創建資料框:
df = pd.DataFrame({'Set': [1, 1, 1, 2, 2, 2, 2, 2], 'Value': [1, 2, 3, 1, 2, 3, 4, 5]})
結果在 DataFrame 中,如下所示。
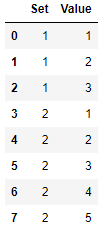
接下來我通過Set進行groupby操作,第一組如下圖。
grouped_by_Set = df.groupby('Set')
grouped_by_Set.get_group(1)
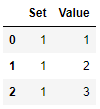
現在我想選擇每組值列中除最后一個條目之外的所有條目。我可以使用grouped_by_Set.nth([0, 1, 2])andgrouped_by_Set.nth(-1)選擇每組的前三個(例如)和最后一個條目,但是選擇每組除最后一個條目之外的所有條目不適用于grouped_by_Set.nth(0:-1). 我無法明確指定條目,因為組具有不同的長度。
uj5u.com熱心網友回復:
IIUC,你可以用ilocinapply
print(df.groupby('Set').apply(lambda x: x.iloc[:-1]).reset_index(drop=True))
Set Value
0 1 1
1 1 2
2 2 1
3 2 2
4 2 3
5 2 4
或者你可以使用duplicatedand keep='last' 創建一個掩碼,然后使用這個掩碼loc
print(df.loc[df.duplicated(subset='Set', keep='last')])
Set Value
0 1 1
1 1 2
3 2 1
4 2 2
5 2 3
6 2 4
uj5u.com熱心網友回復:
您可以使用tail(1)獲取每個組的最后一個條目,然后使用索引通過反轉從原始資料框中取消選擇它isin:
df[~df.index.isin(df.groupby("Set").tail(1).index)]
# Output:
Set Value
0 1 1
1 1 2
3 2 1
4 2 2
5 2 3
6 2 4
uj5u.com熱心網友回復:
試試這個使用reset_index(drop=True) .max()方法,想法是使用每個組的索引來設定切片操作的開始和結束:
grouped_by_Set = df.groupby('Set')
group = grouped_by_Set.get_group(1).reset_index(drop=True)
start = group.index[0]
end = group.index.max()
df_output = group.iloc[start:end, :]
print(df_output)
輸出:
第 1 組:
| 放 | 價值 | |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 1 | 2 |
第 2 組:
| 放 | 價值 | |
|---|---|---|
| 0 | 2 | 1 |
| 1 | 2 | 2 |
| 2 | 2 | 3 |
| 3 | 2 | 4 |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/315083.html
標籤:蟒蛇-3.x 熊猫 pandas-groupby 片
上一篇:如何在特定行或位置編輯文本檔案