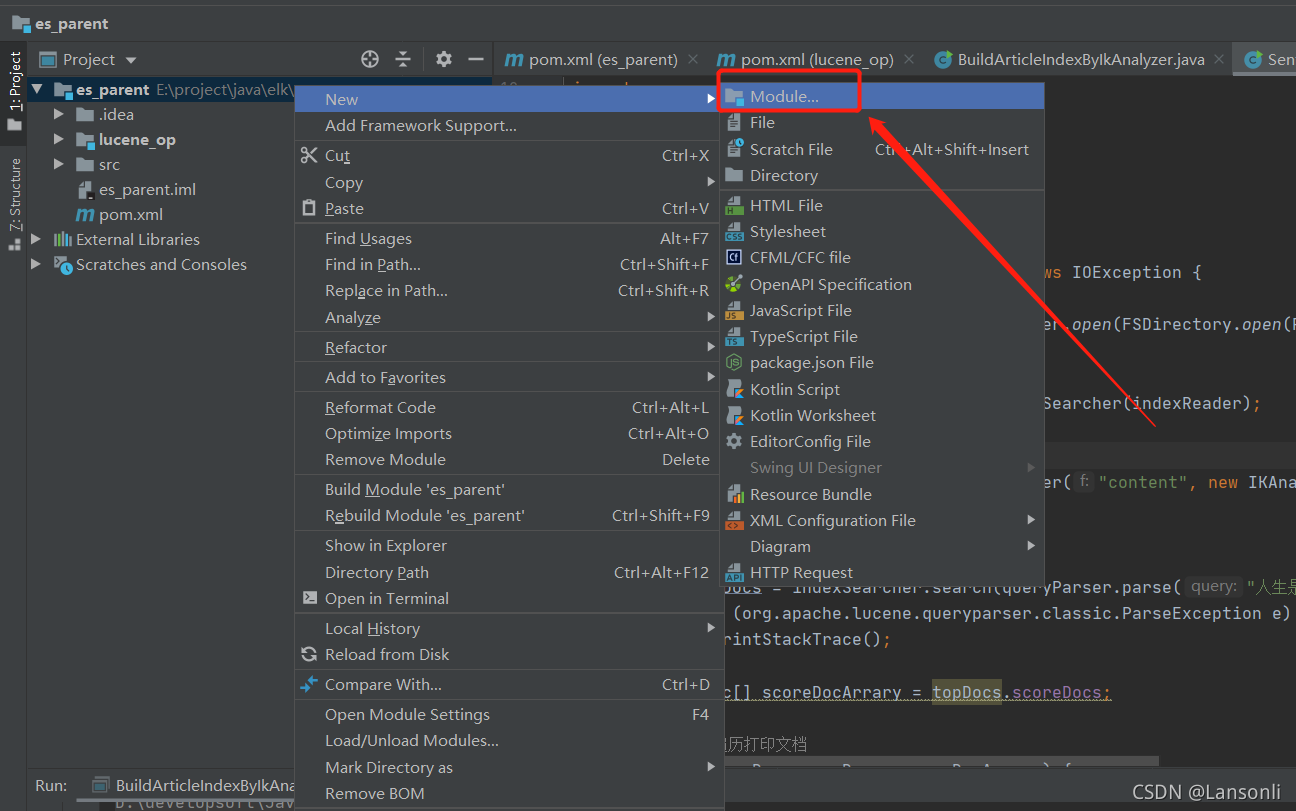
| groupId | cn.it |
| artifactId | lucene_op |
4、匯入Maven依賴
匯入依賴到lucene_op的pom.xml
<dependencies>
<!-- lucene核心類別庫 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>8.4.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>8.0.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>5、創建包和類
- 在java目錄創建 cn.it.lucene 包結構
- 創建BuildArticleIndex類
6、匯入文章資料
- 在 lucene_op 模塊下創建名為 data 的目錄,用來存放文章檔案
- 在 lucene_op 模塊下創建名為 index 的目錄,用于存放最后生成的索引檔案
- 將資料/文章目錄下的txt檔案復制到 data 目錄中
三、???????建立索引庫
1、???????實作步驟
- 構建分詞器(StandardAnalyzer)
- 構建檔案寫入器配置(IndexWriterConfig)
- 構建檔案寫入器(IndexWriter,注意:需要使用Paths來)
- 讀取所有檔案構建檔案
- 檔案中添加欄位
| 欄位名 | 型別 | 說明 |
| file_name | TextFiled | 檔案名欄位,需要在索引檔案中保存檔案名內容 |
| content | TextFiled | 內容欄位,只需要能被檢索,但無需在檔案中保存 |
| path | StoredFiled | 路徑欄位,無需被檢索,只需要在檔案中保存即可 |
- 寫入檔案
- 關閉寫入器
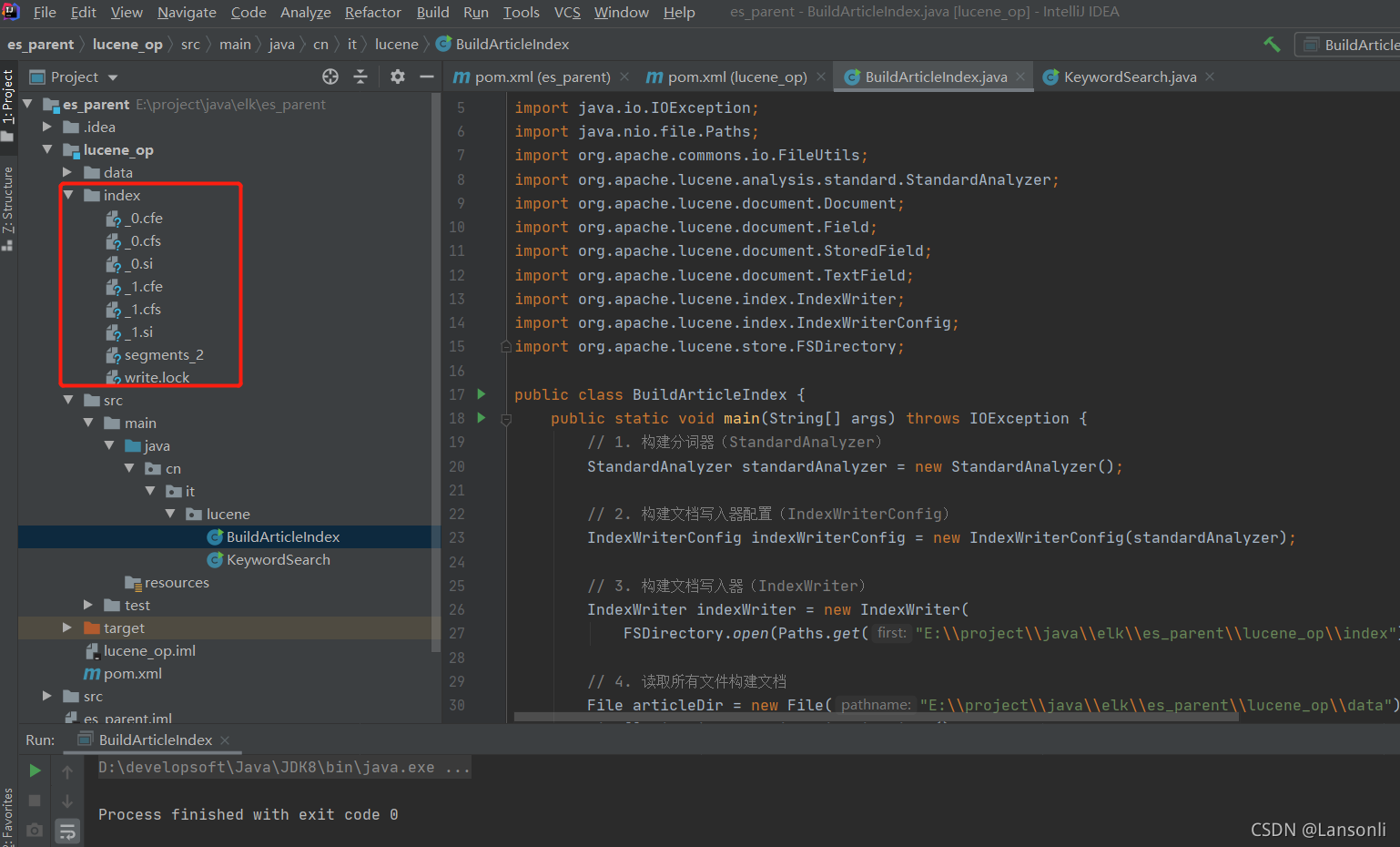
2、???????參考代碼
package cn.it.lucene;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
public class BuildArticleIndex {
public static void main(String[] args) throws IOException {
// 1. 構建分詞器(StandardAnalyzer)
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
// 2. 構建檔案寫入器配置(IndexWriterConfig)
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(standardAnalyzer);
// 3. 構建檔案寫入器(IndexWriter)
IndexWriter indexWriter = new IndexWriter(
FSDirectory.open(Paths.get("E:\\project\\java\\elk\\es_parent\\lucene_op\\index")), indexWriterConfig);
// 4. 讀取所有檔案構建檔案
File articleDir = new File("E:\\project\\java\\elk\\es_parent\\lucene_op\\data");
File[] fileList = articleDir.listFiles();
for (File file : fileList) {
// 5. 檔案中添加欄位
Document docuemnt = new Document();
docuemnt.add(new TextField("file_name", file.getName(), Field.Store.YES));
docuemnt.add(new TextField("content", FileUtils.readFileToString(file, "UTF-8"), Field.Store.NO));
docuemnt.add(new StoredField("path", file.getAbsolutePath() + "/" + file.getName()));
// 6. 寫入檔案
indexWriter.addDocument(docuemnt);
}
// 7. 關閉寫入器
indexWriter.close();
}
}
3、執行效果
四、???????關鍵字查詢
???????1、需求
輸入一個關鍵字“心”,根據關鍵字查詢索引庫中是否有匹配的檔案
2、???????準備作業
- 前提:基于文章文本檔案,已經生成好了索引
- 在cn.it.lucene包下創建一個類KeywordSearch
3、開發步驟
- 使用DirectoryReader.open構建索引讀取器
- 構建索引查詢器(IndexSearcher)
- 構建詞條(Term)和詞條查詢(TermQuery)
- 執行查詢,獲取檔案
- 遍歷列印檔案(可以使用IndexSearch.doc根據檔案ID獲取到檔案)
- 關鍵索引讀取器
4、???????參考代碼
package cn.it.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
public class KeywordSearch {
public static void main(String[] args) throws IOException {
// 1. 構建索引讀取器
IndexReader indexReader = DirectoryReader.open(FSDirectory.open(Paths.get("E:\\project\\java\\elk\\es_parent\\lucene_op\\index")));
// 2. 構建索引查詢器
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 3. 執行查詢,獲取檔案
TermQuery termQuery = new TermQuery(new Term("content", "心"));
TopDocs topDocs = indexSearcher.search(termQuery, 50);
ScoreDoc[] scoreDocArrary = topDocs.scoreDocs;
// 4. 遍歷列印檔案
for (ScoreDoc scoreDoc : scoreDocArrary) {
int docId = scoreDoc.doc;
Document document = indexSearcher.doc(docId);
System.out.println("檔案名:" + document.get("file_name") + " 路徑:" + document.get("path"));
}
indexReader.close();
}
}
5、執行效果
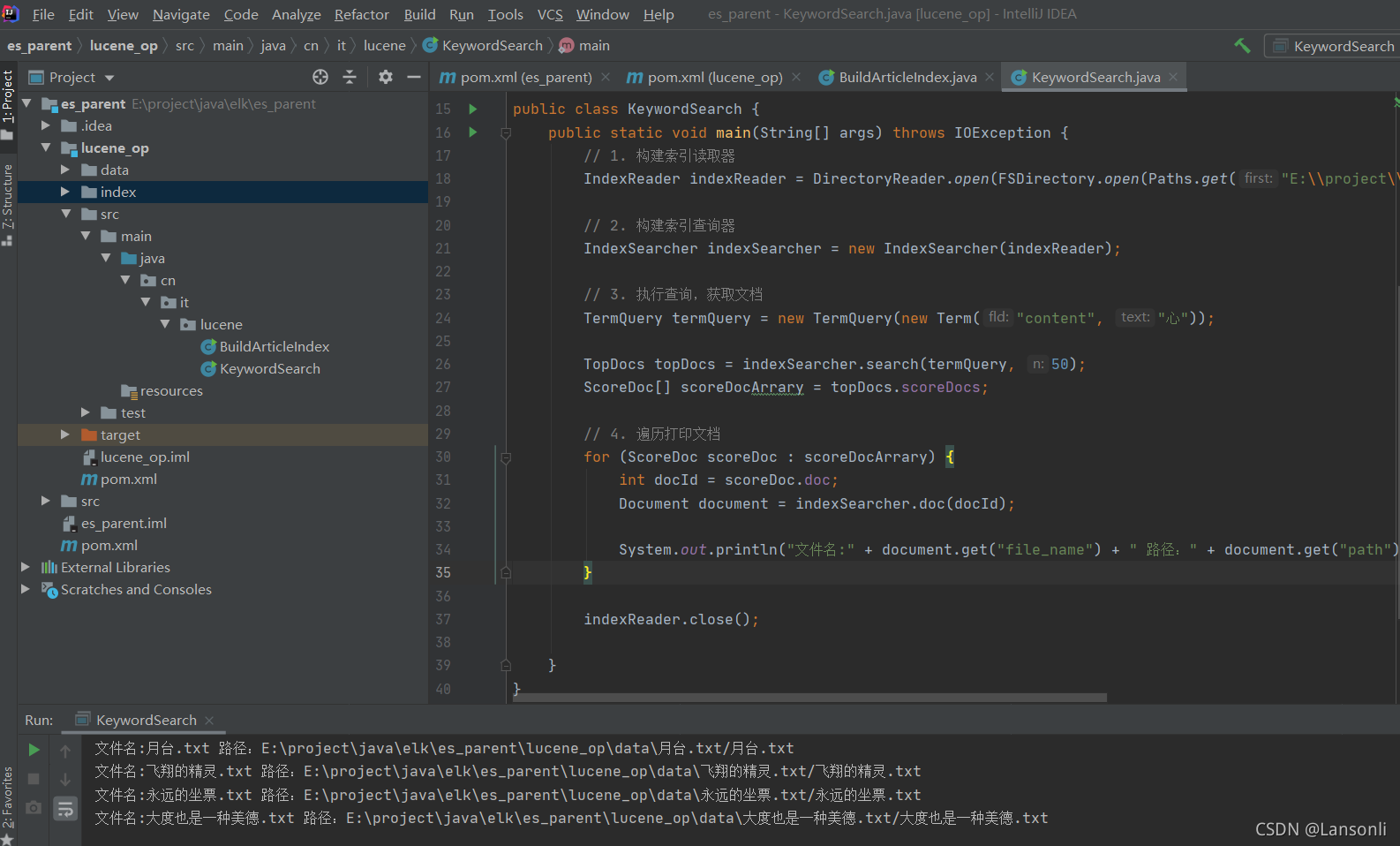
五、搜索詞語問題
上述代碼,都是一個字一個字的搜索,但如果搜索一個詞,例如:“情愿”,我們會發現,我們什么都搜索不出來,所以,接下來,我們還需要來解決搜索一個詞的問題,
六、???????分詞器與中文分詞器
分詞器是指將一段文本,分割成為一個個的詞語的動作,例如:按照停用詞進行分隔(的、地、啊、吧、標點符號等),我們之前在代碼中使用的分詞器是Lucene中自帶的分詞器,這個分詞器對中文很不友好,只是將一個一個字分出來,所以,就會從后出現上面的問題——無法搜索詞語,
所以,基于該背景,我們需要使用跟適合中文的分詞器,中文分詞器也有不少,例如:
- Jieba分詞器
- IK分詞器
- 庖丁分詞器
- Smarkcn分詞器
等等,此處,我們使用比較好用的IK分詞器來進行分詞,
IK已經實作好了Lucene的分詞器:https://github.com/wks/ik-analyzer
| IKAnalyzer是一個開源的,基于java語言開發的輕量級的中文分詞工具包,從2006年12月推出1.0版開始,IKAnalyzer已經推出了3個大版本,最初,它是以開源專案Luence為應用主體的,結合詞典分詞和文法分析演算法的中文分詞組件,新版本的 IKAnalyzer3.0則發展為面向Java的公用分詞組件,獨立于Lucene專案,同時提供了對Lucene的默認優化實作, IKAnalyzer3.0特性: 采用了特有的“正向迭代最細粒度切分演算法“,支持細粒度和最大詞長兩種切分模式;具有83萬字/秒(1600KB/S)的高速處理能力, 采用了多子處理器分析模式,支持:英文字母、數字、中文詞匯等分詞處理,兼容韓文、日文字符 優化的詞典存盤,更小的記憶體占用,支持用戶詞典擴展定義 針對Lucene全文檢索優化的查詢分析器IKQueryParser(作者吐血推薦);引入簡單搜索運算式,采用歧義分析演算法優化查詢關鍵字的搜索排列組合,能極大的提高Lucene檢索的命中率, |
七、使用IK分詞器重構案例
1、???????準備作業
添加Maven依賴
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>8.0.0</version>
</dependency>創建BuildArticleIndexByIkAnalyzer類
2、實作步驟
把之前生成的索引檔案洗掉,然后將之前使用的StandardAnalyzer修改為IKAnalyzer,然后重新生成索引,
3、參考代碼
package cn.it.lucene;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class BuildArticleIndexByIkAnalyzer {
public static void main(String[] args) throws IOException {
// 1. 構建分詞器(StandardAnalyzer)
IKAnalyzer ikAnalyzer = new IKAnalyzer();
// 2. 構建檔案寫入器配置(IndexWriterConfig)
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(ikAnalyzer);
// 3. 構建檔案寫入器(IndexWriter)
IndexWriter indexWriter = new IndexWriter(
FSDirectory.open(Paths.get("E:\\project\\java\\elk\\es_parent\\lucene_op\\index")), indexWriterConfig);
// 4. 讀取所有檔案構建檔案
File articleDir = new File("E:\\project\\java\\elk\\es_parent\\lucene_op\\data");
File[] fileList = articleDir.listFiles();
for (File file : fileList) {
// 5. 檔案中添加欄位
Document docuemnt = new Document();
docuemnt.add(new TextField("file_name", file.getName(), Field.Store.YES));
docuemnt.add(new TextField("content", FileUtils.readFileToString(file, "UTF-8"), Field.Store.NO));
docuemnt.add(new StoredField("path", file.getAbsolutePath() + "/" + file.getName()));
// 6. 寫入檔案
indexWriter.addDocument(docuemnt);
}
// 7. 關閉寫入器
indexWriter.close();
}
}
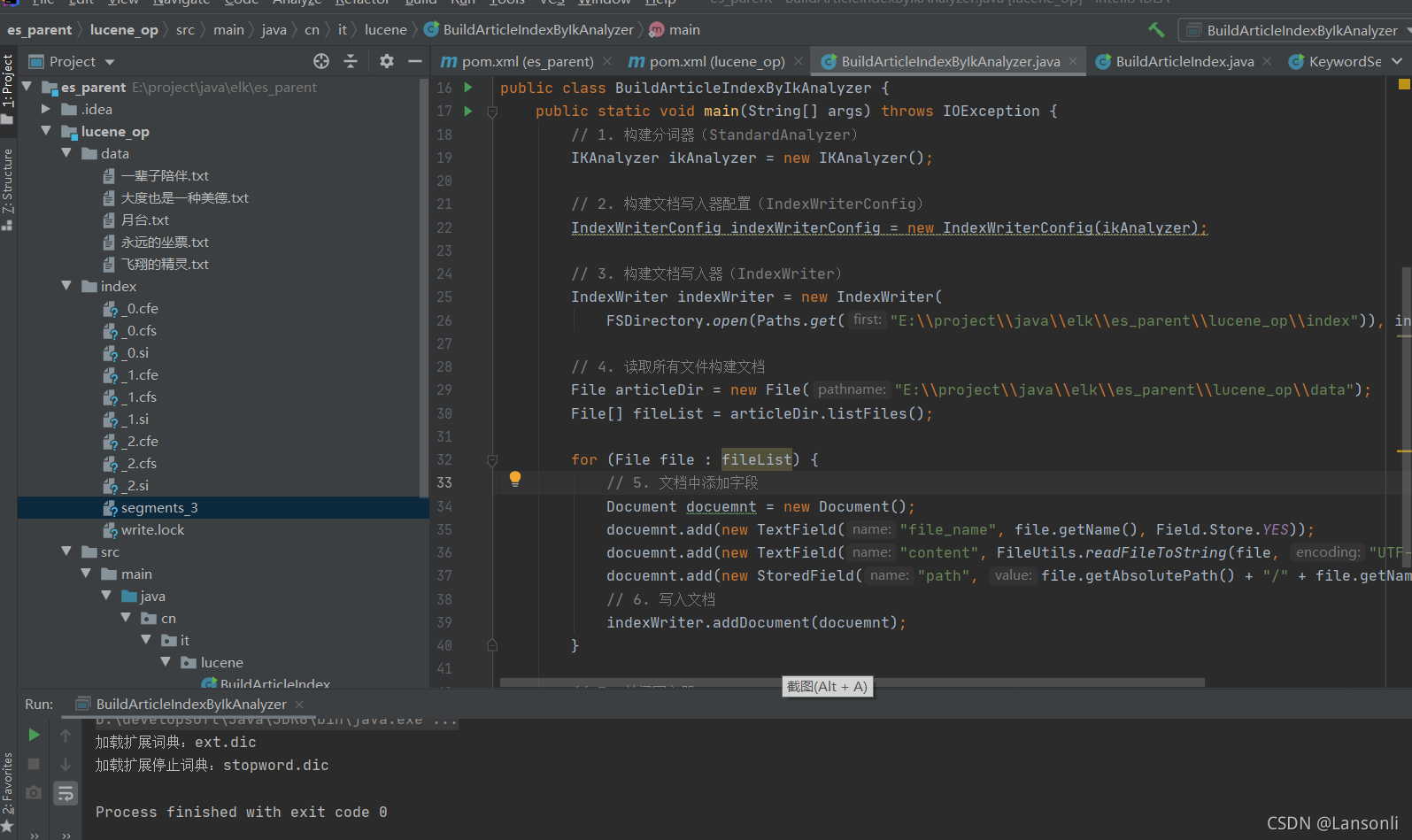
4、執行效果

5、問題
通過使用IK分詞器進行分詞,我們發現,現在我們的程式可以搜索詞語了,但如果我們輸入一句話:人生是一條河,我們想要搜索出來與其相關的文章,應該如何實作呢?
八、???????句子搜索
在cn.it.lucene 包下創建一個SentenceSearch類
1、???????實作步驟
要實作搜索句子,其實是將句子進行分詞后,再進行搜索,我們需要使用QueryParser類來實作,通過QueryParser可以指定分詞器對要搜索的句子進行分詞,
2、???????參考代碼
package cn.it.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class SentenceSearch {
public static void main(String[] args) throws IOException {
// 1. 構建索引讀取器
IndexReader indexReader = DirectoryReader.open(FSDirectory.open(Paths.get("D:\\project\\51.V8.0_NoSQL_MQ\\ElasticStack\\code\\es_parent\\lucene_op\\index")));
// 2. 構建索引查詢器
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 3. 執行查詢,獲取檔案
QueryParser queryParser = new QueryParser("content", new IKAnalyzer());
TopDocs topDocs = null;
try {
topDocs = indexSearcher.search(queryParser.parse("人生是一條河"), 50);
} catch (org.apache.lucene.queryparser.classic.ParseException e) {
e.printStackTrace();
}
ScoreDoc[] scoreDocArrary = topDocs.scoreDocs;
// 4. 遍歷列印檔案
for (ScoreDoc scoreDoc : scoreDocArrary) {
int docId = scoreDoc.doc;
Document document = indexSearcher.doc(docId);
System.out.println("檔案名:" + document.get("file_name") + " 路徑:" + document.get("path"));
}
indexReader.close();
}
}
3、執行效果
- 📢博客主頁:https://lansonli.blog.csdn.net
- 📢歡迎點贊 👍 收藏 ?留言 📝 如有錯誤敬請指正!
- 📢本文由 Lansonli 原創,首發于 CSDN博客🙉
- 📢大資料系列文章會每天更新,停下休息的時候不要忘了別人還在奔跑,希望大家抓緊時間學習,全力奔赴更美好的生活?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301473.html
標籤:其他