文章目錄
- 排序的概念及其運用
- 排序的概念
- 排序運用
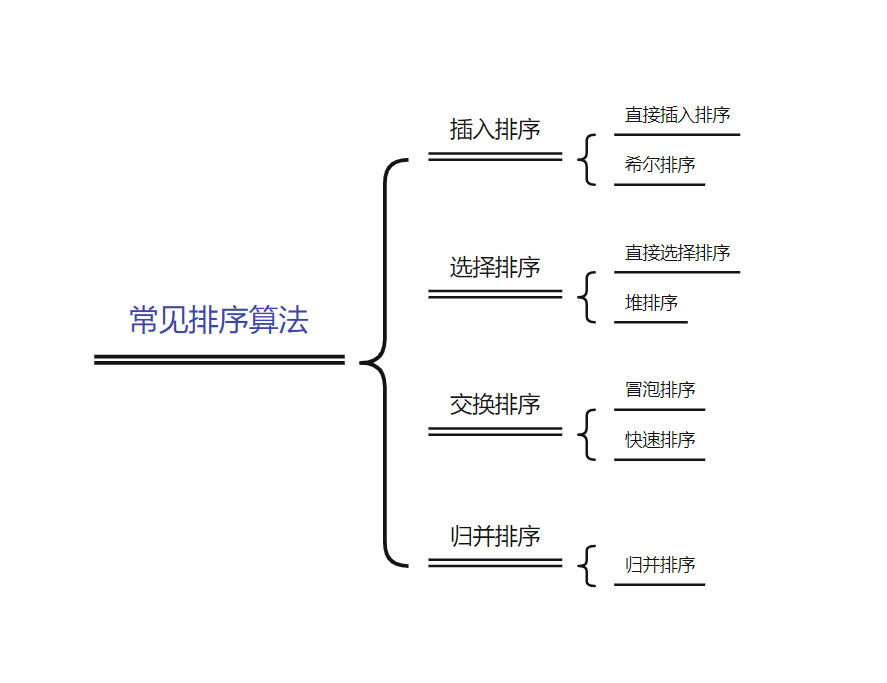
- 常見的排序演算法
- 插入排序
- 希爾排序
- 選擇排序
- 堆排序
- 冒泡排序
- 快速排序
- 左右指標法
- 三數取中法
- 挖坑法
- 前后指標法
- 小區間優化法
- 非遞回實作快排
- 歸并排序
- 非遞回實作
- 內排序與外排序
- 計數排序
排序的概念及其運用
排序的概念
排序:所謂排序,就是使一串記錄,按照其中的某個或某些關鍵字的大小,遞增或遞減的排列起來的操作,
穩定性:假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次
序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排
序演算法是穩定的;否則稱為不穩定的,
內部排序:資料元素全部放在記憶體中的排序,
外部排序:資料元素太多不能同時放在記憶體中,根據排序程序的要求不能在內外存之間移動資料的排序,
排序運用
常見的排序演算法
// 排序實作的介面
// 插入排序
void InsertSort(int* a, int n);
// 希爾排序
void ShellSort(int* a, int n);
// 選擇排序
void SelectSort(int* a, int n);
// 堆排序
void AdjustDwon(int* a, int n, int root);
void HeapSort(int* a, int n);
// 冒泡排序
void BubbleSort(int* a, int n)
// 快速排序遞回實作
// 快速排序hoare版本
int PartSort1(int* a, int left, int right);
// 快速排序挖坑法
int PartSort2(int* a, int left, int right);
// 快速排序前后指標法
int PartSort3(int* a, int left, int right);
void QuickSort(int* a, int left, int right);
// 快速排序 非遞回實作
void QuickSortNonR(int* a, int left, int right)
// 歸并排序遞回實作
void MergeSort(int* a, int n)
// 歸并排序非遞回實作
void MergeSortNonR(int* a, int n)
// 計數排序
void CountSort(int* a, int n)
// 測驗排序的性能對比
void TestOP()
{
srand(time(0));
const int N = 100000;
int* a1 = (int*)malloc(sizeof(int)*N);
int* a2 = (int*)malloc(sizeof(int)*N);
int* a3 = (int*)malloc(sizeof(int)*N);
int* a4 = (int*)malloc(sizeof(int)*N);
int* a5 = (int*)malloc(sizeof(int)*N);
int* a6 = (int*)malloc(sizeof(int)*N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
int begin3 = clock();
SelectSort(a3, N);
int end3 = clock();
int begin4 = clock();
HeapSort(a4, N);
int end4 = clock();
int begin5 = clock();
QuickSort(a5, 0, N-1);
int end5 = clock();
int begin6 = clock();
MergeSort(a6, N);
int end6 = clock();
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
}
排序OJ(可使用各種排序跑這個OJ) OJ鏈接 (插入、選擇、冒泡、前后指標法超時)
插入排序
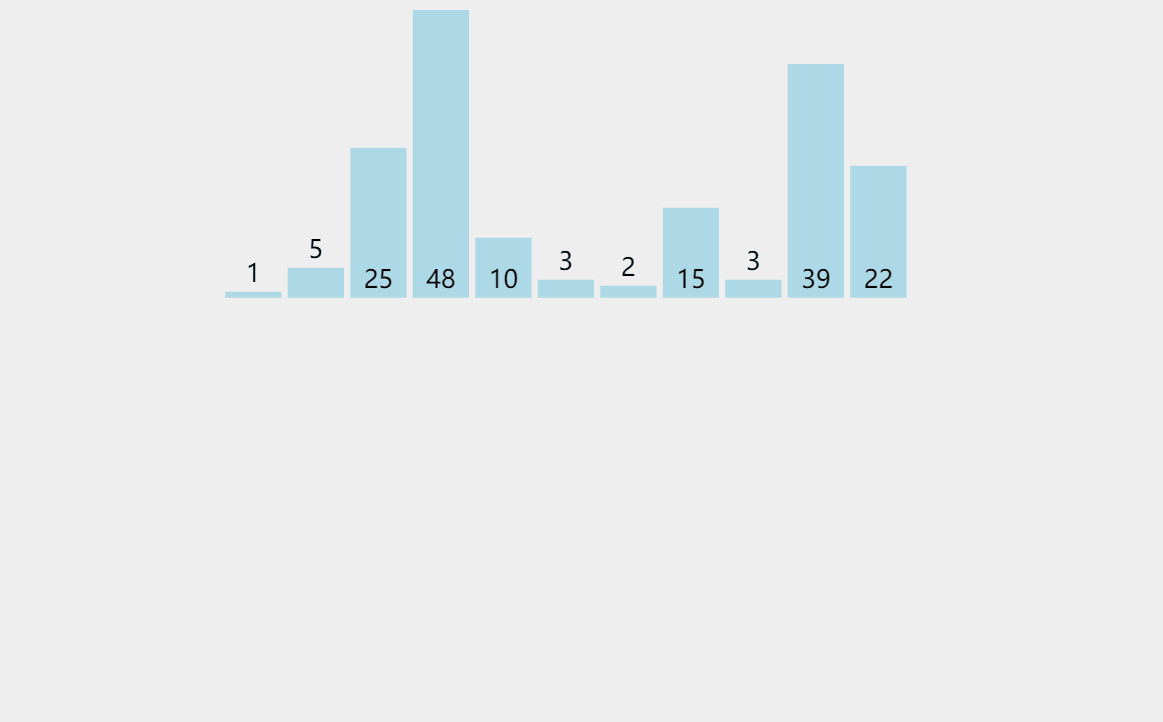
插入排序的思想就像我們打撲克牌,摸完所有牌之后,要將牌進行排序,通常都是將牌插在對應的位置

比如一個陣列a,從a[0],a[1]…a[k],a[k+1]…一直到a[n],使用插入排序的話,就是先將a[0],a[1]…a[k]看成一個有序數列,然后將a[k+1]與a[k]比較,如果比a[k]小,則繼續向前比較,直到a[k]大于其中某個數,就將a[k]插在該數的后面
整體流程:
- 將a[0]看成有序數列,a[1]向前比較,再插入

- 將a[0],a[1]看成有序數列,a[2]向前比較,再插入

- 將a[0],a[1],a[2]看成有序數列,a[3]向前比較,再插入

- 將a[0],a[1],a[2],a[3]看成有序數列,a[4]向前比較,再插入

- …
- 將a[0],a[1],a[2],a[3]…a[k]看成有序數列,a[k + 1]向前比較,再插入

- …
- 將a[0],a[1],a[2],a[3]…a[k],a[k+1]…a[n-1]看成有序數列,a[n]向前比較,再插入

思路: 使用一個end來表示每次插入位置,每次需要插入的元素就在a[end]之后,也就是a[end]是小于需要插入的元素的
代碼:
//插入排序 時間復雜度O(N^2)
void InsertSort(int* a, int n)
{
if (n < 2)
return;
for (int i = 0; i < n - 1; ++i)
{
int end = i;
int tmp = a[i + 1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
--end;
}
else
break;
}
//兩種情況
if (end < 0)//元素插入到陣列的第一位
a[0] = tmp;
else//元素插入到end之后
a[end + 1] = tmp;
//實際上,不加判斷,直接寫成a[end + 1]也是一樣的,因為end<0時,也就是end == 1,end+1就是陣列的第一個位置了
}
}
插入排序的時間復雜度:最壞情況下:O(N^2 ),如果我們的插入排序是要排成升序,則完全是降序的情況下時間復雜度為O(N^2)
? 最好情況:O(N),即已經是有序的情況下,就只需要遍歷陣列,時間復雜度O(N)
希爾排序
希爾排序本質上是插入排序的變種,我們來看機組幾組例子:
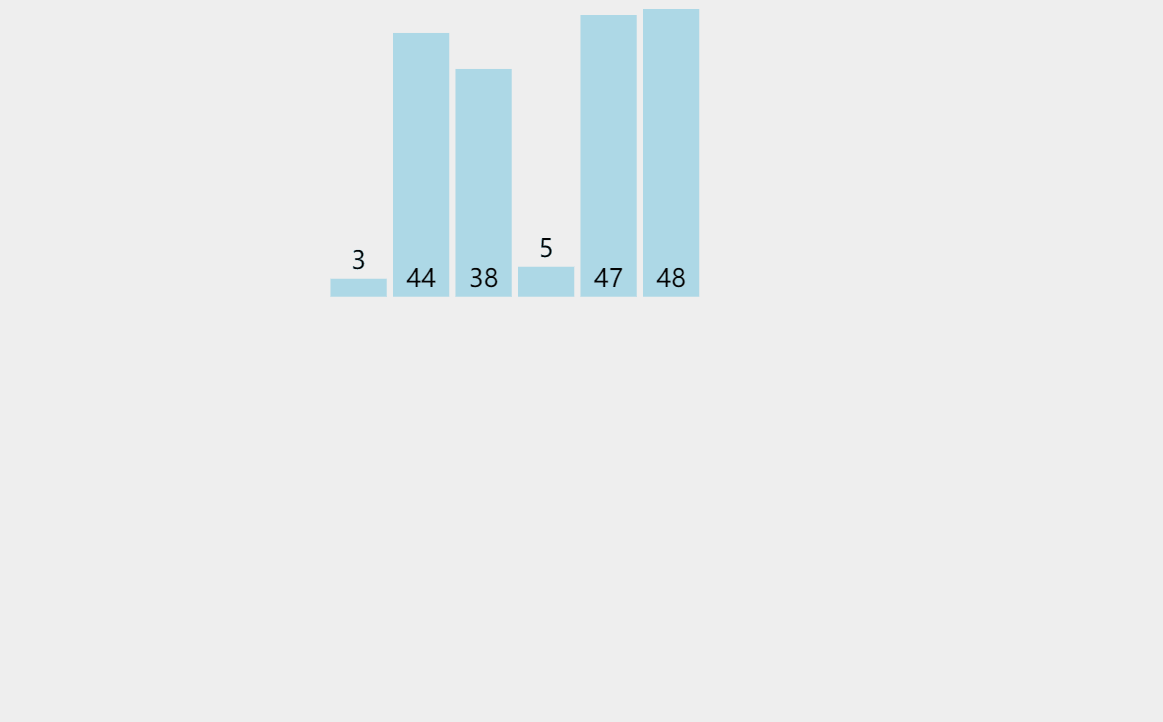
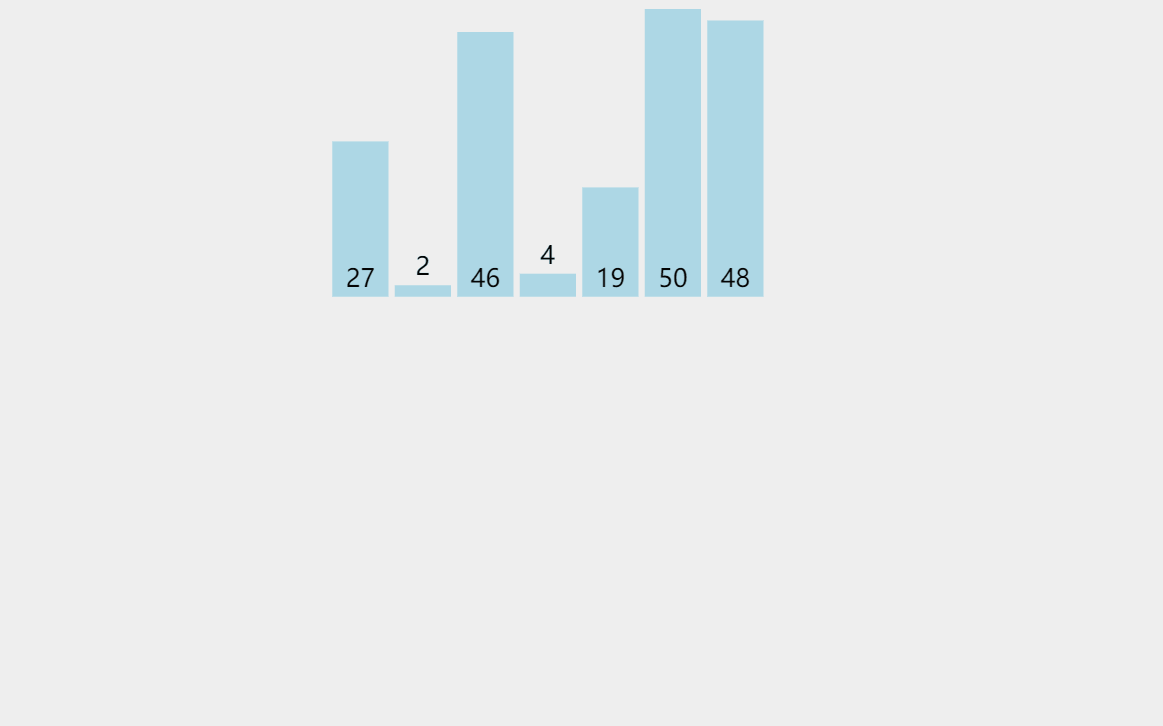
我們觀察到這兩個例子都是接近有序的,所以只移動了幾次,時間復雜度近似為O(N)
希爾排序就是利用這個特點,先將陣列排成近似有序的,再進行一次插入排序,
大致分為兩個步驟:
- 預排序
- 插入排序
那么如何實作預排序呢?
可以利用一個間隙gap,每隔gap個元素分成一組,再對每組元素進行排序,最后即可得到一個接近有序的陣列,
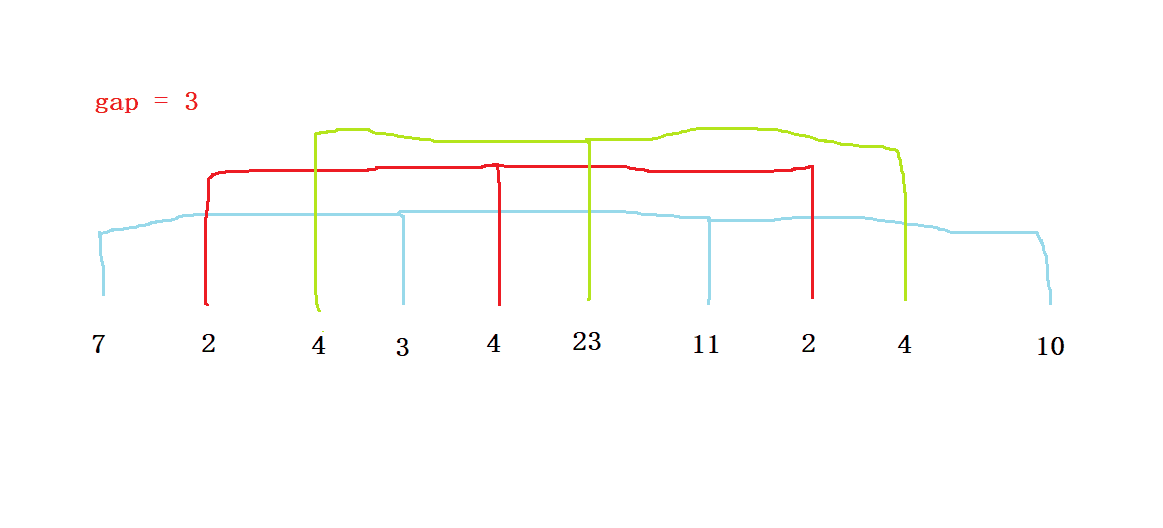
將陣列分為gap部分:
然后藍色的線為一組,紅色的線為一組,綠色的線為一組,分別對三組資料進行插入排序,即為預排序程序,
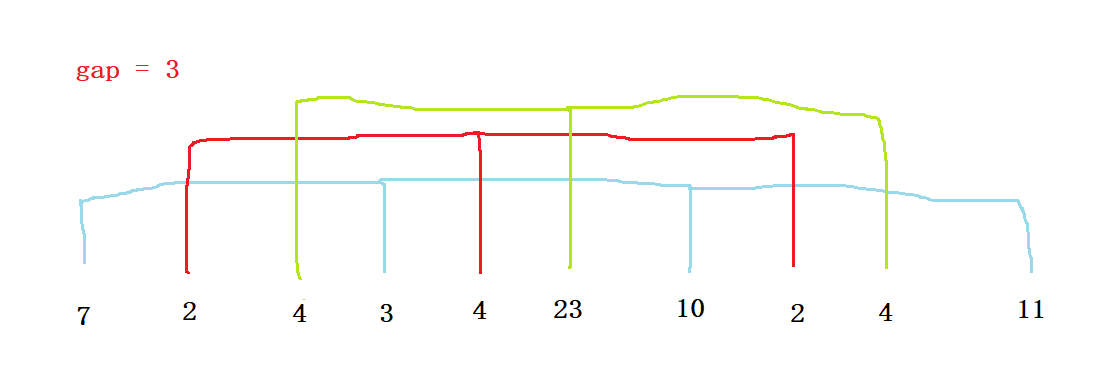
預排序好后,就變成了下圖的樣子:
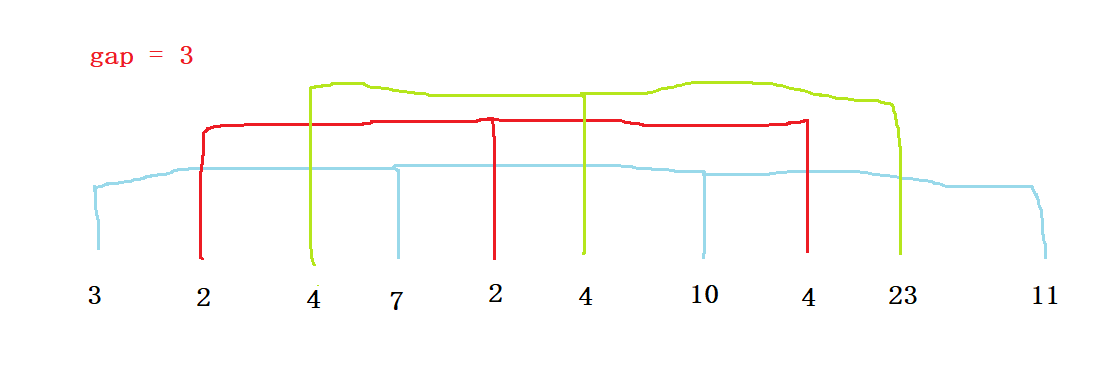
此時的陣列就是一個接近有序的陣列,再次對陣列整體進行插入排序,得到有序陣列,
實際上,當gap為1時,就可以將預處理程序看成是插入排序了,
基于以上分析,我們可以將gap設定為陣列長度n的三分之一、四分之一或者五分之一都行,經過一輪預處理后,再對gap進行縮小,直到最后gap等于1,就可以看作是插入排序了,
關于代碼里有幾個問題需要大家回答:
- 為什么gap要以gap = (gap / 3 + 1)的方式縮小而不是gap = gap / 3
- 為什么for回圈里回圈條件要寫成i < n - gap而不是i < n,更新條件是++i而不是i += gap呢?
代碼:
void ShellSort(int* a, int n)
{
int gap = n;//先初始化gap
while (gap > 1)
{
gap = (gap / 3 + 1);//gap大約為陣列長度的三分之一
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)//查找插入的位置
{
if (a[end] > tmp)
{
a[end + gap] = a[end];/
end -= gap;
}
else
break;
}
a[end + gap] = tmp;
}
}
}
問題一:如果使用gap = gap / 3的方式縮小gap的話,有可能就不能使gap縮小到1,比如n = 6時,一開始gap = 2,隨后根據gap = gap / 3,gap就變成0了,就沒有完成整體的插入排序,所以要使用gap = (gap / 3 + 1)的形式
問題二:因為我們的tmp是設定為a[end + gap],而end == i,當tmp小于前面的元素時,就向前插入,所以只需要將i控制在n - gap就行,那么為什么更新條件是++i而不是i+=gap呢?如果是i+=gap的話,以上面的圖為例,就只能對藍色小組進行預排序,之后就結束回圈了,
而++i的方式則是挨個處理藍紅綠三個小組,可以確保每個小組都被處理到,
選擇排序
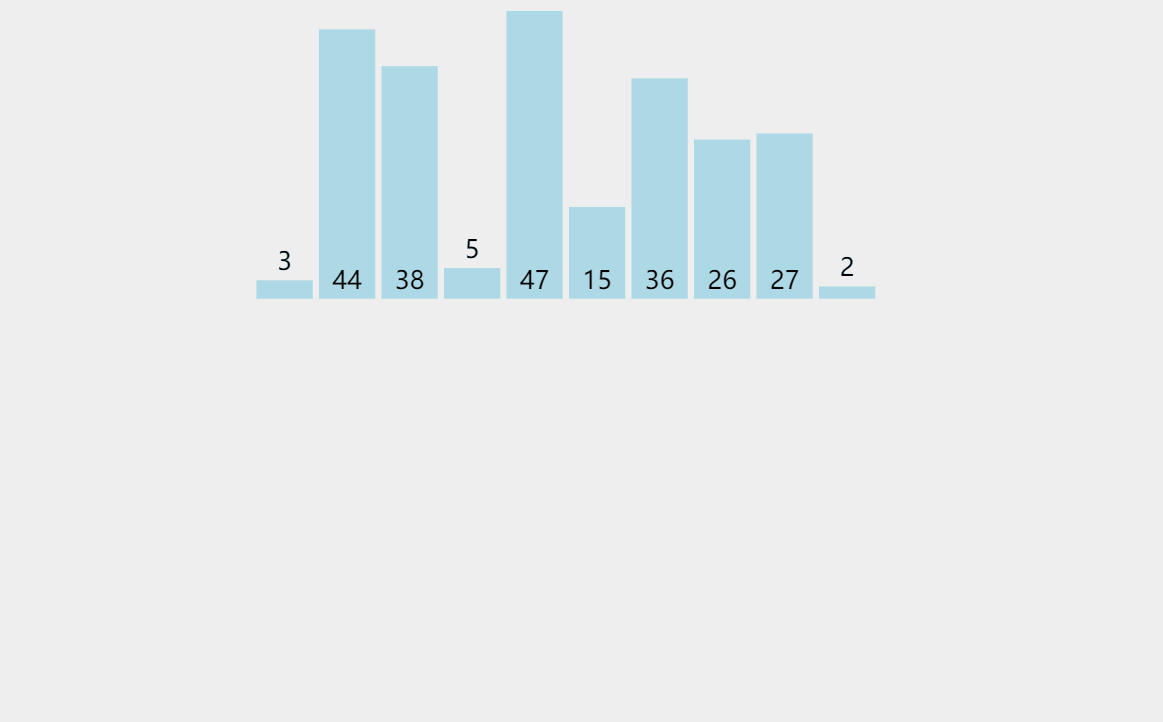
我們可以觀察到,選擇排序是遍歷陣列,選擇一個最小的數,然后與陣列開頭元素交換,以此回圈下去,
時間復雜度O(N^2),
我們可以用一種更快的方式,但并不能改變時間復雜度:在找最小數的同時找最大數,將最大數放在陣列末尾,最小數放在陣列開頭,我們是以下標來標記對應最大值最小值的位置的,
但是這樣寫有一個需要注意的地方,即當陣列的開頭就是最大數時,達不到我們想要的效果,比如[4,2,1,3],最小值為1,最大值為4,我們先將最小值與陣列開頭元素交換,得到[1,2,4,3],接下來我們還想將最大值與陣列末尾元素交換,但此時,原本最大元素的位置以及不是最大值了,而是1,此時就需要更新最大值的位置:maxindex = minindex(新的4的位置)
既然當最大值在陣列開頭時需要處理,那當最小值在陣列末尾時需要處理嗎?以[2,4,3,1]為例,最小值為1,最大值為4,先將1和2交換,得到[1,4,3,2],此時maxindex位置處的元素仍然是4,直接交換4,2即可,不需要進行特殊處理,
代碼:
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
void SelectSort(int* a, int n)
{
int left = 0;
int right = n - 1;
while (left < right)
{
int maxindex = left;//一開始初始化最大最小值均為陣列開頭元素
int minindex = left;
for (int i = left; i <= right; ++i)
{
if (a[maxindex] < a[i])//查找最大值
maxindex = i;
if (a[minindex] > a[i])//查找最小值
minindex = i;
}
//將最大值最小值歸位
Swap(&a[left], &a[minindex]);
if (left == maxindex)
maxindex = minindex;
Swap(&a[right], &a[maxindex]);
++left;
--right;
}
}
堆排序
在了解堆排序之前需要先了解一下什么是堆,堆就類似一棵二叉樹,不過堆是相對更有序的二叉樹,有大堆和小堆之分,
可以先了解一下作者的上一篇文章:堆的實作及應用
了解了堆后,如果我們想要實作排升序,就要先建大堆,
為什么建大堆而不是小堆呢?
我們來看建小堆的話是怎么一個情況:
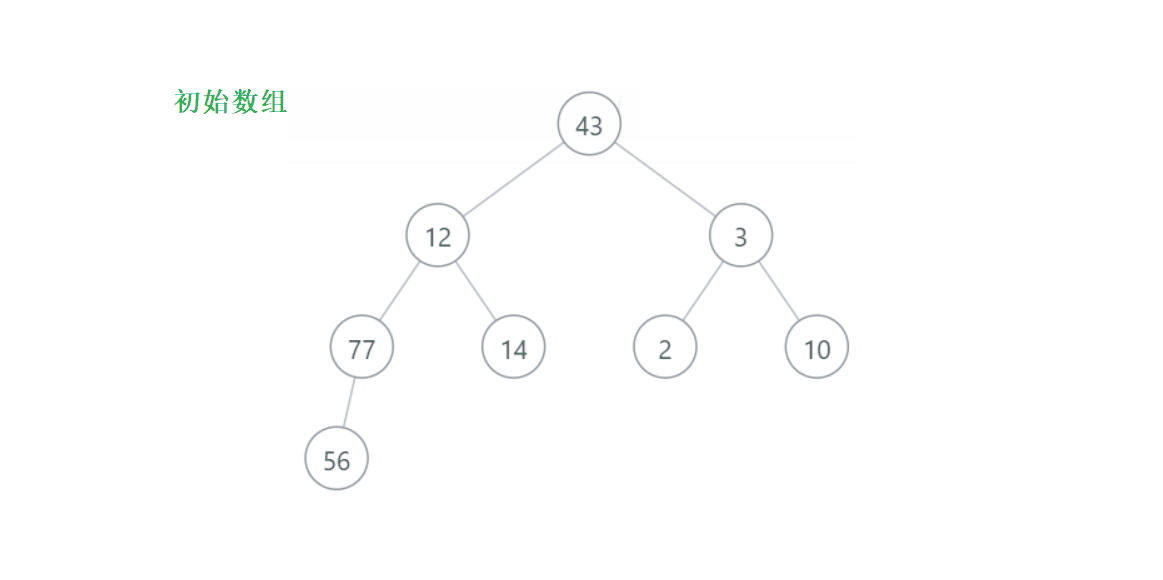
以[43,12,3,77,14,2,10,56]為例
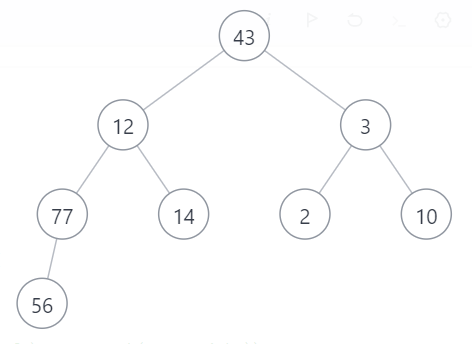
建好小堆后:[2,12,3,56,14,43,10,77]
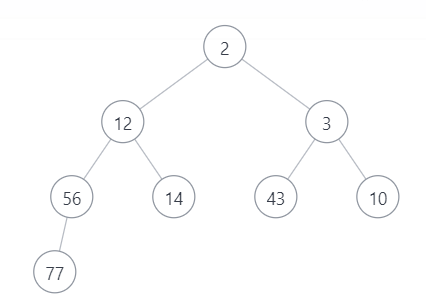
堆頂最小的元素,所以我們需要拿出第二小的數,就要將2從堆中分離出來,也就是剩下的元素從成組成堆,2是根節點,將2脫離出來后,意味著又要重新建堆,時間復雜度O(N),如果反復這樣的話,整個排序的時間復雜度就為O(N^2),堆的優點就沒有被體現出來,
所以,要想排升序的話需要建大堆(排降序是小堆)
我們建好大堆后,堆頂就是最大的數了,將最大的數與堆底的數交換,將堆的大小減1,再進行向下調整,如此往復,當堆只剩下一個元素時,排序就完成了,
也許大家會覺得,那建小堆的話,也將堆頂與堆底的資料進行交換不就可以了,這么做確實可以完成排序,不過完成的是降序,因為最小值在陣列末尾,然后依次類推…
整體程序如下:
代碼:
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
//向下調整演算法
void AddJustDown(int*a, int n, int parent)
{
int child = 2 * parent + 1;
while (child < n)//控制孩子節點不能越界
{
//將左右孩子中較小的與父親比較
//右孩子不能越界
if ((child + 1) < n && a[child] < a[child + 1])
{
++child;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
//堆排序——s
void HeapSort(int* a, int n)
{
//建大堆
//時間復雜度O(n)
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AddJustDown(a, n, i);
}
int end = n - 1;
//總體時間復雜度O(n*logn)
while (end > 0)
{
Swap(&a[0], &a[end]);
AddJustDown(a, end, 0);
--end;
}
}
冒泡排序
冒泡排序的思想類似于選擇排序,冒泡是對陣列里的元素逐一比較,如果前一個元素大于后一個元素,則調換兩者的位置,以此類推,可以將陣列中的最大值放到陣列末尾,下一輪排序時陣列末尾就不用再進行比較了,經過n-1輪調換,就可以將陣列排好序,
兩者的時間復雜度都為O(N^2),但在陣列接近有序的情況下,冒泡的效率是要高于選擇排序的,因為冒泡可以對陣列有序進行判斷,如果有序就不再接著排序了,而選擇排序是無法判斷陣列是否有序的,也就是需要無條件遍歷陣列,
代碼:
void BubbleSort(int* a, int n)
{
int i = 0;
int j = 0;
int flag = 0;//用來判斷陣列是否有序
for (i = 0; i < n - 1; ++i)
{
flag = 0;
for (j = 0; j < n - i - 1; ++j)
{
if (a[j] > a[j + 1])
{
Swap(&a[j], &a[j + 1]);
flag = 1;
}
}
if (flag == 0)
{
break;
}
}
}
快速排序
快速排序有四種實作方法:
- 左右指標法
- 挖坑法
- 前后指標法
- 非遞回實作
左右指標法
我們先解釋左右指標法,
大概思路是選出一個key,key一般是最左邊或者最右邊的元素,將key放到正確的位置上去,比如key是第六大的數,就將key放在陣列的第六個位置,而key左邊的數小于key,右邊的數大于key,依次再分別對左右兩邊陣列進行遞回,當陣列縮小到只有1個或0個元素時,就停止遞回,
所以我們可以定義一個左指標left,一個右指標right,right先從右向左查找小于key的元素,找到了就停下來,left就開始從左向右查找大于key的元素,找到了也停下來,再交換right、left處的元素,由此再繼續right和left的查找,直到left與right相遇,此時將相遇處的元素與key交換,再進行遞回,
我們必須要注意:相遇處的元素是一定小于key的,因為是right先走,如果是left先走就不是了,
觀察一個示例: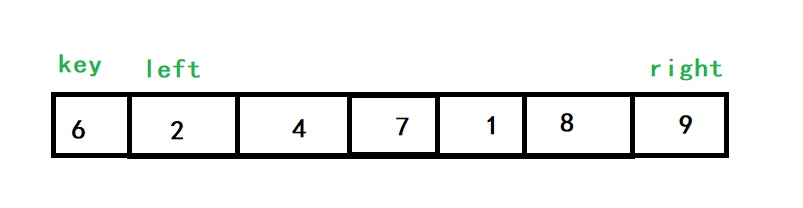
right先走,找到比key(6)小的數字,也就是1,left再查找比key大的數字,也就是7
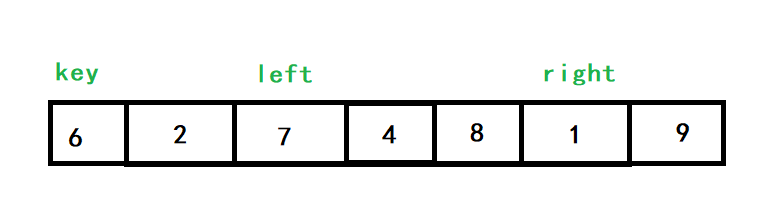
交換7和1的位置,再繼續進行查找
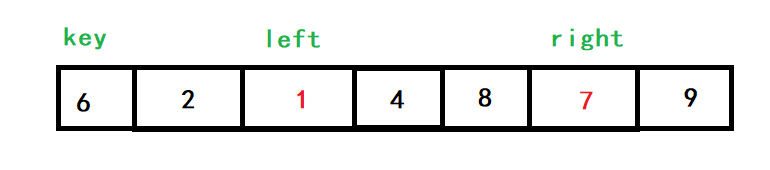
再查找的話,right就指向了4,left再向右查找,此時left還未找到比key大的數字就與right相遇了,相遇元素就是4,4<6,交換4、6的位置,而此時,6的位置就被找好了,再對6左邊的陣列與右邊的陣列進行相同的處理即可完成排序,
我們看到,相遇元素4是小于key的,這不是巧合,因為是right先走,所以相遇的元素一定是right先找到的,
相遇時有兩種情況:
-
右遇左:
a.陣列有序
b.左右位置的值剛進行交換,所以左指標指向的值小于key,而右指標向左沒有找到小于key的元素,遇到左指標,所以相遇值小于key
-
左遇右:右指標已經找到小于key的元素,左指標向右沒有找到大于key的元素,遇見了右指標,所以相遇值小于key
但是,如果是left先走,相遇元素就一定大于key了,并且key要是最右邊的元素,
由于有三種方法,我們將每種方法單獨寫成一個函式SingleWaySorting,再共用一個函式QuickSort包裝進行遞回,
看下面的代碼,大家思考一下為什么這里的回圈需要加上left < right的限制呢?
while (left < right && a[right] >= a[keyi])//查找小于key的元素
{
--right;
}
while (left < right && a[left] <= a[keyi])//查找大于key的元素
{
++left;
}
代碼:
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
//單趟排序——左右指標法
int SingleWaySorting1(int* a, int begin, int end)
{
int left = begin + 1;
int right = end;
int keyi = begin;
while (left < right)
{
while (left < right && a[right] >= a[keyi])//查找小于key的元素
{
--right;
}
while (left < right && a[left] <= a[keyi])//查找大于key的元素
{
++left;
}
//交換left、right
Swap(&a[left], &a[right]);
}
//相遇元素與key元素交換
Swap(&a[left], &a[keyi]);
return left;
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
int keyi = SingleWaySorting1(a, begin, end);//接收key元素的位置,即分界位置
QuickSort(a, begin, keyi - 1);//對key左邊進行排序
QuickSort(a, keyi+1, end);//對key右邊進行排序
}
為什么要加left < right呢?
當陣列有序時,我們看一下如果不加限制,會是什么結果?
right向左查找小于1的數
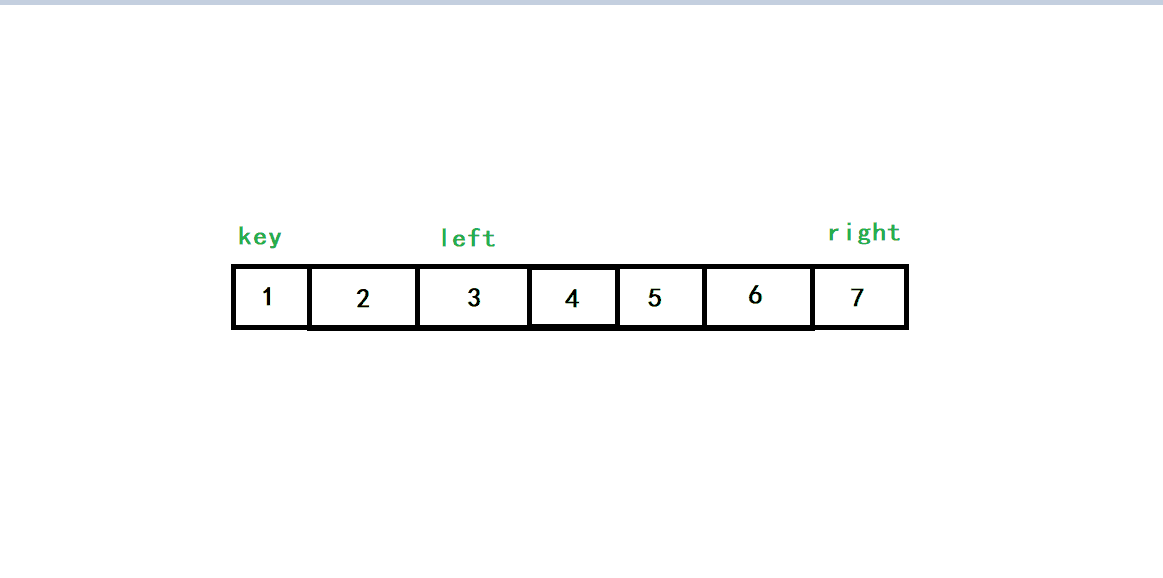
我們發現,如果不加限制的話,right會有越界的行為,所以加上限制是防止陣列越界的現象發生,
同樣,正是因為有序,快速排序的效率反而變低了,甚至是最壞的情況,該情況下時間復雜度為O(N^2)
當key剛好為陣列有序情況下的中位數時,效率最高,時間復雜度為O(N * logN)
我們對上面兩種情況進行分析:
當key剛好為陣列有序情況下的中位數時
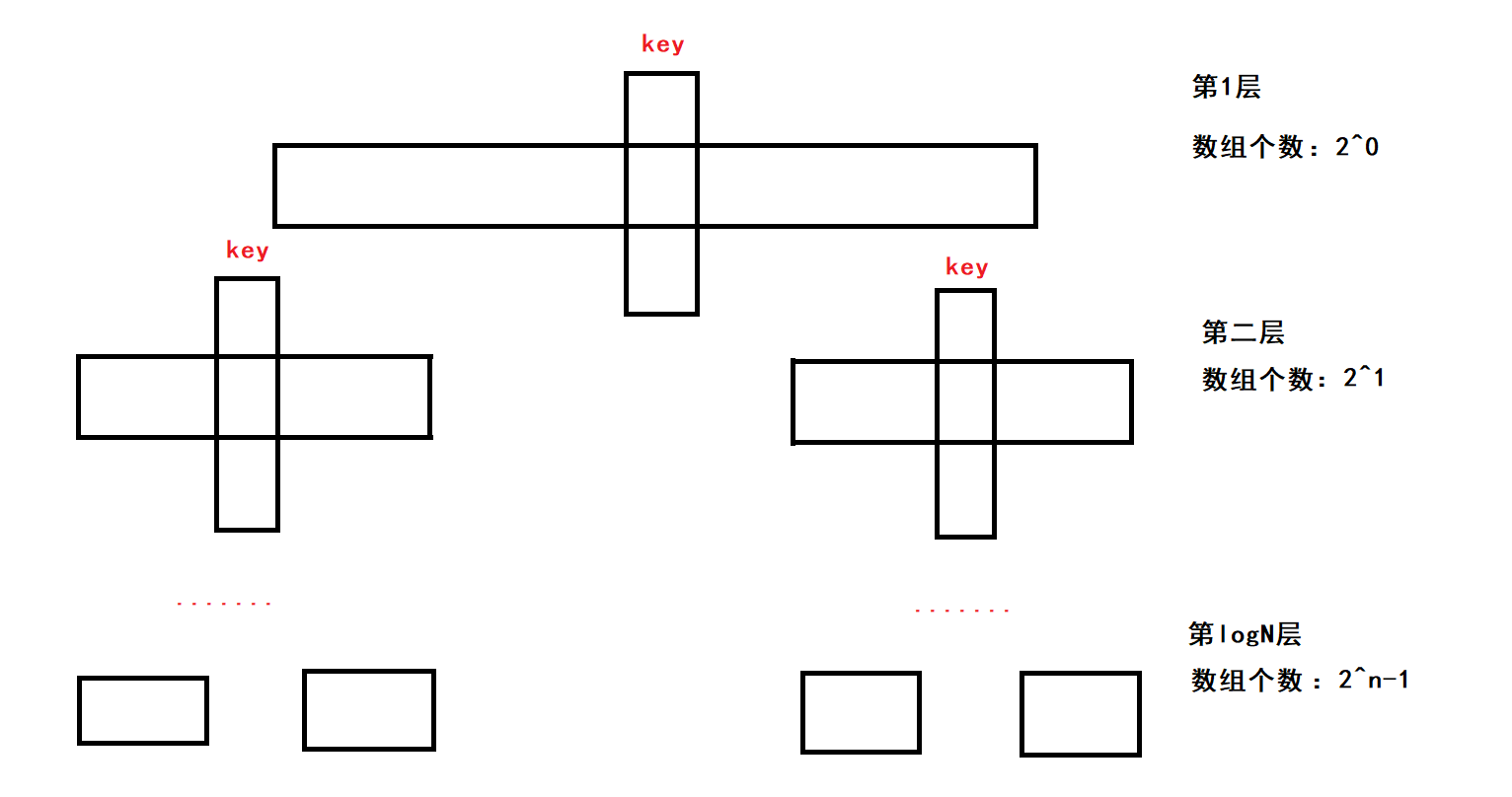
每次遞回就是以key為分割點,將左右陣列近似均等地分開,最后分開的形狀就是一顆二叉樹,N為陣列的長度,所以樹的高度就是logN
單趟排序的時間復雜度為O(N),所以每一層的排序的時間復雜度總和為O(N),而每一層的時間復雜度相加,就得到了O(N * logN)
當陣列有序時,key為陣列中最小的元素
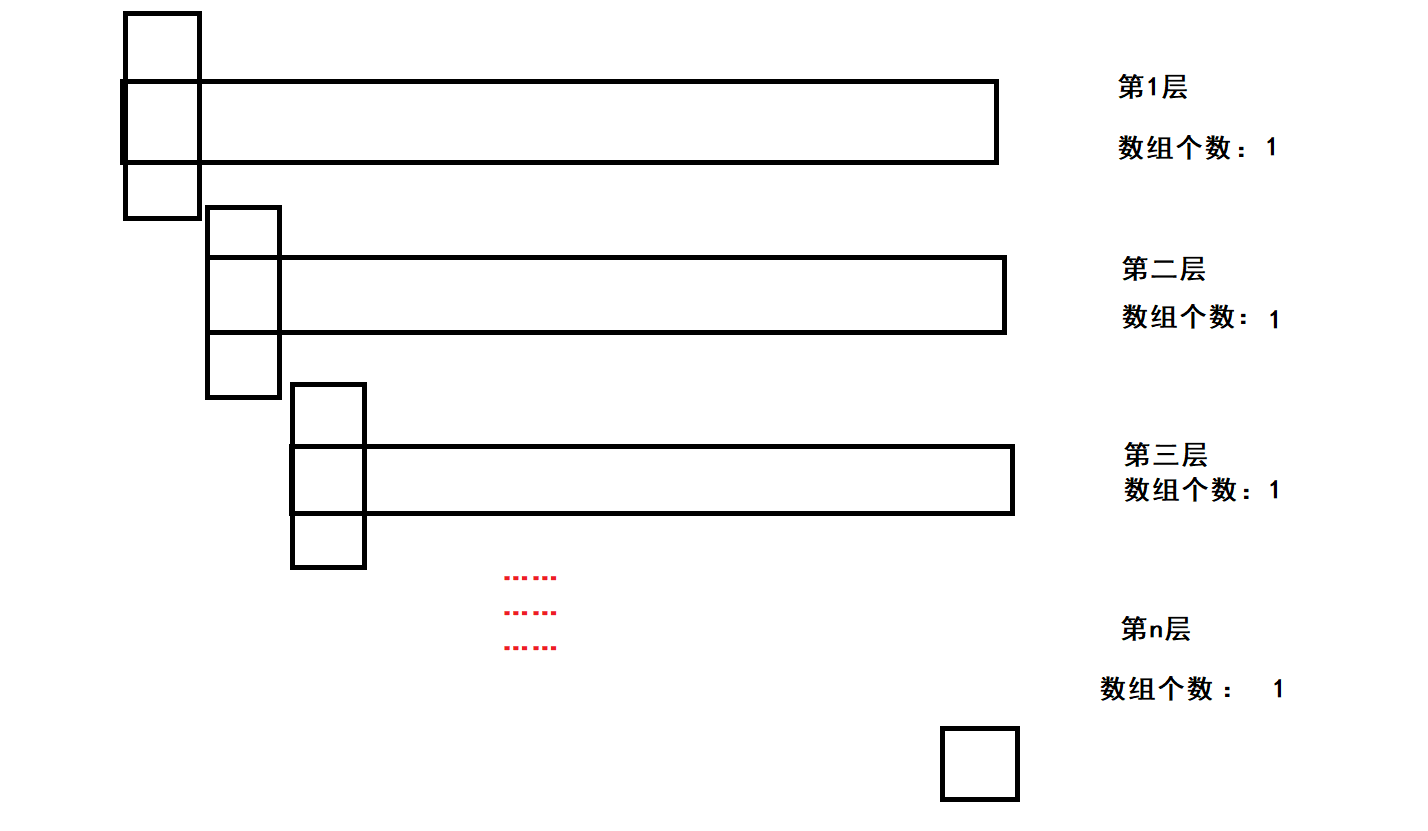
同樣,每一層單趟排序的時間復雜度為O(N),共有N層,所以時間復雜度總和為O(N^2)
我們來看一下排序有序和無序陣列的區別:
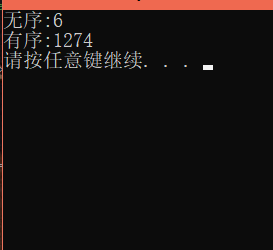
圖中數字代表排序所用時間(單位:毫秒),結果在releas版本下測量得到
我們看到,此時快排對有序陣列的排序是用了1274毫秒的,而對一個隨機的無序陣列則用了6毫秒,差距是十分明顯的,
既然這樣,我們有沒有什么辦法來優化呢?
答案是:有的,
三數取中法
我們采用三數取中法就可以完成對有序陣列排序的優化,
三數取中法的思路:對于陣列a,我們取出陣列的最左邊的元素left,最右邊的元素right以及中間的元素mid,然后取這三者中既不是最大、也不是最小的元素來作為key,
代碼:
int GetMidIndex(int* a, int begin, int end)
{
int left = begin;
int right = end;
int mid = (left + right) / 2;
if (a[left] > a[right])
{
if (a[mid] < a[right])
return right;
else if (a[mid] > a[left])
return left;
else
return mid;
}
else//left<=right
{
if (a[mid] < a[left])
return left;
else if (a[mid] > a[right])
return right;
else
return mid;
}
}
加入到SingWaySorting1中:
int SingleWaySorting1(int* a, int begin, int end)
{
int left = begin;
int right = end;
int keyi = begin;//key的下標
//將三數取中的結果與begin指向的元素交換
Swap(&a[keyi], &a[GetMidIndex(a, begin, end)]);
while (left < right)
{
while (left < right && a[right] >= a[keyi])//查找小于key的元素
{
--right;
}
while (left < right && a[left] <= a[keyi])//查找大于key的元素
{
++left;
}
Swap(&a[left], &a[right]);
}
//相遇元素與key元素交換
Swap(&a[left], &a[keyi]);
return left;
}
這時再分別對有序和無序的陣列排序:
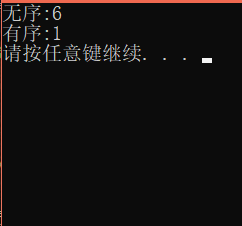
現在我們看到,兩者的差距只有幾毫秒了,所以三數取中的優化效果是十分明顯的,
接下來我們講第二種快排思路:
挖坑法
挖坑法與左右指標法很型別,不過比較好理解,
我們同樣取最左邊或最右邊的元素作為key,接下來的講解以最左邊元素作為key,
保存key的值,將key視為一個坑,隨后也是用一個右指標right查找小于key的元素,找到后,將該元素填入到前面的key的坑中,此時right指向的地方就成為了一個新坑,再用左指標left查找大于key的元素,找到后,將該元素填入right指向的坑中,此時left指向的位置就變成了一個坑,隨后再用右指標查找下一個小于key的元素…依次類推,當right、left相遇時,left指向的相遇處已經是hole了,將key填入相遇的位置處,就完成了單趟排序
以[3,1,7,4,5,2,6]為例,初始情況如下:
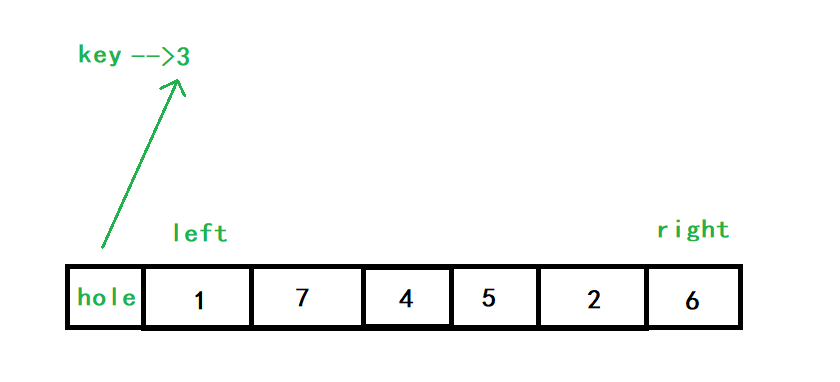
right向左查找小于3的數,也就是2,將2填入hole中,right指向的位置就變成了新的hole
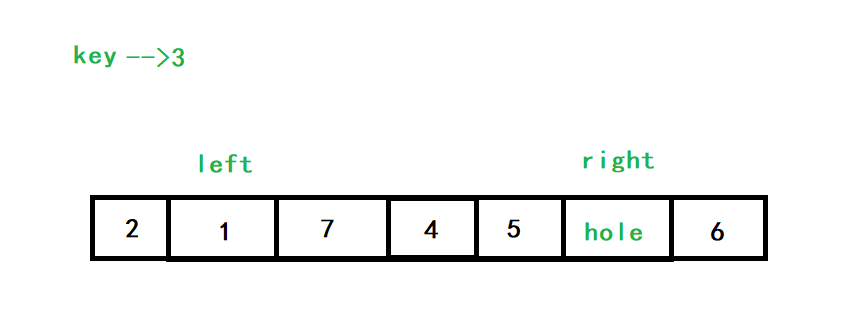
left向右查找大于3的數,也就是7,將7填入hole中,left所指的位置就變成了新的hole
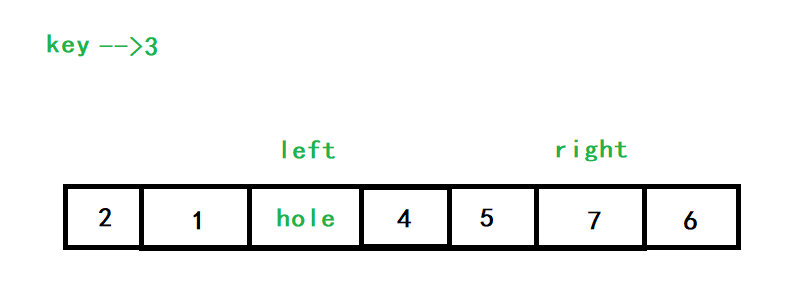
right再向左查找,發現left之后沒有小于3的數了,就與left相遇了,再將key填入hole中,3的位置就被固定好了,于是就完成了單趟排序
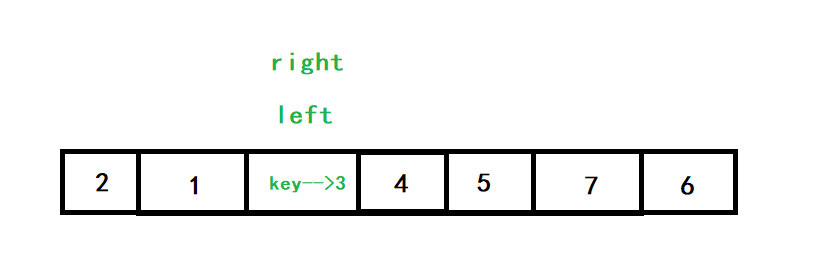
代碼:
int SingleWaySorting2(int* a, int begin, int end)
{
int left = begin;
int right = end;
int keyi = begin;
Swap(&a[keyi], &a[GetMidIndex(a, begin, end)]);
int tmp = a[keyi];
while (left < right)
{
while (left < right && a[right] >= tmp)//查找小于key的數
{
--right;
}
//填坑
a[keyi] = a[right];
while (left < right && a[left] <= tmp)//查找大于key的數
{
++left;
}
//填坑
a[right] = a[left];
//更新坑
keyi = left;
}
//將key填入相遇位置
a[left] = tmp;
return left;
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
int keyi = SingleWaySorting3(a, begin, end);
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi+1, end);
}
最后我們來講快排的最后一種思路:
前后指標法
前后指標法就是我們一開始的動圖采用的方法,與前兩種都有相似之處,
前后指標法有兩種實作方式,
一種是key是第一個元素,一種是key是最后一個元素
兩者思路相似
第一種:
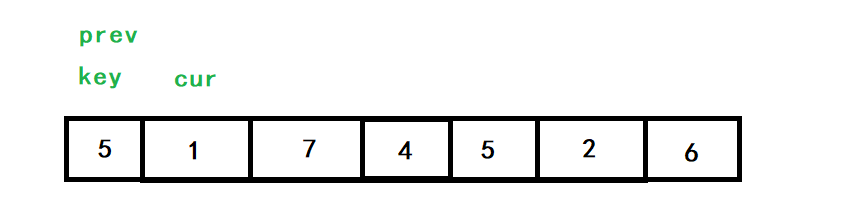
第二種:
cur要從第一個元素開始,將小于key的元素放前面,大于key的元素拋后面
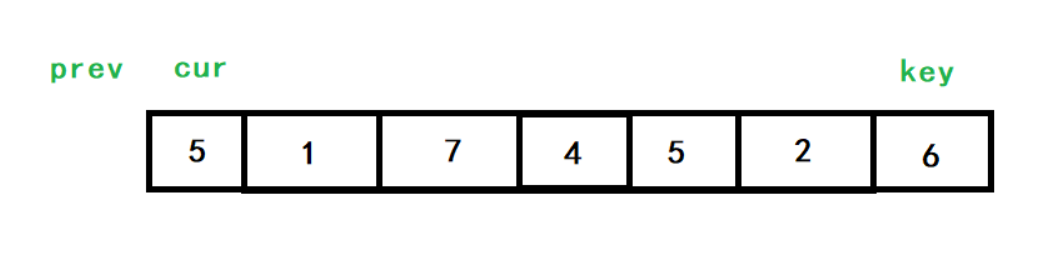
key還是最左邊的值,設定前指標prev,后指標cur,cur和prev一開始保持一前一后的位置,prev指向陣列首元素,
cur去找比key小的值,把小的放在前面,大的放后面,找到以后,++prev,再交換prev和cur對應位置處的值,當cur>end時,key與prev的值交換,單趟排序結束,
以[5,1,7,4,5,2,6]為例,初始情況如下:
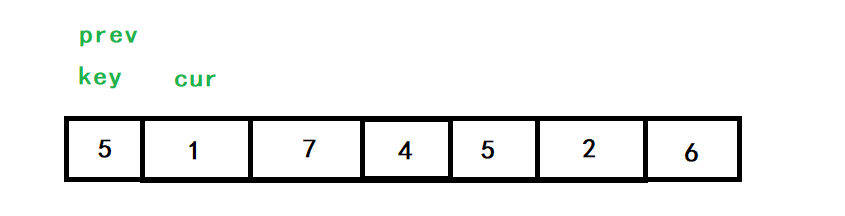
cur查找小于5的數,也就是1,找到后,++prev,對cur和prev指向的值進行交換,此時他倆指向同一位置,
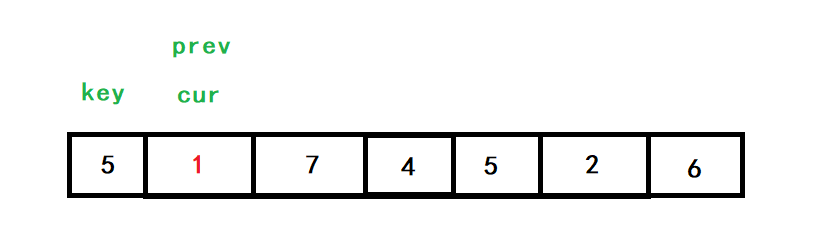
cur再向后找,找到了4,++prev,對cur和prev指向的值進行交換
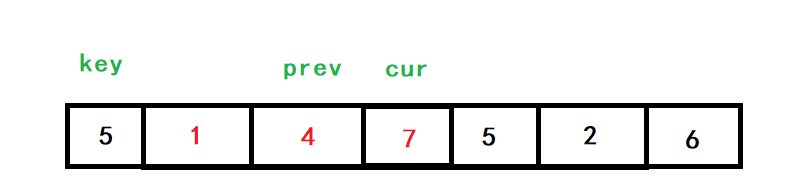
cur再向后找,找到了2,++prev,對cur和prev指向的值進行交換
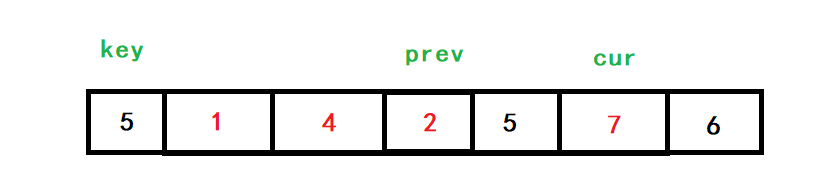
cur再向后已經找不到小于5的數了,于是cur>end,回圈結束,key與prev的值互換,
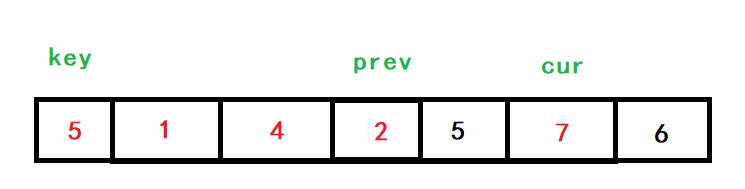
這樣就完成了單趟排序,再將key左右兩邊的陣列進行遞回,就完成了排序,
代碼:
int SingleWaySorting3(int*a, int begin, int end)
{
int cur = begin + 1;
int prev = begin;
int keyi = begin;
while (cur <= end)
{
while (cur <= end && a[cur] >= a[keyi])
{
++cur;
}
if (cur <= end)//當cur>end時不需要再++,因為此時的prev要與key交換
++prev;
if (cur <= end && cur != prev)//當prev和cur指向同一元素時可以不進行交換
{
Swap(&a[prev], &a[cur]);
}
//交換完需要++cur,否則cur一直指向該位置,代碼會陷入死回圈
++cur;
}
Swap(&a[keyi], &a[prev]);
return prev;
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
int keyi = SingleWaySorting3(a, begin, end);
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi+1, end);
}
方法二:
先看代碼:
int SingleWaySorting4(int* a, int begin, int end)
{
//因為key是陣列末尾的元素,所以第一個元素也要經過判斷
int prev = begin - 1;
int cur = begin;
int keyi = end;
while (cur <= end)
{
if (a[cur] >= a[keyi])
{
++cur;
}
if (cur <= end && a[cur] < a[keyi])
{
++prev;
Swap(&a[prev], &a[cur]);
++cur;
}
}
//最后prev指向的是小于key的元素,所以prev要++,指向大于等于key的元素,從而將key放到正確的位置
++prev;
Swap(&a[prev], &a[keyi]);
return prev;
}
如果cur指向的元素大于key,則cur向后走,prev不動直到cur找到小于key的元素,prev++,此時prev指向的就是大于key的元素,兩者交換,再繼續查找,
當cur>end時跳出回圈,此時prev指向的是小于key的元素,所以最后需要++,使其指向大于key的元素,再交換key和prev指向的元素,就可以使key放到正確的位置上,
但存在一種特殊情況,也就是key是最小的元素,所以key應該放到第一個位置,當回圈結束時,prev還是等于begin - 1,所以++prev,prev就指向了第一個元素,從而交換元素,使key位于第一個位置,
因此,
++prev;
Swap(&a[prev], &a[keyi]);
return prev;
這段代碼起到了兩個作用,處理了兩種情況,
除了我們講的三數取中可以優化快排,還有一種小區間優化法也可以對其進行優化,小區間優化法是減少遞回呼叫的次數,現代cpu已經使遞回的效率非常高了,遞回程度太深時程式本身沒問題,但是堆疊空間不夠,導致堆疊溢位,
小區間優化法
小區間優化法是當遞回至陣列只有小部分元素時,比如10、20、30等等,我們就不再用快排了,而是選擇用其他的排序,比如InsertSort
使用:
int SingleWaySorting3(int*a, int begin, int end)
{
int cur = begin + 1;
int prev = begin;
int keyi = begin;
while (cur <= end)
{
while (cur <= end && a[cur] >= a[keyi])
{
++cur;
}
if (cur <= end)//當cur>end時不需要再++,因為此時的prev要與key交換
++prev;
if (cur <= end && cur != prev)//當prev和cur指向同一元素時可以不進行交換
{
Swap(&a[prev], &a[cur]);
}
//交換完需要++cur,否則cur一直指向該位置,代碼會陷入死回圈
++cur;
}
Swap(&a[keyi], &a[prev]);
return prev;
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
return;
if (end - begin > 10)
{
int keyi = SingleWaySorting3(a, begin, end);
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi+1, end);
}
else
{
//a+begin是排序開始的地方
//end-begin+1是排序的長度
InsertSort(a, a + begin, end - begin + 1);
}
}
非遞回實作快排
非遞回實作快排就需要我們借用堆疊來作為輔助了,
將每個陣列的begin、end入堆疊,然后進行單趟排序得到排序后的key的位置,再pop掉begin、end,將被分割后的陣列的begin、end入堆疊,再回圈進行單趟排序,回圈的終止條件是堆疊為空時,
代碼:
Stack.h:
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#include<stdbool.h>
#include<assert.h>
typedef int tp;
typedef struct Stackmember {
tp capacity;
tp top;
tp* a;
}s;
//堆疊的初始化
void StackInit(s* phead);
//堆疊的摧毀
void StackDestroy(s* phead);
//進堆疊
void StackPush(s* phead, tp x);
//出堆疊
void StackPop(s* phead);
//回傳堆疊頂資料
tp StackTop(s* phead);
//判斷堆疊是否為空
bool StackEmpty(s* phead);
//回傳堆疊的大小
tp StackSize(s* phead);
Stack.c:
#include"Stack.h"
void StackInit(s* phead)
{
phead->a = (tp*)malloc(4 * sizeof(tp));
if (phead->a == NULL)
{
perror("malloc");
exit(-1);
}
phead->capacity = 4;
phead->top = 0;
}
void StackDestroy(s* phead)
{
assert(phead != NULL);
free(phead->a);
phead->a = NULL;
phead->top = phead->capacity = 0;
}
void StackPush(s* phead, tp x)
{
assert(phead != NULL);
if (phead->top == phead->capacity)//判斷堆疊是否已滿,滿了就擴容
{
tp* tmp = (tp*)realloc(phead->a, 2 * (phead->capacity) * sizeof(tp));
if (tmp == NULL)
{
perror("realloc");
StackDestroy(phead);
exit(-1);
}
phead->a = tmp;
phead->capacity *= 2;
tmp = NULL;
}
phead->a[phead->top] = x;
phead->top++;
}
void StackPop(s* phead)
{
assert(phead != NULL);
assert(!StackEmpty(phead));
phead->top--;
}
tp StackTop(s* phead)
{
assert(phead != NULL);
assert(!StackEmpty(phead));
return phead->a[phead->top - 1];
}
//判斷堆疊是否為空
bool StackEmpty(s* phead)
{
return phead->top == 0;
}
tp StackSize(s* phead)
{
assert(phead != NULL);
assert(!StackEmpty(phead));
return phead->top;
}
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
//三數取中
int GetMidIndex(int* a, int begin, int end)
{
int left = begin;
int right = end;
int mid = (left + right) / 2;
if (a[left] > a[right])
{
if (a[mid] < a[right])
return right;
else if (a[mid] > a[left])
return left;
else
return mid;
}
else//left<=right
{
if (a[mid] < a[left])
return left;
else if (a[mid] > a[right])
return right;
else
return mid;
}
}
int SingleWaySorting1(int* a, int begin, int end)
{
int left = begin;
int right = end;
int keyi = begin;
Swap(&a[keyi], &a[GetMidIndex(a, begin, end)]);
while (left < right)
{
while (left < right && a[right] >= a[keyi])//查找小于key的元素
{
--right;
}
while (left < right && a[left] <= a[keyi])//查找大于key的元素
{
++left;
}
Swap(&a[left], &a[right]);
}
//相遇元素與key元素交換
Swap(&a[left], &a[keyi]);
return left;
}
void NonRecursiveQSort(int*a, int begin, int end)
{
s s1;
StackInit(&s1);
StackPush(&s1, begin);
StackPush(&s1, end);
while (!StackEmpty(&s1))
{
int end = StackTop(&s1);
StackPop(&s1);
int begin = StackTop(&s1);
StackPop(&s1);
int keyi = SingleWaySorting1(a, begin, end);//用左右指標法排序
if (begin < end)//當陣列長度符合要求時將對應的begin和end入堆疊
{
if (begin < keyi - 1)//當陣列長度符合要求時將對應的begin和end入堆疊
{
StackPush(&s1, begin);
StackPush(&s1, keyi - 1);
}
if (keyi + 1 < end)//當陣列長度符合要求時將對應的begin和end入堆疊
{
StackPush(&s1, keyi + 1);
StackPush(&s1, end);
}
}
}
StackDestroy(&s1);
}
歸并排序
原理:將子陣列排成有序的,再將子陣列合并,
思路:將陣列分為兩部分,分別對兩部分進行排序,隨后合并左右兩部分(即合并兩個有序陣列),但我們要一直向下二分,直到只剩下一個元素無法二分,
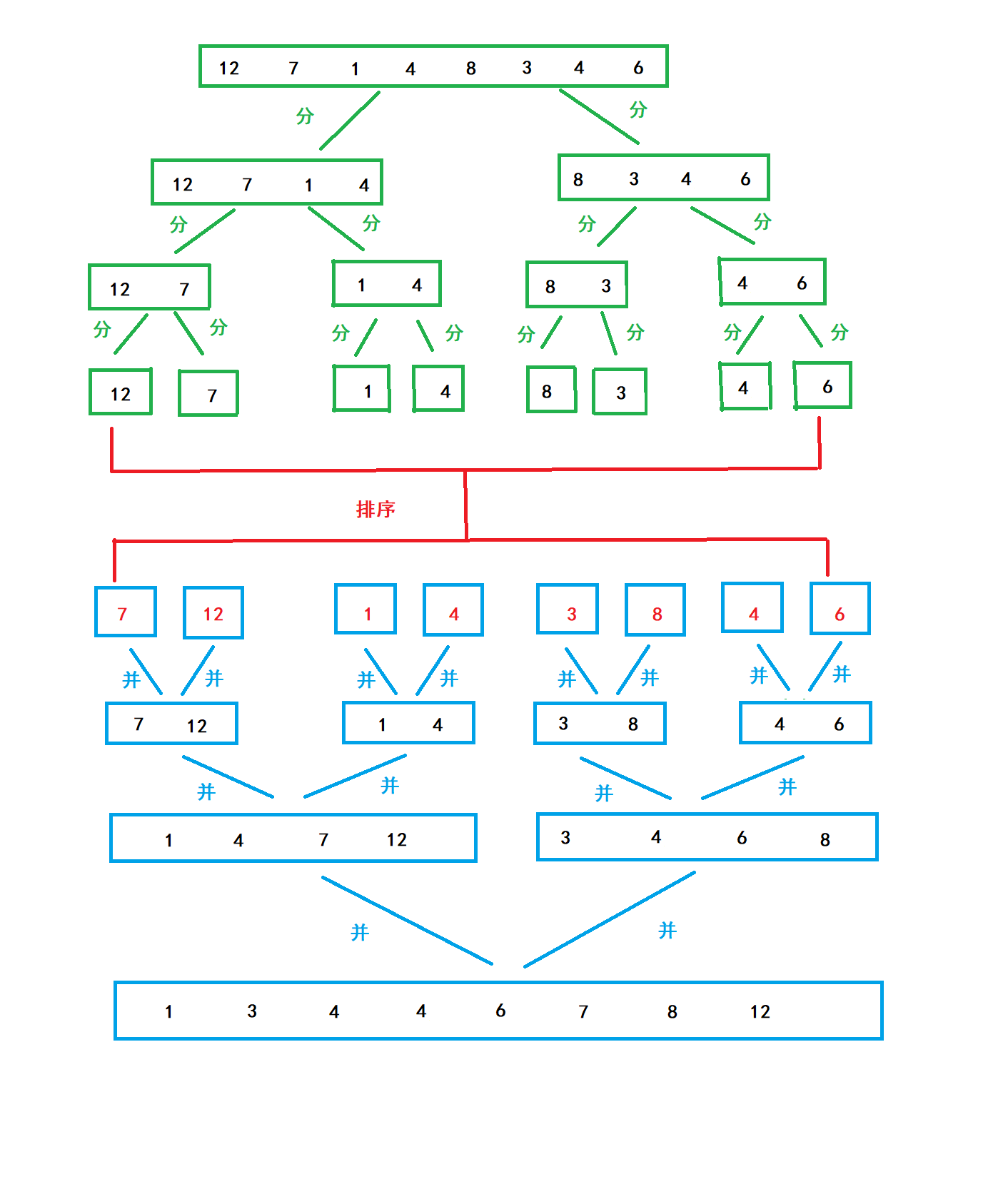
同樣也是遞回實作,
代碼:
void _MergeSort(int* a, int begin, int end, int* tmp)
{
if (begin >= end)
return;
int mid = (begin + end) >> 1;
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
int left1 = begin;
int left2 = mid + 1;
int i = begin;
//合并有序陣列
while (left1 <= mid && left2 <= end)
{
if (a[left1] < a[left2])
tmp[i++] = a[left1++];
else
tmp[i++] = a[left2++];
}
//處理剩余的元素
while (left1 <= mid)
{
tmp[i++] = a[left1++];
}
//處理剩余的元素
while (left2 <= end)
{
tmp[i++] = a[left2++];
}
//拷貝回原陣列
for (i = begin; i <= end; ++i)
{
a[i] = tmp[i];
}
}
void MergeSort(int* a, int size)
{
int* tmp = (int*)malloc(sizeof(int) * size);
if (tmp == NULL)
{
printf("malloc error\n");
exit(-1);
}
_MergeSort(a, 0, size - 1, tmp);
free(tmp);
}
非遞回實作
非遞回實作稍微復雜一點,因為有幾種特殊情況需要考慮,
思路:先對陣列兩兩一組排序,再四四一組排序,直到對整個陣列完成排序,因此我們要用到一個熟悉的變數gap來進行分組,
gap一開始為1,所以一開始是兩兩一組的元素進行排序,排好之后,gap翻倍進行兩兩一組的排序,依次類推,當gap大于陣列長度時就完成排序了
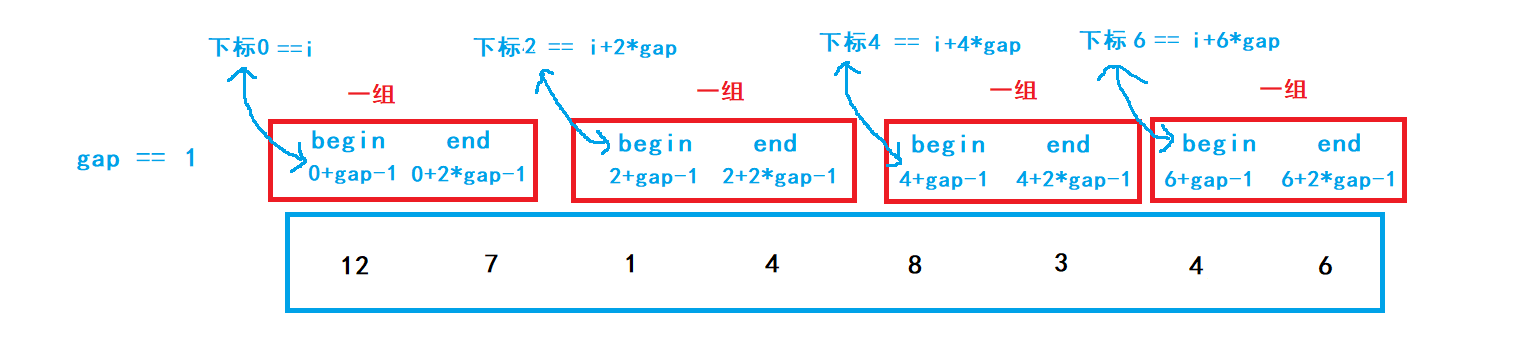
確認每一組的begin、end:
gap為1時:
gap為2時:
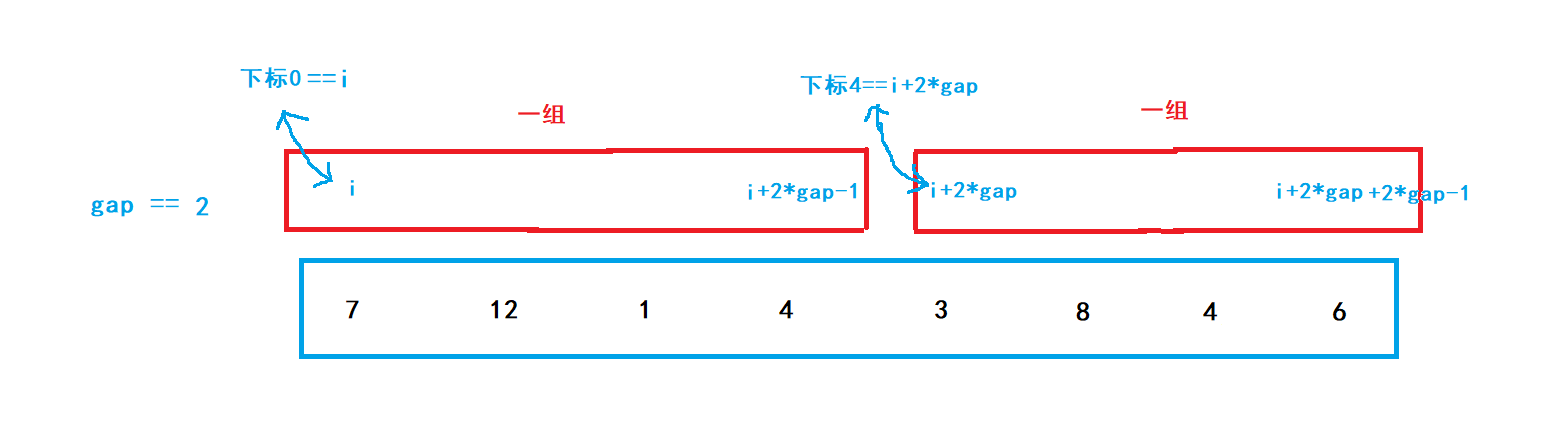
我們可以觀察到,每一個進行排序的組begin、end都與下標i有關,對下一組排序時需要將i加上2*gap,這樣就得到了新的begin,由此可以進行迭代排序,直到i大于陣列長度
大致思路我們知道了,但是還有三種特殊情況需要我們處理:
-
最后一組中,需要歸并的兩個區間中,第一個小區間存在,第二個不存在

-
最后一組中,需要歸并的兩個區間中,第一個小區間存在但不足gap個
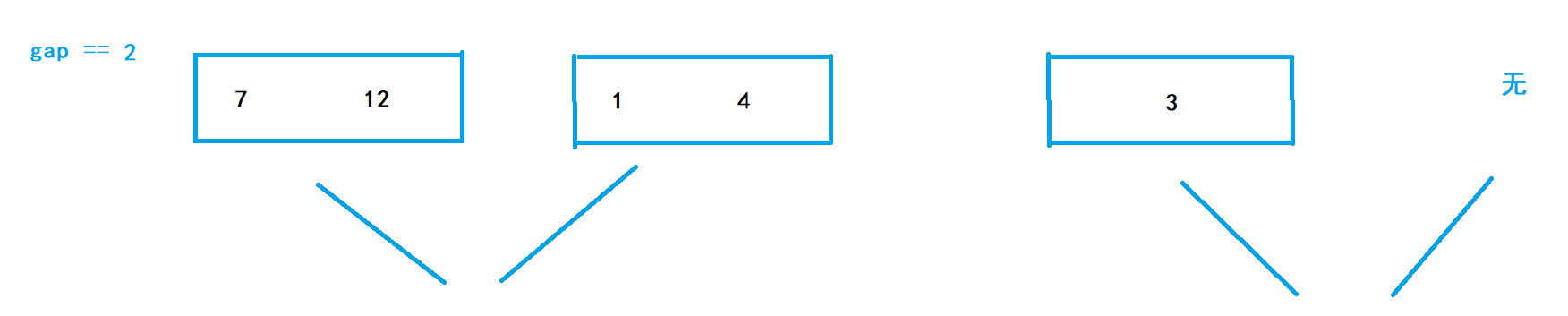
-
最后一組中,需要歸并的兩個區間中,第一個小區間存在,第二個存在但不足gap個

這三種情況會出現陣列越界訪問的情況,
情況1、2其實本質是一樣的,第一組已經有序了,可以直接停止歸并,
情況3則需要將第二組的end更新成size-1(size是陣列的長度),再進行歸并,
代碼:
//復用了遞回的一部分代碼
void _IterateMergeSort(int*a,int begin1,int end1, int begin2, int end2, int*tmp)
{
int left1 = begin1;
int left2 =begin2;
int i = begin1;
//合并有序陣列
while (left1 <= end1 && left2 <= end2)
{
if (a[left1] < a[left2])
tmp[i++] = a[left1++];
else
tmp[i++] = a[left2++];
}
//處理剩余的元素
while (left1 <= end1)
{
tmp[i++] = a[left1++];
}
//處理剩余的元素
while (left2 <= end2)
{
tmp[i++] = a[left2++];
}
//拷貝回原陣列
for (i = begin1; i <= end2; ++i)
{
a[i] = tmp[i];
}
}
void IterateMergeSort(int*a, int size)
{
int* tmp = (int*)malloc(sizeof(int) * size);
if (tmp == NULL)
{
printf("malloc error\n");
exit(-1);
}
int gap = 1;
while (gap < size)
{
for (int i = 0; i < size; i+=2*gap)
{
int begin1 = i;
int end1 = i + gap - 1;
int begin2 = i + gap;
int end2 = i + 2 * gap - 1;
if (begin2 >= size)//說明此時已經不需要歸并了,直接停止當前回圈
{
break;
}
if (end2 >= size)//更新end2
{
end2 = size - 1;
}
_IterateMergeSort(a, begin1, end1, begin2, end2, tmp);
}
gap *= 2;
}
free(tmp);
}
歸并排序的時間復雜度為O(N * logN)
內排序與外排序
內排序:指在排序期間資料物件全部存放在記憶體的排序,
外排序:指在排序期間全部物件太多,不能同時存放在記憶體中,必須根據排序程序的要求,不斷在內,外存間移動的排序,
根據排序元素所在位置的不同,排序分: 內排序和外排序 ,
歸并排序既屬于又屬于內排序又屬于外排序,
使用外排序的一道例題:
假設有10億個整數,放到檔案A中,但需要排好序,我們只能使用512M的記憶體,
思路:10億個整數的大小為4G,我們可以將這4G記憶體分成8份,也就是512M到記憶體中進行排序,注意,在記憶體中排序時不能用歸并排序,因為歸并還需要O(N)的空間,512M裝不下這么多資料,所以要使用其他不需要額外空間的排序,
先將512M資料排好序放到一個小檔案中,再在記憶體中進行下一個512M的排序,也存放在一個小檔案中,以此類推,需要創建8個小檔案,再用歸并排序將這8個小檔案合并,
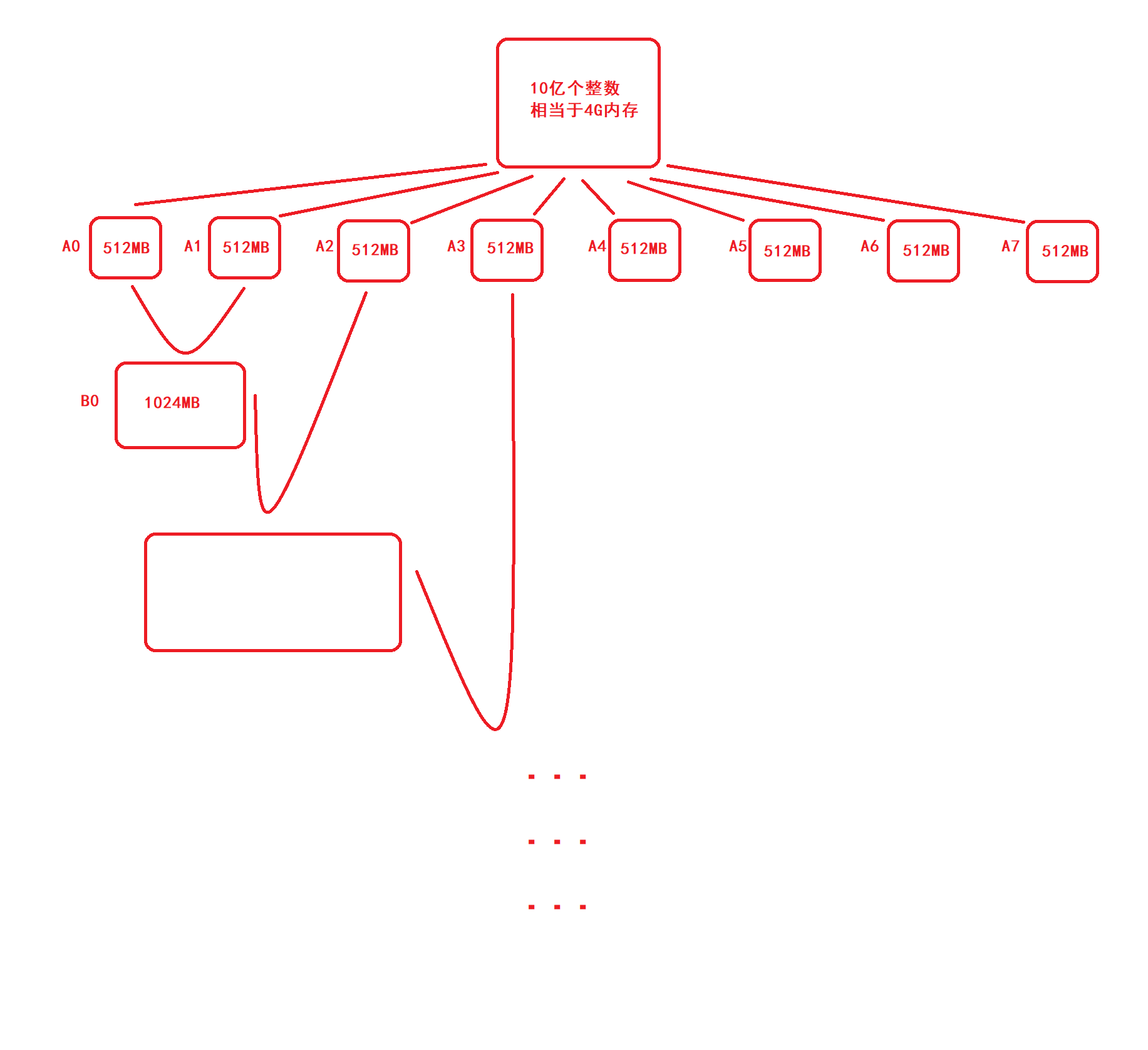
如上圖所示,最后歸并成一個4GB的檔案,放在檔案A中,
最后一種排序:
計數排序
計數排序的思想就是先遍歷一遍陣列,用另一個陣列count統計出每個數字出現的次數,統計方法為數字本身作為count的下標,然后對該元素的統計就存放在改下標對應的元素中,
隨后按照count的下標將這些數按個數輸出,就得到了一個有序數列,
如果原陣列的數字很大,使用陣列下標對應數字的絕對映射方法的話,我們需要開辟的空間也會變得很大,所以我們使用相對映射,
代碼:
//計數排序
void CountSort(int*a, int size)
{
int max = a[0];
int min = a[0];
for (int i = 0; i < size; ++i)
{
if (max < a[i])
max = a[i];
if (min > a[i])
min = a[i];
}
int range = max - min + 1;
int* count = (int*)calloc(range, sizeof(int));//要將count內的元素初始化為0
for (int i = 0; i < size; ++i)
{
//相對映射在count中對應的下標為a[i] - min
++count[a[i] - min];
}
int j = 0;
for (int i = 0; i < range; ++i)
{
while (count[i]--)//將每個元素列印出來
{
a[j++] = i + min;
}
}
}
時間復雜度O(N+range)
空間復雜度O(range)
計數排序適合一組范圍比較集中的資料,如果范圍集中,則效率很高,并且只適合整數,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301524.html
標籤:其他
下一篇:常見排序之近線性排序