三、Spark DataSet基本操作
3.1、DataSet簡介
- DataSet是分布式的資料集合,DataSet提供了強型別支持,也是在RDD的每行資料加了型別約束,
- DateSet整合了RDD和DataFrame的優點,支持結構化和非結構化資料,
- DataFrame表示為DataSet[Row],即DataSet的子集,
- DataSet是面向物件的編程介面,可以通過JVM的物件進行構建DataSet,
3.1.1、DataFrame的缺點
- 編譯時不能型別轉化安全檢查,運行時才能確定是否有問題
- 對于物件支持不友好,rdd內部資料直接以java物件存盤,dataframe記憶體存盤的是row物件而不能是自定義物件
3.1.2、DateSet的優點
- DateSet整合了RDD和DataFrame的優點,支持結構化和非結構化資料
- 和RDD一樣,支持自定義物件存盤
- 和DataFrame一樣,支持結構化資料的sql查詢
- 采用堆外記憶體存盤,gc友好
- 型別轉化安全,代碼友好
3.2、創建DataSet
- 從集合創建DataSet
- 從rdd創建DataSet
- 從DataFrame創建DataSet
3.2.1、從集合創建DataSet
createDataset[T](data: List[T])

3.2.2、從rdd創建DataSet
createDataset[T](data: RDD[T])
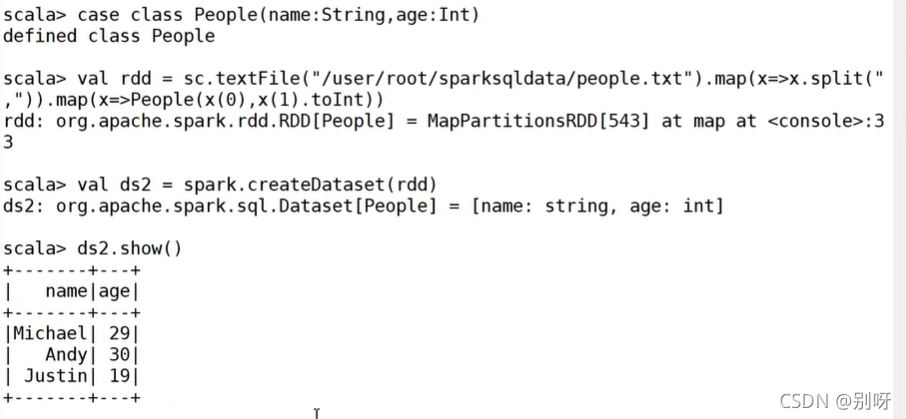
3.2.3、從DataFrame創建DataSet
dataSet=dataFrame.as[強型別]


任務1:讀取Hive表中的超市商品銷售資料
- 創建Hive表
- 匯入用戶購買資料到Hive表
- 讀取Hive表資料創建DataSet
資料 GoodOrder.csv:

步驟:
① 因為是csv,所以我們先上傳到hdfs上

② 打開spark-shell,通過DataFrame方式保存到hive中
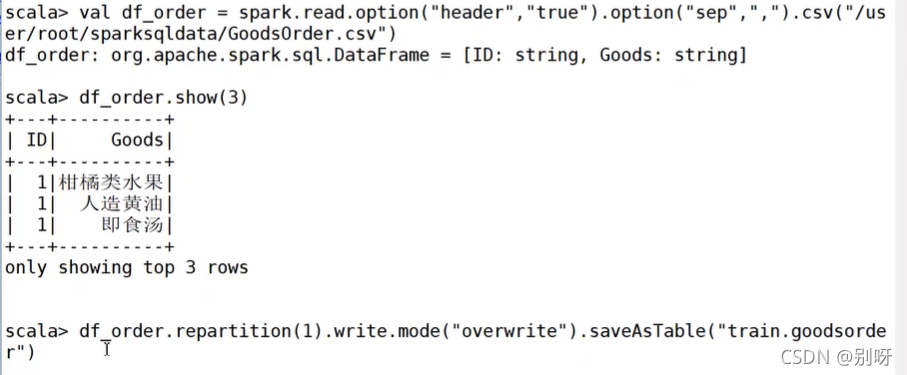
hive中查看資料:
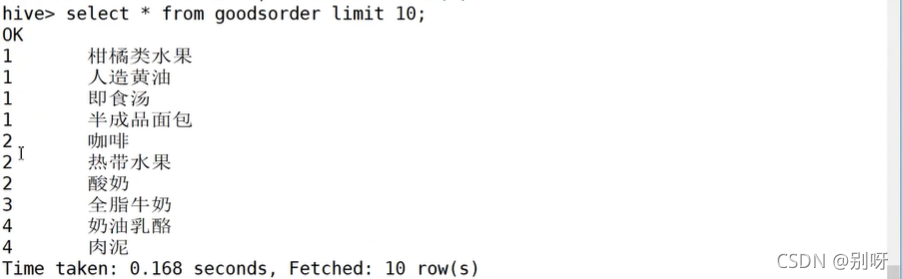
③ 讀取Hive表資料創建DataSet

3.3、DataSet API
應用示例:
(這是一個DataSet)


任務2:統計每件商品的銷量
- 根據商品分組統計商品銷量
- 將統計結果保存到Hive
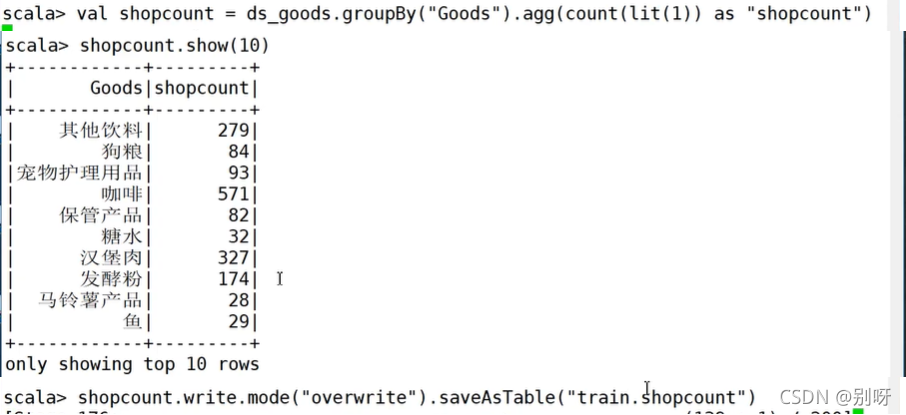
hive查看:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/313186.html
標籤:其他
上一篇:Oracle分布式分片技術——實作兩主機上的Oracle19c資料庫(CentOS7與windows10)之間建立分布式資料庫管理