文章目錄
- 一.Kafka生產者
- 1.1什么是生產者
- 1.2Kafka磁區策略
- 磁區原因
- 磁區原則
- 如何保證資料傳輸的可靠性
- 二.消費者
- 消費方式
- Kafka高效讀取資料
- 下一篇講述Java操作Kafka
一.Kafka生產者
1.1什么是生產者
生產者就是producer,負責生產訊息,并把訊息放入到佇列中
1.2Kafka磁區策略
磁區原因
- 方便在集群中擴展,因為每個topic中有多個partition,partition可以適應相對應的機器,從而適應任意大小的資料
- 提高并發度,可以以partition為單位進行讀寫
磁區原則
- 首先將生產者producer生產的資料封裝成一個ProducerRecord 物件

- 指明 partition 的情況下,直接將指明的值作為 partition 值;
- 沒有指明 partition 值但有 key 的情況下,將 key 值的 hash 值與 topic 的 partition 數進行取余得到 partition 值;
- 既沒有 partition 又沒有 key 值的情況下,第一次呼叫時隨機生成一個整數(后面每次呼叫在這個整數上自增),將這個值與 topic 可用的 partition 總數取余得到 partition 值,也就是常說的 round-robin (輪詢)演算法,
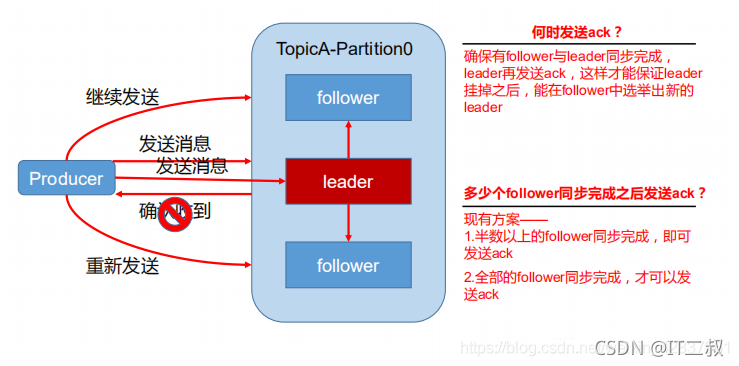
如何保證資料傳輸的可靠性
為保證 producer 發送的資料,能可靠的發送到指定的 topic,topic 中的每個 partition 收到 producer 發送的資料后,都需要向 producer 發送 ack (acknowledgement 確認收到),如果 producer 收到 ack,就會進行下一輪的發送,否則重新發送資料,
二.消費者
消費方式
consumer 采用 pull(拉)模式從 broker 中讀取資料,
push(推)模式很難適應消費速率不同的消費者,因為訊息發送速率是由 broker 決定的,它的目標是盡可能以最快速度傳遞訊息,但是這樣很容易造成 consumer 來不及處理訊息,典型的表現是拒絕服務以及網路擁塞,而 pull 模式則可以根據 consumer 的消費能力以適當的速率消費訊息,
pull 模式不足之處是, 如果 kafka 沒有資料,消費者可能陷入回圈中,一直回傳空資料,針對這一點,kafka 的消費者在消費資料時會傳入一個時長引數 timeout,如果當前沒有資料提供消費,consumer 會等待一段時間之后再回傳,這段時長即 timeout,
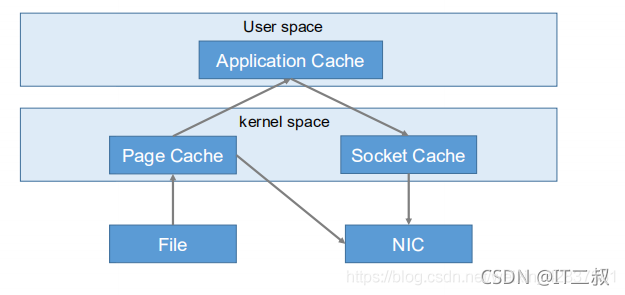
Kafka高效讀取資料
- 順序寫磁盤
Kafka 的 producer 生產資料,要寫到 log 檔案中,寫的程序是一直追加到檔案末尾,為順序寫,順序寫之所以快,是因為其省去了大量磁頭尋址時間, - 零復制技術
下一篇講述Java操作Kafka
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/312080.html
標籤:其他