深度強化學習是一種機器學習,其中智能體(Agent,也翻譯作代理)通過執行操作(Action)和查看結果(Reward)來學習如何在環境中采取最佳的動作或策略,
自 2013 年Deep Q-Learning 論文[1]以來,強化學習已經有了很多突破,從擊敗世界上最好 Dota2 玩家的[2]OpenAI到Dexterity [3],我們正處于深度強化學習研究的激動人心的時刻,
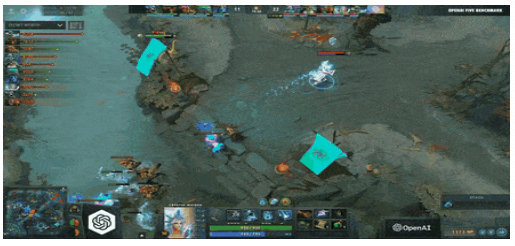
此外,由于很多開源庫(TF-智能體s, Stable-Baseline 2.0…)和仿真環境的公開:Mine強化學習 (Minecraft), Unity ML-智能體s, OpenAI retro (NES, SNES, Genesis games…),大家現在可以隨時使用仿真游戲環境來測驗自己的強化學習程式,
在本課程中,您將通過使用 Tensorflow 和 PyTorch 來訓練能玩太空入侵者、Minecraft、星際爭霸、刺猬索尼克等游戲的聰明的智能體,
在第一章中,您將學習到深度強化學習的基礎知識,在訓練深度強化學習智能體之前,掌握這些深度學習的基礎知識非常重要,讓我們開始吧!
一.什么是強化學習?
為了理解什么是強化學習,讓我們從強化學習的核心思想開始,
強化學習的核心思想是,智能體(AI)將通過與環境互動(通過反復試驗)并接收獎勵(負面或正面)作為執行動作的反饋來從環境中學習,
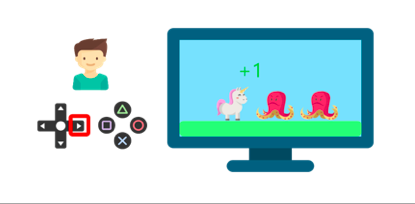
例如,想象一下你把你的弟弟放在一個他從未玩過的電子游戲面前,手里拿著一個控制器,讓他一個人呆著,

游戲場景
他通過按右鍵(動作)與環境(視頻游戲)互動,得到了一枚硬幣,這是+1的獎勵,也許在這場比賽中,他只是知道必須得到金幣,
當他碰到敵人時,獲得-1的懲罰,
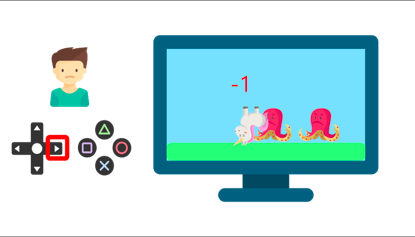
通過反復試驗與他的環境互動,你的弟弟才明白,在這個環境中,他需要獲得金幣,但要避開敵人,
在沒有任何監督的情況下,孩子會越來越擅長玩游戲,
這就是人類和動物通過互動學習的方式,強化學習就是一種從行動中學習的最優解的方法,
1、正式定義
我們現在給出強化學習的一個正式的定義:
強化學習是一種通過構建智能體來解決控制任務(也稱為決策問題)的框架,智能體通過與環境互動、反復試驗和領取獎勵來制定自己的策略,
但是強化學習是如何作業的呢?
二.強化學習框架
強化學習程序
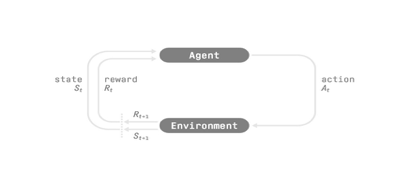
為了理解 強化學習 程序,讓我們想象一個智能體學習玩平臺游戲:
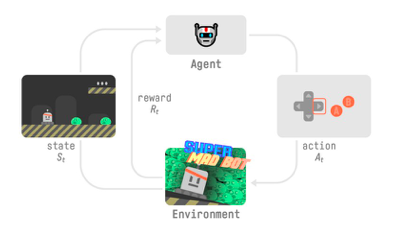
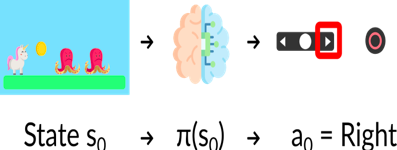
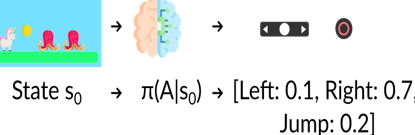
我們的智能體從環境接收狀態 S0——我們接收游戲的第一幀(環境),
基于狀態 S0,智能體采取行動 A0——我們的智能體將向右移動,
環境轉換到新狀態 S1 — 新框架,
環境給了智能體一些獎勵 R1——我們沒有死*(Positive Reward +1)*,
這個強化學習回圈輸出狀態、動作和獎勵以及下一個狀態的序列,
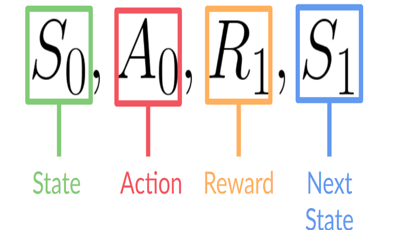
狀態、動作、獎勵、下一個狀態
2、預期回報
智能體的目標是最大化累積獎勵,稱為預期回報,為什么智能體的目標是最大化預期回報?
因為強化學習是基于獎勵假設,即所有目標都可以描述為預期回報(預期累積獎勵)的最大化,這就是為什么在強化學習中,為了獲得最佳行為,我們需要最大化預期累積獎勵,
3、觀察/狀態空間
觀察/狀態是我們的智能體從環境中獲得的資訊,在視頻游戲的情況下,它可以是一張截圖,在交易智能體的情況下,它可以是某只股票的價值等,
觀察和狀態之間有一個區別:
State s:是對環境狀態的完整描述(沒有隱藏資訊),在完全觀察的環境中,

對于國際象棋游戲,我們處于完全觀察的環境中,因為我們可以訪問整個棋盤資訊,
觀察 o:是狀態的部分描述,在部分觀察的環境中,

在《超級馬里奧兄弟》中,我們只能看到靠近玩家的關卡的一部分,因此我們收到了觀察結果,
在《超級馬里奧兄弟》中,我們只是處于一個部分觀察的環境中,我們收到了一個觀察結果,因為我們只看到了關卡的一部分,
4、行動空間
動作空間是環境中所有可能動作的集合,動作可以來自離散或連續空間:
離散空間:可能動作的數量是有限的,

在《超級馬里奧兄弟》中,我們有一組有限的動作,因為我們只有 4 個方向和跳躍,
連續空間:可能的動作數量是無限的,
自動駕駛汽車智能體有無數種可能的動作,因為他可以左轉 20°、21°、22°、鳴喇叭、右轉 20°、20,1°……

考慮這些資訊是至關重要的,因為它在我們將來選擇強化學習 演算法時很重要,
5、獎勵和折扣因子
獎勵是強化學習的基礎,因為它是智能體和環境互動后的唯一反饋,有了它,我們的智能體才知道所采取的行動是否足夠好,
每個時間步長 t 的累積獎勵可以寫成:
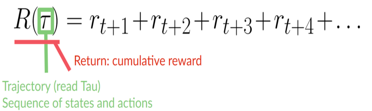
等式還可以寫成:
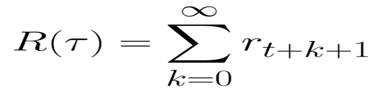
但實際上,我們不能就這樣簡單累加獎勵,在游戲開始時出現的獎勵更有可能發生,因為它們比未來的獎勵更可預測,
假設您的智能體是這只小老鼠,它可以在每個時間步移動一步,而您的對手是貓(它也可以移動),你的目標是在被貓吃掉之前吃掉最大量的奶酪,
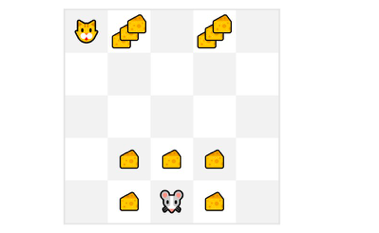
因此,靠近貓的獎勵,即使它更大(更多的奶酪),該獎勵的風險也會更大,因為我們不確定我們能否吃到它,為了計算這部分獎勵,我們定義了折扣獎勵,
為了計算折扣獎勵,我們是這樣進行的:
1、定義一個稱為 的γ 的折扣銀子,它必須介于 0 和 1 之間,
γ越大,折扣越小,這意味著我們的智能體更關心長期獎勵,另一方面,γ越小,折扣越大,這意味著我們的智能體更關心短期獎勵(最近的奶酪),
2、每個獎勵將通過 γ 折現為時間步長的指數
隨著時間步長的增加,貓離我們越來越近,所以未來的獎勵發生的可能性越來越小,
我們的折扣累積預期獎勵是:
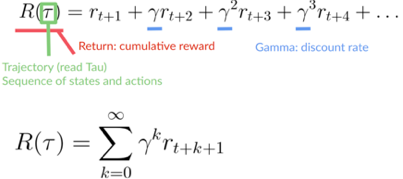
折扣累積預期獎勵
6、任務型別
任務是強化學習問題的一個實體,我們可以有兩種型別的任務:離散的和連續的,
離散任務,在這種情況下,我們有一個起點和一個終點(終止狀態),這將創建一個序列:狀態、操作、獎勵和新狀態,
例如,在《超級馬里奧兄弟》游戲中,這個序列從新馬里奧關卡開始,并馬里奧被殺或到達關卡終點時結束,

連續任務,這些是永遠持續的任務(沒有終止狀態),在這種情況下,智能體必須學習如何選擇最佳動作并隨時與環境互動,
例如,進行自動股票交易的智能體,對于這個任務,沒有起點和終點,智能體一直運行,直到我們決定關閉它,
7、探索/利用權衡
最后,在研究強化學習解決問題的不同方法之前,我們必須討論一個非常重要的點:探索/利用,
探索是通過嘗試隨機動作來探索環境,以找到有關環境的更多資訊,利用是根據已知的資訊來最大化獎勵,
我們強化學習智能體的目標是最大化預期累積獎勵,然而,我們可能會陷入一個陷阱,

在這個游戲中,我們的老鼠可以擁有無限量的小奶酪(每個+1),但是在迷宮的頂部,有一堆大奶酪(+1000),
如果我們只專注于利用,我們的智能體永遠到不了大奶酪那里(探索),它只會獲取最近的獎勵,即使這個獎勵很小(利用),
但是如果我們的智能體做一點探索,它可以發現更大的獎勵(一堆大奶酪),
這就是我們所說的探索/利用的權衡,我們需要平衡對環境的探索程度和對環境的了解程度,
因此,我們必須定義一個規則來處理這種情況,我們將在以后的章節中看到不同的處理方式,如果這個問題令人困惑,請考慮一個真正的問題:餐廳的選擇,
利用:每天都去同一家您認為不錯的餐廳,并冒著錯過另一家更好餐廳的風險,
探索:嘗試以前從未去過的餐廳,冒著體驗不好的風險,但可能有機會獲得美妙的體驗,
三、解決強化學習問題的兩種主要方法
既然我們學習了強化學習框架,那么我們如何解決強化學習問題呢?換句話說,如何構建一個可以選擇最大化其預期累積獎勵的動作的強化學習智能體?
1、策略π:智能體的大腦
策略π是我們智能體的大腦,它是告訴我們在給定狀態下要采取什么行動的函式,所以它定義了在給定一段時間內的智能體行為,
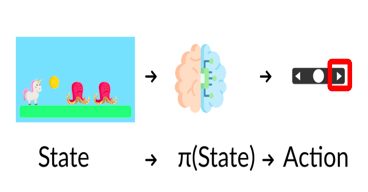
狀態、策略、動作
將策略視為我們智能體的大腦,該功能將告訴我們在給定狀態下采取的行動,這個策略π就是我們要學習的函式,我們的目標是找到最優策略π*,當智能體按照它行動時,是期望收益最大化的策略,我們通過訓練找到了這個π*,
有兩種方法可以訓練我們的智能體來找到這個最優策略π*:
直接地,基于策略的方法:通過教智能體學習在給定狀態下要采取的行動,
間接地,基于價值的方法:教智能體了解哪個狀態更有價值,然后采取會出現更有價值狀態的行動,
2、基于策略的方法
在基于策略的方法中,我們直接學習策略函式,該函式將從每個狀態映射到該狀態的最佳對應動作,或者該狀態下一組可能動作的概率分布,
正如我們在這里看到的,策略(確定性的)直接指示每一步要采取的行動,
我們有兩種型別的策略:
確定地:在給定狀態下該策略將始侄訓傳相同的操作,
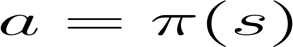
給定狀態下輸出動作
隨機地:在給定狀態下該該策略輸出動作的概率分布,

給定一個初始狀態,隨機策略將輸出該狀態下可能動作的概率分布
3、基于價值的方法
在基于價值的方法中,我們不是訓練策略函式,而是訓練一個將狀態映射到處于該狀態的預期值的值函式,
一個狀態的價值是如果智能體從該狀態開始,根據我們的策略采取行動,它可以獲得的最大的折扣累積預期獎勵,
“按照我們的策略行事”意味著我們的策略是“走向價值最高的”,
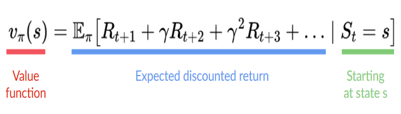
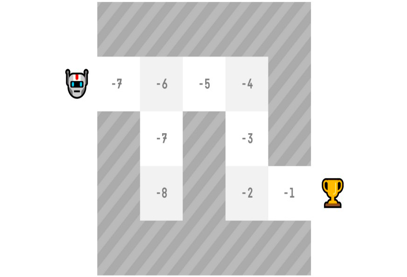
有了我們的價值函式,在每一步,我們的策略都會選擇價值函式定義的具有最大價值的狀態:-7,然后是-6,然后是-5(等等)來實作目標,
四、強化學習的“深度”
談到了強化學習,但我們為什么要談論深度強化學習?深度強化學習引入了深度神經網路來解決強化學習問題——因此得名“深度”,
例如,在下一篇文章中,我們將研究 Q-Learning(經典強化學習)和 Deep Q-Learning,兩者都是基于價值的強化學習演算法,
您會看到不同之處在于,在第一種方法中,我們使用傳統演算法來創建 Q 表,以幫助我們找到對每個狀態要采取的操作,
在第二種方法中,我們將使用神經網路(來近似 q 值),

Q-Learning和 Deep Q-Learning
五、總結
我們總結一下今天學到的知識:
強化學習是一種從行動中學習的計算方法,我們構建了一個智能體,它通過反復試驗與環境互動并接收獎勵(負面或正面)作為反饋,從環境中學習到動作的好壞,
任何強化學習智能體的目標都是最大化其預期累積獎勵(也稱為預期回報),因為強化學習基于獎勵假設,所有目標都可以描述為預期累積獎勵的最大化,
強化學習程序是一個回圈,可以定義為:狀態、動作、獎勵和下一個狀態的序列,
為了計算預期累積獎勵(預期回報),我們對獎勵打折:較早(在游戲開始時)出現的獎勵更有可能發生,因為它們比長期未來獎勵更可預測,
要解決強化學習問題,需要找到最佳策略,策略是智能體的“大腦”,它會告訴我們在給定狀態下要采取什么行動,最佳的一種策略能提供最大化預期回報的行動,
有兩種方法可以找到最佳策略:
通過直接訓練的策略:基于策略的方法,
通過訓練一個價值函式,告訴我們智能體在每個狀態下將獲得的預期回報,并使用這個函式來定義我們的策略:基于價值的方法,
最后,我們談論深度強化學習,因為我們引入了深度神經網路來估計要采取的動作(基于策略)或估計狀態的值(基于值),因此稱為“深度”,
參考資料
[1]Deep Q-Learning 論文:
https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
[2]擊敗世界上最好 Dota2 玩家的:
https://www.twitch.tv/videos/293517383
[3]Dexterity :
https://openai.com/blog/learning-dexterity/
[4]打敗了世界上最好的 Dota2 玩家:
https://www.twitch.tv/videos/293517383
原文鏈接:
https://thomassimonini.medium.com/an-introduction-to-deep-reinforcement-learning-17a565999c0c
- EOF -

往期精彩回顧
適合初學者入門人工智能的路線及資料下載機器學習及深度學習筆記等資料列印機器學習在線手冊深度學習筆記專輯《統計學習方法》的代碼復現專輯
AI基礎下載機器學習的數學基礎專輯黃海廣老師《機器學習課程》視頻課本站qq群851320808,加入微信群請掃碼:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301611.html
標籤:其他
上一篇:貪吃蛇小游戲完整代碼塊