我有一個這樣的資料框
new_col new_elements new_val old_col old_elements old_val
0 0 384444683 593 2 423483819 480
1 1 384444684 594 32 248239340 341
2 2 384444686 596 0 249289049 342
我想要這個:
new_col old_col new_elements old_elements new_val old_val
0 0 2 384444683 423483819 593 480
1 1 32 384444684 248239340 594 341
2 2 0 384444686 249289049 596 342
我知道這df.sort_index(axis=1)會按字母順序對我的列進行排序,但現在它們已經按這種方式排序了。我想要的是在前綴之后按字母順序對它們進行排序(前 4 個字符)
uj5u.com熱心網友回復:
col = df.columns
col = sorted(col,key=lambda x: x[4:])
col
df = df[col]
df
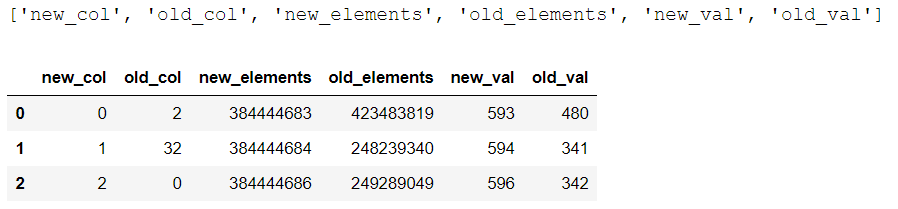
一共放 df = df[sorted(df.columns,key=lambda x: x[4:])]
uj5u.com熱心網友回復:
您還可以sort_index提供密鑰:
df.sort_index(axis=1, key=lambda s: s.str[4:])
new_col old_col new_elements old_elements new_val old_val
0 0 2 384444683 423483819 593 480
1 1 32 384444684 248239340 594 341
2 2 0 384444686 249289049 596 342
uj5u.com熱心網友回復:
我不是專家,但這就是我的做法:
fields = ['new_col', 'old_col', 'new_elements', 'old_elements', 'new_val', 'old_val']
df = df[fields]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/315072.html
上一篇:用C語言決議逗號分隔的字串