我已經研究了半個多月了。測驗過很多demo,但是模型已經訓練成功,使用模型的時候就不知道該怎么輸入自定義音頻,下面的這個demo是其中一個。還望大神講解講解~~
用到的框架:
tensorflow-gpu==1.12 + python3.6 + thchs30
我現在遇到的問題是,怎么輸出中文????
根據這個demo來操作
https://blog.csdn.net/sunshuai_coder/article/details/82799661?ops_request_misc=&request_id=&biz_id=102&utm_term=tensorflow%E8%AF%AD%E9%9F%B3%E8%AF%86%E5%88%AB&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-82799661
但是輸出的結果是
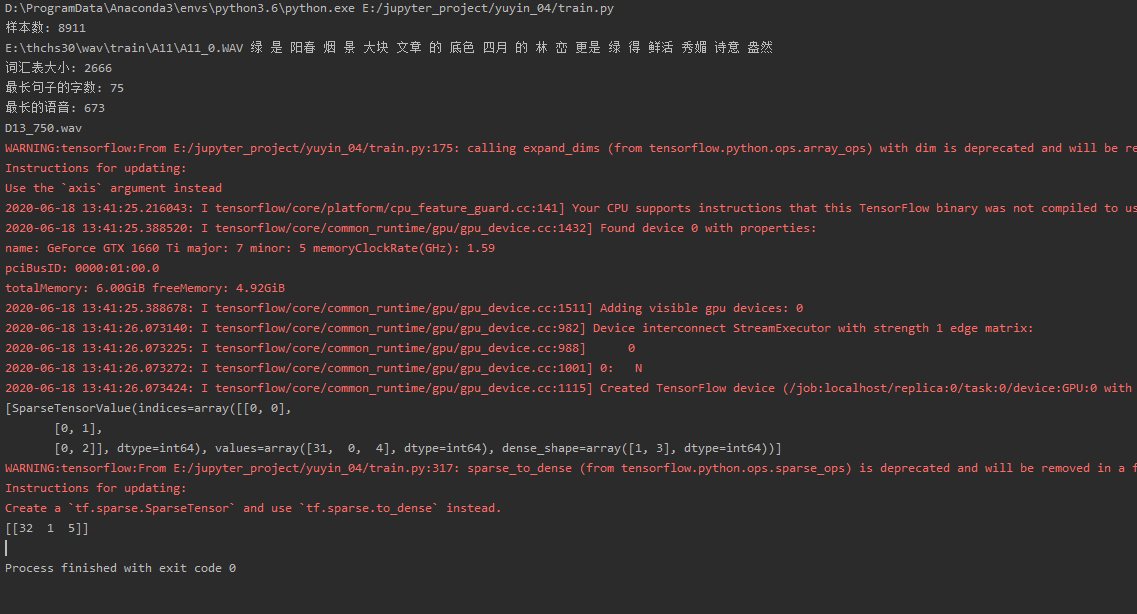
uj5u.com熱心網友回復:
頂一下~~~uj5u.com熱心網友回復:
各位大神~求求幫幫忙咯~~~uj5u.com熱心網友回復:
頂一個~~~~求求各位大神幫忙看看咯轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/31572.html