一.概述
為達到服務人員有效的對現場資料庫環境進行管理、配置和維護,保障資訊系統安全和穩定的運行以及具備日后對資料庫系統風險的評估能力,推出本巡檢方案,
主要目的:
- 了解現場硬體環境
- 了解作業系統環境
- 了解當前I/O狀況
- 了解資料庫版本以及資料庫架構
- 了解當前資料庫風險點
二.適用范圍
適用于接手新專案現場或者接手他人負責的專案,盡快熟悉當前專案環境完整的資訊可以快速有效完成后續的故障處理、事件跟蹤和現場配合作業,
三.環境確認
- 資料庫環境
1.1資料庫運行架構
確認當前資料庫的運行架構,單機/cluster/standby/HA
1.2資料庫安裝目錄
接觸新的專案時,想要管理好資料庫服務首先應找到資料庫的安裝目錄,查看環境變數$KINGBASE_HOME,該環境變數在部署時也應該設定方便其他人員維護,
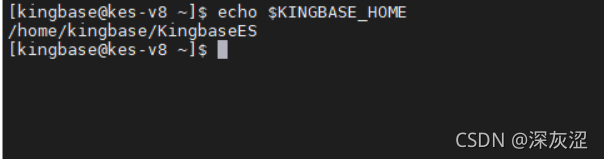
1.3 資料庫版本

1.4 資料庫data目錄位置
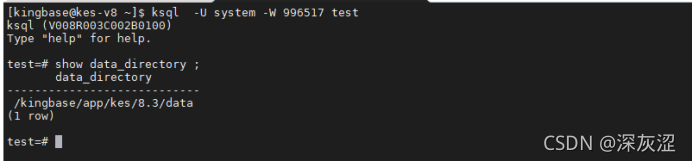
- 注意:目前有些專案data目錄是軟鏈接形式,需留意一下,
1.5 資料庫啟動時間
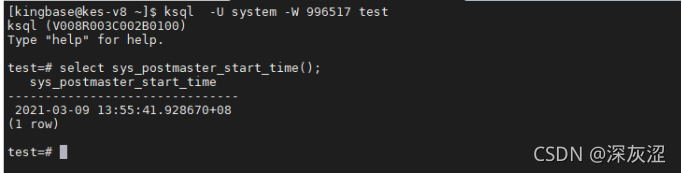
- V7版本使用select sys_kingbase_start_time()
1.6 資料庫license資訊
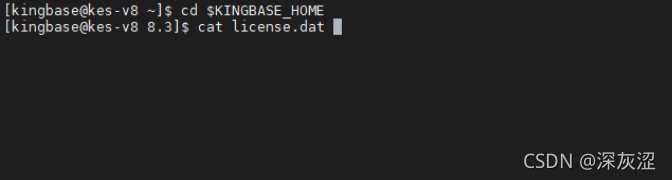
- V8版本查看$KINGBASE_HOME/license.dat
- V7版本查看$KINGBASE_HOME/bin/license.dat
1.7存盤可用空間
df -hT
1.8 備份檔案有效性
解壓備份壓縮檔案,查看備份日志確認當前備份有效性,
2.硬體以及作業系統
2.1作業系統型別
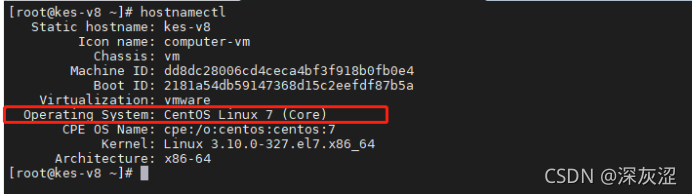
- hostnamectl命令適用于所有Linux作業系統(需要3.0以上內核),查看/etc/issue、/etc/redhat-release檔案等方法
2.2芯片型別
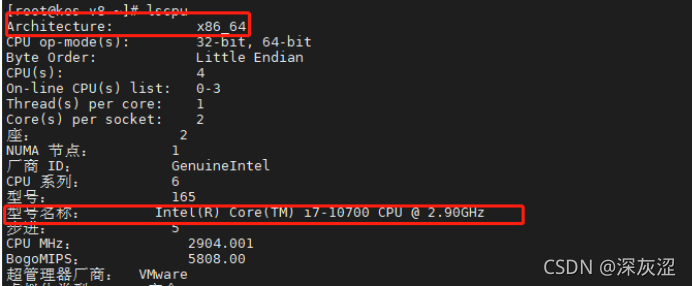
- 需要關注的上圖示記的位置,cpu型別和CPU品牌廠家
2.3記憶體

2.4系統日志

四.環境檢查
1.資料庫
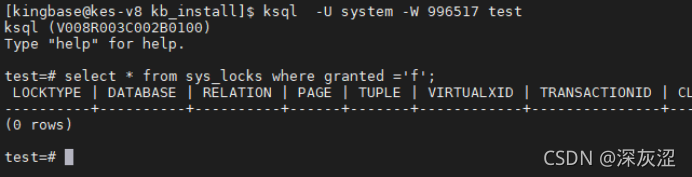
1.1檢查資料庫表鎖資訊
1.2 檢查資料庫鏈接資訊

select datname,usename,client_addr,query,state,now() - query_start as time from sys_stat_activity where time > '03:00:00' and state = 'idle in transaction';
- 該陳述句查詢出超過3小時的長連SQL,根據情況適當處理,
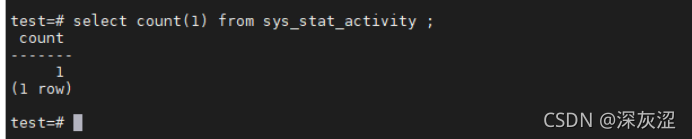
1.3檢查資料庫當前連接數&最大連接數
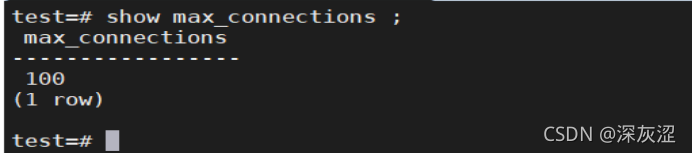
1.4檢查各資料庫大小
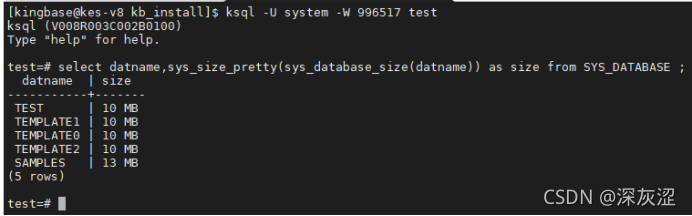
1.5查詢各個庫的年齡
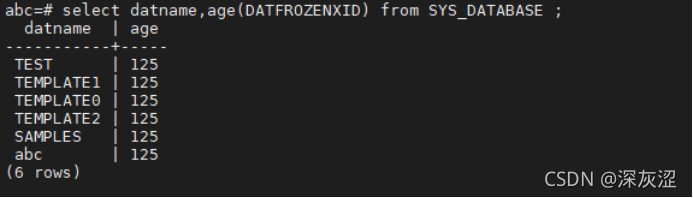
- 如果age列中有超過 5億,應立即進行事務回收,
1.6 資料庫擴展插件
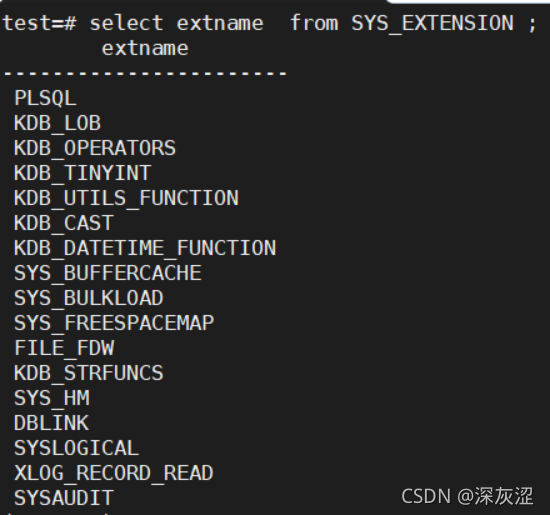
2.作業系統
2.1 CPU使用情況

- 使用top檢查資訊,判斷資源使用情況,
2.2 記憶體使用情況

- 使用free -m 檢查資訊,其中total為總記憶體量;used為使用記憶體量;free 為記憶體剩余量,
2.3 系統I/O情況
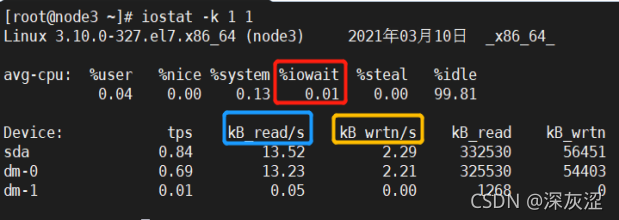
- 如上所示,藍色、黃色部分為磁盤讀寫情況,紅色部分為CPU I/O等待情況,
2.4 系統是否存在僵尸行程

- 系統所能使用的行程號是有限的,如果大量的產生僵死行程,將因為沒有可用的行程號而導致系統不能產生新的行程,
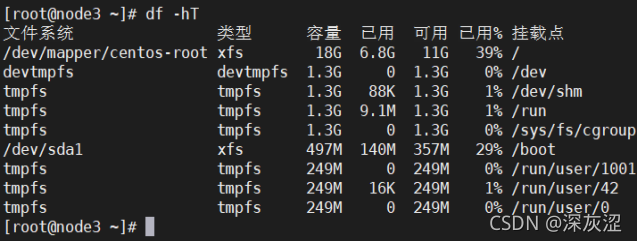
2.5磁盤使用情況
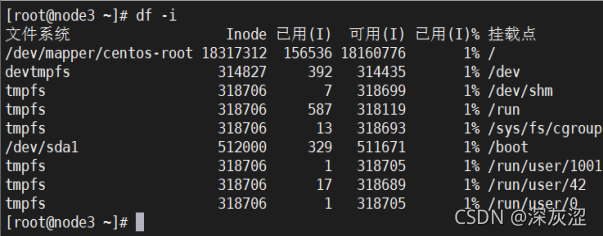
2.6 inode節點資訊
2.7 服務器負載
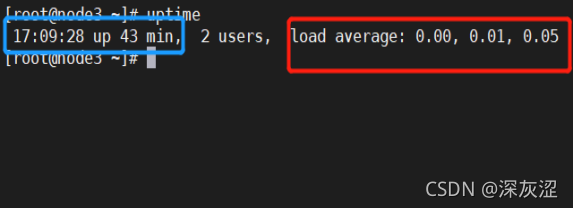
- 藍色部分代表系統啟動時間,紅色部分代表系統的平均負載,3個地方數字正常不超10,
2.8 防火墻狀態

五.性能優化
1.作業系統
1.1內核組態檔檢查
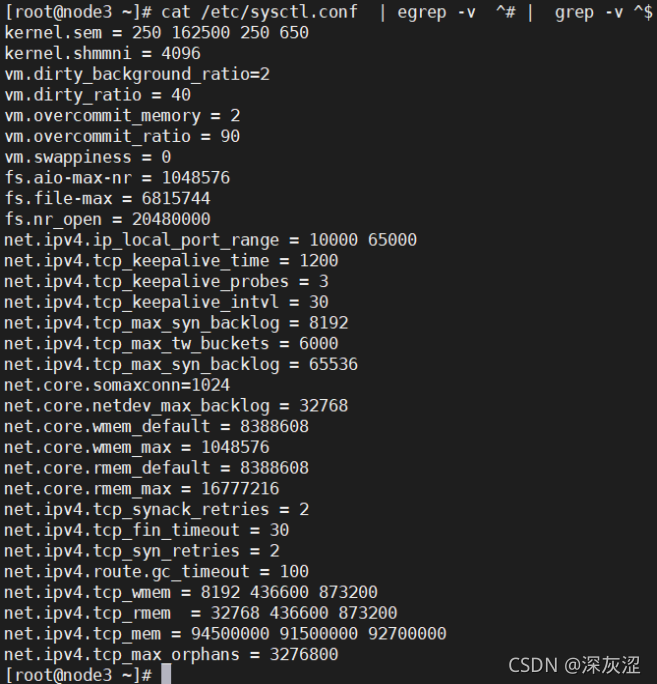
1.2資源限制檔案檢查
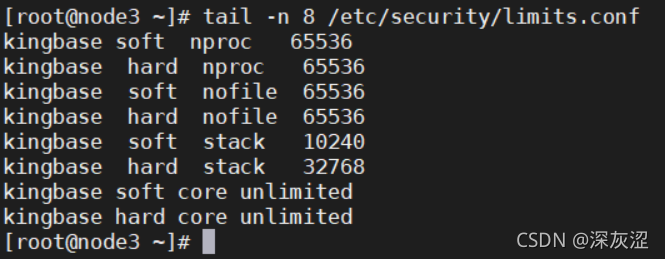
1.3電源管理組態檔

- 在centos7.2中,systemd-logind 服務引入了一個新特性,該新特性是:當一個user 完全退出os之后,remove掉所有的IPC objects,
1.4 selinux狀態
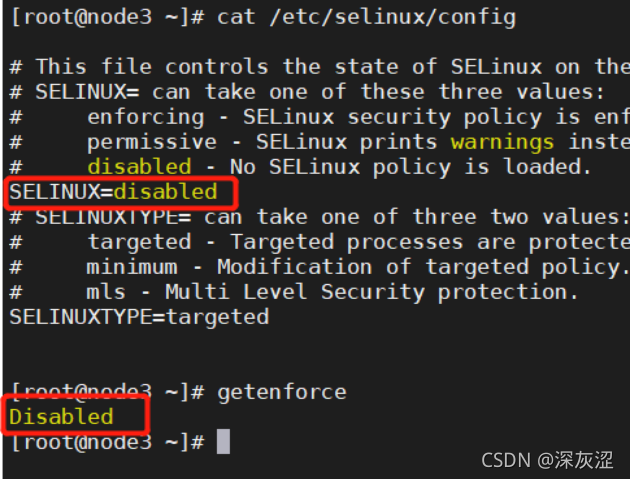
1.5磁盤調度策略
- 查看/sys/block/dm-0/queue/scheduler檔案,推薦deadline
2.資料庫
2.1 kingbase引數優化
cat kingbase.conf | grep -v ^# | grep -v ^$ | grep ^[a-zA-Z] | awk -F'#' '{print $1}'
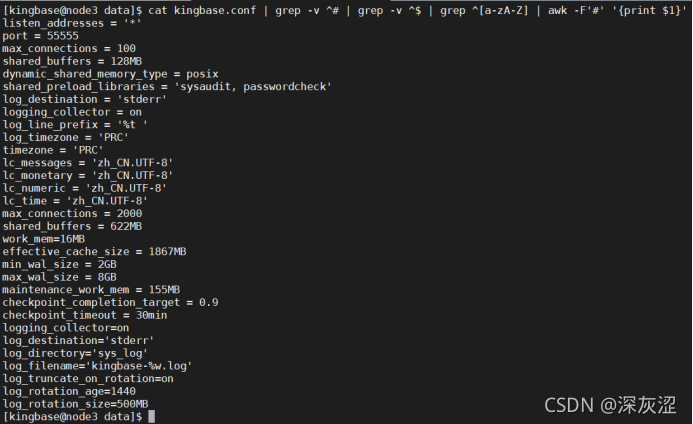
2.2 max_connections=1000
- 資料庫最大連接數,跟進現場需求適當調整
2.3 shared_buffers=總記憶體*25%
- 資料庫共享快取,建議設定服務器記憶體大小的25%
2.4 work_mem=16MB
- SQL陳述句在使用到排序子句的時候所使用到的最大記憶體
2.5 effective_cache_size=總記憶體*50%
- 告知SQL優化器有多少記憶體可用與于磁盤快取,不會實際分發記憶體,建議總記憶體50%
2.6 maintenance_work_mem=1GB
- 定義的記憶體主要影響vacuum,analyze,create index,reindex等操作,設定越高該類命令執行速度越快,
2.7 logging_collector=on
- 開啟后進行資料庫日志收集,
2.8 log_destination=’stderr’
- 日志輸出格式,三種格式stderr,csvlog,syslog,默認stderr
2.9 log_directory=’sys_log’
- 資料庫日志存放路徑,默認sys_log
2.10 log_filename='kingbase-%w.log'
- 資料庫日志命令格式,常見:%w周,%d日,%m月
2.11 log_truncate_on_rotation=on
- 設定為on的話,如果新建了一個同名的日志檔案,則會清空原來的檔案,再寫入日志,而不是在后面追加,
2.12 log_rotation_age=1440
- 當logging_collector被啟用時,這個引數決定一個個體日志檔案的最長生命期,當這些分鐘過去后,一個新的日志檔案將被創建,
2.13 log_rotation_size=500MB
- 這個引數決定一個個體日志檔案的最大尺寸,當這么多千位元組被發送到一個日志檔案后,將創建一個新的日志檔案,
2.14 查看各資料庫中表膨脹資訊
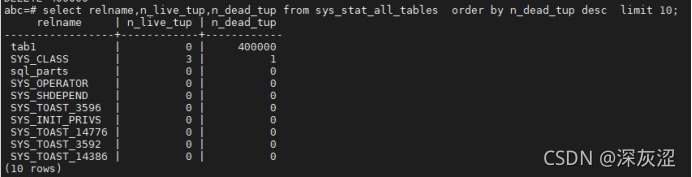
2.15 查詢大于10GB以及年齡大于5億的表

select relname,age(relfrozenxid),sys_relation_size(oid)/1024/1024/1024.0 table_size from sys_class where relkind='r' and age(relfrozenxid)>500000000 and sys_relation_size(oid)/1024/1024/1024 > 10 order by 3 desc;
- 專案維護計劃
資料庫產品維護服務,主要包括:資料庫基本使用培訓、常見故障處理方法培訓以及對資料庫的定期上門巡檢服務,
系統日志、網路狀況、系統空間狀況、存盤設備狀態、系統性能、資料庫各種檔案的狀態與配置、資料庫安全審計、資料庫配置的合理性、實體的運行效率等,
七.檔案交付
- 巡檢報告
定期對各專案進行的健康檢查匯總的檔案形式報告提供可用并歸檔,
- 事件分析報告
資料庫產生故障后,對事件的整個程序記錄提交用戶,也方便部門后續復盤,
- 資料庫升級方案
專案中資料庫升級需要提前準備好升級方案,規劃好升級步驟、思路不容易出錯,所有的升級方案中必須有回退流程,再出現不可控情況時可以回退到升級前的版本,
- 資料庫專案檔案
記錄資料庫的詳細資訊如:硬體環境、資料庫版本,在專案交接時應將專案資訊完善歸納成檔案有利于后續運維,
- 客戶服務記錄單
外出到專案現場作業結束時,需要客戶或集成商簽字認可我們的作業,
八.服務體系
- 電話支持
當發生問題時,可以提供給用戶及時有效的24小時電話支持,服務人員做好客戶服務需求的記錄,并向用戶明確服務需求的解決方式、程序和最終的解決辦法,提供遠程服務接入、微信和電話服務支持,
- 現場服務
如果用戶的問題不能通過電話解決,會立刻派工程師到現場為用戶解決問題,服務人員對解決的程序進行記錄,并向用戶提供解決問題的報告.包括問題原因、解決方法、解決問題的方式和程序,以及建議用戶對系統進行正常使用的指導和培訓,問題解決后需要用戶進行確認,
- 定期巡檢服務
保證資料庫長久穩定的運行,為專案現場制定巡檢服務,每月對資料庫進行一次月度巡檢,每季度進行一次季度巡檢,每半年進行一次半年度巡檢以及每年一次的年度巡檢,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/313182.html
標籤:其他
上一篇:小程式獲取視頻縮略圖
下一篇:Oracle分布式分片技術——實作兩主機上的Oracle19c資料庫(CentOS7與windows10)之間建立分布式資料庫管理