我正在使用 Azure Synapse 呼叫 REST API,回傳資料集如下所示:
{
"links": [
{
"rel": "next",
"href": "[myRESTendpoint]?limit=1000&offset=1000"
},
{
"rel": "last",
"href": "[myRESTendpoint]?limit=1000&offset=60000"
},
{
"rel": "self",
"href": "[myRESTendpoint]"
}
],
"count": 1000,
"hasMore": true,
"items": [
{
"links": [],
"closedate": "6/16/2014",
"id": "16917",
"number": "62000",
"status": "H",
"tranid": "0062000"
},...
],
"offset": 0,
"totalResults": 60316
}
我熟悉對單個端點進行 REST 呼叫,該端點可以使用 Synapse 管道通過一次呼叫回傳所有資料,但是這個特定的 REST 端點對僅回傳 1000 條記錄有一個硬性限制,但它確實提供了一個名為“有更多的”。
有沒有辦法在 Synapse 管道中遞回地進行休息呼叫,直到“hasMore”屬性等于 false?
其最終目標是將資料沉入專用 SQL 池或 ADLS2 并從那里進行轉換。
uj5u.com熱心網友回復:
我曾嘗試使用 Azure 資料工廠實作相同的場景,這似乎更合適且更容易實作目標“最終目標是將資料接收到專用 SQL 池或 ADLS2 并從那里轉換”。
由于您必須遞回地點擊頁面以獲取 1000 條記錄,如果回應標頭/回應正文包含下一頁的 URL,您可以按以下方式設定它。


如果下一頁鏈接或查詢引數未包含在回應標頭/正文中,則您不太可能使用該功能。
或者,您可以利用回圈邏輯并執行復制活動。
在 Rest 連接器中創建兩個引數:
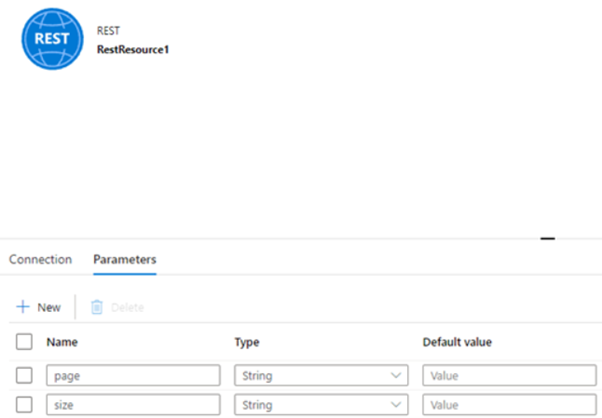
填寫 RestConnector 的相對 URL 的引數。
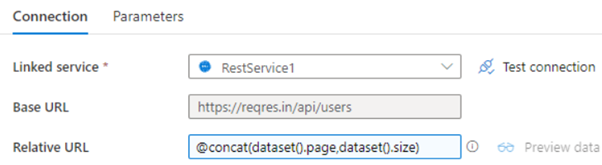
使用設定變數操作,該變數的值將在回圈中增加。對于每個回圈,Copy Activity 的 URL 都是動態設定的。如果要回圈或迭代,可以使用直到活動。
選擇:
根據我的經驗,REST 連接分頁非常嚴格。通常將動作放在一個回圈中。因此,有更多的控制權。FOREACH 回圈,這里
uj5u.com熱心網友回復:
對于那些跟隨執行緒的人,我使用了 IpsitaDash-MT 的建議,使用 ForEach 回圈。對于此 API,當進行呼叫時,我會在呼叫結束時回傳一個名為“totalResults”的屬性。以下是我用來實作我想要做的事情的步驟:
- 對 API 進行虛擬呼叫以獲取“totalResults”引數。這只是回傳我希望獲得的結果數量的呼叫。在這個 API 的情況下,請求的主體是一個 SQL 陳述句,所以當發出虛擬請求時,我只要求我希望得到的結果的 ID。
SQL陳述句示例
然后我從該請求中獲取屬性“totalResults”,在 ForEach 回圈的“Items”中設定一個動態值,如下所示:
@range(0,add(div(sub(int(activity('Get Pages Customers').output.totalResults),mod(int(activity('Get Pages Customers').output.totalResults),1000)),1000 ),1))
注意: API 只允許 1000 個結果的頁面,我做了一些數學計算來獲得一系列頁碼。我還必須在最終結果中加 1 以包含最后一頁。
ForEach 回圈設定
- 在 API 中,我有兩個可以傳遞“限制”和“偏移”的引數。由于我想要所有資料,因此沒有理由將限制設定為 1000(最大允許數)以外的任何值。偏移引數可以設定為小于或等于“totalResults”-“限制”且大于或等于 0 的任何數字。所以我使用步驟 2 中建立的范圍并將其乘以 1000 來設定偏移引數網址。
在復制資料活動中設定偏移引數
REST 連接器中相對 URL 的動態值
注意:由于 Lookup 功能,我發現最好先將資料作為 JSON 接收到 ADLS2 中,而不是放入專用的 SQL 池中。
由于突觸不允許嵌套的 ForEach 回圈,我通過資料流運行資料以格式化資料并檢查重復和更新。
當資料流完成時,它啟動查找活動以獲取剛剛處理的資料并將其傳遞到新管道中以使用另一個 ForEach 回圈獲取父資料的每個 ID 的子資料。
子資料管道的資料流和查找
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/314029.html