第七章 超越統計調整:征服干預之峰
CHAPTER 7 — Beyond Adjustment: The Conquest of Mount Intervention
- 因果之梯的第二層:對未嘗試過的行動和策略的效果進行預測,混雜因子是導致我們預測混淆的主要障礙,在用“路徑阻斷”工具和后門標準消除這一障礙后,就能精確而系統地繪制出登上干預之峰地路線圖,(路徑阻斷工具是d-separation)(195)
- do演算允許研究者探索并繪制出通往干預之峰的所有可能的路線,(195)
最簡單的路線:后門調整公式
-
最常用的預測干預效果的方法是使用統計調整公式“控制”混雜因子,如果確定已經掌握了變數的一個充分集(去混因子)的資料就可以用來阻斷干預和結果之間的所有后門路徑,就可以使用此方法,為了做到這一點,需要首先估計去混因子在每個“水平”或資料分層中產生的效應,并據此測算出干預的平均因果效應,然后需要計算這些層的因果效應的加權平均值,為此需要對每個層都按期在總體中的分布頻率進行加權,(195-196)
-
后門準則在估算平均因果效應的程序中所起的作用是,保證去混因子在各層中的因果效應與我們在這一層觀察到的趨勢相一致,據此可以從資料中逐層估計出因果效應,若沒有后門準則,研究者就無法保證所有的統計調整都是合理的,(196)
-
當有多個混雜因子和多個資料分層時,就很難將所有的可能性都羅列出來,一個補救辦法是將數值分成有限并且數目可控的類別,但是這種分類方式的選擇上可能存在主觀性,如果需要進行統計調整的變數比較多,那么類別的數量就會呈指數增長,這將使計算程序變得難以執行,更糟糕的是,在分類完成后,很可能會發現許多層缺乏樣本,因此無法對其進行任何概率估計,為應對“維度災難”問題,設計了資料外推法,即通過一個與資料擬合的光滑函式來填充空的層所形成的洞,運用最為廣泛的光滑函式是線性近似,使用時每個因果效應都可以用一個數字(因果系數)來表示,并且根據統計調整公式進行計算的程序非常簡單,(197)
-
無論是否經過統計調整,回歸系數只表示一種統計趨勢,其自身并不能傳遞因果資訊,(198)
回歸系數有時可以體現因果效應,有時則無法體現,而其中的差異無法僅依靠資料來說明,還需要具備另外兩個條件才能賦予偏回歸系數rYXZ 以因果合法性:
? (1)所繪制的相應的因果圖能夠合理地解釋現實情況;
? (2)需要據其進行統計調整的變數Z應該滿足后門準則,(198)
-
基于回歸的統計調整只適用于線性模型:
(1)一旦使用了線性模型,就失去了為非線性的相互作用建模的能力;(2)即使不知道圖中箭頭背后的函式是什么,后門調整仍有效,(199)
-
后門準則和后門調整公式的關系:
后門準則用于判定哪些變數集可以用來去除資料中的混雜;
后門調整公式所做的實際上就是去混雜,(199)
-
如果因缺乏必要的資料而無法阻斷某條后臺路徑,統計調整公式就會完全失靈,(199)
前門準則
-
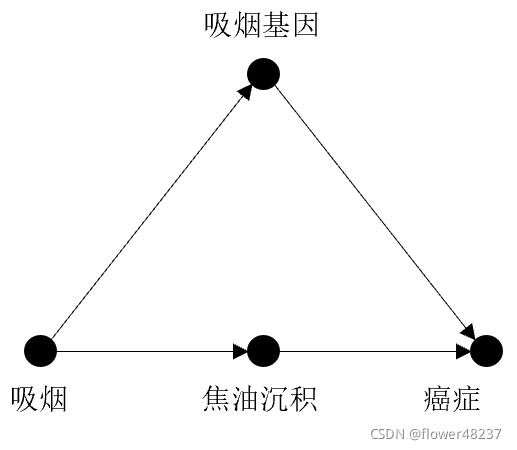
由于缺乏混雜因子的資料,不能阻斷“吸煙 <— 混雜因子 —> 癌癥”的后門路徑,因此不能使用后門調整來控制混雜因子的影響,(200)
前門指的是直接的因果路徑“吸煙 —> 焦油沉積 —> 癌癥”,(201)
-
可以用純數學的方式在不引入do算子本身(不進行實際干預)的情況下算出概率結果,(202)
-
在不引入do算子的前提下表示 P(癌癥 | do (吸煙)) 就被稱作前門調整(202)
-
依據上圖,設X代表吸煙,Y代表癌癥,Z代表焦油沉積,U代表不可觀測的變數(未出現在公式中),公式如下
-
前門調整公式:
? P(Y|do(X)) = Σz P(Z=z,X)Σx P(Y|X=x,Z=z)P(X=x)
-
后門調整公式:
? P(Y|do(X)) = Σz P(Y|X,Z=z)P(Z=z)
-
從前門公式中可知:
(1)在公式的任何地方都看不到U,這是整個問題的關鍵;
(2)將被估量視為一種針對問題中的目標量的計算方法,
-
-
因果圖的一個主要優勢就算讓假設變得透明,以供專家和決策者探討和辯論,(203)
-
在假設正確的情況下,即使沒有混雜因子的資料,仍然可以用數學方式消除混雜因子的影響,(203)
-
前門調整是一個強大的工具,因為:
它允許我們控制混雜因子,并且這些混雜因子可以是我們無法觀測(如“動機”)甚至無法命名的,也正是因為同樣的原因,隨機對照試驗被認為是估計因果效應的黃金標準,(206)
do演算,或者心勝于物
-
前門調整公式和后門調整公式的最終目標是根據P(Y|X,A,B,Z,……)此類不涉及do算子的資料估算干預的效果,即P(Y|do(X)),
如果可以成功消除計算程序中的do概率,就可以利用觀測資料來估計因果效應,就可以從因果關系之梯的第一層踏上第二層,(206)
-
三條合法的do運算式變換?:(209)
-
規則1:如果我們觀察到變數W和Y無關(其前提可能是以其他變數Z為條件),那么Y的概率分布就不會隨W而改變,等式成立的條件是,在洗掉了指向X的所有箭頭之后,變數集Z會阻斷所有從W到Y的路徑,
句法解釋:允許增加或洗掉某個觀察結果,
P(Y|do(X), Z, W) = P(Y|do(X),Z)
-
規則2:如果變數Z阻斷了X到Y的的所有后門路徑,那么以Z為條件(對Z進行變數控制),則do(X)等同于see(X),即在控制了一個充分的去混因子之后,留下的相關性就是真正的因果效應,
句法解釋:允許用觀察替換干預,
P(Y|do(X),Z) = P(Y|X,Z)
-
規則3:如果沒有從X到Y的因果路徑,就可以將do(X)和從P(Y|do(X))中移除,即如果我們實施的干預行動(do)不會影響Y,那么Y的概率分布就不會改變,
句法解釋:允許洗掉或添加干預,
P(Y|do(X)) = P(Y)
-
-
有了上述三條規則,就可以推匯出前門調整公式,這是一個不以控制混雜因子為手段來估計因果效應的方法,(210)
-
如果我們在規則1到3中找不到根據資料估計P(Y|do(X))的方法,那么對于這個問題,解決方案就是不存在的,
在此情況下,除了進行隨機對照試驗別無選擇,這三條規則還能告訴我們,對于某個特定的問題,什么樣的額外假設或實驗可以使因果效應從不可估計變為可估計,(212)
-
伊利亞·斯皮塞=>發現可以用于確定某個解決方案是否存在“多項式時間”的演算法,(213)
案例:斯諾醫生的離奇案例
-
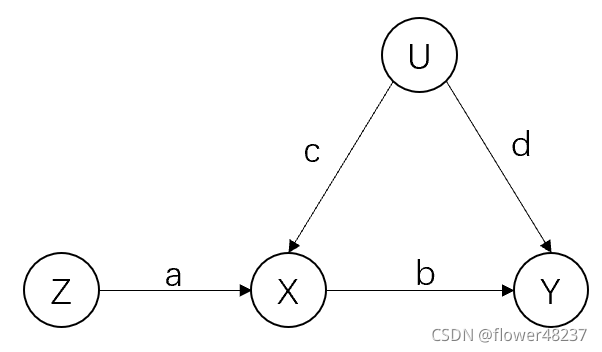
工具變數(222)如圖,Z就是一個工具變數:
(1)Z和U之間沒有箭頭(二者獨立)
(2)Z和X之間有一個箭頭
(3)Z和Y之間沒有直接箭頭
-
工具變數允許我們執行與前門調整相同的處理:在無法控制混雜因子或收集其資料的情況下估計X對Y的效應,(223)
-
路徑圖所體現的假設在本質上是因果關系,(223)
好膽固醇與壞膽固醇
-
“未履行問題”,如受試者雖然隨機地接受了藥物安排,但實際上并沒有復用被分配的藥物,(226)
-
當變數都是二元變數,而不是數值變數時,意味著不能使用線性模型,因此工具變數公式也不適用,在這種情況下,通常可以使用被稱為“單調性”的弱相關來代替線性假設,但在這么做之前,需要先確保工具變數的三個假設都是有效的(226-227):
(1)工具變數Z獨立于混雜因子
(2)Z到Y無直接路徑
(3)Z和X之間存在強關聯
-
取最好和最壞情況的做法通常會得到一個估計結果的取值范圍,(228)
-
在做任何干預研究之前,都要看我們實際操作的變數(如低密度脂蛋白的終生水平)是否與我們認為自己正在操作的變數(如低密度脂蛋白的當前水平)相同,
工具變數是一個重要的工具,他能我們幫助我們揭示do演算無法解釋的因果資訊,do演算強調的是點估計,而非不等式,
相比工具變數,do演算具有更強大的靈活性,因為在do演算中,我們不需要對因果模型中函式的性質做任何假設,而如果我們的確有足夠的科學依據證實類似單調性或線性這樣的假設的話,那么像工具變數這種針對性更強的工具就更值得考慮,(230-231)
《THE BOOK OF WHY: THE NEW SCIENCE OF CAUSE AND EFFECT》
——JUDEA PEARL AND DANA MACKENZIE
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301700.html
標籤:其他