Zookeeper
1、Zookeeper快速入門
1.1、Zookeeper 概述
- Zookeeper 是一個基于觀察者模式設計的分布式服務管理框架,負責存盤和管理資料,接受觀察者的注冊,一旦這些資料的狀態發生變化,Zookeeper 就將負責通知已經在Zookeeper上注冊的那些觀察者做出相應的反應,
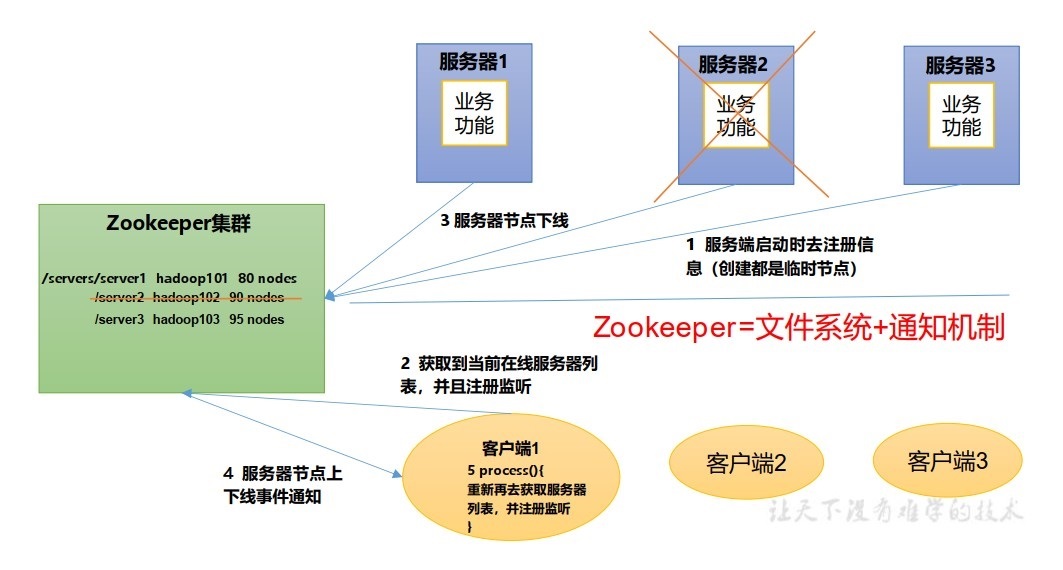
1.2、Zookeeper 的特點
1):Zookeeper :一個領導者 (Leader),多個跟隨者 (Follower)組成的集群,
2):集群中只要有半數以上節點存活,Zookeeper 集群就能正常服務,所以Zookeeper 適合安裝奇數臺服務器,
3):全域資料一致:每個Server保存一份相同的資料副本,Client無論連接到哪個Server,資料都是一致的,
4):更新請求順序執行,來自同一個Client的更新請求按其發送順序依次執行,
5):資料更新原子性,一次資料更新要么成功,要么失敗,
6):實時性,在一定時間范圍內,Client能讀到最新資料,
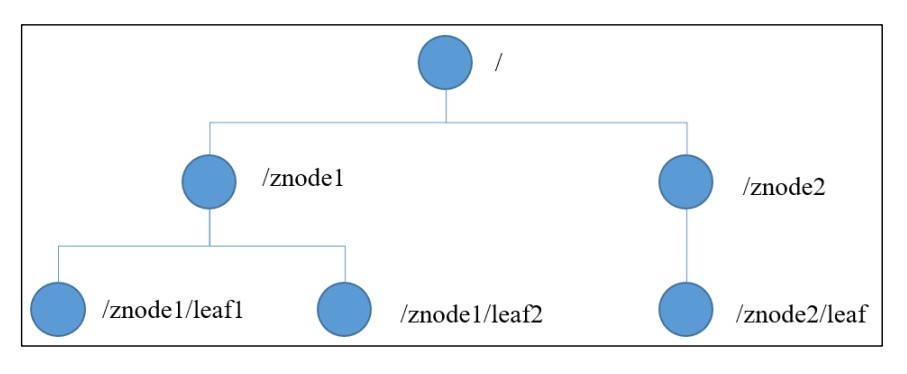
1.3、資料結構
- Zookeeper 資料模型的結構與Unix 檔案系統很類似,像一個分布式的小檔案存盤系統,整體上可以看作是一棵樹,每個節點稱做一個 ZNode,每一個 ZNode 默認能夠存盤 1MB 的資料,每個 ZNode 都可以通過其路徑唯一標識,
1.4、應用場景
-
提供的服務包括:統一命名服務、統一配置管理、統一集群管理、服務器節點動態上下線、軟負載均衡等 ,
-
同一服務命名:在分布式環境下,經常需要對應用/服務進行統一命名,便于識別,例如:IP不容易記住,而域名容易記住,
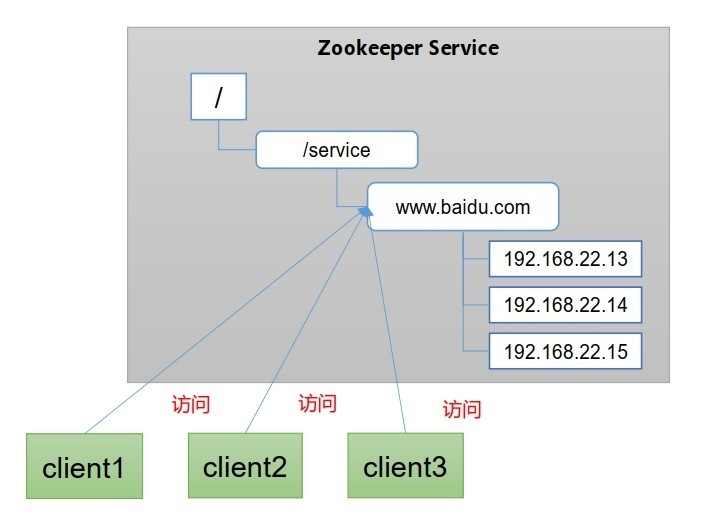
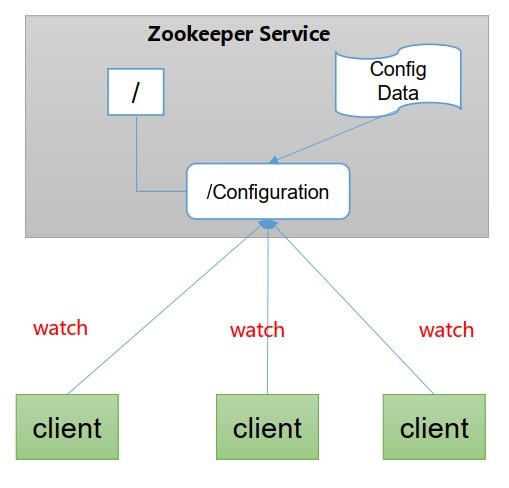
- 統一配置管理
- 分布式環境下,組態檔同步非常常見:1、一般要求一個集群中,所有節點的配置資訊是一致的,比如Kafka集群,2、對組態檔修改之后,希望能夠快速同步到各個節點上,
- 配置管理可交由Zookeeper實作:1、可將配置資訊寫入Zookeeper上的一個Znode,2、各個客戶端服務器監聽這個Znode,3、一旦Znode中的資料被修改,Zookeeper將通知各個客戶端服務器,
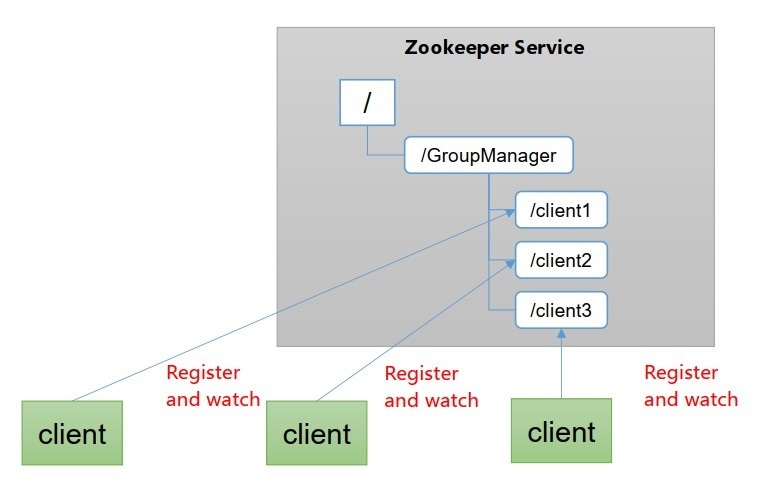
- 同一集群管理
- 分布式環境中,實時掌握每個節點的狀態是必要的:可根據節點實時狀態做出一些調整,
- Zookeeper可以實作實時監控節點狀態變化:1、可將節點資訊寫入Zookeeper上的一個Znode,2、監聽這個Znode可獲取它的實時狀態變化,
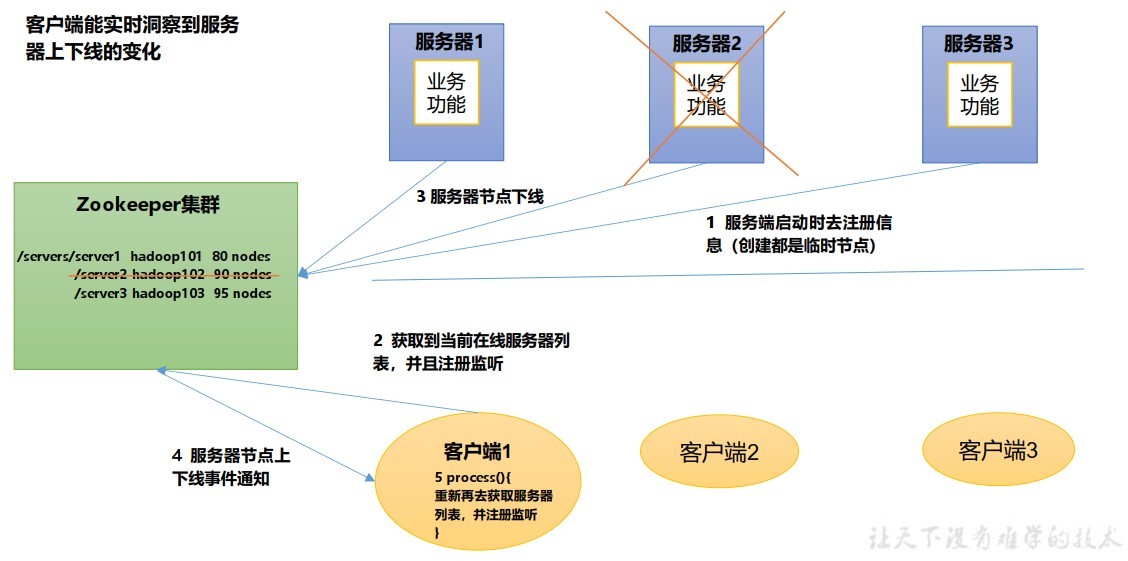
- 服務器動態上下線
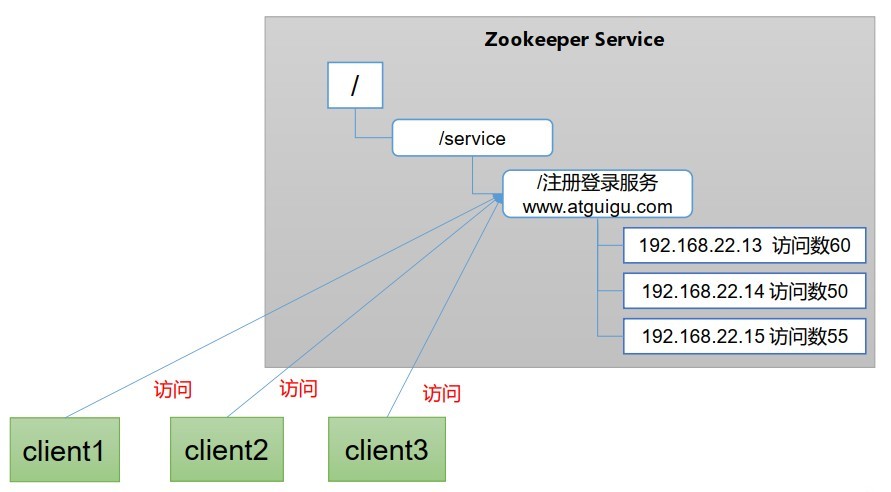
- 負載均衡:在Zookeeper中記錄每臺服務器的訪問數,讓訪問數最少的服務器去處理最新的客戶daunt請求
2、Zookeeper操作
2.1、簡單操作:
1、啟動Zookeeper:
[root@192 zookeeper-3.5.7]# bin/zkServer.sh start
2、查看行程是否啟動
[root@192 zookeeper-3.5.7]# jps
102109 Jps
20286 QuorumPeerMain
3、查看狀態
[root@192 zookeeper-3.5.7]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: standalone
4、啟動客戶端
[root@192 zookeeper-3.5.7]# bin/zkCli.sh
5、退出客戶端
[zk: localhost:2181(CONNECTED) 0] quit
6、停止Zookeeper
[root@192 zookeeper-3.5.7]# bin/zkServer.sh stop
2.2、配置引數解讀
- Zookeeper中的組態檔zoo.cfg中引數含義解讀如下 :
- tickTime = 2000: 通信心跳時間, Zookeeper服務器與客戶端心跳時間,單位毫秒
- initLimit = 10: LF初始通信時限 :Leader和Follower初始連接時能容忍的最多心跳數(tickTime的數量)
- syncLimit = 5: LF同步通信時限 :Leader和Follower之間通信時間如果超過syncLimit * tickTime, Leader認為Follwer死
掉,從服務器串列中洗掉Follwer - dataDir: 保存Zookeeper中的資料 ,注意: 默認的tmp目錄,容易被Linux系統定期洗掉,所以一般不用默認的tmp目錄,
- clientPort = 2181:客戶端連接埠,通常不做修改,
3、Zookeeper 集群操作
3.1、集群操作
3.1.1、集群安裝
-
集群規劃:在 hadoop102、 hadoop103 和 hadoop104 三個節點上都部署 Zookeeper,
- 思考:如果是 10 臺服務器,需要部署多少臺 Zookeeper?
-
解壓安裝
1、在 hadoop102 解壓 Zookeeper 安裝包到/opt/module/目錄下 :
[192@hadoop102 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
? 2、修改 apache-zookeeper-3.5.7-bin 名稱為 zookeeper-3.5.7
[192@hadoop102 module]$ mv apache-zookeeper-3.5.7-bin/zookeeper-3.5.7
-
配置服務器編號
1、在/opt/module/zookeeper-3.5.7/這個目錄下創建 zkData
[192@hadoop102 zookeeper-3.5.7]$ mkdir zkData
? 2、在/opt/module/zookeeper-3.5.7/zkData 目錄下創建一個 myid 的檔案
[192@hadoop102 zkData]$ vi myid
? 在檔案中添加與 server 對應的編號(注意:上下不要有空行,左右不要有空格)
2
? 注意: 添加 myid 檔案,一定要在 Linux 里面創建,在 notepad++里面很可能亂碼
? 3、拷貝配置好的 zookeeper 到其他機器上
[192@hadoop102 module ]$ xsync zookeeper-3.5.7
? 并分別在 hadoop103、 hadoop104 上修改 myid 檔案中內容為 3、 4
-
配置zoo.cfg檔案
1、重命名/opt/module/zookeeper-3.5.7/conf 這個目錄下的 zoo_sample.cfg 為 zoo.cfg
[192@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
? 2、打開 zoo.cfg 檔案
[192@hadoop102 conf]$ vim zoo.cfg
? #修改資料存盤路徑配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
? #增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
? 3、配置引數解讀
server.A=B:C:D,
A 是一個數字,表示這個是第幾號服務器;
集群模式下配置一個檔案 myid, 這個檔案在 dataDir 目錄下,這個檔案里面有一個資料就是 A 的值, Zookeeper 啟動時讀取此檔案,拿到里面的資料與 zoo.cfg 里面的配置資訊比較從而判斷到底是哪個 server,
B 是這個服務器的地址;
C 是這個服務器 Follower 與集群中的 Leader 服務器交換資訊的埠;
D 是萬一集群中的 Leader 服務器掛了,需要一個埠來重新進行選舉,選出一個新的
Leader,而這個埠就是用來執行選舉時服務器相互通信的埠,
? 4、同步 zoo.cfg 組態檔
[192@hadoop102 conf]$ xsync zoo.cfg
-
集群操作
1、分別啟動 Zookeeper
[192@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[192@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[192@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start
? 2、查看狀態
[192@hadoop102 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower
[192@hadoop103 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: leader
[192@hadoop104 zookeeper-3.4.5]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower
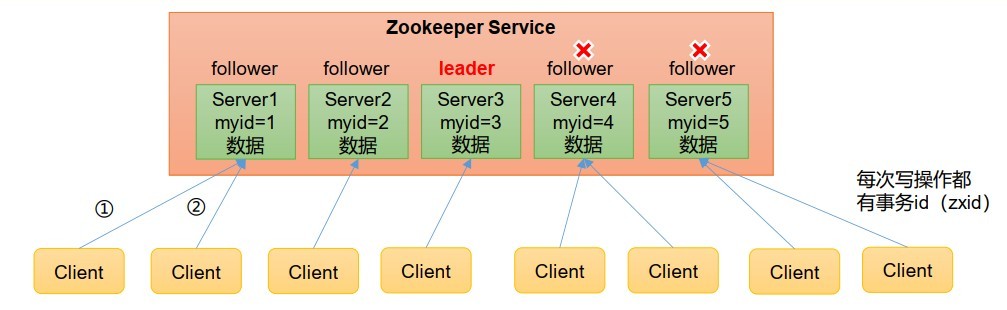
3.1.2 選舉機制
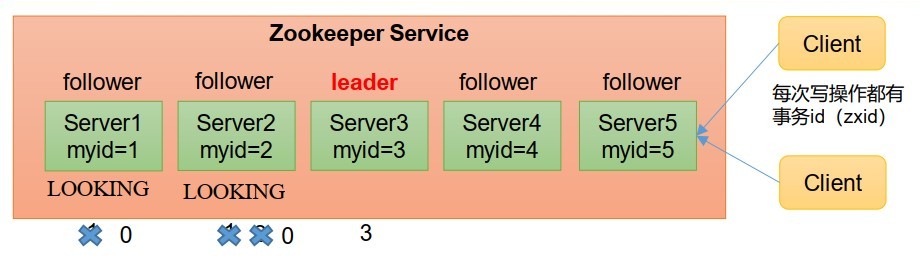
- 第一次啟動
- 服務器1啟動,發起一次選舉,服務器1投自己一票,此時服務器1票數一票,不夠半數以上(3票),選舉無法完成,服務器1狀態保持為 LOOKING;
- 服務器2啟動,在發起一次選舉,服務器1和2分別投自己一票并交換選票資訊:此時服務器1發現服務器2的myid比自己目前投票推舉的(服務器1)大,更改選票為推舉服務器2,此時服務器1票數0票,服務器2票數2票,沒有半數以上結果,選舉無法完成,服務器1和2保持狀態LOOKING,
- 服務器3啟動,發起一次選舉,此時服務器1和2都會更改選票為服務器3.此次投票結果:服務器1為0票,服務器2為0票,服務器3為3票,此時服務器3的票數已經超過半數,服務器3當選Leader,服務器1,2更改狀態為FOLLOWING,服務器3更改狀態為LEADING,
- 服務器4啟動,發起一次選舉,此時服務器1,2,3已經不是LOOKING狀態,不會更改選票資訊,交換選票結果:服務器3位3票,服務器4為1票,此時服務器4服從多數,更改選票資訊為服務器3,并更改狀態為FOLLOING,
- 服務器5啟動,同4一樣當小弟,
SID:服務器ID,用來唯一標識一臺Zookeeper集群中的機器,每臺機器不能重復,和myid一致,
ZXID:事務ID,ZXID是一個事務ID,用來表示一次服務器狀態的變更,在某一時刻,集群中的每臺機器的ZXID值不一定完全一致,這和Zookeeper服務器對于客戶端“更新請求”的處理邏輯有關,
Epoch:每個Leader任期的代號,沒有Leader時同一輪投票程序中的邏輯時鐘值是相同的,每投完一次票這個資料就會增加,
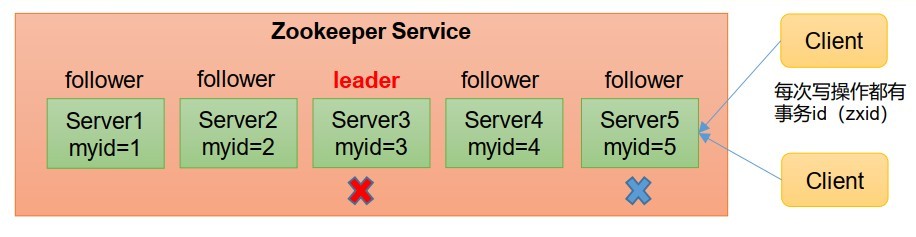
- 非第一次啟動
- 當Zookeeper集群中的一臺服務器出現以下兩種情況之一時,就會開始進入Leader選舉:
- 服務器初始化啟動
- 服務器運行期間無法和Leader保持連接
- 而當一臺機器進入Leader選舉流程時,當前集群也可能會處于以下兩種狀態:
- 集群中本來就已經存在一個Leader:機器試圖去選舉Leader時,會被告知當前服務器的Leader資訊,對于該機器來說, 僅僅需要和Leader機器建立連接,并進行狀態同步即可,
- 集群中確實不存在Leader:假設Zookeeper由5臺服務器組成,SID分別為1、2、3、4、5,ZXID分別為8、8、8、7、7,并且此時SID為3的服務器是Leader,某一時刻3和5服務器出現故障,因此開始進行Leader選舉,選舉規則:1、EPOCH大的直接勝出,2、EPOCH相同,事務id大的勝出,3、事務id相同,服務器id大的勝出,
- 當Zookeeper集群中的一臺服務器出現以下兩種情況之一時,就會開始進入Leader選舉:
3.1.3 ZK 集群啟動停止腳本
- 在 hadoop102 的/home/ktf/bin 目錄下創建腳本
[192@hadoop102 bin]$ vim zk.sh
? 在腳本中撰寫如下內容
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 啟動 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh
start"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh
stop"
done
};;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 狀態 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh
status"
done
};;
esac
- 增加腳本執行權限
[192@hadoop102 bin]$ chmod u+x zk.sh
- Zookeeper 集群啟動腳本
[192@hadoop102 module]$ zk.sh start
- Zookeeper 集群停止腳本
[192@hadoop102 module]$ zk.sh stop
3.2、客戶端命令列操作
3.2.1、命令列基本語法
| 命令基本語法 | 功能描述 |
|---|---|
| help | 顯示所有操作命令 |
| ls path | 使用 ls 命令來查看當前 znode 的子節點 [可監聽] |
| -w 監聽子節點變化 | |
| -s 附加次級資訊 | |
| create | 普通創建 |
| -s 含有序列 | |
| -e 臨時(重啟或者超時消失) | |
| get path | 獲得節點的值 [可監聽] |
| -w 監聽節點內容變化 | |
| -s 附加次級資訊 | |
| set | 設定節點的具體值 |
| stat | 查看節點狀態 |
| delete | 洗掉節點 |
| deleteall | 遞回洗掉節點 |
- 啟動客戶端
[192@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh -server hadoop102:2181
- 顯示所有操作命令
[zk: hadoop102:2181(CONNECTED) 1] help
3.2.2 znode 節點資料資訊
- 查看當前znode中所包含的內容
[zk: hadoop102:2181(CONNECTED) 0] ls /
[zookeeper]
- 查看當前節點詳細資料
[zk: hadoop102:2181(CONNECTED) 5] ls -s /
[zookeeper]cZxid = 0x0 // 創建節點的事務 zxid
ctime = Thu Jan 01 08:00:00 CST 1970 //znode 被創建的毫秒數(從 1970 年開始)
mZxid = 0x0 // znode 最后更新的事務 zxid
mtime = Thu Jan 01 08:00:00 CST 1970 // znode 最后修改的毫秒數(從 1970 年開始)
pZxid = 0x0 // znode 最后更新的子節點 zxid
cversion = -1 // znode 子節點變化號, znode 子節點修改次數
dataVersion = 0 // znode 資料變化號
aclVersion = 0 // znode 訪問控制串列的變化號
ephemeralOwner = 0x0 // 如果是臨時節點,這個是 znode 擁有者的 session id,如果不是臨時節點則是 0,
dataLength = 0 // znode 的資料長度
numChildren = 1 // znode 子節點數量
3.2.3 節點型別(持久/短暫/有序號/無序號)
- 持久(Persistent):客戶端和服務器斷開連接后,創建的節點不洗掉
- 短暫(Ephemeral):客戶端和服務器斷開連接后,創建的節點自己洗掉
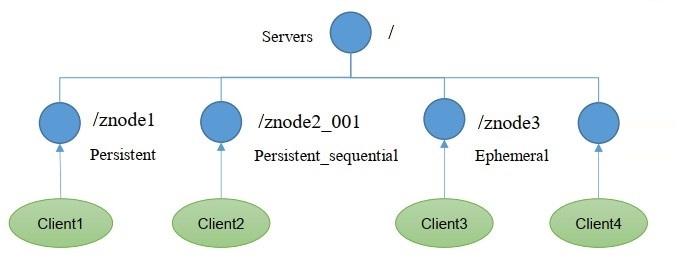
- 持久化目錄節點:客戶端與Zookeeper斷開連接后,該節點依舊存在
- 持久化順序編號目錄節點:客戶端與Zookeeper斷開連接后,該節點依舊存在,只是Zookeeper給 該節點名稱進行順序編號
- 臨時目錄節點:客戶端與Zookeeper斷開連接后,該節點被洗掉
- 臨時順序編號目錄節點:客戶端與Zookeeper斷開連接后,該節點被洗掉,只是Zookeeper給該節點名稱進行順序編號,
說明:創建Znode時設定順序表示,Znode名稱后會附加一個值,順序號是一個單調遞增的計數器,由父節點維護,
注意:在分布式系統中,順序號可以被用于為所有的事件進行全域排序,這樣客戶端可以通過順序號推斷事件的順序,
1、分別創建2個普通節點(永久節點 + 不帶序號)
[zk: localhost:2181(CONNECTED) 3] create /sanguo "diaochan"
Created /sanguo
[zk: localhost:2181(CONNECTED) 4] create /sanguo/shuguo "liubei"
Created /sanguo/shuguo
注意:創建節點時, 要賦值
2、獲得節點的值
[zk: localhost:2181(CONNECTED) 5] get -s /sanguo
diaochan
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000003
mtime = Wed Aug 29 00:03:23 CST 2018
pZxid = 0x100000004
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 1
[zk: localhost:2181(CONNECTED) 6] get -s /sanguo/shuguo
liubei
cZxid = 0x100000004
ctime = Wed Aug 29 00:04:35 CST 2018
mZxid = 0x100000004
mtime = Wed Aug 29 00:04:35 CST 2018
pZxid = 0x100000004
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0
3、創建帶序號的節點(永久節點 + 帶序號)
- 先創建一個普通的根節點/sanguo/weiguo
[zk: localhost:2181(CONNECTED) 1] create /sanguo/weiguo "caocao"
Created /sanguo/weiguo
- 創建帶序號的節點
[zk: localhost:2181(CONNECTED) 2] create -s /sanguo/weiguo/zhangliao "zhangliao"
Created /sanguo/weiguo/zhangliao0000000000
[zk: localhost:2181(CONNECTED) 3] create -s /sanguo/weiguo/zhangliao "zhangliao"
Created /sanguo/weiguo/zhangliao0000000001
[zk: localhost:2181(CONNECTED) 4] create -s /sanguo/weiguo/xuchu "xuchu"
Created /sanguo/weiguo/xuchu0000000002
如果原來沒有序號節點,序號從 0 開始依次遞增, 如果原節點下已有 2 個節點,則再排序時從 2 開始,以此類推,
4、創建短暫節點(短暫節點 + 不帶序號 or 帶序號)
- 創建短暫的不帶序號的節點
[zk: localhost:2181(CONNECTED) 7] create -e /sanguo/wuguo "zhouyu"
Created /sanguo/wuguo
- 創建短暫的帶序號的節點
[zk: localhost:2181(CONNECTED) 2] create -e -s /sanguo/wuguo "zhouyu"
Created /sanguo/wuguo0000000001
- 在當前客戶端是能查看到的
[zk: localhost:2181(CONNECTED) 3] ls /sanguo
[wuguo, wuguo0000000001, shuguo]
- 退出當前客戶端然后再重啟客戶端
[zk: localhost:2181(CONNECTED) 12] quit
[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkCli.sh
- 再次查看根目錄下短暫節點已經洗掉
[zk: localhost:2181(CONNECTED) 0] ls /sanguo
[shuguo]
- 修改節點資料值
[zk: localhost:2181(CONNECTED) 6] set /sanguo/weiguo "simayi"
3.2.4 監聽器原理
-
客戶端注冊監聽它關心的目錄節點,當目錄節點發生變化(資料改變、節點洗掉、子目錄節點增加洗掉)時, ZooKeeper 會通知客戶端,監聽機制保證 ZooKeeper 保存的任何的資料的任何改變都能快速的回應到監聽了該節點的應用程式
-
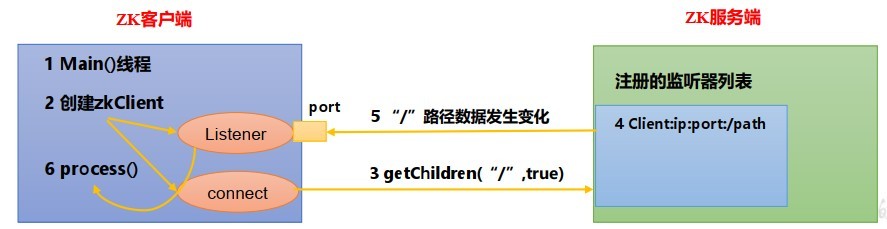
監聽器詳解:
- 首先要有一個main()執行緒
- 在main執行緒中創建Zookeeper客戶端,這時就會創建兩個執行緒,一個負責網路連接通信(connet),一個負責監聽(listener),
- 通過connect執行緒將注冊的監聽事件發送給Zookeeper,
- 在Zookeeper的注冊監聽串列中將注冊監聽事件添加到串列中,
- Zookeeper監聽到有資料或路徑變化,就會將這個訊息發送給listener執行緒,
- listener執行緒內部呼叫了process()方法,
-
常見的監聽
- 監聽節點資料的變化:get path [watch]
- 監聽子節點增減的變化:ls path [watch]
1、節點的值變化監聽
- 在hadoop104 主機上注冊監聽/sanguo 節點資料變化
[zk: localhost:2181(CONNECTED) 26] get -w /sanguo
- 在 hadoop103 主機上修改/sanguo 節點的資料
[zk: localhost:2181(CONNECTED) 1] set /sanguo "xisi
- 觀察 hadoop104 主機收到資料變化的監聽
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged
path:/sanguo
注意:在hadoop103再多次修改/sanguo的值, hadoop104上不會再收到監聽,因為注冊一次,只能監聽一次,想再次監聽,需要再次注冊
2、節點的子節點變化監聽(路徑變化)
- 在 hadoop104 主機上注冊監聽/sanguo 節點的子節點變化
[zk: localhost:2181(CONNECTED) 1] ls -w /sanguo
[shuguo, weiguo]
- 在 hadoop103 主機/sanguo 節點上創建子節點
[zk: localhost:2181(CONNECTED) 2] create /sanguo/jin "simayi"
Created /sanguo/jin
- 觀察 hadoop104 主機收到子節點變化的監聽
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged
path:/sanguo
注意: 節點的路徑變化,也是注冊一次,生效一次,想多次生效,就需要多次注冊,
3.2.5 節點洗掉與查看
- 洗掉節點
[zk: localhost:2181(CONNECTED) 4] delete /sanguo/jin
- 遞回洗掉節點
[zk: localhost:2181(CONNECTED) 15] deleteall /sanguo/shuguo
- 查看節點狀態
[zk: localhost:2181(CONNECTED) 17] stat /sanguo
cZxid = 0x100000003
ctime = Wed Aug 29 00:03:23 CST 2018
mZxid = 0x100000011
mtime = Wed Aug 29 00:21:23 CST 2018
pZxid = 0x100000014
cversion = 9
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 4
numChildren = 1
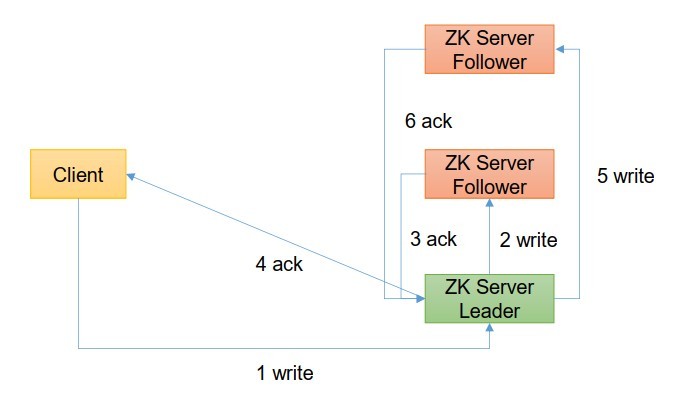
3.3 客戶端向服務端寫資料流程
- 寫流程之寫入請求直接發送給Leader節點
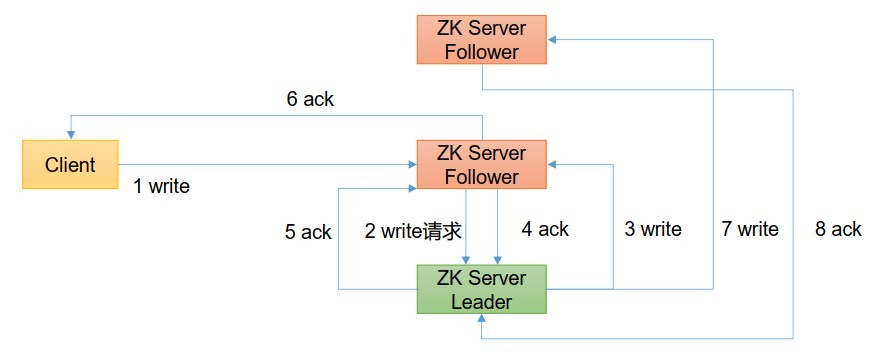
- 寫流程之寫入請求發送給follower節點
4、ZooKeeper 分布式鎖
1、概述
- 什么叫做分布式鎖呢?
- 比如說"行程 1"在使用該資源的時候,會先去獲得鎖, "行程 1"獲得鎖以后會對該資源 保持獨占,這樣其他行程就無法訪問該資源, "行程 1"用完該資源以后就將鎖釋放掉,讓其他行程來獲得鎖,那么通過這個鎖機制,我們就能保證了分布式系統中多個行程能夠有序的訪問該臨界資源,那么我們把這個分布式環境下的這個鎖叫作分布式鎖,
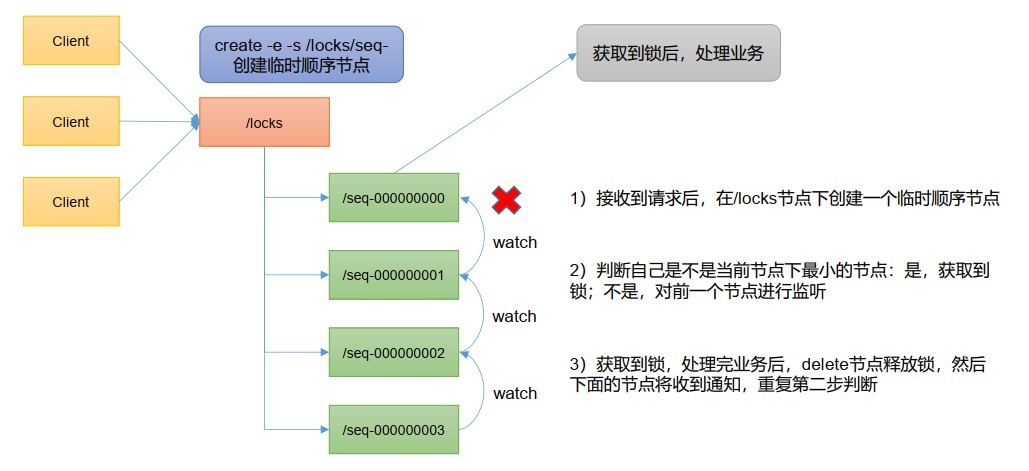
2、原生 Zookeeper 實作分布式鎖案例
- 原生 Zookeeper 實作分布式鎖案例
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public class DistributedLock {
// zookeeper server 串列
private String connectString ="hadoop102:2181,hadoop103:2181,hadoop104:2181";
// 超時時間
private int sessionTimeout = 2000;
private ZooKeeper zk;
private String rootNode = "locks";
private String subNode = "seq-";
// 當前 client 等待的子節點
private String waitPath;
//ZooKeeper 連接
private CountDownLatch connectLatch = new CountDownLatch(1);
//ZooKeeper 節點等待
private CountDownLatch waitLatch = new CountDownLatch(1);
// 當前 client 創建的子節點
private String currentNode;
// 和 zk 服務建立連接,并創建根節點
public DistributedLock() throws IOException,
InterruptedException, KeeperException {
zk = new ZooKeeper(connectString, sessionTimeout, new
Watcher() {
@Override
public void process(WatchedEvent event) {
// 連接建立時, 打開 latch, 喚醒 wait 在該 latch 上的執行緒
if (event.getState() ==
Event.KeeperState.SyncConnected) {
connectLatch.countDown();
}
// 發生了 waitPath 的洗掉事件
if (event.getType() ==
Event.EventType.NodeDeleted && event.getPath().equals(waitPath))
{
waitLatch.countDown();
}
}
});
// 等待連接建立
connectLatch.await();
//獲取根節點狀態
Stat stat = zk.exists("/" + rootNode, false);
//如果根節點不存在,則創建根節點,根節點型別為永久節點
if (stat == null) {
System.out.println("根節點不存在");
zk.create("/" + rootNode, new byte[0],
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
// 加鎖方法
public void zkLock() {
try {
//在根節點下創建臨時順序節點,回傳值為創建的節點路徑
currentNode = zk.create("/" + rootNode + "/" + subNode,
null, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
// wait 一小會, 讓結果更清晰一些
Thread.sleep(10);
// 注意, 沒有必要監聽"/locks"的子節點的變化情況
List<String> childrenNodes = zk.getChildren("/" +
rootNode, false);
// 串列中只有一個子節點, 那肯定就是 currentNode , 說明
client 獲得鎖
if (childrenNodes.size() == 1) {
return;
} else {
//對根節點下的所有臨時順序節點進行從小到大排序
Collections.sort(childrenNodes);
//當前節點名稱
String thisNode = currentNode.substring(("/" +
rootNode + "/").length());
//獲取當前節點的位置
int index = childrenNodes.indexOf(thisNode);
if (index == -1) {
System.out.println("資料例外");
} else if (index == 0) {
// index == 0, 說明 thisNode 在串列中最小, 當前
client 獲得鎖
return;
} else {
// 獲得排名比 currentNode 前 1 位的節點
this.waitPath = "/" + rootNode + "/" +
childrenNodes.get(index - 1);
// 在 waitPath 上注冊監聽器, 當 waitPath 被洗掉時,
zookeeper 會回呼監聽器的 process 方法
zk.getData(waitPath, true, new Stat());
//進入等待鎖狀態
waitLatch.await();
return;
}
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 解鎖方法
public void zkUnlock() {
try {
zk.delete(this.currentNode, -1);
} catch (InterruptedException | KeeperException e) {
e.printStackTrace();
}
}
}
- 分布式鎖測驗
import org.apache.zookeeper.KeeperException;
import java.io.IOException;
public class DistributedLockTest {
public static void main(String[] args) throws
InterruptedException, IOException, KeeperException {
// 創建分布式鎖 1
final DistributedLock lock1 = new DistributedLock();
// 創建分布式鎖 2
final DistributedLock lock2 = new DistributedLock();
new Thread(new Runnable() {
@Override
public void run() {
// 獲取鎖物件
try {
lock1.zkLock();
System.out.println("執行緒 1 獲取鎖");
Thread.sleep(5 * 1000);
lock1.zkUnlock();
System.out.println("執行緒 1 釋放鎖");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
// 獲取鎖物件
try {
lock2.zkLock();
System.out.println("執行緒 2 獲取鎖");
Thread.sleep(5 * 1000);
lock2.zkUnlock();
System.out.println("執行緒 2 釋放鎖");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
- 輸出:
執行緒 1 獲取鎖
執行緒 1 釋放鎖
執行緒 2 獲取鎖
執行緒 2 釋放鎖
3、Curator 框架實作分布式鎖
- 原生的 Java API 開發存在的問題 :
- 會話連接是異步的,需要自己去處理,比如使用 CountDownLatch
- Watch 需要重復注冊,不然就不能生效
- 開發的復雜性還是比較高的
- 不支持多節點洗掉和創建,需要自己去遞回
- Curator 是一個專門解決分布式鎖的框架,解決了原生 Java API 開發分布式遇到的問題
- Curator 案例實操 :
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessLock;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
public class CuratorLockTest {
private String rootNode = "/locks";
// zookeeper server 串列
private String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
// connection 超時時間
private int connectionTimeout = 2000;
// session 超時時間
private int sessionTimeout = 2000;
public static void main(String[] args) {
new CuratorLockTest().test();
}
// 測驗
private void test() {
// 創建分布式鎖 1
final InterProcessLock lock1 = new
InterProcessMutex(getCuratorFramework(), rootNode);
// 創建分布式鎖 2
final InterProcessLock lock2 = new
InterProcessMutex(getCuratorFramework(), rootNode);
new Thread(new Runnable() {
@Override
public void run() {
// 獲取鎖物件
try {
lock1.acquire();
System.out.println("執行緒 1 獲取鎖");
// 測驗鎖重入
lock1.acquire();
System.out.println("執行緒 1 再次獲取鎖");
Thread.sleep(5 * 1000);
lock1.release();
System.out.println("執行緒 1 釋放鎖");
lock1.release();
System.out.println("執行緒 1 再次釋放鎖");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
// 獲取鎖物件
try {
lock2.acquire();
System.out.println("執行緒 2 獲取鎖");
// 測驗鎖重入
lock2.acquire();
System.out.println("執行緒 2 再次獲取鎖");
Thread.sleep(5 * 1000);
lock2.release();
System.out.println("執行緒 2 釋放鎖");
lock2.release();
System.out.println("執行緒 2 再次釋放鎖");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
// 分布式鎖初始化
public CuratorFramework getCuratorFramework (){
//重試策略,初試時間 3 秒,重試 3 次
RetryPolicy policy = new ExponentialBackoffRetry(3000, 3);
//通過工廠創建 Curator
CuratorFramework client =
CuratorFrameworkFactory.builder()
.connectString(connectString)
.connectionTimeoutMs(connectionTimeout)
.sessionTimeoutMs(sessionTimeout)
.retryPolicy(policy).build();
//開啟連接
client.start();
System.out.println("zookeeper 初始化完成...");
return client;
}
}
- 觀察控制臺變化:
執行緒 1 獲取鎖
執行緒 1 再次獲取鎖
執行緒 1 釋放鎖
執行緒 1 再次釋放鎖
執行緒 2 獲取鎖
執行緒 2 再次獲取鎖
執行緒 2 釋放鎖
執行緒 2 再次釋放鎖
5、Zookeeper原始碼分析
1、Paxos演算法
- Paxos演算法:一種基于訊息傳遞且具備高度容錯特性的一致性演算法,
- Paxos演算法解決的問題:就是如何快速正確的在一個分布式系統中對某個資料值達成一致,并且保證無論發生任何例外都不會破壞整個系統的一致性,
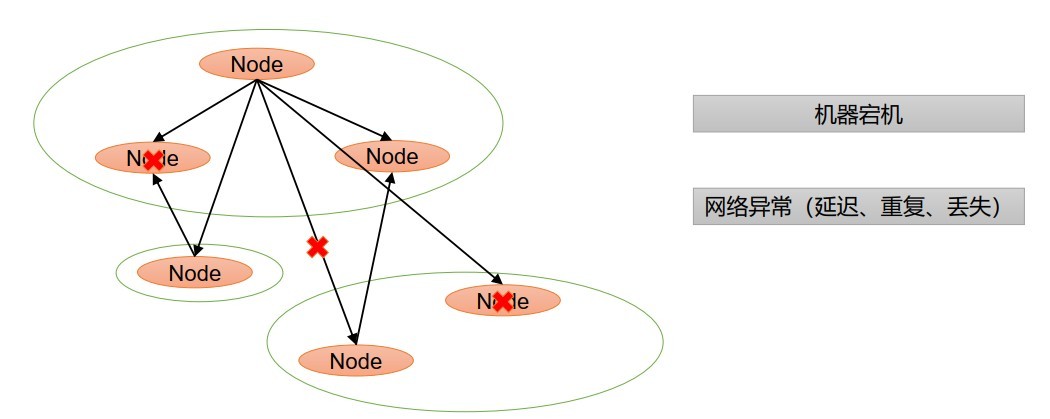
- 在一個Paxos系統中,首先將所有節點劃分為Proposer(提議者),Acceptor(接收者),和Learner(學習者),(注意:每個節點都可以身兼數職)
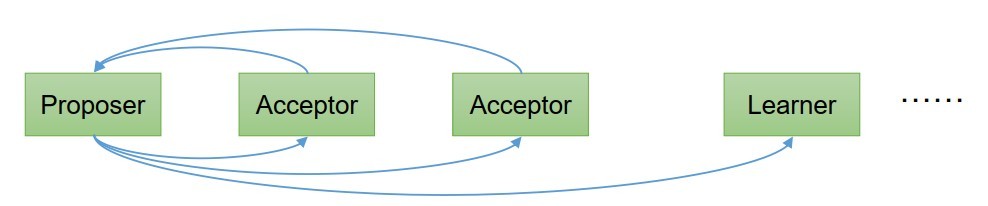
- 一個完整的Paxos演算法流程分為三個階段:
- Prepare準備階段:Proposer向多個Acceptor發出Propose請求Promise(承諾),Acceptor針對收到的Propose請求進行Promise(承諾)
- Accept接受階段:Proposer收到多數Acceptor承諾的Promise后,向Acceptor發出Propose請求,Acceptor針對收到的Propose請求進行Accept處理
- Learn學習階段:Propose將形成的決議發送給所有Learners

- 演算法流程
- Prepare: Proposer生成全域唯一且遞增的Proposal ID,向所有Acceptor發送Propose請求,這里無需攜帶提案內容,只攜帶Proposal ID即可,
- Promise:Acceptor收到Propose請求后,做出“兩個承諾,一個應答”,
- 不再接受Proposal ID小于等于(注意:這里是<=)當前請求的Propose請求,
- 不再接受Proposal ID小于(注意:這里是< )當前請求的Accept請求,
- 不違背以前做出的承諾下,回復已經Accept過的提案中Proposal ID最大的那個提案的Value和Proposal ID,沒有則回傳空值,
- Propose: Proposer收到多數Acceptor的Promise應答后,從應答中選擇Proposal ID最大的提案的Value,作為本次要發起的提案,如果所有應答的提案Value均為空值,則可以自己隨意決定提案Value,然后攜帶當前Proposal ID,向所有Acceptor發送 Propose請求,
- Accept: Acceptor收到Propose請求后,在不違背自己之前做出的承諾下,接受并持久化當前Proposal ID和提案Value,
- Learn: Proposer收到多數Acceptor的Accept后,決議形成,將形成的決議發送給所有Learner,
- 下面我們針對上述描述做三種情況的推演舉例:為了簡化流程,我們這里不設定 Learner,

- 情況1:有A1、A2、A3、A4、A5 5位議員,就稅率問題進行決議,
- A1發起1號Proposal的Propose,等待Promise承諾;
- A2-A5回應Promise
- A1在收到兩份回復時就會發起稅率10%的Proposal;
- A2-A5回應Accept
- 通過Proposal,稅率10%,

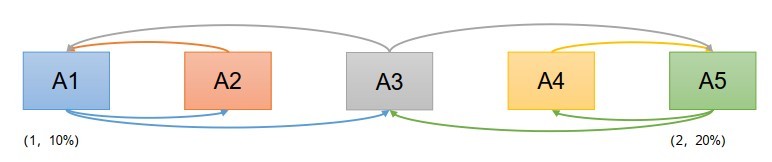
- 情況2:現在我們假設在A1提出提案的同時,A5決定將稅率定為20%
- A1, A5同時發起Propose(序號分別為1, 2)
- A2承諾A1, A4承諾A5, A3行為成為關鍵
- 情況1: A3先收到A1訊息,承諾A1,
- A1發起Proposal(1, 10%), A2, A3接受,
- 之后A3又收到A5訊息, 回復A1: (1, 10%),并承諾A5,
- A5發起Proposal(2, 20%), A3, A4接受,之后A1, A5同時廣播決議,
-
現在我們假設在A1提出提案的同時, A5決定將稅率定為20%
- A1, A5同時發起Propose(序號分別為1, 2)
- A2承諾A1, A4承諾A5, A3行為成為關鍵
- 情況2: A3先收到A1訊息,承諾A1,之后立刻收到A5訊息,承諾A5,
- A1發起Proposal(1, 10%),無足夠回應, A1重新Propose (序號3), A3再次承諾A1,
- A5發起Proposal(2, 20%),無足夠相應, A5重新Propose (序號4), A3再次承諾A5,
- ……
-
造成這種情況的原因是系統中有一個以上的 Proposer,多個 Proposers 相互爭奪 Acceptor,造成遲遲無法達成一致的情況, 針對這種情況,一種改進的 Paxos 演算法被提出:從系統中選出一個節點作為 Leader,只有 Leader 能夠發起提案, 這樣,一次 Paxos 流程中只有一個Proposer,不會出現活鎖的情況,此時只會出現例子中第一種情況,
-
Paxos 演算法缺陷:在網路復雜的情況下,一個應用 Paxos 演算法的分布式系統,可能很久無法收斂,甚至陷入活鎖的情況,
2、ZAB 協議
-
什么是 ZAB 演算法 :Zab 借鑒了 Paxos 演算法,是特別為 Zookeeper 設計的支持崩潰恢復的原子廣播協議,基于該協議, Zookeeper 設計為只有一臺客戶端(Leader)負責處理外部的寫事務請求,然后Leader 客戶端將資料同步到其他 Follower 節點, 即 Zookeeper 只有一個 Leader 可以發起提案 ,
-
Zab 協議包括兩種基本的模式: 訊息廣播、 崩潰恢復 ,
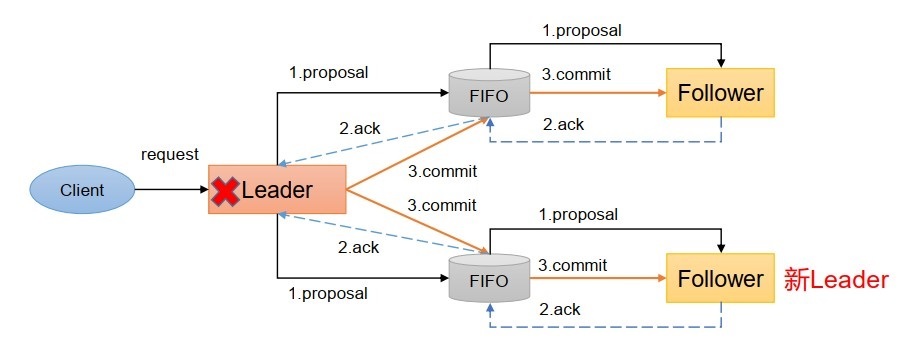
2.1、訊息廣播
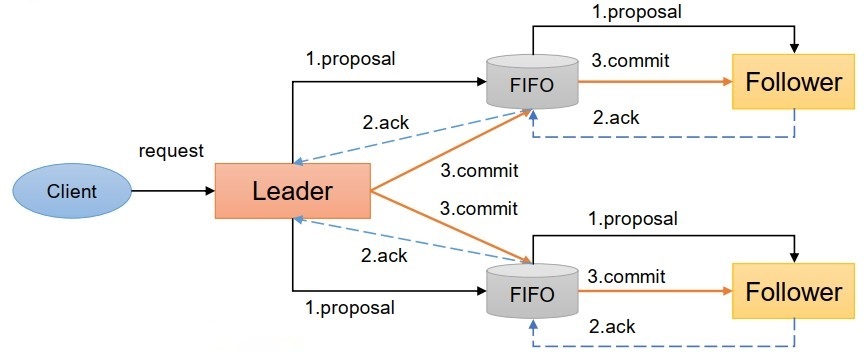
-
客戶端發起一個寫操作請求,
-
Leader服務器將客戶端的請求轉化為事務Proposal 提案, 同時為每個Proposal 分配一個全域的ID, 即zxid,
-
Leader服務器為每個Follower服務器分配一個單獨的佇列, 然后將需要廣播的 Proposal依次放到佇列中去, 并且根據FIFO策略進行訊息發送,
-
Follower接收到Proposal后, 會首先將其以事務日志的方式寫入本地磁盤中, 寫入成功后向Leader反饋一個Ack回應訊息,
-
Leader接收到超過半數以上Follower的Ack回應訊息后, 即認為訊息發送成功, 可以發送commit訊息,
-
Leader向所有Follower廣播commit訊息, 同時自身也會完成事務提交, Follower 接收到commit訊息后, 會將上一條事務提交,
-
Zookeeper采用Zab協議的核心, 就是只要有一臺服務器提交了Proposal, 就要確保所有的服務器最終都能正確提交Proposal,
-
ZAB協議針對事務請求的處理程序類似于一個兩階段提交程序
- 廣播事務階段
- 廣播提交操作
-
這兩階段提交模型如下, 有可能因為Leader宕機帶來資料不一致, 比如
- Leader 發 起 一 個 事 務Proposal1 后 就 宕 機 , Follower 都 沒 有Proposal1
- Leader收到半數ACK宕機,沒來得及向Follower發送Commit
-
怎么解決呢?
- ZAB引入了崩潰恢復模式,
2.2、崩潰恢復
崩潰恢復——例外假設
- 一旦Leader服務器出現崩潰或者由于網路原因導致Leader服務器失去了與過半 Follower的聯系,那么就會進入崩潰恢復模式,
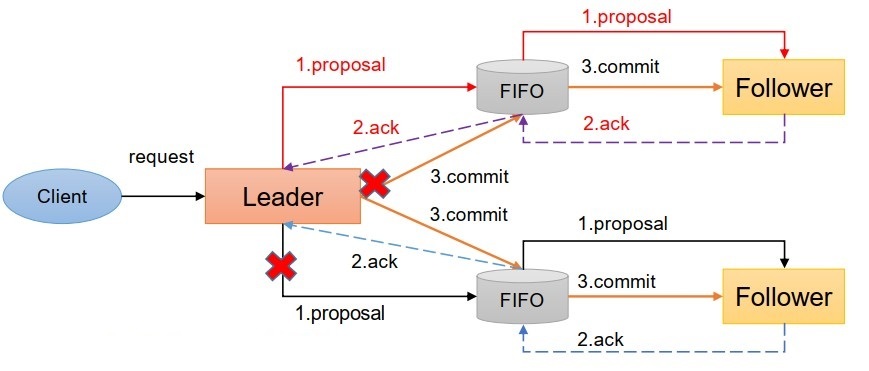
- 假設兩種服務器例外情況:
- 假設一個事務在Leader提出之后, Leader掛了,
- 一個事務在Leader上提交了, 并且過半的Follower都回應Ack了, 但是Leader在Commit訊息發出之前掛了,
- Zab協議崩潰恢復要求滿足以下兩個要求:
- 確保已經被Leader提交的提案Proposal, 必須最終被所有的Follower服務器提交, (已經產生的提案, Follower必須執行)
- 確保丟棄已經被Leader提出的, 但是沒有被提交的Proposal, (丟棄胎死腹中的提案)
崩潰恢復——Leader選舉
- 崩潰恢復主要包括兩部分: Leader選舉和資料恢復,
- Leader選舉: 根據上述要求, Zab協議需要保證選舉出來的Leader需要滿足以下條件:
- 新選舉出來的Leader不能包含未提交的Proposal, 即新Leader必須都是已經提交了Proposal的Follower服務器節點,
- 新選舉的Leader節點中含有最大的zxid, 這樣做的好處是可以避免Leader服務器檢查Proposal的提交和丟棄作業,
崩潰恢復——資料恢復
- 崩潰恢復主要包括兩部分: Leader選舉和資料恢復,
- Zab如何資料同步:
- 完成Leader選舉后, 在正式開始作業之前(接收事務請求, 然后提出新的Proposal) , Leader服務器會首先確認事務日
志中的所有的Proposal 是否已經被集群中過半的服務器Commit, - Leader服務器需要確保所有的Follower服務器能夠接收到每一條事務的Proposal, 并且能將所有已經提交的事務Proposal應用到記憶體資料中, 等到Follower將所有尚未同步的事務Proposal都從Leader服務器上同步過, 并且應用到記憶體資料中以后,Leader才會把該Follower加入到真正可用的Follower串列中,
- 完成Leader選舉后, 在正式開始作業之前(接收事務請求, 然后提出新的Proposal) , Leader服務器會首先確認事務日
3、CAP
- CAP理論告訴我們, 一個分布式系統不可能同時滿足以下三種
- 一致性(C:Consistency)
- 可用性(A:Available)
- 磁區容錯性( P:Partition Tolerance)
- 這三個基本需求, 最多只能同時滿足其中的兩項, 因為P是必須的, 因此往往選擇就在CP或者AP中,
- 一致性( C:Consistency)
- 在分布式環境中, 一致性是指資料在多個副本之間是否能夠保持資料一致的特性, 在一致性的需求下, 當一個系統在資料一致的狀態下執行更新操作后, 應該保證系統的資料仍然處于一致的狀態,
- 可用性(A:Available)
- 可用性是指系統提供的服務必須一直處于可用的狀態, 對于用戶的每一個操作請求總是能夠在有限的時間內回傳結果,
- 磁區容錯性( P:Partition Tolerance)
- 分布式系統在遇到任何網路磁區故障的時候, 仍然需要能夠保證對外提供滿足一致性和可用性的服務, 除非是整個網路
環境都發生了故障,
- 分布式系統在遇到任何網路磁區故障的時候, 仍然需要能夠保證對外提供滿足一致性和可用性的服務, 除非是整個網路
- ZooKeeper保證的是CP
- ZooKeeper不能保證每次服務請求的可用性, (注:在極端環境下, ZooKeeper可能會丟棄一些請求, 消費者程式需要
重新請求才能獲得結果) , 所以說, ZooKeeper不能保證服務可用性, - 進行Leader選舉時集群都是不可用 ,
- ZooKeeper不能保證每次服務請求的可用性, (注:在極端環境下, ZooKeeper可能會丟棄一些請求, 消費者程式需要
來自尚硅谷的學習筆記!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301912.html
標籤:其他