| 一起重新開始學大資料-Hbase篇-day 57 Hbase調優 |

💚文章目錄💛
- 1、預磁區
- 2、Rowkey設計
- ①設計原則
- ②熱點問題
- 3、In memory
- 4、Max Version
- 5、Compact&split
- 6、BulkLoading
- ①代碼
- ②說明
1、預磁區
Pre-Creating Regions(預磁區) 概述:
??默認情況下,在創建HBase表的時候會自動創建一個region磁區,當匯入資料的時候, 所有的HBase客戶端都向這一個region寫資料,直到這個region足夠大了才進行切分, 但這樣的情況,會導致如果資料量過大導致寫入速度過慢,所以可以使用一種可以加快批量寫入速度的方法是通過預先創建一些空的regions,這樣當資料寫入 HBase時,會按照region磁區情況,在集群內做資料的負載均衡,
??如果知道hbase資料表的key的分布情況,就可以在建表的時候對hbase進行region的預磁區,這樣做的好處是防止大資料量插入的熱點問題,提高資料插入的效率,
?
?
執行步驟:
①理解磁區方式并且生成磁區檔案
??首先就是要想明白資料的key是如何分布的,然后規劃一下要分成多少region,每個region的startkey和endkey是多少,然后將規劃的key寫到一個檔案中,比如,key的前幾位字串都是從0001~0010的數字,這樣可以分成10個region,劃分key的檔案如下:
??0001|
??0002|
??0003|
??0004|
??0005|
??0006|
??0007|
??0008|
??0009|
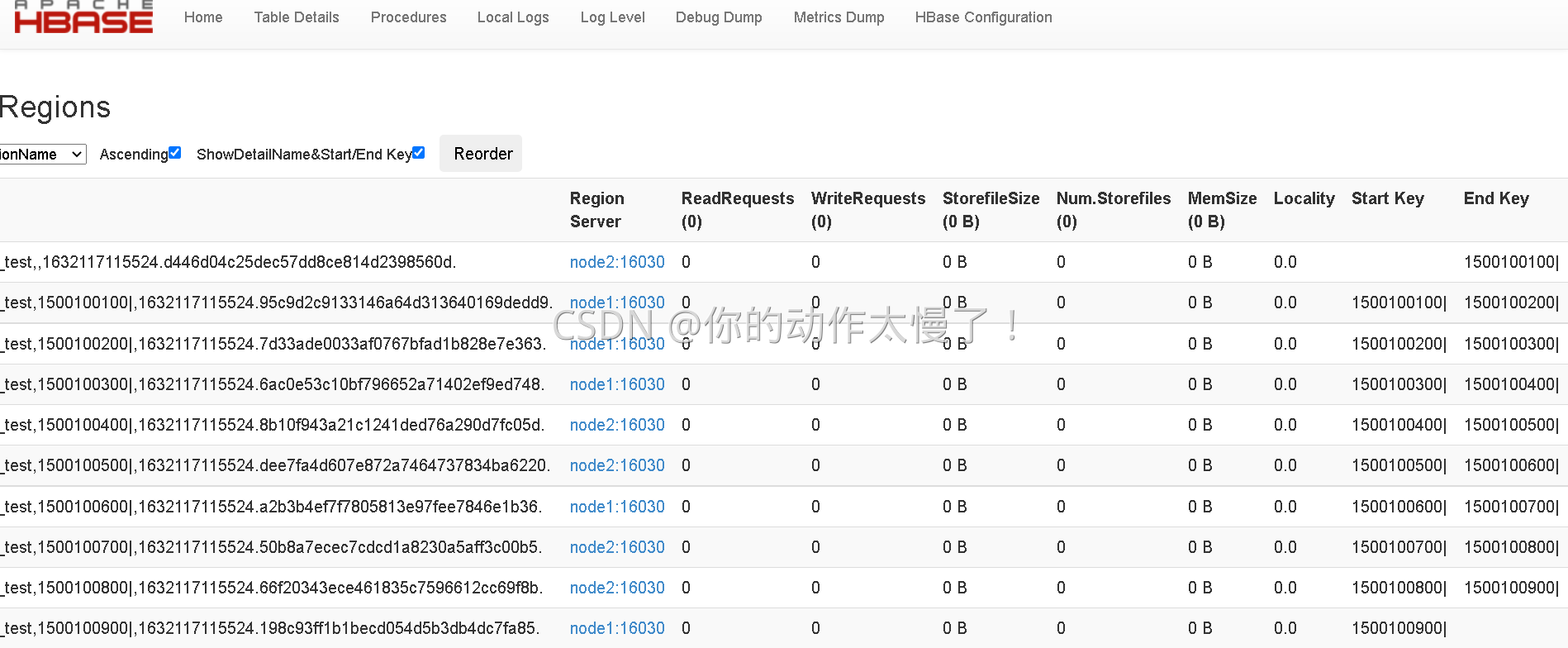
??為什么后面會跟著一個"|",是因為在ASCII碼中,"|"的值是124,大于所有的數字和字母等符號,當然也可以用“~”(ASCII-126),分隔檔案的第一行為第一個region的stopkey,每行依次類推,最后一行不僅是倒數第二個region的stopkey,同時也是最后一個region的startkey,也就是說磁區檔案中填的都是key取值范圍的分隔點,如下圖磁區檔案所示(第一行為第一個region的stopkey,也就是說小于1500100100的都放在第一個磁區,大于等于1500100100的以及小于1500100200的放在第二個磁區):
在本地創建一個磁區檔案
vim region_split_info.txt
輸入以下內容:

②base shell中建磁區表,指定磁區檔案
可以通過指定SPLITS_FILE的值指定磁區檔案,如果磁區資訊比較少,也可以直接用SPLITS磁區,我們可以通過如下命令建一個磁區表,指定第一步中生成的磁區檔案:
create 'split_table_test', 'cf', {SPLITS_FILE => '/usr/local/soft/data/region_split_info.txt'}
下面,我們登陸一下master的web頁面Hmaster:60010,查看一下hbase的表資訊,找到剛剛新建的預磁區表,進入查看region資訊:
2、Rowkey設計
①設計原則
HBase中row key用來檢索表中的記錄,支持以下三種方式:
-
通過單個row key訪問:即按照某個row key鍵值進行get操作;
-
通過row key的range進行scan:即通過設定startRowKey和endRowKey,在這個范圍內進行掃描;
-
全表掃描:即直接掃描整張表中所有行記錄,
??在HBase中,row key可以是任意字串,最大長度64KB,實際應用中一般為 10~100bytes,存為byte[]位元組陣列,一般設計成定長的,
??row key是按照字典序存盤,因此,設計row key時,要充分利用這個排序特點,將經常一起讀取的資料存盤到一塊,將最近可能會被訪問的資料放在一塊,
??HBase是三維有序存盤的,通過rowkey(行鍵),column key(column family和qualifier)和TimeStamp(時間戳)這個三個維度可以對HBase中的資料進行快速定位,
rowkey長度原則
??rowkey是一個二進制碼流,可以是任意字串,最大長度 64kb ,實際應用中一般為10-100bytes,以 byte[] 形式保存,一般設計成定長,
建議越短越好,不要超過16個位元組,原因如下:
??資料的持久化檔案HFile中是按照KeyValue存盤的,如果rowkey過長,比如超過100位元組,1000w行資料,光rowkey就要占用100*1000w=10億個位元組,將近1G資料,這樣會極大影響HFile的存盤效率;
??MemStore將快取部分資料到記憶體,如果rowkey欄位過長,記憶體的有效利用率就會降低,系統不能快取更多的資料,這樣會降低檢索效率,
rowkey散列原則
??如果rowkey按照時間戳的方式遞增,不要將時間放在二進制碼的前面,建議將rowkey的高位作為散列欄位,由程式隨機生成,低位放時間欄位,這樣將提高資料均衡分布在每個RegionServer,以實作負載均衡的幾率,如果沒有散列欄位,首欄位直接是時間資訊,所有的資料都會集中在一個RegionServer上,這樣在資料檢索的時候負載會集中在個別的RegionServer上,造成熱點問題,會降低查詢效率,
rowkey唯一原則
??必須在設計上保證其唯一性,rowkey是按照字典順序排序存盤的,因此,設計rowkey的時候,要充分利用這個排序的特點,將經常讀取的資料存盤到一塊,將最近可能會被訪問的資料放到一塊,
②熱點問題
??HBase中的行是按照rowkey的字典順序排序的,這種設計優化了scan操作,可以將相關的行以及會被一起讀取的行存取在臨近位置,便于scan,然而糟糕的rowkey設計是熱點的源頭, 熱點發生在大量的client直接訪問集群的一個或極少數個節點(訪問可能是讀,寫或者其他操作),大量訪問會使熱點region所在的單個機器超出自身承受能力,引起性能下降甚至region不可用,這也會影響同一個RegionServer上的其他region,由于主機無法服務其他region的請求, 設計良好的資料訪問模式以使集群被充分,均衡的利用,
??為了避免寫熱點,設計rowkey會使得不同行在同一個region,但是在更多資料情況下,資料應該被寫入集群的多個region,而不是一個,
下面是一些常見的避免熱點的方法以及它們的優缺點(附帶案例說明):
加鹽
??這里所說的加鹽不是密碼學中的加鹽,而是在rowkey的前面增加亂數,具體就是給rowkey分配一個隨機前綴以使得它和之前的rowkey的開頭不同,分配的前綴種類數量應該和你想使用資料分散到不同的region的數量一致,加鹽之后的rowkey就會根據隨機生成的前綴分散到各個region上,以避免熱點,
#資料
20210918_10001
20210919_10001
20210920_10001
# 加鹽
1679592560_20210918_10001
665840881_20210919_10001
374714006_20210920_10001
哈希
??哈希會使同一行永遠用一個前綴加鹽,哈希也可以使負載分散到整個集群,但是讀卻是可以預測的,使用確定的哈希可以讓客戶端重構完整的rowkey,可以使用get操作準確獲取某一個行資料
#資料
20210918_10001
20210919_10001
20210920_10001
# 哈希
37410b3a3a683b1dbeaf165b750bf7ed_20210918_10001
9b58fa08284d1a30c386e17aa7cffc35_20210919_10001
fb1c5c2fb7add4d693181e69ed78228d_20210920_10001
反轉
??第三種防止熱點的方法時反轉固定長度或者數字格式的rowkey,這樣可以使得rowkey中經常改變的部分(最沒有意義的部分)放在前面,這樣可以有效的隨機rowkey,但是犧牲了rowkey的有序性,
??反轉rowkey的例子以手機號為rowkey,可以將手機號反轉后的字串作為rowkey,這樣的就避免了以手機號那樣比較固定開頭導致熱點問題
#資料:
183XXXX5028
188XXXX5027
139XXXX1245
#反轉
8205XXXX381
7205XXXX881
5421XXXX931
時間戳反轉
??一個常見的資料處理問題是快速獲取資料的最近版本,使用反轉的時間戳作為rowkey的一部分對這個問題十分有用,可以用 Long.Max_Value - timestamp 追加到key的末尾,例如[key][reverse_timestamp] , [key] 的最新值可以通過scan [key]獲得[key]的第一條記錄,因為HBase中rowkey是有序的,第一條記錄是最后錄入的資料,
??比如需要保存一個用戶的操作記錄,按照操作時間倒序排序,在設計rowkey的時候,可以這樣設計
# 資料 = > 時間戳反轉
000001_1631929041 => 000001_9223372035222846766
000001_1631929341 => 000001_9223372035222846466
000001_1631929641 => 000001_9223372035222846166
000001_1631929941 => 000001_9223372035222845866
000001_1631930441 => 000001_9223372035222845366
3、In memory
??創建表的時候,可以通過HColumnDescriptor.setInMemory(true)將表放到 RegionServer的快取中,保證在讀取的時候被cache命中,(針對列簇)
??在Hbase shell中通過desc 查看表,可以看到是否開啟

4、Max Version
??創建表的時候,可以通過HColumnDescriptor.setMaxVersions(int maxVersions)設定 表中資料的最大版本,如果只需要保存最新版本的資料,那么可以設定 setMaxVersions(1),
?
5、Compact&split
??在HBase中,資料在更新時首先寫入WAL 日志(HLog)和記憶體(MemStore)中, MemStore中的資料是排序的,當MemStore累計到一定閾值(128M)時,由單獨的執行緒flush到磁盤上,成為一個StoreFile,與此同時, 系統會在zookeeper中記錄一個redo point,表示這個時刻之前的變更已經持久化了
??StoreFile是只讀的,一旦創建后就不可以再修改,因此Hbase的更新其實是不斷追加的操作,當一個Store中的StoreFile的數量達到一定的閾值后,就會進行一次合并(major compact),將對同一個key的修改合并到一起,形成一個大的StoreFile;當StoreFile的大小達到一定閾值后,又會對 StoreFile進行分割(split),等分為兩個StoreFile,
?
?
6、BulkLoading
優點:
-
如果我們一次性入庫hbase巨量資料,處理速度慢不說,還特別占用Region資源, 一個比較高效便捷的方法就是使用 “Bulk Loading”方法,即HBase提供的HFileOutputFormat類,
-
它是利用hbase的資料資訊按照特定格式存盤在hdfs內這一原理,直接生成這種hdfs記憶體儲的資料格式檔案,然后上傳至合適位置,即完成巨量資料快速入庫的辦法,配合mapreduce完成,高效便捷,而且不占用region資源,增添負載,
限制:
-
僅適合初次資料匯入,即表內資料為空,或者每次入庫表內都無資料的情況,
-
HBase集群與Hadoop集群為同一集群,即HBase所基于的HDFS為生成HFile的MR的集群
①代碼
- 生成HFile部分
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.RegionLocator;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.mapreduce.KeyValueSortReducer;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
import org.apache.hadoop.hbase.mapreduce.SimpleTotalOrderPartitioner;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class BulkLoading {
public static class BulkLoadingMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, KeyValue> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] splits = value.toString().split(",");
String mdn = splits[0];
String start_time = splits[1];
// 經度
String longitude = splits[4];
// 維度
String latitude = splits[5];
String rowkey = mdn + "_" + start_time;
KeyValue lg = new KeyValue(rowkey.getBytes(), "info".getBytes(), "lg".getBytes(), longitude.getBytes());
KeyValue lt = new KeyValue(rowkey.getBytes(), "info".getBytes(), "lt".getBytes(), latitude.getBytes());
context.write(new ImmutableBytesWritable(rowkey.getBytes()), lg);
context.write(new ImmutableBytesWritable(rowkey.getBytes()), lt);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
// 創建Job實體
Job job = Job.getInstance(conf);
job.setJarByClass(BulkLoading.class);
job.setJobName("BulkLoading");
// 保證全域有序
job.setPartitionerClass(SimpleTotalOrderPartitioner.class);
// 設定reduce個數
job.setNumReduceTasks(4);
// 配置map任務
job.setMapperClass(BulkLoadingMapper.class);
// 配置reduce任務
// KeyValueSortReducer 保證在每個Reduce有序
job.setReducerClass(KeyValueSortReducer.class);
// 輸入輸出路徑
FileInputFormat.addInputPath(job, new Path("/data/DIANXIN/"));
FileOutputFormat.setOutputPath(job, new Path("/data/hfile"));
// 創建HBase連接
Connection conn = ConnectionFactory.createConnection(conf);
// create 'dianxin_bulk','info'
// 獲取dianxin_bulk 表
Table dianxin_bulk = conn.getTable(TableName.valueOf("dianxin_bulk"));
// 獲取dianxin_bulk 表 region定位器
RegionLocator regionLocator = conn.getRegionLocator(TableName.valueOf("dianxin_bulk"));
// 使用HFileOutputFormat2將輸出的資料按照HFile的形式格式化
HFileOutputFormat2.configureIncrementalLoad(job, dianxin_bulk, regionLocator);
// 等到MapReduce任務執行完成
job.waitForCompletion(true);
// 加載HFile到 dianxin_bulk 中
LoadIncrementalHFiles load = new LoadIncrementalHFiles(conf);
load.doBulkLoad(new Path("/data/hfile"), conn.getAdmin(), dianxin_bulk, regionLocator);
/**
* create 'dianxin_bulk','info'
* hadoop jar HBaseJavaAPI10-1.0-jar-with-dependencies.jar com.shujia.Demo10BulkLoading
*/
}
}
②說明
-
最終輸出結果,無論是map還是reduce,輸出部分key和value的型別必須是: < ImmutableBytesWritable, KeyValue>或者< ImmutableBytesWritable, Put>,
-
最終輸出部分,Value型別是KeyValue 或Put,對應的Sorter分別是KeyValueSortReducer或PutSortReducer,
-
MR例子中HFileOutputFormat2.configureIncrementalLoad(job, dianxin_bulk, regionLocator);自動對job進行配置,SimpleTotalOrderPartitioner是需要先對key進行整體排序,然后劃分到每個reduce中,保證每一個reducer中的的key最小最大值區間范圍,是不會有交集的,因為入庫到HBase的時候,作為一個整體的Region,key是絕對有序的,
-
MR例子中最后生成HFile存盤在HDFS上,輸出路徑下的子目錄是各個列族,如果對HFile進行入庫HBase,相當于move HFile到HBase的Region中,HFile子目錄的列族內容沒有了,但不能直接使用mv命令移動,因為直接移動不能更新HBase的元資料,
-
HFile入庫到HBase通過HBase中 LoadIncrementalHFiles的doBulkLoad方法,對生成的HFile檔案入庫
?
?
?
上一章-Hbase篇-day 56 Phoenix
下一章-隨緣更新
?
?
?
??
?


轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301704.html
標籤:其他
下一篇:HDFS資料跨區域存盤分布