前言
YOLOP能同時處理目標檢測、可行駛區域分割、車道線檢測 三個視覺感知任務,并速度優異、保持較好精度進行作業,代碼開源,它是華中科技大學——王興剛團隊,在全景駕駛感知方面提出的模型,致敬開源精神,
論文地址:https://arxiv.org/abs/2108.11250
開源代碼:https://github.com/hustvl/YOLOP

目錄
一、網路框架
1.1 Encoder 編碼器
1.2 Decoders 解碼器
二、損失函式和訓練方法
三、YOLOP效果與性能
四、搭建開發環境
五、模型推理測驗
5.1 推理圖片
5.2 使用GPU推理
5.3 推理視頻
5.4 使用相機進行推理
六、訓練模型
參考文獻
摘要
全景駕駛感知系統是自動駕駛的重要組成部分,高精度、實時的感知系統可以輔助車輛在行駛中做出合理的決策,提出了一個全景駕駛感知網路(YOLOP)來同時執行交通目標檢測、可行駛區域分割和車道檢測,


在上圖中,紫色邊界框表示交通物件,綠色區域是可行駛區域,紅色線表示車道線,
一、網路框架
YOLOP由一個用于特征提取的編碼器,和三個用于處理特定任務的解碼器組成,下圖是YOLOP的網路結構:
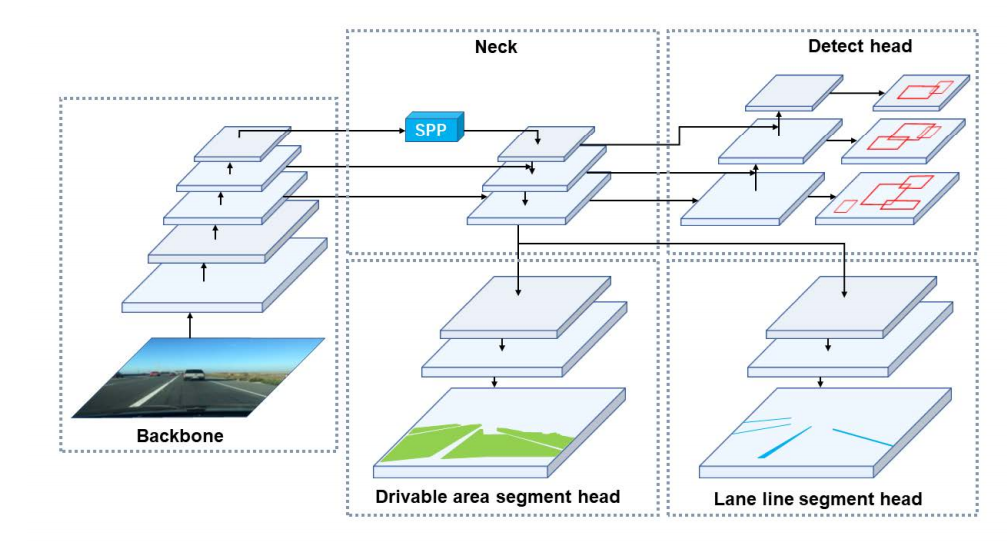
YOLOP是一種單階段網路,包含一個共享編碼器,三個用于特定任務的解碼器,其中三個任務的解碼器:目標檢測部分、可行駛區域分割、車道線分割,不同解碼器之間并沒有復雜的、冗余共享模塊,這可以極大降低計算量,同時使得該網路易于端到端訓練,
1.1 Encoder 編碼器
該網路中的編碼器由Backbone網路與Neck網路構成,
Backbone網路:參考了YOLOv4,采用CSP-Darknet結構,提取輸入影像的特征,它支持特征傳播和重用,減少了引數和計算的數量,
Neck網路:使得提取的影像特征以充分利用它們,它由空間金字塔池(SPP)模塊和特征金字塔網路(FPN)模塊組成,SPP模型生成并融合不同尺度的特征,FPN模塊融合不同語意層次的特征,因此,Neck網路生成包含“多個尺度”和“多個語意級別資訊”的豐富特征,便于融合特征,
1.2 Decoders 解碼器
YOLOP包含三個用于三個任務的解碼器:目標檢測部分、可行駛區域分割、車道線分割,
1)對于目標檢測任務,YOLOP 采用了類似于 YOLOv4 的基于錨框Anchor的多尺度檢測技術,這部分結構由“路徑聚合網路”組成;Neck網路中的 FPN 自上而下傳輸語意特征,而 PAN 自下而上傳輸影像特征,YOLOP 將它們結合起來以獲得更好的特征融合效果,由此獲得的多尺度融合特征圖用于檢測,
多尺度特征的每個grid被賦予三個先驗anchor(包含不同縱橫比),檢測頭將預測位置偏移、高寬、類別概率以及預測置信度,
2)可行駛區域分割和車道線分割部分使用相同的網路結構,將FPN的輸出特征(解析度為)送入到分割分支,我們設計的分割分支非常簡單,通過三次上采樣處理輸出特征尺寸為,代表每個像素是駕駛區域/車道線還是背景的概率,由于Neck中已包含SPP模塊,我們并未像PSPNet添加額外的SPP模塊,此外,我們采用了最近鄰上采樣層以降低計算量,因此,分割解碼器不僅具有高精度輸出,同時推理速度非常快,
來自 FPN 底層的大小為(W/8, H/8, 256)的特征被饋送到分割分支,它應用三個上采樣程序并將特征圖恢復為(W, H, 2),它表示輸入影像中可行駛區域和車道線的像素級概率,在其他分割網路有 SPP 模塊的地方,YOLOP 分割頭不需要,因為Neck網路中共享 SPP 模塊,
二、損失函式和訓練方法
YOLOP 使用簡單的損失函式,它為三個解碼器頭提供三個單獨的損失函式,檢測損失是分類損失、物件損失和邊界框損失的加權和,可行駛區域分割頭和車道線分割頭的損失函式都包含帶有 logits 的交叉熵損失,車道線分割由于其在預測備用類別方面的有效性而具有額外的 IoU 損失,模型的整體損失函式是所有三個損失的加權和,

上圖是端到端與交替優化技術的訓練結果,YOLOP 的創建者嘗試了不同的訓練方法,他們嘗試了端到端的培訓,這在所有任務都相關的情況下非常有用,此外,他們還研究了一些逐步訓練模型的交替優化演算法,每個步驟都專注于一項或多項相關任務,但經過作者測驗,交替優化演算法提供的性能改進可以忽略不計,
三、YOLOP效果與性能
車輛檢測效果:

| Model | Recall(%) | mAP50(%) | Speed(fps) |
|---|---|---|---|
Multinet | 81.3 | 60.2 | 8.6 |
DLT-Net | 89.4 | 68.4 | 9.3 |
Faster R-CNN | 77.2 | 55.6 | 5.3 |
YOLOv5s | 86.8 | 77.2 | 82 |
YOLOP(ours) | 89.2 | 76.5 | 41 |
可行區域檢測效果:

| Model | mIOU(%) | Speed(fps) |
|---|---|---|
Multinet | 71.6 | 8.6 |
DLT-Net | 71.3 | 9.3 |
PSPNet | 89.6 | 11.1 |
YOLOP(ours) | 91.5 | 41 |
車道線檢測效果:

| Model | mIOU(%) | IOU(%) |
|---|---|---|
ENet | 34.12 | 14.64 |
SCNN | 35.79 | 15.84 |
ENet-SAD | 36.56 | 16.02 |
YOLOP(ours) | 70.50 | 26.20 |
性能小結:
YOLOP 在具有挑戰性的 BDD100K 資料集上針對三個任務的最新模型進行了測驗,它在物件檢測任務的準確性方面擊敗了 Faster RCNN、MultiNet 和 DLT-Net,并且可以實時推斷,對于可行駛區域分割任務,YOLOP 的性能分別比 MultiNet 和 DLT-Net 等模型高 19.9% 和 20.2%,而且,它比它們都快 4 到 5 倍,同樣,對于車道檢測任務,它的性能優于現有的最先進模型高達 2 倍,
它是首批在 Jetson TX2 等嵌入式設備上同時實時執行這三項任務并實作最先進性能的模型之一,
四、搭建開發環境
下載工程包,并解壓,https://github.com/hustvl/YOLOP
首先創建一個conda環境,命名為YOLOP
conda create -n YOLOP python=3.7創建好后進入環境
conda activate YOLOP安裝PyTorch 1.7+版本和 torchvision 0.8+版本
conda install pytorch==1.7.0 torchvision==0.8.0 cudatoolkit=10.2 -c pytorch安裝其他依賴庫
pip install -r requirements.txt如果安裝程序沒錯誤,這樣YOLOP的開發環境就搭建好了,
五、模型推理測驗
注意:官方代碼默認是“注釋掉標簽資訊的”,如果想每個框框中顯示類別和置信度,需要解注釋,
lib/utils/plot.py,在plot.py檔案中的81到87行代碼,進行解注釋
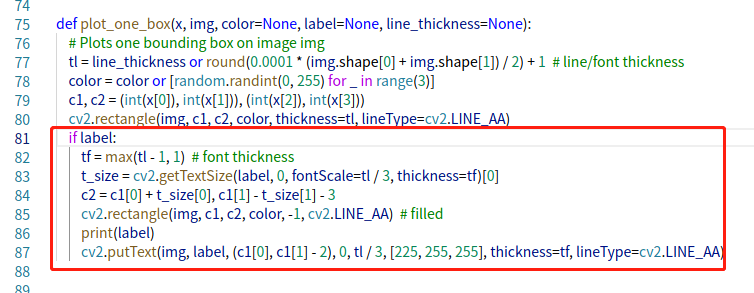
輸入的結果中,每個框有標簽資訊

5.1 推理圖片
測驗某一張圖片
python tools/demo.py --source inference/images/name.png測驗整個目錄下的所有圖片
python tools/demo.py --source inference/images結果不會直接顯示的,而是放在 inference/output 目錄下,
5.2 使用GPU推理
代碼默認是CPU進行推理的,如果使用GPU需要添加引數 --device
python tools/demo.py --source inference/images/name.png --device 0這里的0 是指系統為GPU分配的cuda device號,如果只有一個顯卡,默認是0了,
指定CPU進行推理
python tools/demo.py --source inference/images/name.png --device cpu5.3 推理視頻
使用GPU推理視頻
python tools/demo.py --source inference/videos/1.mp4 --device 05.4 使用相機進行推理
使用相機進行GPU推理
python tools/demo.py --source 0 --device 0這里的--source 0,是指系統為相機分配的設備號,如果只有一個,默認是0了,
六、訓練模型
首先下載資料集和標簽:
-
從 images下載圖片資料集
-
從 det_annotations下載檢測任務的標簽
-
從 da_seg_annotations下載可行駛區域分割任務的標簽
-
從 ll_seg_annotations下載車道線分割任務的標簽
按照如下圖片資料集檔案結構:
├─dataset root
│ ├─images
│ │ ├─train
│ │ ├─val
│ ├─det_annotations
│ │ ├─train
│ │ ├─val
│ ├─da_seg_annotations
│ │ ├─train
│ │ ├─val
│ ├─ll_seg_annotations
│ │ ├─train
│ │ ├─val
在 ./lib/config/default.py下更新資料集的路徑配置,
我們可以在 ./lib/config/default.py設定訓練配置. (包括: 預訓練模型的讀取,損失函式, 資料增強,optimizer,訓練預熱和余弦退火,自動anchor,訓練輪次epoch, batch_size)
如果你想嘗試交替優化或者單一任務學習,可以在./lib/config/default.py 中將對應的配置選項修改為 True,(如下,所有的配置都是 False, which means training multiple tasks end to end),
# Alternating optimization
_C.TRAIN.SEG_ONLY = False # Only train two segmentation branchs
_C.TRAIN.DET_ONLY = False # Only train detection branch
_C.TRAIN.ENC_SEG_ONLY = False # Only train encoder and two segmentation branchs
_C.TRAIN.ENC_DET_ONLY = False # Only train encoder and detection branch
# Single task
_C.TRAIN.DRIVABLE_ONLY = False # Only train da_segmentation task
_C.TRAIN.LANE_ONLY = False # Only train ll_segmentation task
_C.TRAIN.DET_ONLY = False # Only train detection task
開始訓練:
python tools/train.py參考文獻
[1] YOLOP介紹
[3] 論文地址:https://arxiv.org/abs/2108.11250
[4] 開源代碼:https://github.com/hustvl/YOLOP
[5] YOLOP/README _CH.md at main · hustvl/YOLOP · GitHub
本文只供大家參考和學習,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301856.html
標籤:其他