目錄
- 深度學習計算
- 層和塊
- 引數管理
- 自定義層
- 讀寫檔案
- 卷積神經網路
- 從全連接層到卷積
- 影像卷積
- 填充和步幅
- 多輸入多輸出通道
- 池化層
- LeNet
- 貓狗大戰
深度學習計算
層和塊
單個神經元:(1)接受一些輸入;(2)生成相應的標量輸出;(3)具有一組相關 引數(parameters),
層:(1)接受一組輸入,(2)生成相應的輸出,(3)由一組可調整引數描述,
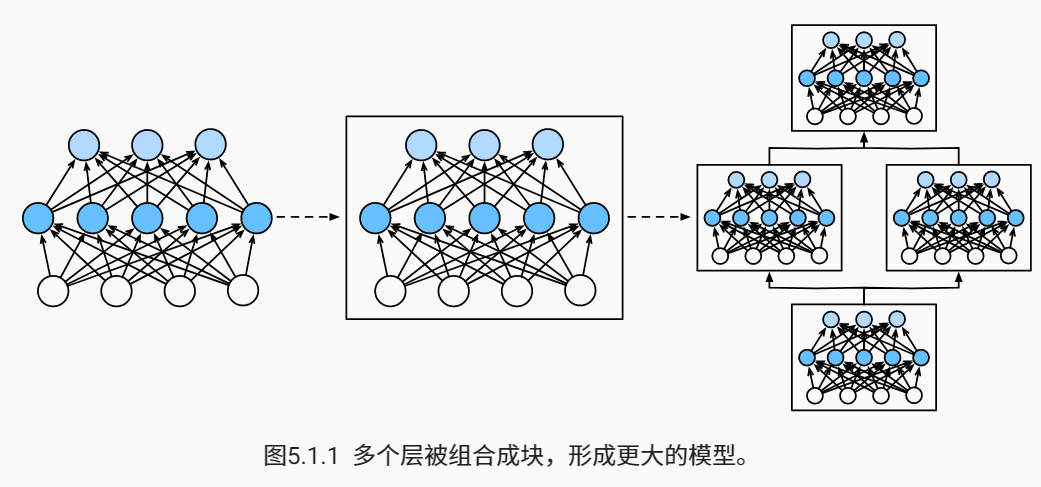
自定義塊
每個塊必須提供的基本功能:
1.將輸入資料作為其正向傳播函式的引數,
2.通過正向傳播函式來生成輸出,請注意,輸出的形狀可能與輸入的形狀不同,例如,我們上面模型中的第一個全連接的層接收任意維的輸入,但是回傳一個維度256的輸出,
3.計算其輸出關于輸入的梯度,可通過其反向傳播函式進行訪問,通常這是自動發生的,
4.存盤和訪問正向傳播計算所需的引數,
5.根據需要初始化模型引數,
順序塊
需要定義兩個關鍵函式: 1. 一種將塊逐個追加到串列中的函式, 2. 一種正向傳播函式,用于將輸入按追加塊的順序傳遞給塊組成的“鏈條”,
在正向傳播函式中執行代碼
到目前為止,我們網路中的所有操作都對網路的激活值及網路的引數起作用,然而,有時我們可能希望合并既不是上一層的結果也不是可更新引數的項,我們稱之為常數引數(constant parameters),
引數管理
選擇了架構并設定了超引數之后,我們就進入了訓練階段,此時,我們的目標是找到使損失函式最小化的引數值,經過訓練后,我們將需要使用這些引數來做出未來的預測,大多數情況下,我們可以忽略宣告和操作引數的具體細節,而只依靠深度學習框架來完成繁重的作業,然而,當我們離開具有標準層的層疊架構時,我們有時會陷入宣告和操作引數的麻煩中,
引數管理主要介紹:
1.訪問引數,用于除錯、診斷和可視化,
2.引數初始化,
3.在不同模型組件間共享引數,
引數訪問
目標引數
每個引數都表示為引數(parameter)類的一個實體,要對引數執行任何操作,首先我們需要訪問底層的數值,
引數是復合的物件,包含值、梯度和額外資訊,除了值之外,我們還可以訪問每個引數的梯度,
一次性訪問所有引數
當我們處理更復雜的塊(例如,嵌套塊)時,需要遞回整個樹來提取每個子塊的引數,同時,這為我們提供了另一種訪問網路引數的方式,
從嵌套塊收集引數
定義一個生成塊的函式(可以說是塊工廠),然后將這些塊組合到更大的塊中,因為層是分層嵌套的,所以我們也可以像通過嵌套串列索引一樣訪問它們,
引數初始化
默認情況下,PyTorch會根據一個范圍均勻地初始化權重和偏置矩陣,這個范圍是根據輸入和輸出維度計算出的,PyTorch的nn.init模塊提供了多種預置初始化方法,
內置初始化
首先呼叫內置的初始化器;還可以將所有引數初始化為給定的常數(比如1);還可以對某些塊應用不同的初始化方法,
自定義初始化
若深度學習框架沒有提供我們需要的初始化方法,我們使用以下的分布為任意權重引數ω定義初始化方法:

1.實作了一個my_init函式來應用到net
2.可以直接設定引數
引數系結
目的:在多個層間共享引數,
引數系結的層:不僅值相等,而且由相同的張量表示,因此,如果我們其中一個引數會隨另一個引數的改變而改變,
梯度變化情況:當引數系結時,由于模型引數包含梯度,因此在反向傳播期間引數系結的層的梯度會加在一起,
自定義層
不帶引數的層
要構建不帶引數的層,我們只需繼承基礎層類并實作正向傳播功能,
帶引數的層
我們可以使用內置函式來創建引數,這些函式提供一些基本的管理功能,比如管理訪問、初始化、共享、保存和加載模型引數,這樣做的好處之一是,我們不需要為每個自定義層撰寫自定義序列化程式,
讀寫檔案
加載和保存張量
對于單個張量,我們可以直接呼叫load和save函式分別讀寫它們,這兩個函式都要求我們提供一個名稱,save要求將要保存的變數作為輸入,
1.可以將存盤在檔案中的資料讀回記憶體,
2.可以存盤一個張量串列,然后把它們讀回記憶體,
3.可以寫入或讀取從字串映射到張量的字典,當我們要讀取或寫入模型中的所有權重時,這很方便,
加載和保存模型引數
深度學習框架提供了內置函式來保存和加載整個網路,需要注意一點,這將保存模型的引數而不是保存整個模型,
卷積神經網路
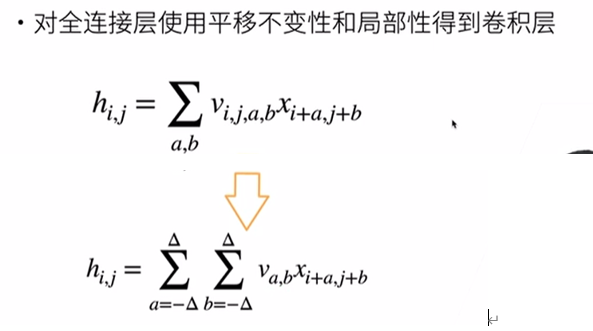
從全連接層到卷積
全連接層
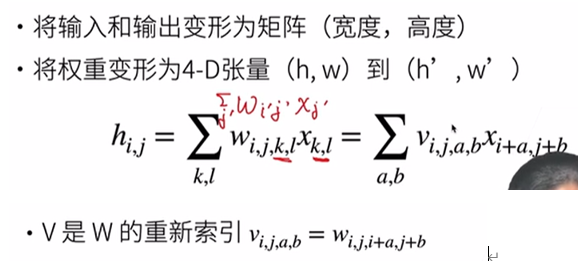


總結
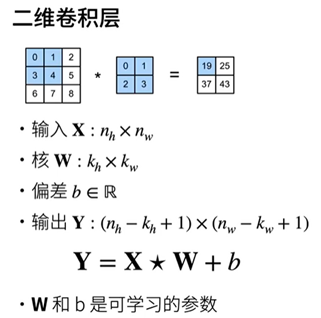
影像卷積




代碼實作
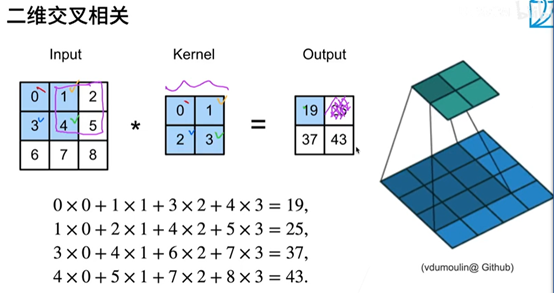
互相關運算

注:X:輸入 K:核矩陣 h、w: 行數列數
Y(輸出):輸入的高-核的高度+1,輸入的寬度-核的寬度+1
for for遍歷所有輸出元素
驗證上述二維互相關運算的輸出

實作二維卷積層

卷積層的簡單應用:檢測影像中不同顏色的邊緣
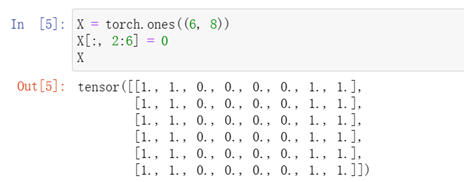


卷積核K只能檢測垂直邊緣
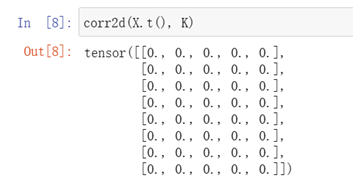
學習由X生成Y的卷積核

注:輸入輸出均為1
Reshape增加兩個維度:通道數,批量大小數,均為1
L:loss
訪問Weight.data操作:inplace操作?
所學的卷積核的權重張量

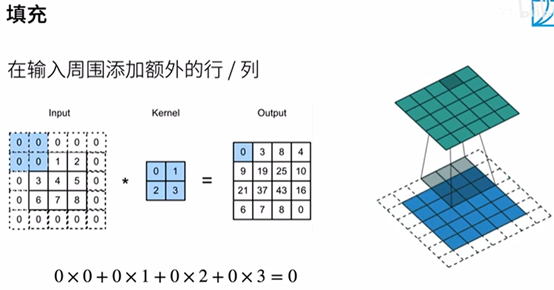
填充和步幅





代碼實作
填充(在所有側邊填充1個像素)

注:定義一個函式
在維度前面加入通道數、批量大小數
呼叫conv2d函式
四維拿掉前兩維得到矩陣的輸出
填充不同的高度和寬度

注:Padding(填充)行數2 列數1
輸出輸入還一樣88*
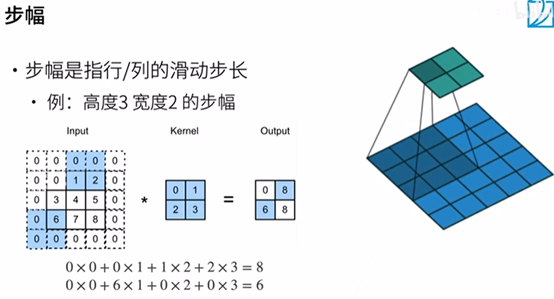
將高度和寬度步幅設定為2

注:stride(步幅)=2
輸出44 減半*
復雜例子

QA
1.超引數重要程度:核大小最重要,其次填充,步幅;
2.卷積核3*3居多;
3.多個輸入和輸出通道,重要超引數:通道數,
多輸入多輸出通道



變化:卷積核多了Co(output),


代碼實作
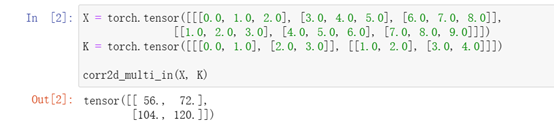
實作多通入通道互相關運算

注:X、K都是3d,zip起來,for拿出對應輸入通道的小矩陣,做互相關運算,然后求和,
驗證互相關運算的輸出
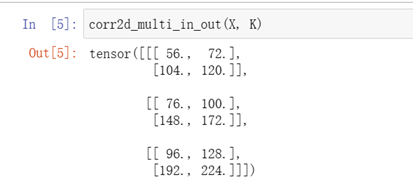
計算多通道的輸出的互相關函式

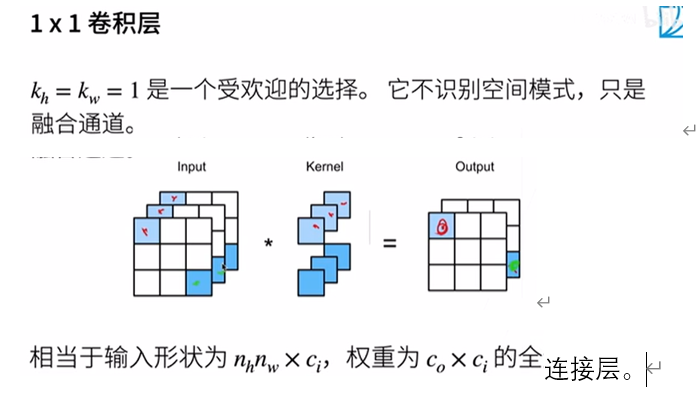
1*1卷積

池化層

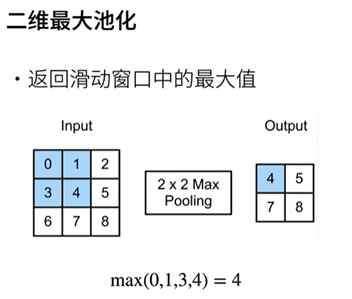



代碼實作
實作池化層的正向傳播

驗證二維最大匯聚層的輸出

驗證平均匯聚層

填充和步幅
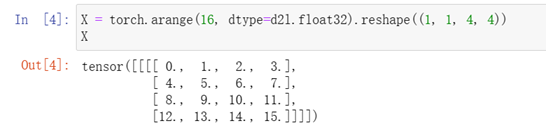
深度學習框架中的步幅與池化視窗的大小相同
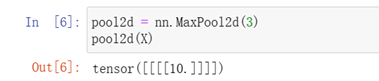
填充和步幅可以手動設定

可以設定一個任意大小的矩形池化視窗,并分別設定填充和步幅的高度和寬度
池化層在每個輸入通道上單獨運算


LeNet

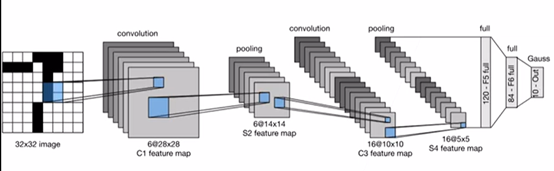

代碼實作
LeNet(LeNet-5)由兩個部分組成: * 卷積編碼器:由兩個卷積層組成; * 全連接層密集塊:由三個全連接層組成,
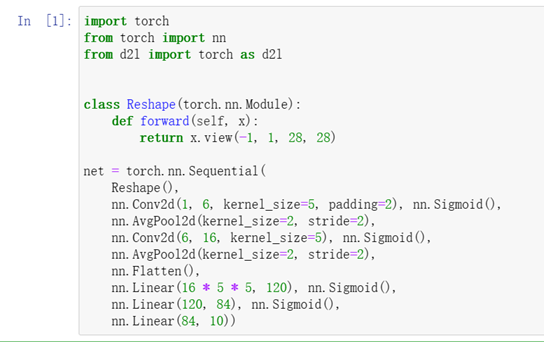
注:Reshape() 批量數不變 通道數變成1 2828
卷積層nn.Conv2d(輸入1,輸出6,kernel55,填充2) 加入nn.Sigmoid()激活函式
均值池化層 nn.AvgPool2d(kernel22 步幅2)
卷積層 nn.Conv2d(輸入6,輸出16,kernel55) 加入nn.Sigmoid()激活函式
均值池化層 nn.AvgPool2d(kernel22 步幅2) nn.Flatten():第一位批量保持,后面拉成一樣的維度
nn.Linear(1655,120) nn.Sigmoid()
nn.Linear(120,84) nn.Sigmoid()
nn.Linear(84,10)*
檢查模型

注:第一組卷積+池化+激活
卷積: 12828->62828 通道數變為6,高寬不變
Sigmoid: 62828
平均池化:62828->61414 通道數不變,高寬變了
第二組卷積+池化+激活
卷積: 61414->161010 通道數變為16,高寬變為1010
Sigmoid: 161010
平均池化:161010->1655 通道數不變,高寬變了
Flatten:1400 拉直變成MLP
Liner+Sigmoid:1120
Liner+Sigmoid:184
Liner:110*
LeNet在Fashion-MNIST資料集上的表現

對 evaluate_accuracy函式進行輕微的修改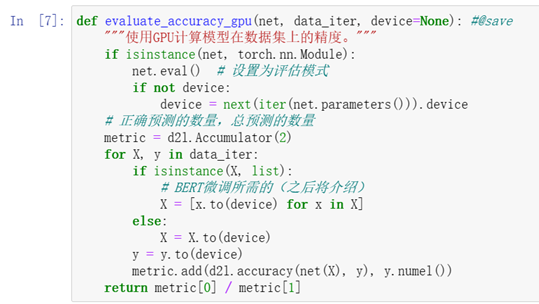
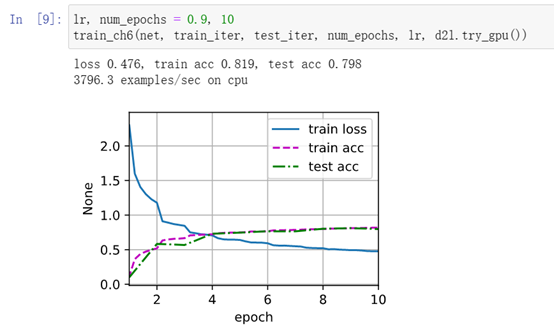
訓練和評估LeNet-5模型
貓狗大戰
GPU
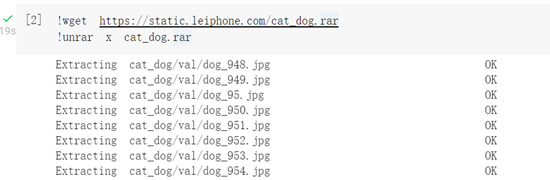
下載解壓資料集到當前目錄
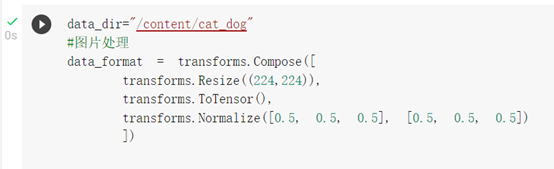
圖片處理
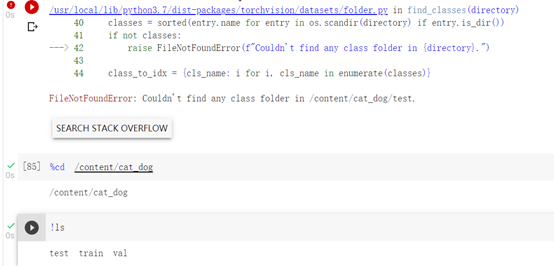
拼接路徑

報錯…
未完待續…
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301854.html
標籤:其他
上一篇:torch-1.8.1 cu111-cp38-cp38-win_amd64.whl is not a supported wheel on this p