介紹
說起 Kafka 很多同學都知道,即使你沒有用過也知道,它是訊息佇列中數一數二的運動健將,他可以承載每秒鐘上百萬此的資料處理,但問什么 Kafka 可以這么快呢?
歸納原因主要有這四點原因,磁盤順序讀寫、頁快取、零拷貝、批量操作,
對比 RocketMQ
說到 Kafka 有一個話題我們無法回避,就是與其他訊息佇列的對比,這里我們以 RocketMQ 為例,Kafka 與 RocketMQ 有著完全不同的使用場景,
看下圖,RocketMQ 就行一個高壓水槍他的流速快橫截面積小,吞吐量不高處理速度快,而Kafaka 采用完全相反的設計橫截面積大,吞吐量高處理速度慢,

四大特點
1. 順序讀寫
為什么順序讀寫快呢,來看下面一篇測驗文章,有權威的測驗分別對機械硬碟、固態硬碟、記憶體進行隨機與順序讀寫測驗,
黃色為隨機讀寫,藍色為順序讀寫,可以看到隨機讀寫性能依次是機械硬碟、固態硬碟、記憶體,而順序讀寫機械硬碟反而強于固態硬碟,對于企業來說存盤空間SSD、記憶體是非常昂貴的,所以 Kafaka 在設計的時候也是根據這個進行來順序存盤的,

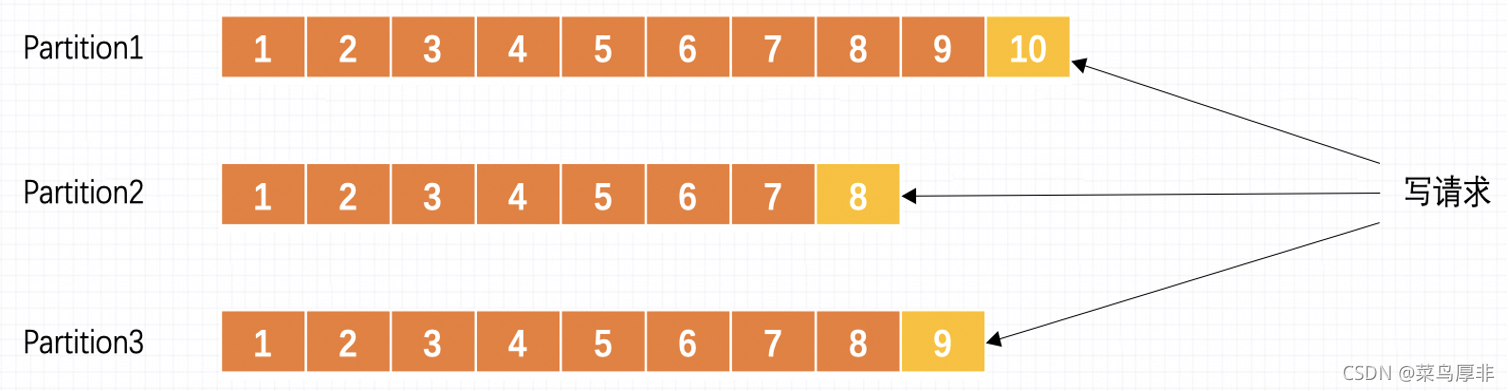
在 Kafka 中一個概念叫做 Partition ,磁區的意思用來存盤訊息,生產者生產的訊息都是從末尾進行添加,
這里設計到一個新的問題,就是消費過的訊息消費了之后進行洗掉不就破壞了訊息的順序關系了嗎,這里 Kafka 做了個折中的處理,不進行實時的訊息洗掉,而是在某個時間進行批量洗掉的,這個比單個洗掉效率要高,
2. 頁快取
頁快取相對來說比較簡單,頁快取在作業系統層面是保存資料的一個基本單位,Kafka 避免使用 JVM,直接使用作業系統的頁快取特性提高處理速度,進而避免了JVM GC 帶來的性能損耗,
3. 零拷貝
作為 Kafka 運行在 Linux 作業系統,作為 Linux 作業系統,它有一個特性叫做零拷貝,就是在用戶態與內核態不再發生拷貝,
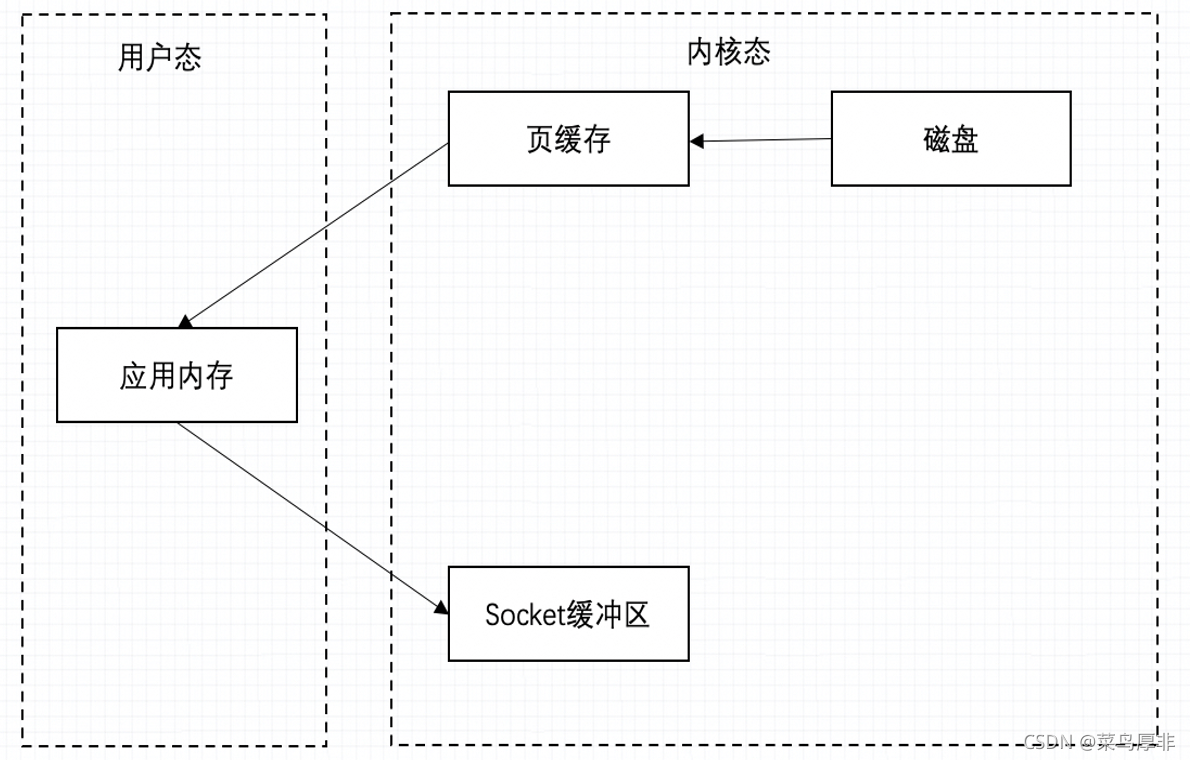
接下來我使用更加形象化進行解釋,來看下圖,假設現在有一條資料需要應用程式進行操作,但是他現在存盤在磁盤上,作業系統層面會將磁盤資訊加載到頁快取,之后再 copy 到應用層面的應用記憶體,需要發送的時候再加載到 socket 緩沖區,
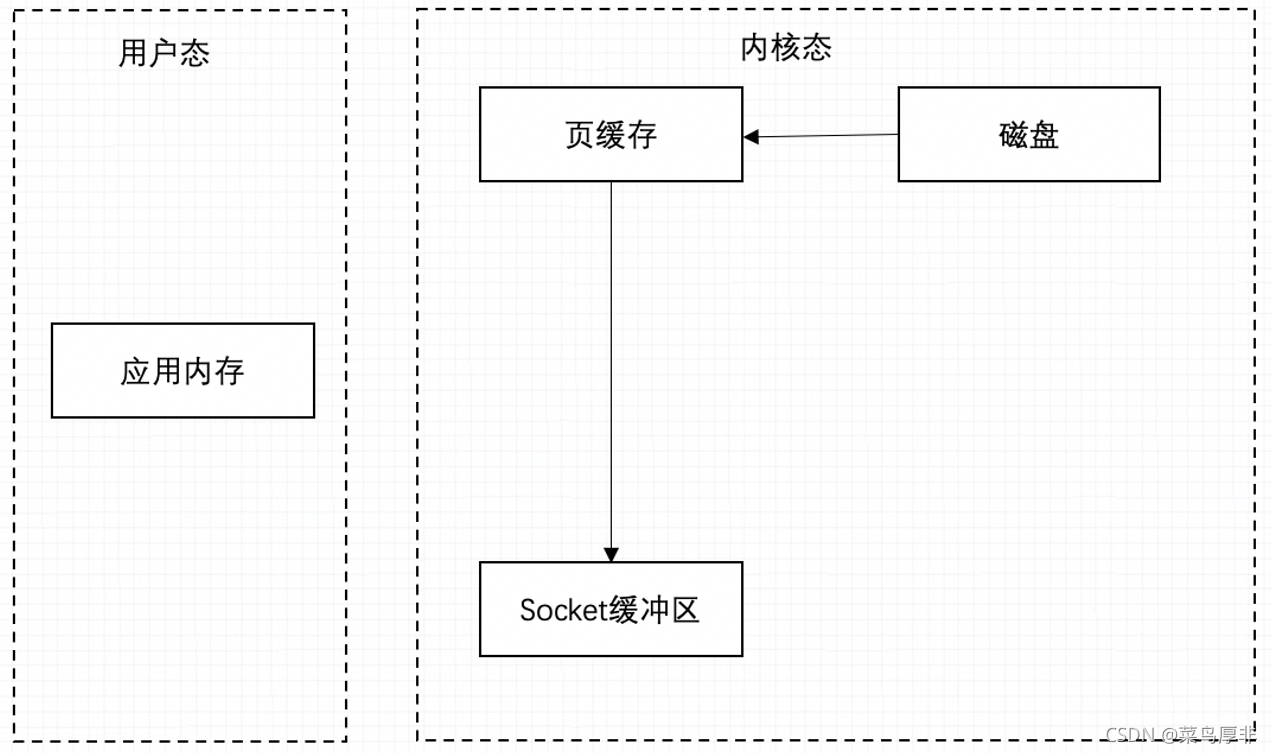
但 Kafka 不是這么做的,來看下圖,當資料需要操作會加載到內核態的頁快取中,需要發送是再加載到 socket 緩沖區中,其中就少了與用戶態之間的 copy 動作,如果再處理海量資料的時候,效率就提高了很多,
4. 批量操作

最后一個呢是批處理,同學可以想一下在 JDBC 中資料庫的操作,會有些批量處理操作,它用來提高網路利用率與資料庫執行效率,
在 kafka 中頁提高了大量批處理的 API ,可以對資料進行統一的壓縮合并,通過更小的資料包在網路中進行資料發送,再進行后續處理,這在大量資料處理中,效率提高是非常明顯的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/301914.html
標籤:其他