這篇將會著重介紹使用 pytorch 進行機器學習訓練程序中的一些常見技巧,掌握它們可以讓你事半功倍,
使用的代碼大部分會基于上一篇最后一個例子,即根據碼農條件預測工資??,如果你沒看上一篇請點擊這里查看,
保存和讀取模型狀態
在 pytorch 中各種操作都是圍繞 tensor 物件來的,模型的引數也是 tensor,如果我們把訓練好的 tensor 保存到硬碟然后下次再從硬碟讀取就可以直接使用了,
我們先來看看如何保存單個 tensor,以下代碼運行在 python 的 REPL 中:
# 參考 pytorch
>>> import torch
# 新建一個 tensor 物件
>>> a = torch.tensor([1, 2, 3], dtype=torch.float)
# 保存 tensor 到檔案 1.pt
>>> torch.save(a, "1.pt")
# 從檔案 1.pt 讀取 tensor
>>> b = torch.load("1.pt")
>>> b
tensor([1., 2., 3.])
torch.save 保存 tensor 的時候會使用 python 的 pickle 格式,這個格式保證在不同的 python 版本間兼容,但不支持壓縮內容,所以如果 tensor 非常大保存的檔案將會占用很多空間,我們可以在保存前壓縮,讀取前解壓縮以減少檔案大小:
# 參考壓縮庫
>>> import gzip
# 保存 tensor 到檔案 1.pt,保存時使用 gzip 壓縮
>>> torch.save(a, gzip.GzipFile("1.pt.gz", "wb"))
# 從檔案 1.pt 讀取 tensor,讀取時使用 gzip 解壓縮
>>> b = torch.load(gzip.GzipFile("1.pt.gz", "rb"))
>>> b
tensor([1., 2., 3.])
torch.save 不僅支持保存單個 tensor 物件,還支持保存 tensor 串列或者詞典 (實際上它還可以保存 tensor 以外的 python 物件,只要 pickle 格式支持),我們可以呼叫 state_dict 獲取一個包含模型所有引數的集合,再用 torch.save 就可以保存模型的狀態:
>>> from torch import nn
>>> class MyModel(nn.Module):
... def __init__(self):
... super().__init__()
... self.layer1 = nn.Linear(in_features=8, out_features=100)
... self.layer2 = nn.Linear(in_features=100, out_features=50)
... self.layer3 = nn.Linear(in_features=50, out_features=1)
... def forward(self, x):
... hidden1 = nn.functional.relu(self.layer1(x))
... hidden2 = nn.functional.relu(self.layer2(hidden1))
... y = self.layer3(hidden2)
... return y
...
>>> model = MyModel()
>>> model.state_dict()
OrderedDict([('layer1.weight', tensor([[ 0.2261, 0.2008, 0.0833, -0.2020, -0.0674, 0.2717, -0.0076, 0.1984],
省略途中輸出
0.1347, 0.1356]])), ('layer3.bias', tensor([0.0769]))])
>>> torch.save(model.state_dict(), gzip.GzipFile("model.pt.gz", "wb"))
讀取模型狀態可以使用 load_state_dict 函式,不過你需要保證模型的引數定義沒有發生變化,否則讀取會出錯:
>>> new_model = MyModel()
>>> new_model.load_state_dict(torch.load(gzip.GzipFile("model.pt.gz", "rb")))
<All keys matched successfully>
一個很重要的細節是,如果你讀取模型狀態后不是準備繼續訓練,而是用于預測其他資料,那么你應該呼叫 eval 函式來禁止自動微分等功能,這樣可以加快運算速度:
>>> new_model.eval()
pytorch 不僅支持保存和讀取模型狀態,還支持保存和讀取整個模型包括代碼和引數,但我不推薦這種做法,因為使用的時候會看不到模型定義,并且模型依賴的類別庫或者函式不會一并保存起來所以你還是得預先加載它們否則會出錯:
>>> torch.save(model, gzip.GzipFile("model.pt.gz", "wb"))
>>> new_model = torch.load(gzip.GzipFile("model.pt.gz", "rb"))
記錄訓練集和驗證集的正確率變化
我們可以在訓練程序中記錄訓練集和驗證集的正確率變化,以觀察是否可以收斂,訓練速度如何,以及是否發生過擬合問題,以下是代碼例子:
# 參考 pytorch 和 pandas 和顯示圖表使用的 matplotlib
import pandas
import torch
from torch import nn
from matplotlib import pyplot
# 定義模型
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=100)
self.layer2 = nn.Linear(in_features=100, out_features=50)
self.layer3 = nn.Linear(in_features=50, out_features=1)
def forward(self, x):
hidden1 = nn.functional.relu(self.layer1(x))
hidden2 = nn.functional.relu(self.layer2(hidden1))
y = self.layer3(hidden2)
return y
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓訓練程序可重現,你也可以選擇不這樣做
torch.random.manual_seed(0)
# 創建模型實體
model = MyModel()
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.SGD(model.parameters(), lr=0.0000001)
# 從 csv 讀取原始資料集
df = pandas.read_csv('salary.csv')
dataset_tensor = torch.tensor(df.values, dtype=torch.float)
# 切分訓練集 (60%),驗證集 (20%) 和測驗集 (20%)
random_indices = torch.randperm(dataset_tensor.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
traning_set_x = dataset_tensor[traning_indices][:,:-1]
traning_set_y = dataset_tensor[traning_indices][:,-1:]
validating_set_x = dataset_tensor[validating_indices][:,:-1]
validating_set_y = dataset_tensor[validating_indices][:,-1:]
testing_set_x = dataset_tensor[testing_indices][:,:-1]
testing_set_y = dataset_tensor[testing_indices][:,-1:]
# 記錄訓練集和驗證集的正確率變化
traning_accuracy_history = []
validating_accuracy_history = []
# 開始訓練程序
for epoch in range(1, 500):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
traning_accuracy_list = []
for batch in range(0, traning_set_x.shape[0], 100):
# 切分批次,一次只計算 100 組資料
batch_x = traning_set_x[batch:batch+100]
batch_y = traning_set_y[batch:batch+100]
# 計算預測值
predicted = model(batch_x)
# 計算損失
loss = loss_function(predicted, batch_y)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄這一個批次的正確率,torch.no_grad 代表臨時禁用自動微分功能
with torch.no_grad():
traning_accuracy_list.append(1 - ((batch_y - predicted).abs() / batch_y).mean().item())
traning_accuracy = sum(traning_accuracy_list) / len(traning_accuracy_list)
traning_accuracy_history.append(traning_accuracy)
print(f"training accuracy: {traning_accuracy}")
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
predicted = model(validating_set_x)
validating_accuracy = 1 - ((validating_set_y - predicted).abs() / validating_set_y).mean()
validating_accuracy_history.append(validating_accuracy.item())
print(f"validating x: {validating_set_x}, y: {validating_set_y}, predicted: {predicted}")
print(f"validating accuracy: {validating_accuracy}")
# 檢查測驗集
predicted = model(testing_set_x)
testing_accuracy = 1 - ((testing_set_y - predicted).abs() / testing_set_y).mean()
print(f"testing x: {testing_set_x}, y: {testing_set_y}, predicted: {predicted}")
print(f"testing accuracy: {testing_accuracy}")
# 顯示訓練集和驗證集的正確率變化
pyplot.plot(traning_accuracy_history, label="traning")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
# 手動輸入資料預測輸出
while True:
try:
print("enter input:")
r = list(map(float, input().split(",")))
x = torch.tensor(r).view(1, len(r))
print(model(x)[0,0].item())
except Exception as e:
print("error:", e)
經過 500 輪訓練后會生成以下的圖表:
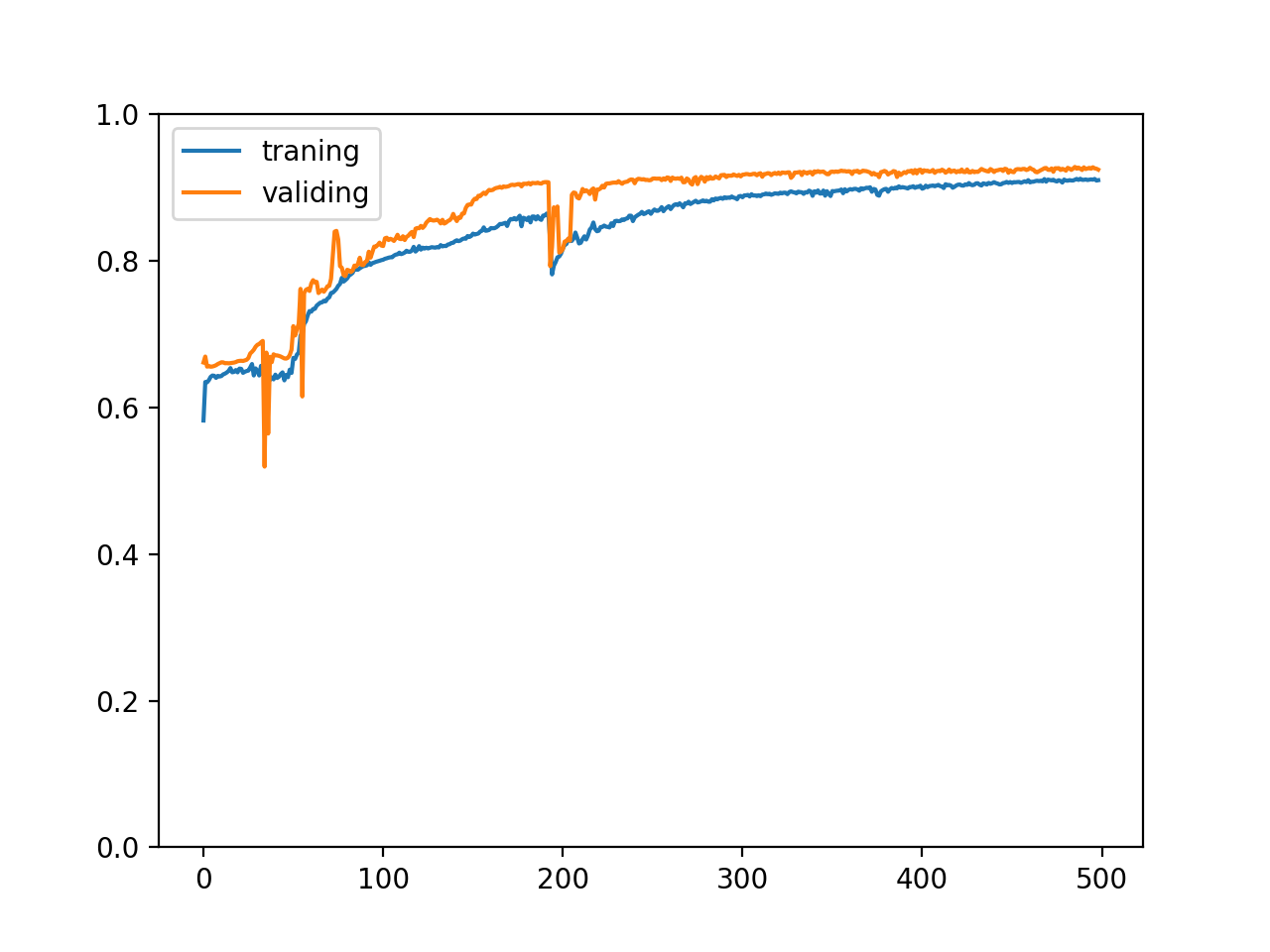
我們可以從圖表看到訓練集和驗證集的正確率都隨著訓練逐漸上升,并且兩個正確率非常接近,這代表訓練很成功,模型針對訓練集掌握了規律并且可以成功預測沒有經過訓練的驗證集,但實際上我們很難會看到這樣的圖表,這是因為例子中的資料集是精心構建的并且生成了足夠大量的資料,
我們還可能會看到以下型別的圖表,分別代表不同的狀況:
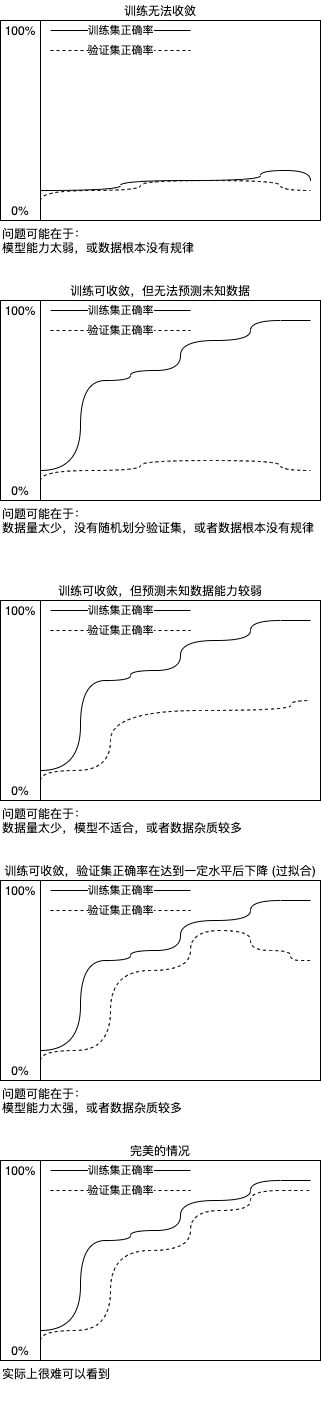
如果有足夠的資料,資料遵從某種規律并且雜質較少,劃分訓練集和驗證集的時候分布均勻,并且使用適當的模型,即可達到理想的狀況,但實際很難做到??,通過分析訓練集和驗證集的正確率變化我們可以定位問題發生在哪里,其中過擬合問題可以用提早停止 (Early Stopping) 的方式解決 (在第一篇文章已經提到過),接下來我們看看如何決定什么時候停止訓練,
決定什么時候停止訓練
還記得第一篇提到的訓練流程嗎?我們將會了解如何在代碼中實作這個訓練流程:
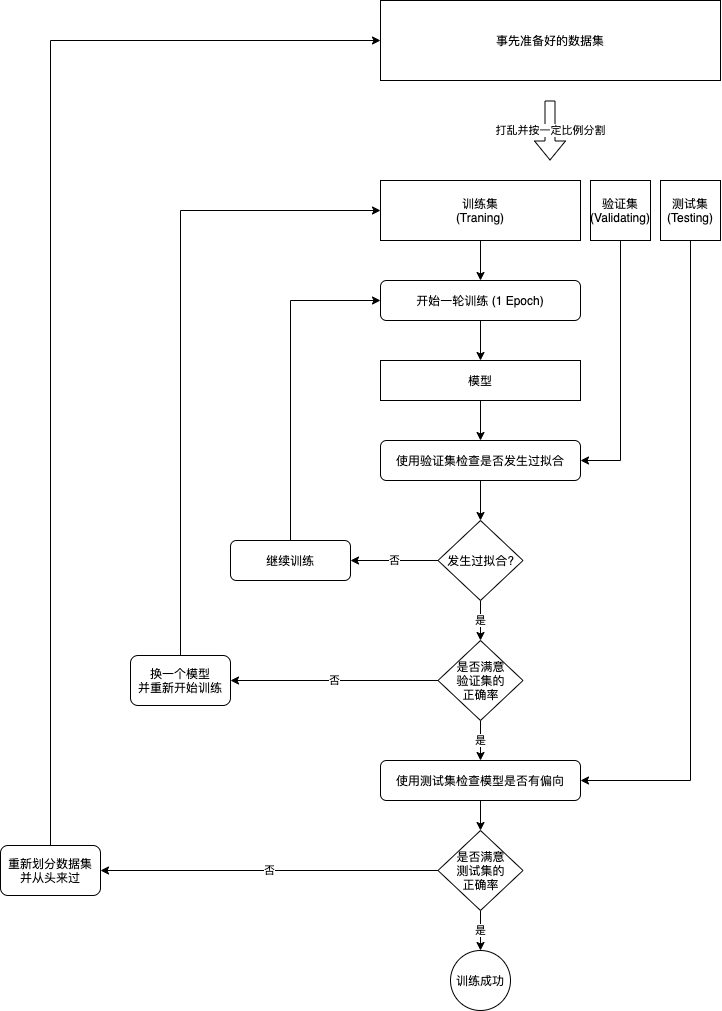
實作判斷是否發生過擬合,可以簡單的記錄歷史最高的驗證集正確率,如果經過很多次訓練都沒有重繪最高正確率則結束訓練,記錄最高正確率的同時我們還需要保存模型的狀態,這時模型摸索到了足夠多的規律,但是還沒有修改引數適應訓練集中的雜質,用來預測未知資料可以達到最好的效果,這種手法又稱提早停止 (Early Stopping),是機器學習中很常見的手法,
代碼實作如下:
# 參考 pytorch 和 pandas 和顯示圖表使用的 matplotlib
import pandas
import torch
from torch import nn
from matplotlib import pyplot
# 定義模型
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=100)
self.layer2 = nn.Linear(in_features=100, out_features=50)
self.layer3 = nn.Linear(in_features=50, out_features=1)
def forward(self, x):
hidden1 = nn.functional.relu(self.layer1(x))
hidden2 = nn.functional.relu(self.layer2(hidden1))
y = self.layer3(hidden2)
return y
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓訓練程序可重現,你也可以選擇不這樣做
torch.random.manual_seed(0)
# 創建模型實體
model = MyModel()
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.SGD(model.parameters(), lr=0.0000001)
# 從 csv 讀取原始資料集
df = pandas.read_csv('salary.csv')
dataset_tensor = torch.tensor(df.values, dtype=torch.float)
# 切分訓練集 (60%),驗證集 (20%) 和測驗集 (20%)
random_indices = torch.randperm(dataset_tensor.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
traning_set_x = dataset_tensor[traning_indices][:,:-1]
traning_set_y = dataset_tensor[traning_indices][:,-1:]
validating_set_x = dataset_tensor[validating_indices][:,:-1]
validating_set_y = dataset_tensor[validating_indices][:,-1:]
testing_set_x = dataset_tensor[testing_indices][:,:-1]
testing_set_y = dataset_tensor[testing_indices][:,-1:]
# 記錄訓練集和驗證集的正確率變化
traning_accuracy_history = []
validating_accuracy_history = []
# 記錄最高的驗證集正確率
validating_accuracy_highest = 0
validating_accuracy_highest_epoch = 0
# 開始訓練程序
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
traning_accuracy_list = []
for batch in range(0, traning_set_x.shape[0], 100):
# 切分批次,一次只計算 100 組資料
batch_x = traning_set_x[batch:batch+100]
batch_y = traning_set_y[batch:batch+100]
# 計算預測值
predicted = model(batch_x)
# 計算損失
loss = loss_function(predicted, batch_y)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄這一個批次的正確率,torch.no_grad 代表臨時禁用自動微分功能
with torch.no_grad():
traning_accuracy_list.append(1 - ((batch_y - predicted).abs() / batch_y).mean().item())
traning_accuracy = sum(traning_accuracy_list) / len(traning_accuracy_list)
traning_accuracy_history.append(traning_accuracy)
print(f"training accuracy: {traning_accuracy}")
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
predicted = model(validating_set_x)
validating_accuracy = 1 - ((validating_set_y - predicted).abs() / validating_set_y).mean()
validating_accuracy_history.append(validating_accuracy.item())
print(f"validating x: {validating_set_x}, y: {validating_set_y}, predicted: {predicted}")
print(f"validating accuracy: {validating_accuracy}")
# 記錄最高的驗證集正確率與當時的模型狀態,判斷是否在 100 次訓練后仍然沒有重繪記錄
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
torch.save(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 100:
# 在 100 次訓練后仍然沒有重繪記錄,結束訓練
print("stop training because highest validating accuracy not updated in 100 epoches")
break
# 使用達到最高正確率時的模型狀態
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(torch.load("model.pt"))
# 檢查測驗集
predicted = model(testing_set_x)
testing_accuracy = 1 - ((testing_set_y - predicted).abs() / testing_set_y).mean()
print(f"testing x: {testing_set_x}, y: {testing_set_y}, predicted: {predicted}")
print(f"testing accuracy: {testing_accuracy}")
# 顯示訓練集和驗證集的正確率變化
pyplot.plot(traning_accuracy_history, label="traning")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
# 手動輸入資料預測輸出
while True:
try:
print("enter input:")
r = list(map(float, input().split(",")))
x = torch.tensor(r).view(1, len(r))
print(model(x)[0,0].item())
except Exception as e:
print("error:", e)
最終輸出如下:
省略開始的輸出
stop training because highest validating accuracy not updated in 100 epoches
highest validating accuracy: 0.93173748254776 from epoch 645
testing x: tensor([[48., 1., 18., ..., 5., 0., 5.],
[22., 1., 2., ..., 2., 1., 2.],
[24., 0., 1., ..., 3., 2., 0.],
...,
[24., 0., 4., ..., 0., 1., 1.],
[39., 0., 0., ..., 0., 5., 5.],
[36., 0., 5., ..., 3., 0., 3.]]), y: tensor([[14000.],
[10500.],
[13000.],
...,
[15500.],
[12000.],
[19000.]]), predicted: tensor([[15612.1895],
[10705.9873],
[12577.7988],
...,
[16281.9277],
[10780.5996],
[19780.3281]], grad_fn=<AddmmBackward>)
testing accuracy: 0.9330222606658936
訓練集與驗證集的正確率變化如下,可以看到我們停在了一個很好的地方??,繼續訓練下去也不會有什么改進:
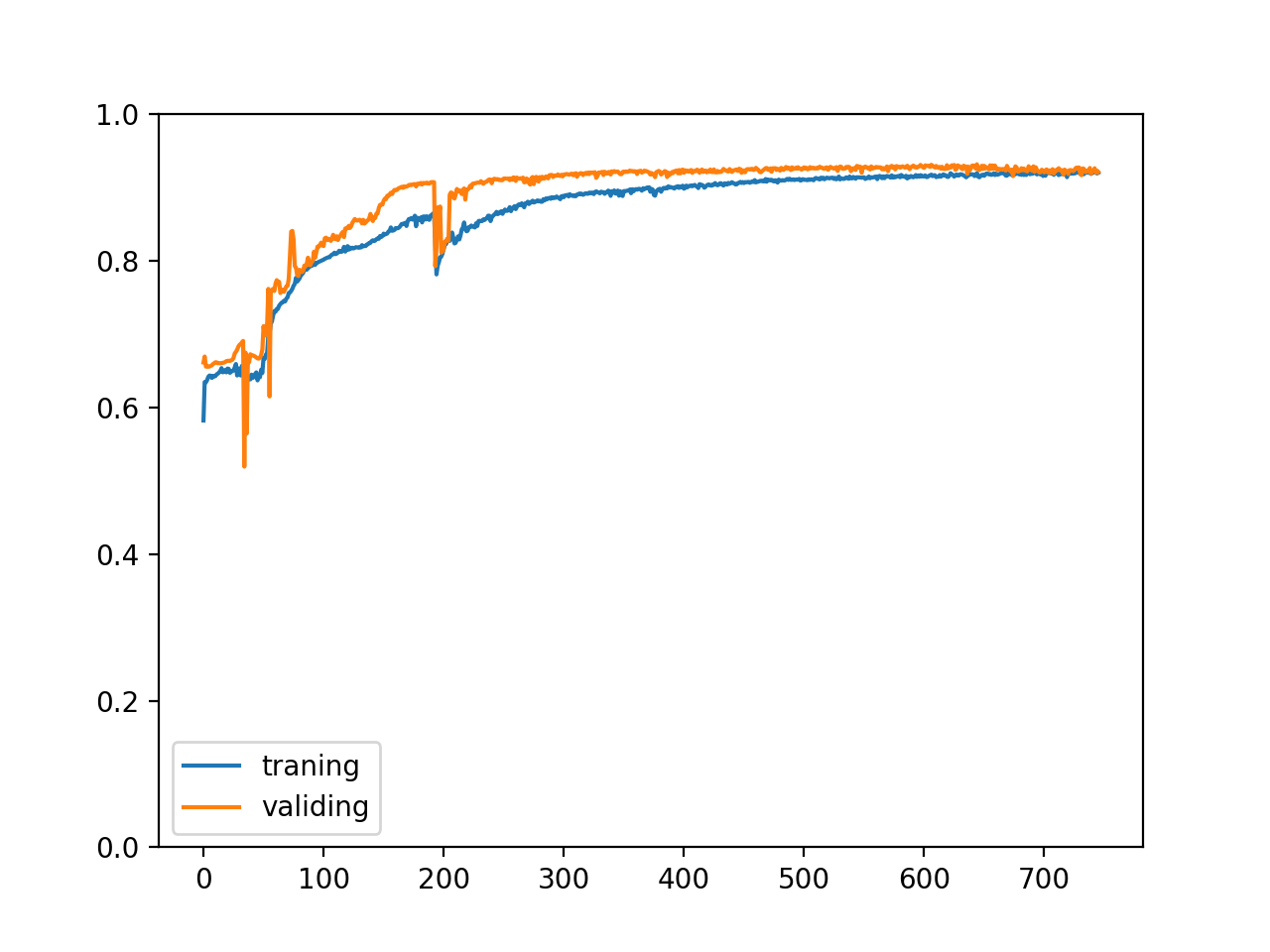
改行程式結構
我們還可以對程式結構進行以下的改進:
- 分離準備資料集和訓練的程序
- 訓練程序中分批讀取資料
- 提供介面使用訓練好的模型
至此為止我們看到的訓練代碼都是把準備資料集,訓練,訓練后評價和使用寫在一個程式里面的,這樣做容易理解但在實際業務中會比較浪費時間,如果你發現一個模型不適合,需要修改模型那么你得從頭開始,我們可以分離準備資料集和訓練的程序,首先讀取原始資料并且轉換到 tensor 物件再保存到硬碟,然后再從硬碟讀取 tensor 物件進行訓練,這樣如果需要修改模型但不需要修改輸入輸出轉換到 tensor 的編碼時,可以節省掉第一步,
在實際業務上資料可能會非常龐大,做不到全部讀取到記憶體中再分批次,這時我們可以在讀取原始資料并且轉換到 tensor 物件的時候進行分批,然后訓練的程序中逐批從硬碟讀取,這樣就可以防止記憶體不足的問題,
最后我們可以提供一個對外的介面來使用訓練好的模型,如果你的程式是 python 寫的那么直接呼叫即可,但如果你的程式是其他語言寫的,可能需要先建立一個 python 服務器提供 REST 服務,或者使用 TorchScript 進行跨語言互動,詳細可以參考官方的教程,
總結起來我們會拆分以下程序:
- 讀取原始資料集并轉換到 tensor 物件
- 分批次保存 tensor 物件到硬碟
- 分批次從硬碟讀取 tensor 物件并進行訓練
- 訓練時保存模型狀態到硬碟 (一般選擇保存驗證集正確率最高時的模型狀態)
- 提供介面使用訓練好的模型
以下是改進后的示例代碼:
import os
import sys
import pandas
import torch
import gzip
import itertools
from torch import nn
from matplotlib import pyplot
class MyModel(nn.Module):
"""根據碼農條件預測工資的模型"""
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=100)
self.layer2 = nn.Linear(in_features=100, out_features=50)
self.layer3 = nn.Linear(in_features=50, out_features=1)
def forward(self, x):
hidden1 = nn.functional.relu(self.layer1(x))
hidden2 = nn.functional.relu(self.layer2(hidden1))
y = self.layer3(hidden2)
return y
def save_tensor(tensor, path):
"""保存 tensor 物件到檔案"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""從檔案讀取 tensor 物件"""
return torch.load(gzip.GzipFile(path, "rb"))
def prepare():
"""準備訓練"""
# 資料集轉換到 tensor 以后會保存在 data 檔案夾下
if not os.path.isdir("data"):
os.makedirs("data")
# 從 csv 讀取原始資料集,分批每次讀取 2000 行
for batch, df in enumerate(pandas.read_csv('salary.csv', chunksize=2000)):
dataset_tensor = torch.tensor(df.values, dtype=torch.float)
# 切分訓練集 (60%),驗證集 (20%) 和測驗集 (20%)
random_indices = torch.randperm(dataset_tensor.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
training_set = dataset_tensor[traning_indices]
validating_set = dataset_tensor[validating_indices]
testing_set = dataset_tensor[testing_indices]
# 保存到硬碟
save_tensor(training_set, f"data/training_set.{batch}.pt")
save_tensor(validating_set, f"data/validating_set.{batch}.pt")
save_tensor(testing_set, f"data/testing_set.{batch}.pt")
print(f"batch {batch} saved")
def train():
"""開始訓練"""
# 創建模型實體
model = MyModel()
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.SGD(model.parameters(), lr=0.0000001)
# 記錄訓練集和驗證集的正確率變化
traning_accuracy_history = []
validating_accuracy_history = []
# 記錄最高的驗證集正確率
validating_accuracy_highest = 0
validating_accuracy_highest_epoch = 0
# 讀取批次的工具函式
def read_batches(base_path):
for batch in itertools.count():
path = f"{base_path}.{batch}.pt"
if not os.path.isfile(path):
break
yield load_tensor(path)
# 計算正確率的工具函式
def calc_accuracy(actual, predicted):
return max(0, 1 - ((actual - predicted).abs() / actual.abs()).mean().item())
# 開始訓練程序
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
traning_accuracy_list = []
for batch in read_batches("data/training_set"):
# 切分小批次,有助于泛化模型
for index in range(0, batch.shape[0], 100):
# 劃分輸入和輸出
batch_x = batch[index:index+100,:-1]
batch_y = batch[index:index+100,-1:]
# 計算預測值
predicted = model(batch_x)
# 計算損失
loss = loss_function(predicted, batch_y)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄這一個批次的正確率,torch.no_grad 代表臨時禁用自動微分功能
with torch.no_grad():
traning_accuracy_list.append(calc_accuracy(batch_y, predicted))
traning_accuracy = sum(traning_accuracy_list) / len(traning_accuracy_list)
traning_accuracy_history.append(traning_accuracy)
print(f"training accuracy: {traning_accuracy}")
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
validating_accuracy_list = []
for batch in read_batches("data/validating_set"):
validating_accuracy_list.append(calc_accuracy(batch[:,-1:], model(batch[:,:-1])))
validating_accuracy = sum(validating_accuracy_list) / len(validating_accuracy_list)
validating_accuracy_history.append(validating_accuracy)
print(f"validating accuracy: {validating_accuracy}")
# 記錄最高的驗證集正確率與當時的模型狀態,判斷是否在 100 次訓練后仍然沒有重繪記錄
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 100:
# 在 100 次訓練后仍然沒有重繪記錄,結束訓練
print("stop training because highest validating accuracy not updated in 100 epoches")
break
# 使用達到最高正確率時的模型狀態
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 檢查測驗集
testing_accuracy_list = []
for batch in read_batches("data/testing_set"):
testing_accuracy_list.append(calc_accuracy(batch[:,-1:], model(batch[:,:-1])))
testing_accuracy = sum(testing_accuracy_list) / len(testing_accuracy_list)
print(f"testing accuracy: {testing_accuracy}")
# 顯示訓練集和驗證集的正確率變化
pyplot.plot(traning_accuracy_history, label="traning")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用訓練好的模型"""
parameters = [
"Age",
"Gender (0: Male, 1: Female)",
"Years of work experience",
"Java Skill (0 ~ 5)",
"NET Skill (0 ~ 5)",
"JS Skill (0 ~ 5)",
"CSS Skill (0 ~ 5)",
"HTML Skill (0 ~ 5)"
]
# 創建模型實體,加載訓練好的狀態,然后切換到驗證模式
model = MyModel()
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 詢問輸入并預測輸出
while True:
try:
x = torch.tensor([int(input(f"Your {p}: ")) for p in parameters], dtype=torch.float)
# 轉換到 1 行 1 列的矩陣,這里其實可以不轉換但推薦這么做,因為不是所有模型都支持非批次輸入
x = x.view(1, len(x))
y = model(x)
print("Your estimated salary:", y[0,0].item(), "\n")
except Exception as e:
print("error:", e)
def main():
"""主函式"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓程序可重現,你也可以選擇不這樣做
torch.random.manual_seed(0)
# 根據命令列引數選擇操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
執行以下命令即可走一遍完整的流程,如果你需要調整模型,可以直接重新運行 train 避免 prepare 的時間消耗:
python3 example.py prepare
python3 example.py train
python3 example.py eval
注意以上代碼在打亂資料集和分批的處理上與以往的代碼不一樣,以上的代碼會分段讀取 csv 檔案,然后對每一段打亂再切分訓練集,驗證集和測驗集,這樣做同樣可以保證資料在各個集合中分布均勻,最終訓練集和驗證集的正確率變化如下:
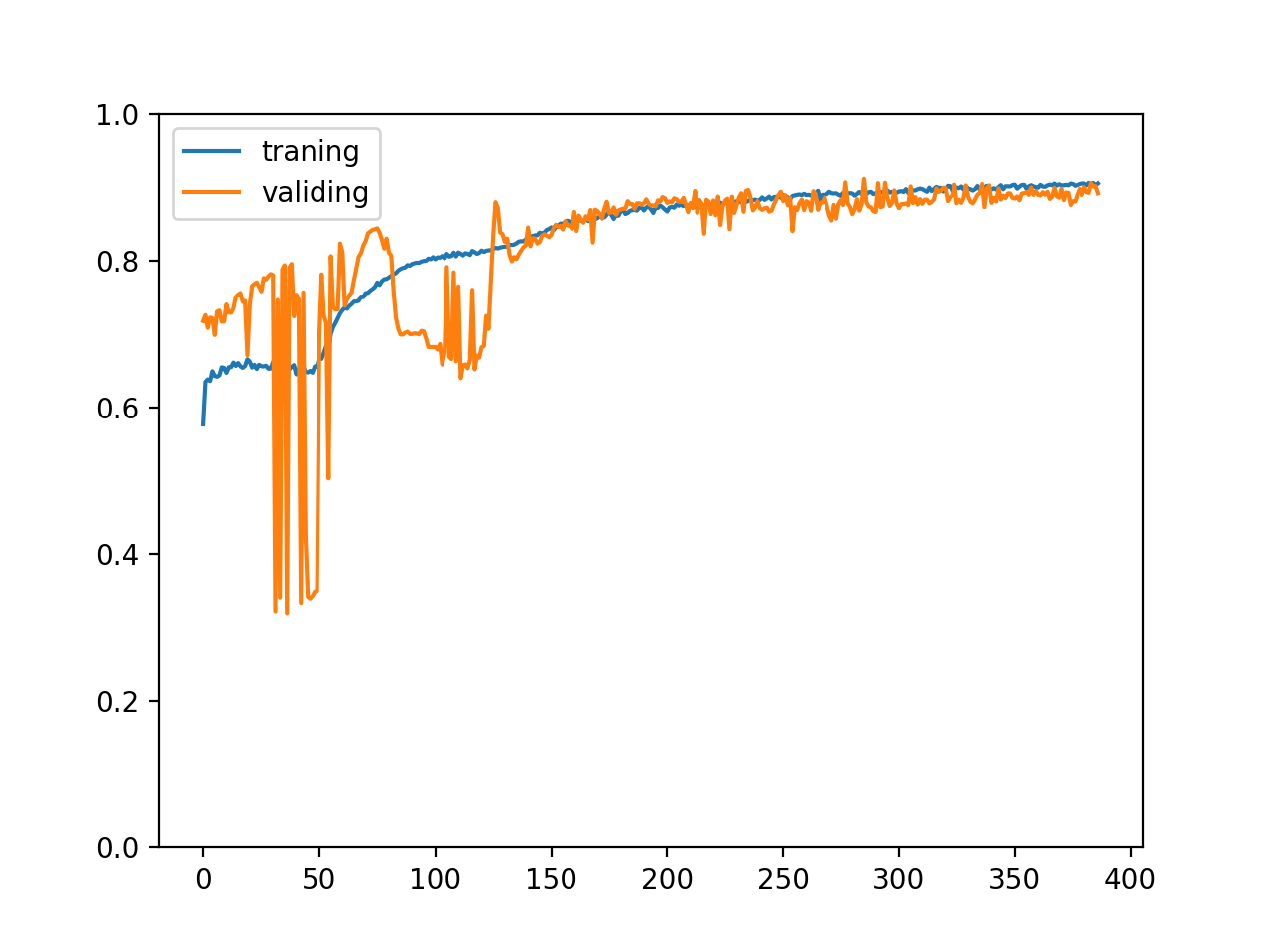
正規化輸入和輸出值
目前為止我們在訓練的時候都是直接給模型原始的輸入值,然后用原始的輸出值去調整引數,這樣做的問題是,如果輸入值非常大導函式值也會非常大,如果輸出值非常大需要調整引數的次數會非常多,過去我們用一個非常非常小的學習比率 (0.0000001) 來避開這個問題,但其實有更好的辦法,那就是正規化輸入和輸出值,這里的正規化指的是讓輸入值和輸出值按一定比例縮放,讓大部分的值都落在 -1 ~ 1 的區間中,在根據碼農條件預測工資的例子中,我們可以把年齡和作業經驗年數乘以 0.01 (范圍 0 ~ 100 年),各項技能乘以 0.02 (范圍 0 ~ 5),工資乘以 0.0001 (以萬為單位),對 dataset_tensor 進行以下操作即可實作:
# 對每一行乘以指定的系數
dataset_tensor *= torch.tensor([0.01, 1, 0.01, 0.2, 0.2, 0.2, 0.2, 0.2, 0.0001])
然后再修改學習比率為 0.01:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
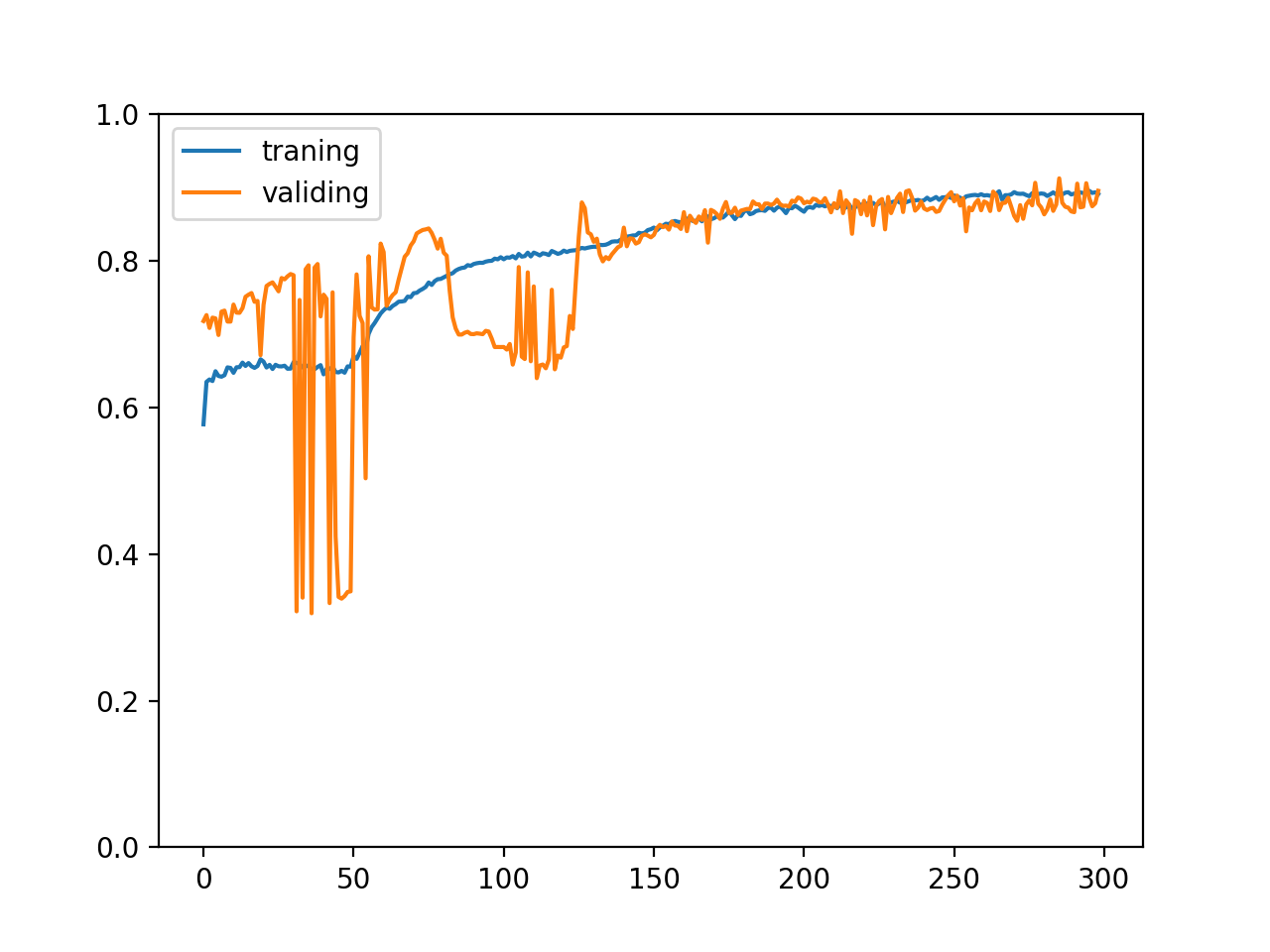
比較訓練 300 次的正確率變化如下:
正規化輸入和輸出值前
正規化輸入和輸出值后
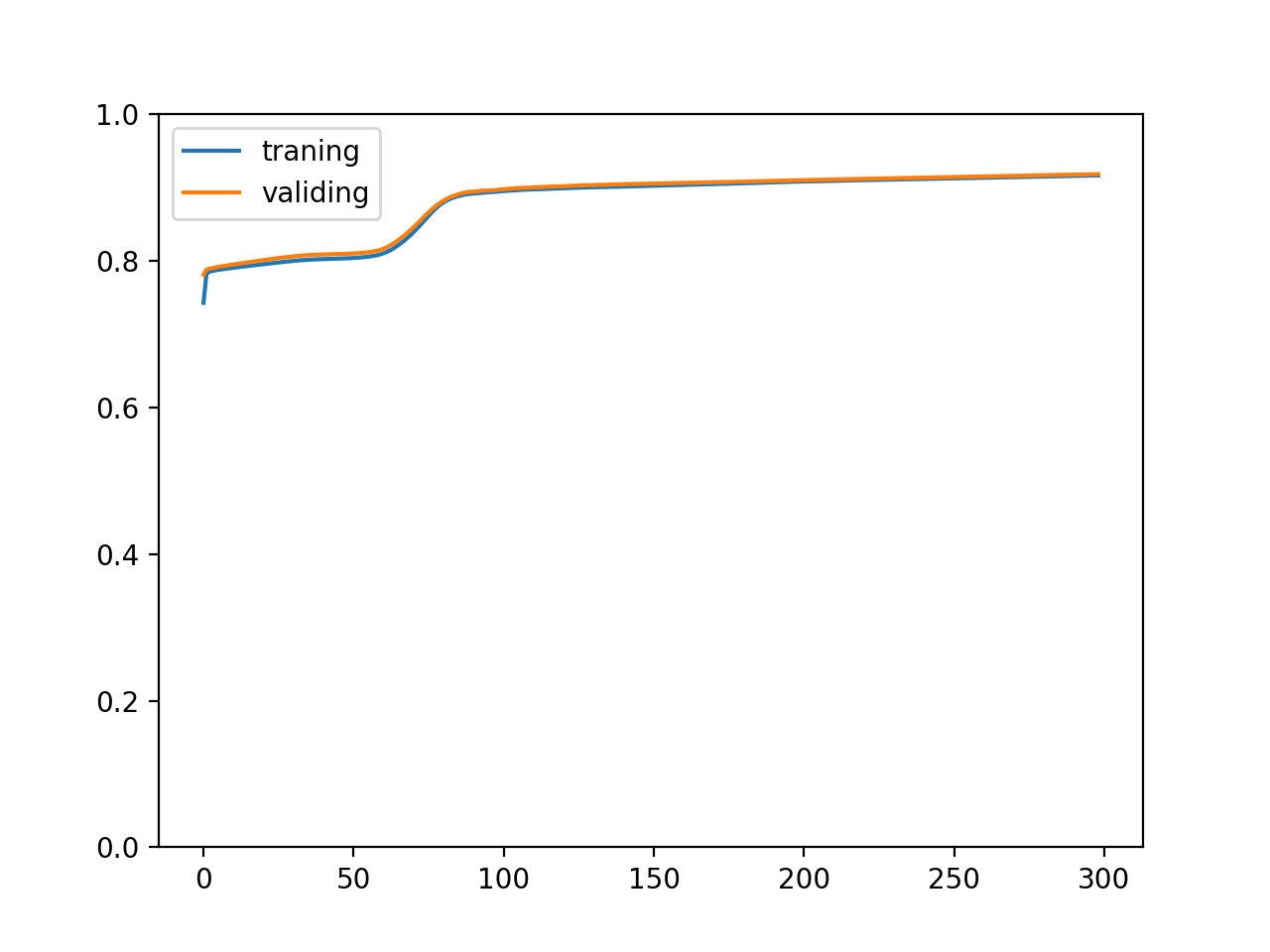
可以看到效果相當驚人??,正規化輸入和輸出值后訓練速度變快了并且正確率的變化曲線平滑了很多,實際上這是必須做的,部分資料集如果沒有經過正規化根本無法學習,讓模型接收和輸出更小的值 (-1 ~ 1 的區間) 可以防止導函式值爆炸和使用更高的學習比率加快訓練速度,
此外,別忘了在使用模型的時候縮放輸入和輸出值:
x = torch.tensor([int(input(f"Your {p}: ")) for p in parameters], dtype=torch.float)
x *= torch.tensor([0.01, 1, 0.01, 0.2, 0.2, 0.2, 0.2, 0.2])
# 轉換到 1 行 1 列的矩陣,這里其實可以不轉換但推薦這么做,因為不是所有模型都支持非批次輸入
x = x.view(1, len(x))
y = model(x) * 10000
print("Your estimated salary:", y[0,0].item(), "\n")
使用 Dropout 幫助泛化模型
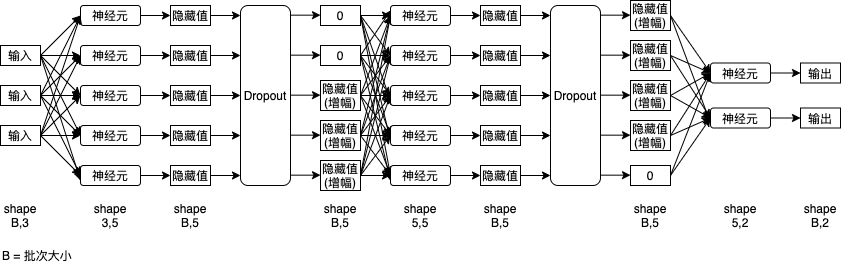
在之前的內容中已經提到過,如果模型能力過于強大或者資料雜質較多,則模型有可能會適應資料中的雜質以達到更高的正確率 (過擬合現象),這時候雖然訓練集的正確率會上升,但驗證集的正確率會維持甚至下降,模型應對未知資料的能力會降低,防止過擬合現象,增強模型應對未知資料的能力又稱泛化模型 (Generalize Model),泛化模型的手段之一是使用 Dropout,Dropout 會在訓練程序中隨機屏蔽一部分的神經元,讓這些神經元的輸出為 0,同時增幅沒有被屏蔽的神經元輸出讓輸出值合計接近原有的水平,這樣做的好處是模型會嘗試摸索怎樣在一部分神經元被屏蔽后仍然可以正確預測結果 (減弱跨層神經元之間的關聯),最終導致模型更充分的掌握資料的規律,
下圖是使用 Dropout 以后的神經元網路例子 (3 輸入 2 輸出,3 層每層各 5 隱藏值):
接下來我們看看在 Pytorch 中怎么使用 Dropout:
# 參考 pytorch 類別庫
>>> import torch
# 創建屏蔽 20% 的 Dropout 函式
>>> dropout = torch.nn.Dropout(0.2)
# 定義一個 tensor (假設這個 tensor 是某個神經元網路層的輸出結果)
>>> a = torch.tensor(range(1, 11), dtype=torch.float)
>>> a
tensor([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
# 應用 Dropout 函式
# 我們可以看到沒有屏蔽的值都會相應的增加 (除以 0.8) 以讓合計值維持原有的水平
# 此外屏蔽的數量會根據概率浮動,不一定 100% 等于我們設定的比例 (這里有屏蔽 1 個值的也有屏蔽 3 個值的)
>>> dropout(a)
tensor([ 0.0000, 2.5000, 3.7500, 5.0000, 6.2500, 7.5000, 8.7500, 10.0000,
11.2500, 12.5000])
>>> dropout(a)
tensor([ 1.2500, 2.5000, 3.7500, 5.0000, 6.2500, 7.5000, 8.7500, 0.0000,
11.2500, 0.0000])
>>> dropout(a)
tensor([ 1.2500, 2.5000, 3.7500, 5.0000, 6.2500, 7.5000, 8.7500, 0.0000,
11.2500, 12.5000])
>>> dropout(a)
tensor([ 1.2500, 2.5000, 3.7500, 5.0000, 6.2500, 7.5000, 0.0000, 10.0000,
11.2500, 0.0000])
>>> dropout(a)
tensor([ 1.2500, 2.5000, 3.7500, 5.0000, 0.0000, 7.5000, 8.7500, 10.0000,
11.2500, 0.0000])
>>> dropout(a)
tensor([ 1.2500, 2.5000, 0.0000, 5.0000, 0.0000, 7.5000, 8.7500, 10.0000,
11.2500, 12.5000])
>>> dropout(a)
tensor([ 0.0000, 2.5000, 3.7500, 5.0000, 6.2500, 7.5000, 0.0000, 10.0000,
0.0000, 0.0000])
接下來我們看看怎樣應用 Dropout 到模型中,首先我們重現一下過擬合現象,增加模型的神經元數量并且減少訓練集的資料量即可:
模型部分的代碼:
class MyModel(nn.Module):
"""根據碼農條件預測工資的模型"""
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=200)
self.layer2 = nn.Linear(in_features=200, out_features=100)
self.layer3 = nn.Linear(in_features=100, out_features=1)
def forward(self, x):
hidden1 = nn.functional.relu(self.layer1(x))
hidden2 = nn.functional.relu(self.layer2(hidden1))
y = self.layer3(hidden2)
return y
訓練部分的代碼 (每個批次只訓練前 16 個資料):
for batch in read_batches("data/training_set"):
# 切分小批次,有助于泛化模型
for index in range(0, batch.shape[0], 16):
# 劃分輸入和輸出
batch_x = batch[index:index+16,:-1]
batch_y = batch[index:index+16,-1:]
# 計算預測值
predicted = model(batch_x)
# 計算損失
loss = loss_function(predicted, batch_y)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄這一個批次的正確率,torch.no_grad 代表臨時禁用自動微分功能
with torch.no_grad():
traning_accuracy_list.append(calc_accuracy(batch_y, predicted))
# 只訓練前 16 個資料
break
固定訓練 1000 次以后的正確率:
training accuracy: 0.9706422178819776
validating accuracy: 0.8514168351888657
highest validating accuracy: 0.8607834208011628 from epoch 223
testing accuracy: 0.8603586450219154
以及正確率變化的趨勢:
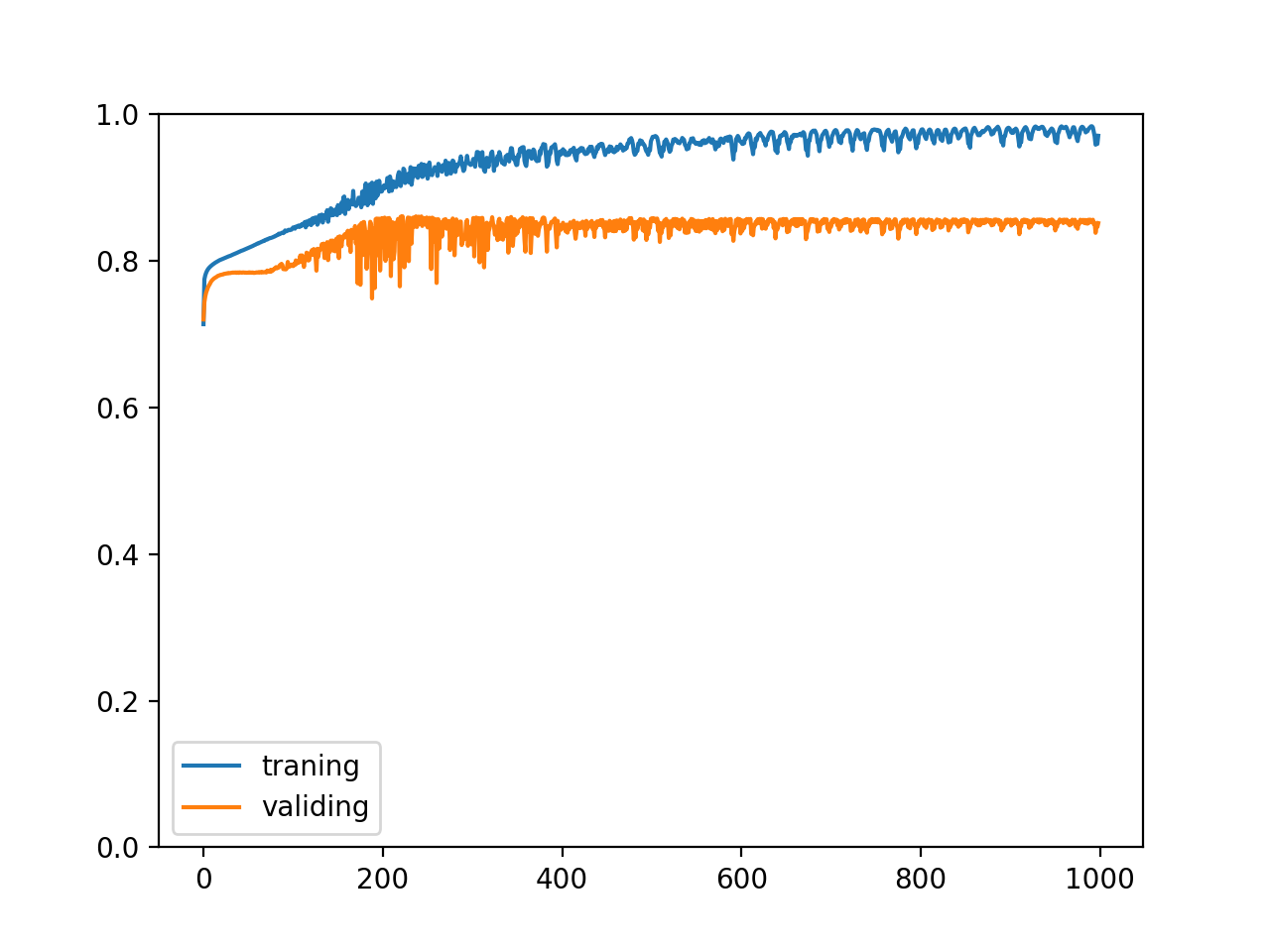
試著在模型中加入兩個 Dropout,分別對應第一層與第二層的輸出 (隱藏值):
class MyModel(nn.Module):
"""根據碼農條件預測工資的模型"""
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=200)
self.layer2 = nn.Linear(in_features=200, out_features=100)
self.layer3 = nn.Linear(in_features=100, out_features=1)
self.dropout1 = nn.Dropout(0.2)
self.dropout2 = nn.Dropout(0.2)
def forward(self, x):
hidden1 = self.dropout1(nn.functional.relu(self.layer1(x)))
hidden2 = self.dropout2(nn.functional.relu(self.layer2(hidden1)))
y = self.layer3(hidden2)
return y
這時候再來訓練會得出以下的正確率:
training accuracy: 0.9326518730819225
validating accuracy: 0.8692235469818115
highest validating accuracy: 0.8728838726878166 from epoch 867
testing accuracy: 0.8733032837510109
以及正確率變化的趨勢:

我們可以看到訓練集的正確率沒有盲目的上升,并且驗證集與測驗集的正確率都各上升了 1% 以上,說明 Dropout 是有一定效果的,
使用 Dropout 時應該注意以下的幾點:
- Dropout 應該針對隱藏值使用,不能放在第一層的前面 (針對輸入) 或者最后一層的后面 (針對輸出)
- Dropout 應該放在激活函式后面 (因為激活函式是神經元的一部分)
- Dropout 只應該在訓練程序中使用,評價或實際使用模型時應該呼叫
model.eval()切換模型到評價模式,以禁止 Dropout - Dropout 函式應該定義為模型的成員,這樣呼叫
model.eval()可以索引到模型對應的所有 Dropout 函式 - Dropout 的屏蔽比例沒有最佳值,你可以針對當前的資料和模型多試幾次找出最好的結果
提出 Dropout 手法的原始論文在這里,如果你有興趣可以查看,
使用 BatchNorm 正規化批次
BatchNorm 是另外一種提升訓練效果的手法,在一些場景下可以提升訓練效率和抑制過擬合,BatchNorm 和 Dropout 一樣針對隱藏值使用,會對每個批次的各項值 (每一列) 進行正規化,計算公式如下:

總結來說就是讓每一列中的各個值減去這一列的平均值,然后除以這一列的標準差,再按一定比例調整,
在 python 中使用 BatchNorm 的例子如下:
# 創建 batchnorm 函式,3 代表列數
>>> batchnorm = torch.nn.BatchNorm1d(3)
# 查看 batchnorm 函式內部的權重與偏移
>>> list(batchnorm.parameters())
[Parameter containing:
tensor([1., 1., 1.], requires_grad=True), Parameter containing:
tensor([0., 0., 0.], requires_grad=True)]
# 隨機創建一個 10 行 3 列的 tensor
>>> a = torch.rand((10, 3))
>>> a
tensor([[0.9643, 0.6933, 0.0039],
[0.3967, 0.8239, 0.3490],
[0.4011, 0.8903, 0.3053],
[0.0666, 0.5766, 0.4976],
[0.4928, 0.1403, 0.8900],
[0.7317, 0.9461, 0.1816],
[0.4461, 0.9987, 0.8324],
[0.3714, 0.6550, 0.9961],
[0.4852, 0.7415, 0.1779],
[0.6876, 0.1538, 0.3429]])
# 應用 batchnorm 函式
>>> batchnorm(a)
tensor([[ 1.9935, 0.1096, -1.4156],
[-0.4665, 0.5665, -0.3391],
[-0.4477, 0.7985, -0.4754],
[-1.8972, -0.2986, 0.1246],
[-0.0501, -1.8245, 1.3486],
[ 0.9855, 0.9939, -0.8611],
[-0.2523, 1.1776, 1.1691],
[-0.5761, -0.0243, 1.6798],
[-0.0831, 0.2783, -0.8727],
[ 0.7941, -1.7770, -0.3581]], grad_fn=<NativeBatchNormBackward>)
# 手動重現 batchnorm 對第一列的計算
>>> aa = a[:,:1]
>>> aa
tensor([[0.9643],
[0.3967],
[0.4011],
[0.0666],
[0.4928],
[0.7317],
[0.4461],
[0.3714],
[0.4852],
[0.6876]])
>>> (aa - aa.mean()) / (((aa - aa.mean()) ** 2).mean() + 0.00001).sqrt()
tensor([[ 1.9935],
[-0.4665],
[-0.4477],
[-1.8972],
[-0.0501],
[ 0.9855],
[-0.2523],
[-0.5761],
[-0.0831],
[ 0.7941]])
修改模型使用 BatchNorm 的代碼如下:
class MyModel(nn.Module):
"""根據碼農條件預測工資的模型"""
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=200)
self.layer2 = nn.Linear(in_features=200, out_features=100)
self.layer3 = nn.Linear(in_features=100, out_features=1)
self.batchnorm1 = nn.BatchNorm1d(200)
self.batchnorm2 = nn.BatchNorm1d(100)
self.dropout1 = nn.Dropout(0.1)
self.dropout2 = nn.Dropout(0.1)
def forward(self, x):
hidden1 = self.dropout1(self.batchnorm1(nn.functional.relu(self.layer1(x))))
hidden2 = self.dropout2(self.batchnorm2(nn.functional.relu(self.layer2(hidden1))))
y = self.layer3(hidden2)
return y
需要同時調整學習比率:
# 創建引數調整器
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
固定訓練 1000 次的結果如下,可以看到在這個場景下 BatchNorm 沒有發揮作用??,反而減慢了學習速度和影響可達到的最高正確率 (你可以試試增加訓練次數):
training accuracy: 0.9048486271500588
validating accuracy: 0.8341873311996459
highest validating accuracy: 0.8443503141403198 from epoch 946
testing accuracy: 0.8452585405111313
使用 BatchNorm 時應該注意以下的幾點:
- BatchNorm 應該針對隱藏值使用,和 Dropout 一樣
- BatchNorm 需要指定隱藏值數量,應該與對應層的輸出數量匹配
- BatchNorm 應該放在 Dropout 前面,有部分人會選擇把 BatchNorm 放在激活函式前,也有部分人選擇放在激活函式后
- Linear => ReLU => BatchNorm => Dropout
- Linear => BatchNorm => ReLU => Dropout
- BatchNorm 只應該在訓練程序中使用,和 Dropout 一樣
- BatchNorm 函式應該定義為模型的成員,和 Dropout 一樣
- 使用 BatchNorm 的時候應該相應的減少 Dropout 的屏蔽比例
- 部分場景可能不適用 BatchNorm (據說更適用于物件識別和圖片分類),需要實踐才能出真知 ?
提出 BatchNorm 手法的原始論文在這里,如果你有興趣可以查看,
理解模型的 eval 和 train 模式
在前面的例子中我們使用了 eval 和 train 函式切換模型到評價模式和訓練模式,評價模式會禁用自動微分,Dropout 和 BatchNorm,那么這兩個模式是如何實作的呢?
pytorch 的模型都基于 torch.nn.Module 這個類,不僅是我們自己定義的模型,nn.Sequential, nn.Linear, nn.ReLU, nn.Dropout, nn.BatchNorm1d 等等的型別都會基于 torch.nn.Module,torch.nn.Module 有一個 training 成員代表模型是否處于訓練模式,而 eval 函式用于遞回設定所有 Module 的 training 為 False,train 函式用于遞回設定所有 Module 的 training 為 True,我們可以手動設定這個成員看看是否能起到相同效果:
>>> a = torch.tensor(range(1, 11), dtype=torch.float)
>>> dropout = torch.nn.Dropout(0.2)
>>> dropout.training = False
>>> dropout(a)
tensor([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
>>> dropout.training = True
>>> dropout(a)
tensor([ 1.2500, 2.5000, 3.7500, 0.0000, 0.0000, 7.5000, 8.7500, 10.0000,
0.0000, 12.5000])
理解這一點后,你可以在模型中添加只在訓練或者評價的時候執行的代碼,根據 self.training 判斷即可,
最終代碼
根據碼農條件預測工資的最終代碼如下:
import os
import sys
import pandas
import torch
import gzip
import itertools
from torch import nn
from matplotlib import pyplot
class MyModel(nn.Module):
"""根據碼農條件預測工資的模型"""
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=200)
self.layer2 = nn.Linear(in_features=200, out_features=100)
self.layer3 = nn.Linear(in_features=100, out_features=1)
self.batchnorm1 = nn.BatchNorm1d(200)
self.batchnorm2 = nn.BatchNorm1d(100)
self.dropout1 = nn.Dropout(0.1)
self.dropout2 = nn.Dropout(0.1)
def forward(self, x):
hidden1 = self.dropout1(self.batchnorm1(nn.functional.relu(self.layer1(x))))
hidden2 = self.dropout2(self.batchnorm2(nn.functional.relu(self.layer2(hidden1))))
y = self.layer3(hidden2)
return y
def save_tensor(tensor, path):
"""保存 tensor 物件到檔案"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""從檔案讀取 tensor 物件"""
return torch.load(gzip.GzipFile(path, "rb"))
def prepare():
"""準備訓練"""
# 資料集轉換到 tensor 以后會保存在 data 檔案夾下
if not os.path.isdir("data"):
os.makedirs("data")
# 從 csv 讀取原始資料集,分批每次讀取 2000 行
for batch, df in enumerate(pandas.read_csv('salary.csv', chunksize=2000)):
dataset_tensor = torch.tensor(df.values, dtype=torch.float)
# 正規化輸入和輸出
dataset_tensor *= torch.tensor([0.01, 1, 0.01, 0.2, 0.2, 0.2, 0.2, 0.2, 0.0001])
# 切分訓練集 (60%),驗證集 (20%) 和測驗集 (20%)
random_indices = torch.randperm(dataset_tensor.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
training_set = dataset_tensor[traning_indices]
validating_set = dataset_tensor[validating_indices]
testing_set = dataset_tensor[testing_indices]
# 保存到硬碟
save_tensor(training_set, f"data/training_set.{batch}.pt")
save_tensor(validating_set, f"data/validating_set.{batch}.pt")
save_tensor(testing_set, f"data/testing_set.{batch}.pt")
print(f"batch {batch} saved")
def train():
"""開始訓練"""
# 創建模型實體
model = MyModel()
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
# 記錄訓練集和驗證集的正確率變化
traning_accuracy_history = []
validating_accuracy_history = []
# 記錄最高的驗證集正確率
validating_accuracy_highest = 0
validating_accuracy_highest_epoch = 0
# 讀取批次的工具函式
def read_batches(base_path):
for batch in itertools.count():
path = f"{base_path}.{batch}.pt"
if not os.path.isfile(path):
break
yield load_tensor(path)
# 計算正確率的工具函式
def calc_accuracy(actual, predicted):
return max(0, 1 - ((actual - predicted).abs() / actual.abs()).mean().item())
# 開始訓練程序
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
traning_accuracy_list = []
for batch in read_batches("data/training_set"):
# 切分小批次,有助于泛化模型
for index in range(0, batch.shape[0], 100):
# 劃分輸入和輸出
batch_x = batch[index:index+100,:-1]
batch_y = batch[index:index+100,-1:]
# 計算預測值
predicted = model(batch_x)
# 計算損失
loss = loss_function(predicted, batch_y)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄這一個批次的正確率,torch.no_grad 代表臨時禁用自動微分功能
with torch.no_grad():
traning_accuracy_list.append(calc_accuracy(batch_y, predicted))
traning_accuracy = sum(traning_accuracy_list) / len(traning_accuracy_list)
traning_accuracy_history.append(traning_accuracy)
print(f"training accuracy: {traning_accuracy}")
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
validating_accuracy_list = []
for batch in read_batches("data/validating_set"):
validating_accuracy_list.append(calc_accuracy(batch[:,-1:], model(batch[:,:-1])))
validating_accuracy = sum(validating_accuracy_list) / len(validating_accuracy_list)
validating_accuracy_history.append(validating_accuracy)
print(f"validating accuracy: {validating_accuracy}")
# 記錄最高的驗證集正確率與當時的模型狀態,判斷是否在 100 次訓練后仍然沒有重繪記錄
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 100:
# 在 100 次訓練后仍然沒有重繪記錄,結束訓練
print("stop training because highest validating accuracy not updated in 100 epoches")
break
# 使用達到最高正確率時的模型狀態
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 檢查測驗集
testing_accuracy_list = []
for batch in read_batches("data/testing_set"):
testing_accuracy_list.append(calc_accuracy(batch[:,-1:], model(batch[:,:-1])))
testing_accuracy = sum(testing_accuracy_list) / len(testing_accuracy_list)
print(f"testing accuracy: {testing_accuracy}")
# 顯示訓練集和驗證集的正確率變化
pyplot.plot(traning_accuracy_history, label="traning")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用訓練好的模型"""
parameters = [
"Age",
"Gender (0: Male, 1: Female)",
"Years of work experience",
"Java Skill (0 ~ 5)",
"NET Skill (0 ~ 5)",
"JS Skill (0 ~ 5)",
"CSS Skill (0 ~ 5)",
"HTML Skill (0 ~ 5)"
]
# 創建模型實體,加載訓練好的狀態,然后切換到驗證模式
model = MyModel()
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 詢問輸入并預測輸出
while True:
try:
x = torch.tensor([int(input(f"Your {p}: ")) for p in parameters], dtype=torch.float)
# 正規化輸入
x *= torch.tensor([0.01, 1, 0.01, 0.2, 0.2, 0.2, 0.2, 0.2])
# 轉換到 1 行 1 列的矩陣,這里其實可以不轉換但推薦這么做,因為不是所有模型都支持非批次輸入
x = x.view(1, len(x))
# 預測輸出
y = model(x)
# 反正規化輸出
y *= 10000
print("Your estimated salary:", y[0,0].item(), "\n")
except Exception as e:
print("error:", e)
def main():
"""主函式"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓程序可重現,你也可以選擇不這樣做
torch.random.manual_seed(0)
# 根據命令列引數選擇操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
最終訓練結果如下,驗證集和測驗集正確率達到了 94.3% (前一篇分別是 93.3% 和 93.1%):
epoch: 848
training accuracy: 0.929181088420252
validating accuracy: 0.9417830203473568
stop training because highest validating accuracy not updated in 100 epoches
highest validating accuracy: 0.9437697219848633 from epoch 747
testing accuracy: 0.9438129015266895
正確率變化如下:
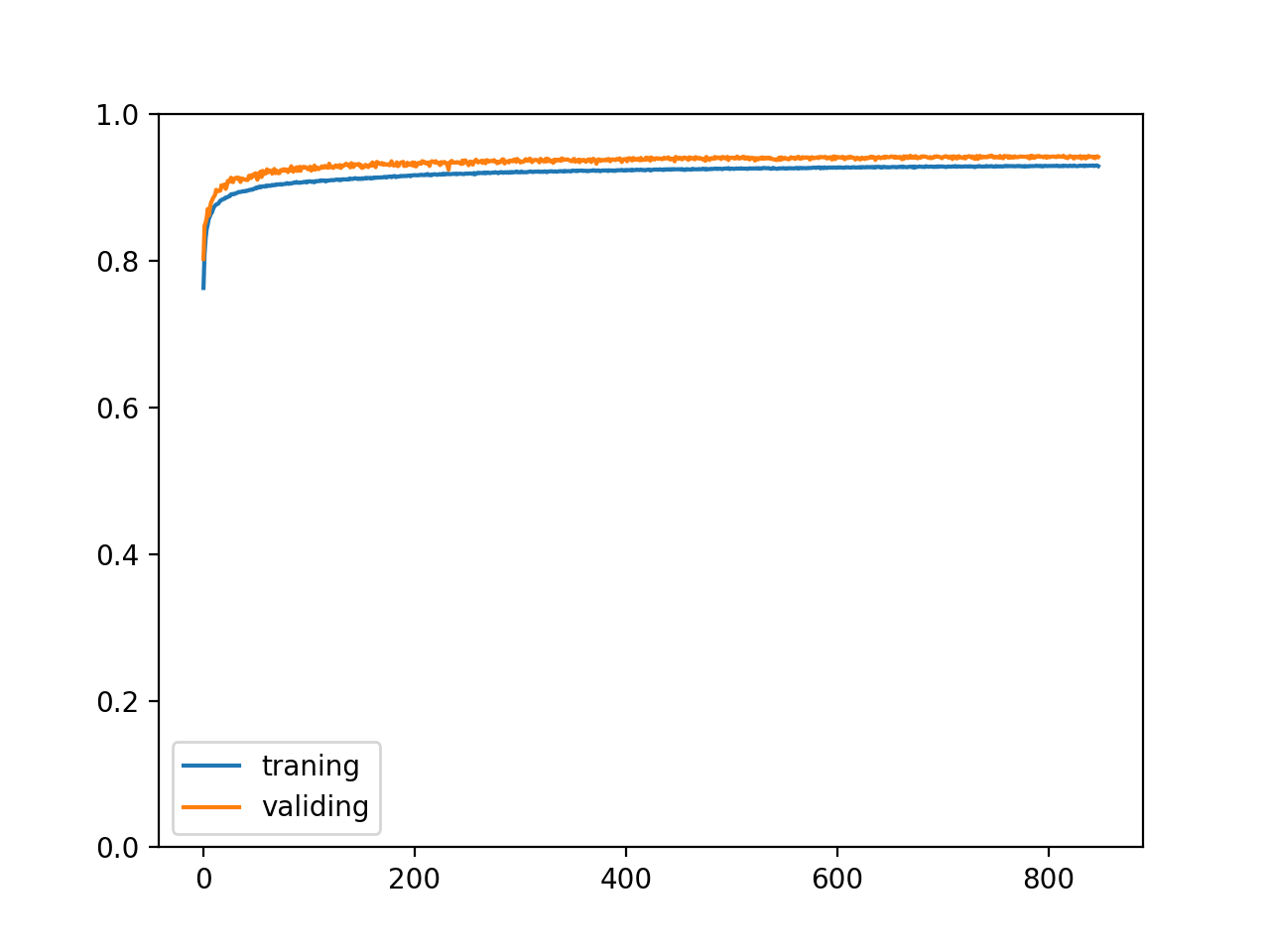
算是圓滿成功了叭??,
寫在最后
在這一篇我們看到了各種改進訓練程序和改善訓練效果的手法,預測了各種各樣碼農的工資??,接下來我們可以試著做一些不同的事情了,下一篇會介紹遞回模型 RNN,LSTM 與 GRU,它們可以用于處理不定長度的資料,實作根據背景關系分類,預測趨勢,自動補全等功能,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/31262.html
標籤:其他