@目錄
- 驗證碼分析
- 全國增值稅發票查驗平臺驗證碼
- 8.24 增加了點騷操作
- 8.15 小白救星(可視化操作)
- 7.17 更新 (必讀)
- 7.16 更新(關于發票查驗服務本身)
- 7.14 更新(驗證碼識別率截至15號有97.5%了其實)
- 7.13 更新(識別率回歸,初步到94%)
- 7.12 更新(生成器調參思路)
- 7.6 更新(官網更新,識別率翻車到90%)
- 6.19 更新(訓練和部署原始碼+JS逆向思路)
- 驗證碼分析
- 識別思路
- 實驗成果
驗證碼分析
如圖所示:影像驗證碼,識別指定顏色的文字,

全國增值稅發票查驗平臺驗證碼
8.24 增加了點騷操作
針對有些白嫖黨老是把別人的試用額度給占滿了,給白嫖提升一點小難度,歡迎闖關,
8.15 小白救星(可視化操作)
大多大朋友門還是喜歡往介面里懟一些奇奇怪怪的東西,為了給不會呼叫介面的小白更好的明白這個介面是怎么一回事,更新了一個簡陋的操作界面
再次宣告: 我一直強調要【原圖】,不要【截圖】,【模擬瀏覽器選手】請你們【放棄】,速度【慢】,只有人工打碼平臺支持你們的截圖識別,本介面針對【企業用戶】,連【右鍵-另存為圖片】都不會的請在家長的陪同下使用,
1.本地提交一張【90x35】大小的圖片;
2. 選擇需要識別的【顏色】;
3. 點擊【提交】即可;
注意: 截圖和原圖天差地別,總有人頑固而偏執的以為看起來沒什么區別,這就體現了腦子和讀書的重要性,不會獲取原圖的大師兄請點擊右上方/左上方關閉按鈕,

測驗地址:
http://152.136.207.29:19812/preview
7.17 更新 (必讀)
被迫日更營業,不好意思了,質疑我另有所圖可以,可是不能質疑我的技術啊,
專票查詢要輸入金額(帶小數點),校驗碼是6位,這不是常識嗎? 居然還有人跑來問我為什么核驗結果不一致,100元和100.80元能一樣嗎,0.8元就不是錢了嗎?
之前驗證碼也是,居然有不少人截屏傳了一張 [230x75] 的圖過來,測完氣乎乎的說我騙人,識別率根本就是0,我也是服氣,都不看文章的嗎???

以至于最終被迫妥協限制了輸入 [90x35] 尺寸,除了人工打碼平臺沒人會去識別截圖的,
拜托了各位老鐵們,好好看看文章吧,我沒有寫廢話的習慣,我本著釣魚的目的寫的介面,介面各項指標都是和描述一致的,任何測評資料都是絲毫不摻水分的,
7.16 更新(關于發票查驗服務本身)
驗證碼識別率是不需要更高了,我看有人找我了解發票查驗這塊,也順帶給個測驗好了,目前支持全發票種類,你們看到的沒錯,是全發票種類,市面上的API介面也不一定能支持,其中包括(湊字數):增值稅專用發票、增值稅專用發票帶清單、貨物運輸業增值稅專用發票、增值稅普通發票、增值稅電子專用發票、增值稅電子普通發票、增值稅普通發票(卷票)、通行費xxx增值稅電子普通發票、二手車銷售統一發票,
恕我直言,就算是專門做查驗服務的企業也不一定有我們業余開發的專業,不信的盡管來對比測驗hhhh,
查驗服務測驗介面:
| 請求地址 | Content-Type | 引數形式 | 請求方法 |
|---|---|---|---|
| http://106.53.31.110:8080/check?fpdm=3100171320&fphm=79262007&date=20170620&code=184553&channel=yd | url | JSON | GET |
具體引數:
| 引數名 | 必選 | 型別 | 說明 |
|---|---|---|---|
| fpdm | Yes | String | 發票代碼 |
| fphm | Yes | String | 發票號碼 |
| date | Yes | String | 發票時間 |
| code | Yes | String | 開具金額或者校驗六位,不知道就不填,服務器會回傳提示之后再根據填寫, |
| channel | Yes | String | 你猜,不填就拉閘 |
回傳結果:
| 引數名 | 型別 | 說明 |
|---|---|---|
| message | String | 結果提示 |
| code | String | 0為成功處理 |
| time | String | 請求所花費的時間(毫秒) |
| data | String | 決議的資料 |
| info | String | 原始資料 |
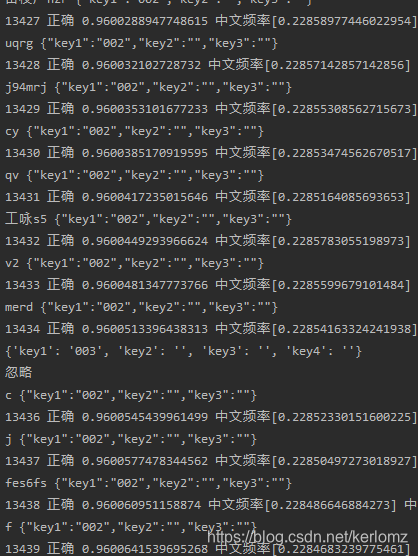
7.14 更新(驗證碼識別率截至15號有97.5%了其實)
后來想想94不好看,就跑到96%了,測驗次數為一萬個官網請求,這樣又是全網最高識別率,
7.13 更新(識別率回歸,初步到94%)
由于沒有更高的需求,中文字符集訓練過于耗時,GPU資源也不能一直用來跑這個,決定停止訓練,目前版本官網實測5千次請求,94.3%準確率,
7.12 更新(生成器調參思路)
最新的思路:樣本生成器自動調參的方法,當然了寫生成器需要有一定的技術含量,需要弄清楚哪些是變數,CSDN有位大佬寫過python版本的生成器,我下載來生成了一波,發現相似度比我簡書放出的釣魚版本還低hhhh,通過預留引數介面基于給出的一張樣圖,生成各種參數的生成樣本,自動對比生成樣本和給定對照樣本的相似度,取最佳引數即可獲得官網演算法的最佳引數,調參成本也就生成w級別的樣本即可找出最佳引數,對于計算機而言1分鐘不到,這樣只要掌握的通用生成器,只要在一定范圍內更新都不是問題,此方法過于偏門,其實就算公開了思路,但是能寫出來的人估計也沒幾個,有錢的大公司每次更新無腦去人工打碼采集樣本就好了,小公司還是不要做什么發票查驗了,實力勸退,
7.6 更新(官網更新,識別率翻車到90%)
由于官網會測驗本介面,對生成引數進行演算法微調,不論是字體樣式,顏色配比,字符集等等都針對這CSDN的兩篇文章的生成器做了對抗,由于之前訓練的時候盡可能考慮到模型的泛化能力,測驗介面識別率降比不大,目前仍有90%的識別率,為了保證模型的持續抗更新能力,目前在線介面已不再進行更新,
之前技術不精,思路略顯笨拙,新的模型輔助了全新的生成器演算法,能更好的對抗和適應各種引數的更新,后續或會開放最新的防更新思路,如何提高模型的泛化能力,最新介面請直接聯系我,白嫖勿擾,
6.19 更新(訓練和部署原始碼+JS逆向思路)
有人說我文章沒有干貨只有思路,這里我分享一下原始碼,訓練及部署的教程:
https://blog.csdn.net/kerlomz/article/details/86706542
至于國稅總局的發票查驗平臺JS這塊的逆向可以參考:
https://blog.csdn.net/qq_35228149/article/details/106818057
驗證碼分析
如圖所示:影像驗證碼,識別指定顏色的文字,
識別思路
首先有幾條道路可以通向羅馬,這里不分先后優劣一一講述,
- 顏色提取的思路,可以采用HSV/K-means聚類進行顏色的分離提取:效果如下:
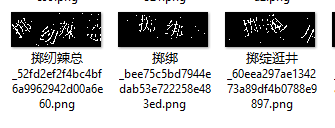
弊端顯而易見,會有較大的特征丟失,識別率有較大的提升瓶頸,經過測驗,中英文+漢字的識別率在90%左右, - 不分離顏色的思路,該方案有兩種處理方法:
(1)同時預測顏色和字符內容,這種方法看起來比較正統,但是成本較高,需要標注每張圖的顏色和字符內容,這個要求有多高呢,一般的打碼平臺是無法提供這樣的結果的,打碼平臺只回傳對應顏色的內容,只能人工標注,那么需要多少樣本呢?筆者訓練的識別率98的模型用了100w左右的樣本,一張這樣的樣本標注假設需要0.1元,那么100w樣本需要10w標注費用,假設0.01元,也要1w的標注費用,但是驗證碼高質量的人工標注幾乎是不存在的,因為很多樣本,人眼的識別率是不如機器的,其次,標注團隊不一定都是高學歷,官網使用的字符集并不一定尋常人都認識,大多不會去深究,再者,相似的漢字也是容易混淆的,一個漢字旋轉之后像另一個漢字是很常見的現象,所以總而言之,總體標注的準確率大概率不會超過85%, 所以即使有錢,也不一定能獲得最好的資源,這方法看起來并不可取,有一種節約成本的辦法,可以通過演算法生成樣本,但是呢,生成的識別率英文數字還可以,中文的識別率就低的可憐了,附上生成方法:https://www.jianshu.com/p/da1b972e24f2 ,當然這個生成演算法是需要修改加工的,原始演算法識別率不會超過40%,綜合多個維度的演算法微調去和官網的演算法進行碰撞匹配,才能達到最終的效果,所以在此先勸退伸手黨,CSDN也有另一篇Python版的生成演算法,可以自行測驗,生成的圖片比我這個還不像hhhh,也是需要自行修改的,
(2)每個顏色分別訓練一個模型, 這種方法看起來有點蠢,但是確實比較合適有效的辦法了,可以輕松借助打碼平臺的回傳結果標注樣本,需要的顏色可以通過官網提供的欄位取到,回傳結果通過打碼平臺識別得到,這樣一組合,樣本就有了,這種方法的成本相對較低,樣本數不變的前提下,打碼價格低于人工標注的成本,不過人工打碼回應平均在10-20秒之間,采集如此大量的樣本資料可能要把業務都熬沒了,其次還是一個認知水平問題,打碼平臺的打手普遍學歷不高,尚有不少漢字是人不齊全的,很有可能導致樣本極度不均衡,字符集不全等等,歸根到底高質量的樣本還是得從生成演算法入手,慢慢提升模型對漢字的辨識度,筆者訓練的樣本用了100w,每個顏色分別訓練這樣成本還是下不來,四種顏色就是500w樣本,官網的每次獲取圖片的時候顏色隨機出現的概率也不一定是1/4,
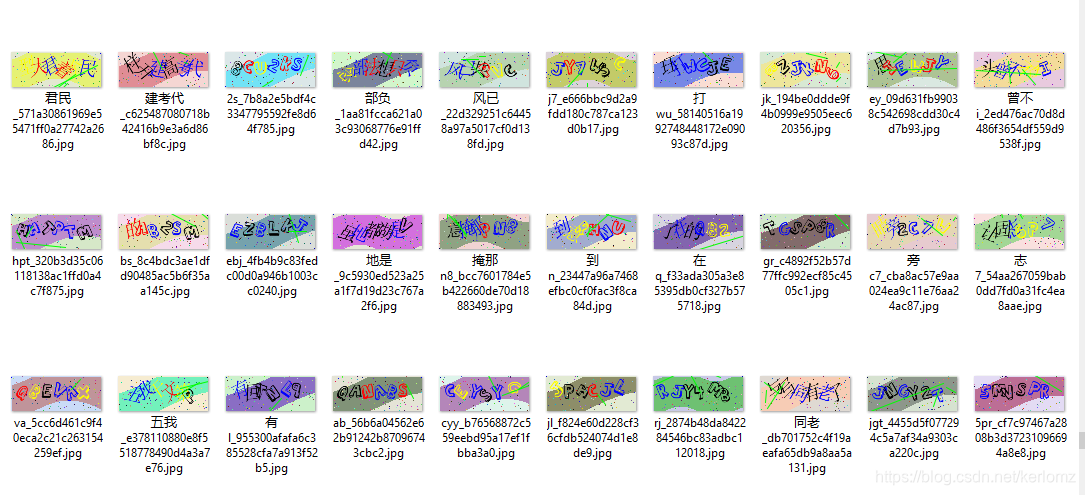
(3)把所有顏色都通過顏色變換為一種顏色,整體思路同(2),如下圖,筆者將黑色轉換為紅色,我們只需要訓練紅色的圖片:藍轉紅、黃轉紅、黑轉紅,樣本成本只有采集一種顏色的成本,看起來是目前位置最佳的方案了,事實也是如此的,但是呢,100w的總樣本量對于普通人來說也是一筆不小的花銷,即便有了樣本能做出來也需要花費不少的時間和精力,
有些演算法作業者可能會低估樣本的實際需求量,3.6k分類,中文字體小,容易混淆相似的字多,不同的角度重疊干擾都會大大增加,過于復雜的網路對性能的要求也高,為了平衡性能和準確率,足夠數量的樣本支撐是必須的,100w樣本量其實不大,一點都不要驚訝,7月之后的版本筆者用了6k字符集做的抗更新模型,訓練足足花了1周,
不過采集樣本不是單純的接打碼平臺就完事了,需要經過官網判斷,只有通過驗證,正確的樣本才保存下來,這樣有效的樣本對提高識別率才有幫助,
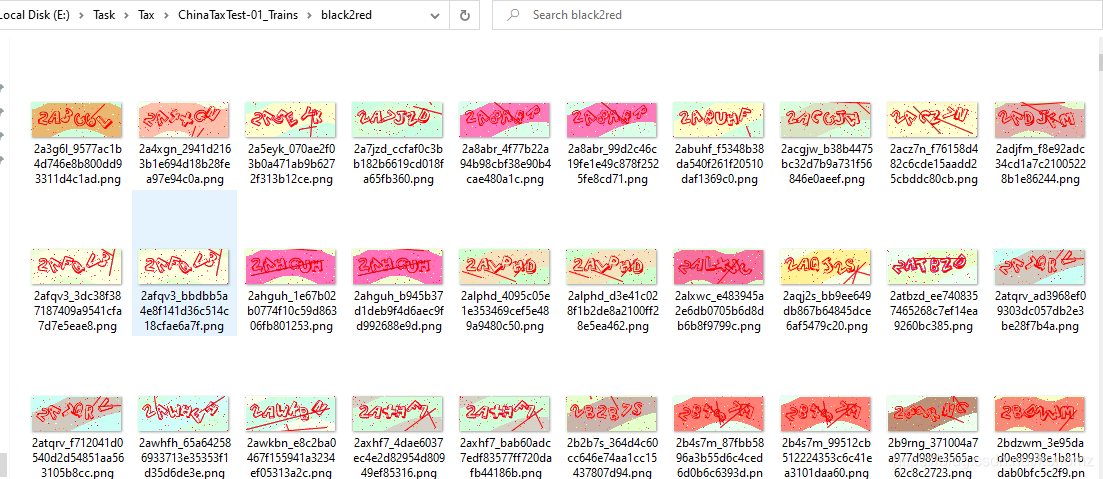
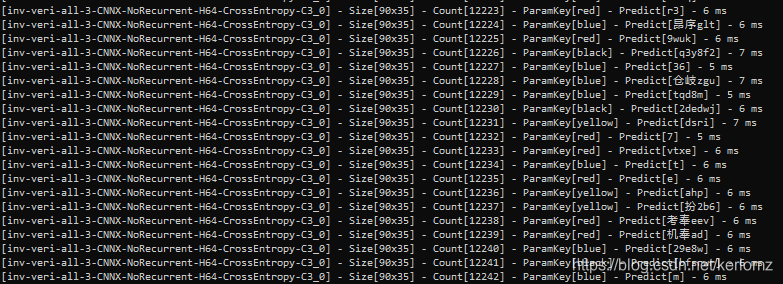
實驗成果

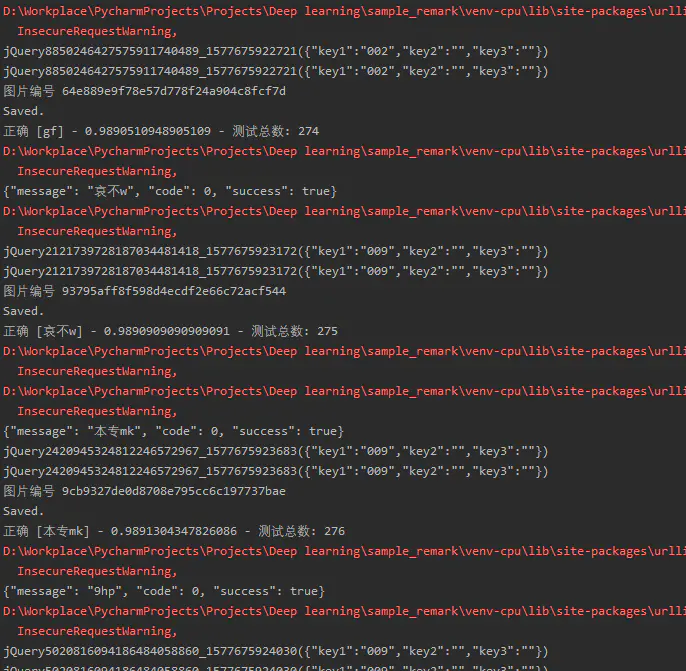
筆者實時對接官網對實驗模型進行檢驗,結果如上圖,測驗了200+次,識別率達到98%以上,識別速度的話,CPU大概5-8毫秒左右,部署騰訊云1核1G服務器實測10ms-12ms,模型大概3mb,
附上介面僅供測驗,為了防止濫用,介面每天只支持請求500次(此介面已不回傳文本識別結果,采用圖片結果代替,請在上面提供的測驗頁面中測驗):
http://152.136.207.29:19812/preview
| 請求地址 | Content-Type | 引數形式 | 請求方法 |
|---|---|---|---|
| http://152.136.207.29:19812/captcha/v1 | application/json | JSON | POST |
具體引數:
| 引數名 | 必選 | 型別 | 說明 |
|---|---|---|---|
| image | Yes | String | Base64 編碼 |
| param_key | No | String | 顏色,red\blue\green\black\yellow |
請求為JSON格式,形如:
{"image": "iVBORw0KGgoAAAANSUhEUgAAAFoAAAAjCAIAAA...base64編碼后的影像二進制流", "param_key ": "blue"}
注意:圖片只能是 90x35 尺寸的原圖,請勿截圖
也請勿使用 模擬瀏覽器 的截圖獲取,如果不知道如何使用協議獲取驗證碼,可以參考這個文章的方法:
https://blog.csdn.net/kerlomz/article/details/106793781
若對最新的JS逆向感興趣可以關注作者,
若以上方法都不清楚,可以【另存為圖片】,本模型針對【原圖】訓練,
截圖無法識別,不理解的可以先了解下深度學習 影像識別原理 ,或咨詢 作者 ,
回傳結果:
| 引數名 | 型別 | 說明 |
|---|---|---|
| message | String | 識別結果或錯誤訊息 |
| code | String | 狀態碼 |
| success | String | 是否請求成功 |
該回傳為JSON格式,形如:
{'uid': "9b5a6a34-9693-11ea-b6f9-525400a21e62", "message": "xxxx", "code": 0, "success": true}
請勿惡意使用,若超出當日限制將回傳:
{'uid': "9b5a6a34-9693-11ea-b6f9-525400a21e62", 'message': '超出當日請求限制,請聯系作者QQ:27009583', 'success': False, 'code': -555}
若回傳 400 則表示資料包格式有誤,請檢查是否符合JSON標準,
若回傳 405 則請檢查確保使用POST方式請求,
Python示例:
import requests
import base64
with open(r"C:\1.png", "rb") as f:
b = f.read()
# param_key: black-全黑色,red-紅色,blue-藍色,yellow-黃色
r = requests.post("http://152.136.207.29:19812/captcha/v1", json={
"image": base64.b64encode(b).decode(), "param_key": "yellow"
})
print(r.json())
如有疑問可以加我QQ:27009583
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/31312.html
標籤:其他