目錄
- 1 連續登陸用戶
- 1.1 需求
- 1.2 分析
- 1.3 建表
- 1.4 方案一:自連接過濾實作
- 1.5 方案二:視窗函式實作
- 2 級聯累加求和
- 2.1 需求
- 2.2 分析
- 2.3 建表
- 2.4 方案一:自連接分組聚合
- 2.5 方案二:視窗函式實作
- 3 分組TopN
- 3.1 需求
- 3.2 分析
- 3.3 建表
- 3.4 實作
1 連續登陸用戶
1.1 需求
當前有一份用戶登錄資料如下圖所示,資料中有兩個欄位,分別是userId和loginTime,
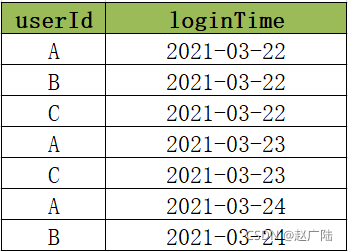
userId表示唯一的用戶ID,唯一標識一個用戶,loginTime表示用戶的登錄日期,例如第一條資料就表示A在2021年3月22日登錄了,
現在需要對用戶的登錄次數進行統計,得到連續登陸N(N>=2)天的用戶,
例如統計連續兩天的登錄的用戶,需要回傳A和C,因為A在22/23/24都登錄了,所以肯定是連續兩天登錄,C在22和23號登錄了,所以也是連續兩天登錄的,
例如統計連續三天的登錄的用戶,只能回傳A,因為只有A是連續三天登錄的,
1.2 分析
基于以上的需求根據資料尋找規律,要想得到連續登陸用戶,必須找到兩個相同用戶ID的行之間登陸日期之間的關系,
例如:統計連續登陸兩天的用戶,只要用戶ID相等,并且登陸日期之間相差1天即可,基于這個規律,我們有兩種方案可以實作該需求,
方案一:實作表中的資料自連接,構建笛卡爾積,在結果中找到符合條件的id即可
方案二:使用視窗函式來實作
1.3 建表
? 創建表
--切換資料庫
use db_function;
--建表
create table tb_login(
userid string,
logintime string
) row format delimited fields terminated by '\t';
? 創建資料:vim /export/data/login.log\
A 2021-03-22
B 2021-03-22
C 2021-03-22
A 2021-03-23
C 2021-03-23
A 2021-03-24
B 2021-03-24
? 加載資料
load data local inpath ‘/export/data/login.log’ into table tb_login;
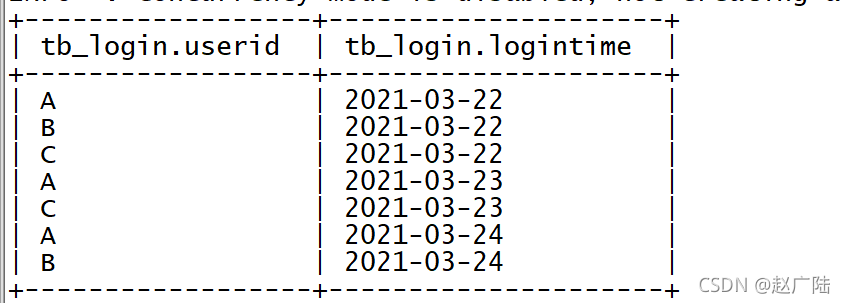
? 查詢資料
select * from tb_login;
1.4 方案一:自連接過濾實作
? 構建笛卡爾積
select
a.userid as a_userid,
a.logintime as a_logintime,
b.userid as b_userid,
b.logintime as b_logintime
from tb_login a,tb_login b;
? 查看資料
+-----------+--------------+-----------+--------------+
| A_USERID | A_LOGINTIME | B_USERID | B_LOGINTIME |
+-----------+--------------+-----------+--------------+
| A | 2021-03-22 | A | 2021-03-22 |
| B | 2021-03-22 | A | 2021-03-22 |
| C | 2021-03-22 | A | 2021-03-22 |
| A | 2021-03-23 | A | 2021-03-22 |
| C | 2021-03-23 | A | 2021-03-22 |
| A | 2021-03-24 | A | 2021-03-22 |
| B | 2021-03-24 | A | 2021-03-22 |
| A | 2021-03-22 | B | 2021-03-22 |
| B | 2021-03-22 | B | 2021-03-22 |
| C | 2021-03-22 | B | 2021-03-22 |
| A | 2021-03-23 | B | 2021-03-22 |
| C | 2021-03-23 | B | 2021-03-22 |
| A | 2021-03-24 | B | 2021-03-22 |
| B | 2021-03-24 | B | 2021-03-22 |
| A | 2021-03-22 | C | 2021-03-22 |
| B | 2021-03-22 | C | 2021-03-22 |
| C | 2021-03-22 | C | 2021-03-22 |
| A | 2021-03-23 | C | 2021-03-22 |
| C | 2021-03-23 | C | 2021-03-22 |
| A | 2021-03-24 | C | 2021-03-22 |
| B | 2021-03-24 | C | 2021-03-22 |
| A | 2021-03-22 | A | 2021-03-23 |
| B | 2021-03-22 | A | 2021-03-23 |
| C | 2021-03-22 | A | 2021-03-23 |
| A | 2021-03-23 | A | 2021-03-23 |
| C | 2021-03-23 | A | 2021-03-23 |
| A | 2021-03-24 | A | 2021-03-23 |
| B | 2021-03-24 | A | 2021-03-23 |
| A | 2021-03-22 | C | 2021-03-23 |
| B | 2021-03-22 | C | 2021-03-23 |
| C | 2021-03-22 | C | 2021-03-23 |
| A | 2021-03-23 | C | 2021-03-23 |
| C | 2021-03-23 | C | 2021-03-23 |
| A | 2021-03-24 | C | 2021-03-23 |
| B | 2021-03-24 | C | 2021-03-23 |
| A | 2021-03-22 | A | 2021-03-24 |
| B | 2021-03-22 | A | 2021-03-24 |
| C | 2021-03-22 | A | 2021-03-24 |
| A | 2021-03-23 | A | 2021-03-24 |
| C | 2021-03-23 | A | 2021-03-24 |
| A | 2021-03-24 | A | 2021-03-24 |
| B | 2021-03-24 | A | 2021-03-24 |
| A | 2021-03-22 | B | 2021-03-24 |
| B | 2021-03-22 | B | 2021-03-24 |
| C | 2021-03-22 | B | 2021-03-24 |
| A | 2021-03-23 | B | 2021-03-24 |
| C | 2021-03-23 | B | 2021-03-24 |
| A | 2021-03-24 | B | 2021-03-24 |
| B | 2021-03-24 | B | 2021-03-24 |
+-----------+--------------+-----------+--------------+
? 保存為表
create table tb_login_tmp as
select
a.userid as a_userid,
a.logintime as a_logintime,
b.userid as b_userid,
b.logintime as b_logintime
from tb_login a,tb_login b;
? 過濾資料:用戶id相同并且登陸日期相差1
select
a_userid,a_logintime,b_userid,b_logintime
from tb_login_tmp
where a_userid = b_userid
and cast(substr(a_logintime,9,2) as int) - 1 = cast(substr(b_logintime,9,2) as int);

? 統計連續登陸兩天的用戶
select
distinct a_userid
from tb_login_tmp
where a_userid = b_userid
and cast(substr(a_logintime,9,2) as int) - 1 = cast(substr(b_logintime,9,2) as int);
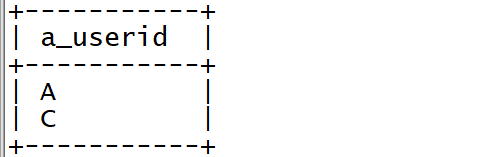
? 問題
如果現在需要統計連續3天的用戶個數,如何實作呢?或者說需要統計連續5天、連續7天、連續10天、連續30天登陸的用戶如何進行計算呢?
如果使用自連接的方式會非常的麻煩才能實作統計連續登陸兩天以上的用戶,并且性能很差,所以我們需要使用第二種方式來實作,
1.5 方案二:視窗函式實作
? 視窗函式lead
? 功能:用于從當前資料中基于當前行的資料向后偏移取值
? 語法:lead(colName,N,defautValue)
?colName:取哪一列的值
?N:向后偏移N行
? defaultValue:如果取不到回傳的默認值
?分析
當前資料中記錄了每個用戶每一次登陸的日期,一個用戶在一天只有1條資訊,我們可以基于用戶的登陸資訊,找到如下規律:
連續兩天登陸 : 用戶下次登陸時間 = 本次登陸以后的第二天
連續三天登陸 : 用戶下下次登陸時間 = 本次登陸以后的第三天
……依次類推,
我們可以對用戶ID進行磁區,按照登陸時間進行排序,通過lead函式計算出用戶下次登陸時間,通過日期函式計算出登陸以后第二天的日期,如果相等即為連續兩天登錄,
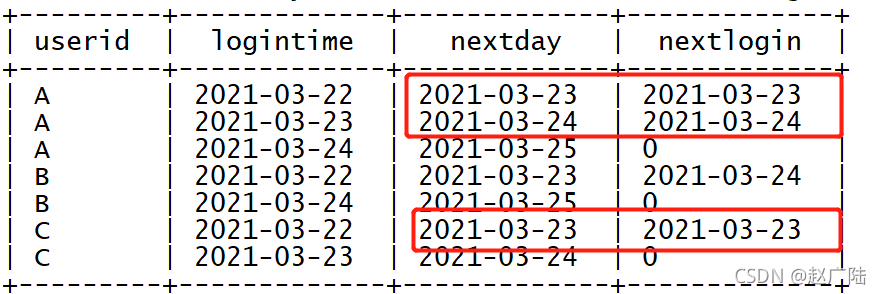
? 統計連續2天登錄
select
userid,
logintime,
--本次登陸日期的第二天
date_add(logintime,1) as nextday,
--按照用戶id磁區,按照登陸日期排序,取下一次登陸時間,取不到就為0
lead(logintime,1,0) over (partition by userid order by logintime) as nextlogin
from tb_login;
with t1 as (
select
userid,
logintime,
–本次登陸日期的第二天
date_add(logintime,1) as nextday,
–按照用戶id磁區,按照登陸日期排序,取下一次登陸時間,取不到就為0
lead(logintime,1,0) over (partition by userid order by logintime) as nextlogin
from tb_login )
select distinct userid from t1 where nextday = nextlogin;
? 統計連續3天登錄
select
userid,
logintime,
--本次登陸日期的第三天
date_add(logintime,2) as nextday,
--按照用戶id磁區,按照登陸日期排序,取下下一次登陸時間,取不到就為0
lead(logintime,2,0) over (partition by userid order by logintime) as nextlogin
from tb_login;
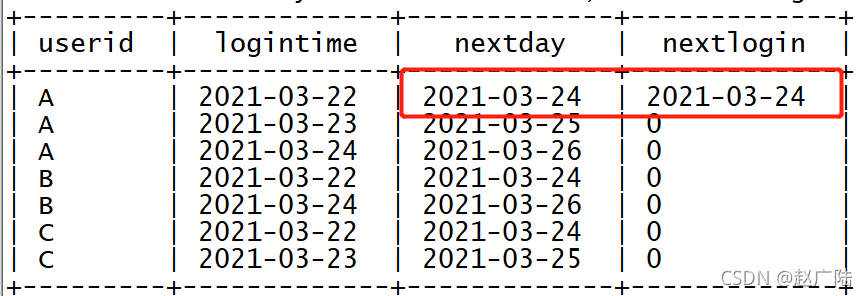
with t1 as (
select
userid,
logintime,
--本次登陸日期的第三天
date_add(logintime,2) as nextday,
--按照用戶id磁區,按照登陸日期排序,取下下一次登陸時間,取不到就為0
lead(logintime,2,0) over (partition by userid order by logintime) as nextlogin
from tb_login )
select distinct userid from t1 where nextday = nextlogin;
? 統計連續N天登錄
select
userid,
logintime,
–本次登陸日期的第N天
date_add(logintime,N-1) as nextday,
–按照用戶id磁區,按照登陸日期排序,取下下一次登陸時間,取不到就為0
lead(logintime,N-1,0) over (partition by userid order by logintime) as nextlogin
from tb_login;
2 級聯累加求和
2.1 需求
當前有一份消費資料如下,記錄了每個用戶在每個月的所有消費記錄,資料表中一共有三列:
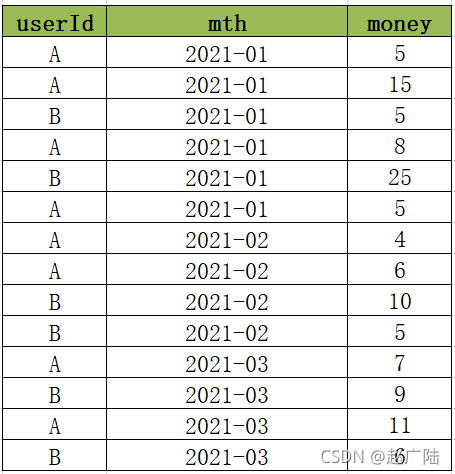
?userId:用戶唯一id,唯一標識一個用戶
?mth:用戶消費的月份,一個用戶可以在一個月多次消費
?money:用戶每次消費的金額
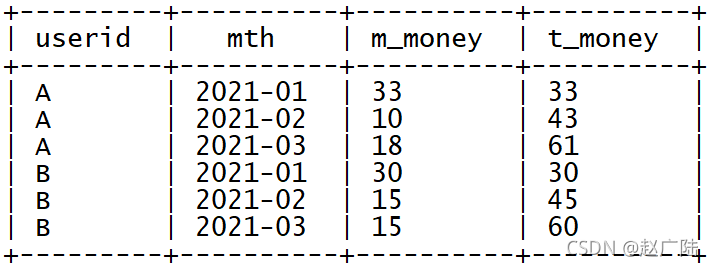
現在需要基于用戶每個月的多次消費的記錄進行分析,統計得到每個用戶在每個月的消費總金額以及當前累計消費總金額,最后結果如下:
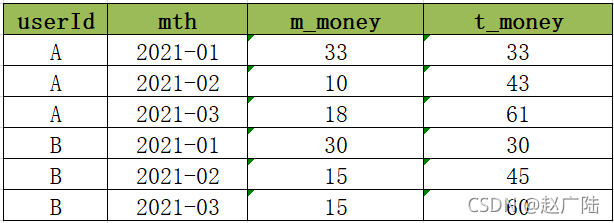
以用戶A為例:
A在2021年1月份,共四次消費,分別消費5元、15元、8元、5元,所以本月共消費33元,累計消費33元,
A在2021年2月份,共兩次消費,分別消費4元、6元,所以本月共消費10元,累計消費43元,
2.2 分析
如果要實作以上需求,首先要統計出每個用戶每個月的消費總金額,分組實作集合,但是需要按照用戶ID,將該用戶這個月之前的所有月份的消費總金額進行累加實作,該需求可以通過兩種方案來實作:
方案一:分組統計每個用戶每個月的消費金額,然后構建自連接,根據條件分組聚合
方案二:分組統計每個用戶每個月的消費金額,然后使用視窗聚合函式實作
2.3 建表
? 創建表
--切換資料庫
use db_function;
--建表
create table tb_money(
userid string,
mth string,
money int
) row format delimited fields terminated by '\t';
? 創建資料:vim /export/data/money.tsv
A 2021-01 5
A 2021-01 15
B 2021-01 5
A 2021-01 8
B 2021-01 25
A 2021-01 5
A 2021-02 4
A 2021-02 6
B 2021-02 10
B 2021-02 5
A 2021-03 7
B 2021-03 9
A 2021-03 11
B 2021-03 6
?加載資料
load data local inpath ‘/export/data/money.tsv’ into table tb_money;
? 查詢資料
select * from tb_money;
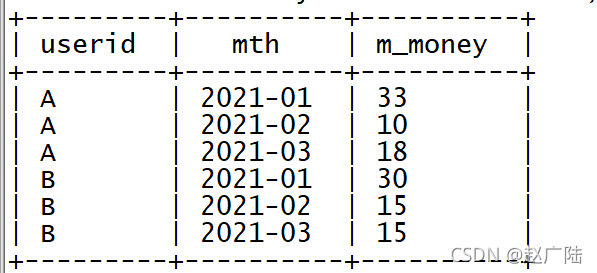
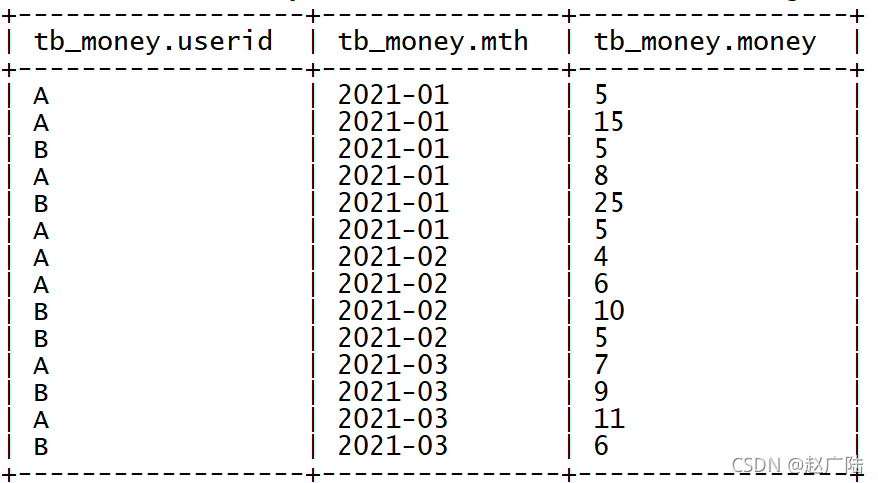 ? 統計得到每個用戶每個月的消費總金額
? 統計得到每個用戶每個月的消費總金額
create table tb_money_mtn as
select
userid,
mth,
sum(money) as m_money
from tb_money
group by userid,mth;
2.4 方案一:自連接分組聚合
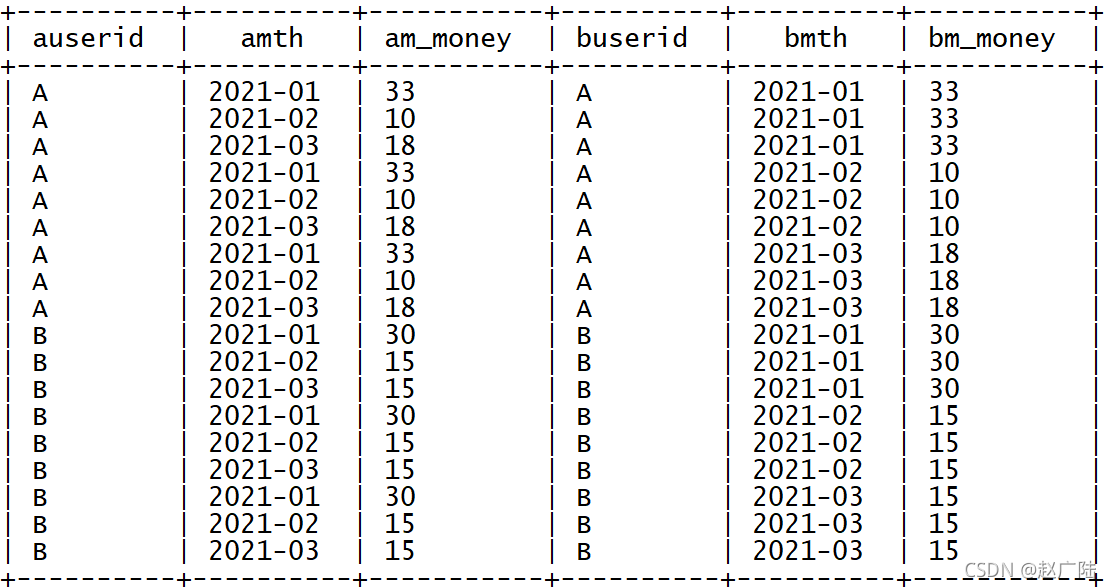
? 基于每個用戶每個月的消費總金額進行自連接
select
a.userid as auserid,
a.mth as amth,
a.m_money as am_money,
b.userid as buserid,
b.mth as bmth,
b.m_money as bm_money
from tb_money_mtn a join tb_money_mtn b on a.userid = b.userid;
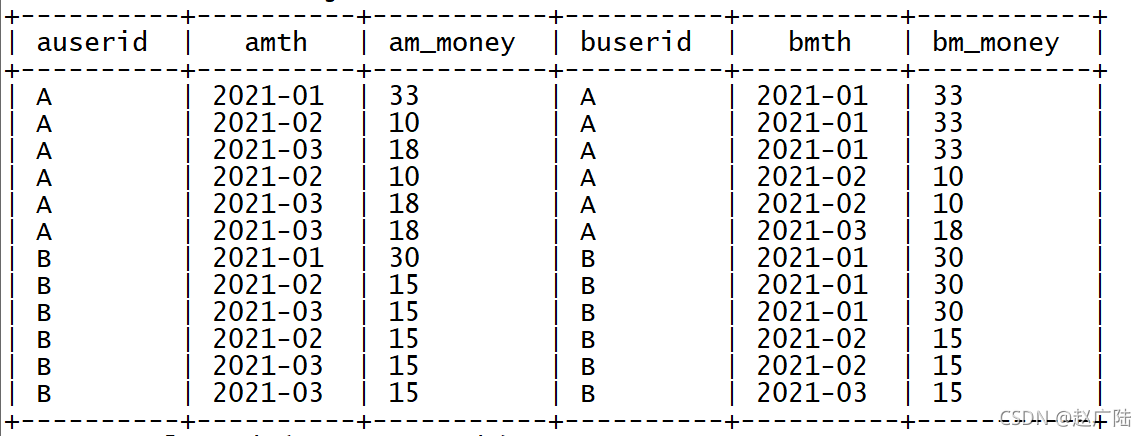
? 將每個月之前月份的資料過濾出來
select
a.userid as auserid,
a.mth as amth,
a.m_money as am_money,
b.userid as buserid,
b.mth as bmth,
b.m_money as bm_money
from tb_money_mtn a join tb_money_mtn b on a.userid = b.userid
where a.mth >= b.mth;
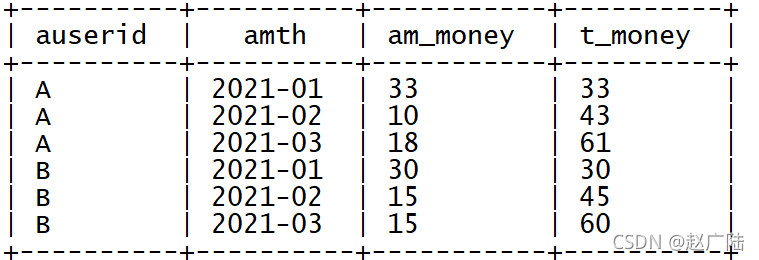
? 對每個用戶每個月的金額進行分組,聚合之前月份的消費金額
select
a.userid as auserid,
a.mth as amth,
a.m_money as am_money,
sum(b.m_money) as t_money
from tb_money_mtn a join tb_money_mtn b on a.userid = b.userid
where a.mth >= b.mth
group by a.userid,a.mth,a.m_money;
2.5 方案二:視窗函式實作
? 視窗函式sum
? 功能:用于實作基于視窗的資料求和
? 語法:sum(colName) over (partition by col order by col)
?colName:對某一列的值進行求和
?分析
基于每個用戶每個月的消費金額,可以通過視窗函式對用戶進行磁區,按照月份排序,然后基于聚合視窗,從每個磁區的第一行累加到當前和,即可得到累計消費金額,
? 統計每個用戶每個月消費金額及累計總金額
select
userid,
mth,
m_money,
sum(m_money) over (partition by userid order by mth) as t_money
from tb_money_mtn;
3 分組TopN
3.1 需求
作業中經常需要實作TopN的需求,例如熱門商品Top10、熱門話題Top20、熱門搜索Top10、地區用戶Top10等等,TopN是大資料業務分析中最常見的需求,

普通的TopN只要基于資料進行排序,然后基于排序后的結果取前N個即可,相對簡單,但是在TopN中有一種特殊的TopN計算,叫做分組TopN,
分組TopN指的是基于資料進行分組,從每個組內取TopN,不再基于全域取TopN,如果要實作分組取TopN就相對麻煩,
例如:現在有一份資料如下,記錄這所有員工的資訊: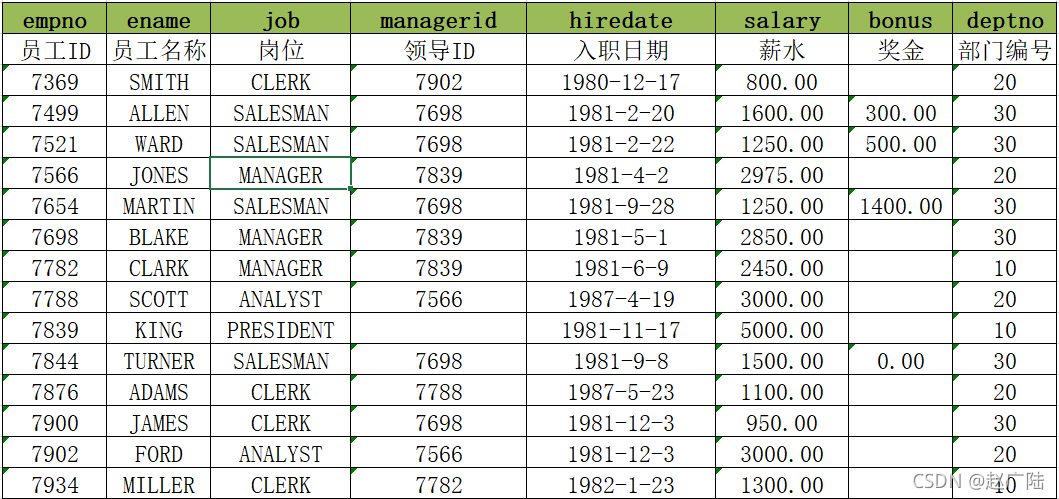
如果現在有一個需求:查詢每個部門薪資最高的員工的薪水,這個可以直接基于表中資料分組查詢得到
select deptno,max(salary) from tb_emp group by deptno;
但是如果現在需求修改為:統計查詢每個部門薪資最高的前兩名員工的薪水,這時候應該如何實作呢?
3.2 分析
根據上述需求,這種情況下是無法根據group by分組聚合實作的,因為分組聚合只能實作回傳一條聚合的結果,但是需求中需要每個部門回傳薪資最高的前兩名,有兩條結果,這時候就需要用到視窗函式中的磁區來實作了,
3.3 建表
? 創建表
--切換資料庫
use db_function;
--建表
create table tb_emp(
empno string,
ename string,
job string,
managerid string,
hiredate string,
salary double,
bonus double,
deptno string
) row format delimited fields terminated by '\t';
?創建資料:vim /export/data/emp.txt
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
? 加載資料
load data local inpath ‘/export/data/emp.txt’ into table tb_emp;
?查詢資料
select empno,ename,salary,deptno from tb_emp;
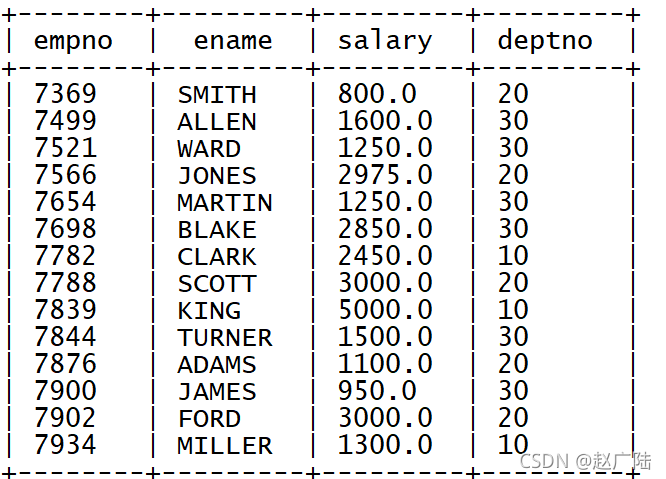
3.4 實作
? TopN函式:row_number、rank、dense_rank
? row_number:對每個磁區的資料進行編號,如果值相同,繼續編號
? rank:對每個磁區的資料進行編號,如果值相同,編號相同,但留下空位
? dense_rank:對每個磁區的資料進行編號,如果值相同,編號相同,不留下空位
? 基于row_number實作,按照部門磁區,每個部門內部按照薪水降序排序
select
empno,
ename,
salary,
deptno,
row_number() over (partition by deptno order by salary desc) as rn
from tb_emp;
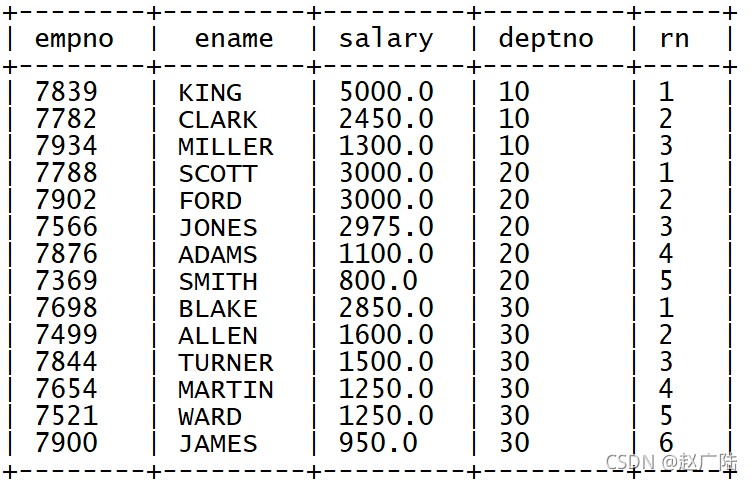
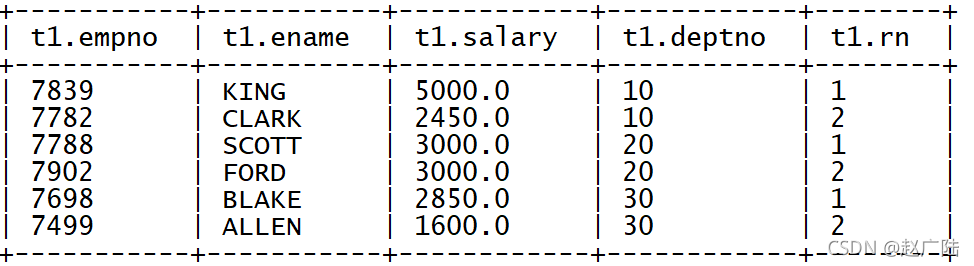
? 過濾每個部門的薪資最高的前兩名
with t1 as (
select
empno,
ename,
salary,
deptno,
row_number() over (partition by deptno order by salary desc) as rn
from tb_emp )
select * from t1 where rn < 3;
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301711.html
標籤:其他