1. 冪迭代演算法(簡稱冪法)
(1) 占優特征值和占優特征向量
已知方陣\(\bm{A} \in \R^{n \times n}\), \(\bm{A}\)的占優特征值是比\(\bm{A}\)的其他特征值(的絕對值)都大的特征值\(\lambda\),若這樣的特征值存在,則與\(\lambda\)相關的特征向量我們稱為占優特征向量,
(2) 占優特征值和占優特征向量的性質
如果一個向量反復與同一個矩陣相乘,那么該向量會被推向該矩陣的占優特征向量的方向,如下面這個例子所示:
import numpy as np
def prime_eigen(A, x, k):
x_t = x.copy()
for j in range(k):
x_t = A.dot(x_t)
return x_t
if __name__ == '__main__':
A = np.array(
[
[1, 3],
[2, 2]
]
)
x = np.array([-5, 5])
k = 4
r = prime_eigen(A, x, k)
print(r)
該演算法運行結果如下:
250, 260
為什么會出現這種情況呢?因為對\(\forall \bm{x} \in \R^{n}\)都可以表示為\(A\)所有特征向量的線性組合(假設所有特征向量張成\(\R^n\)空間),我們設\(\bm{x}^{(0)} = (-5, 5)^T\),則冪迭代的程序可以如下表示:
\[\begin{aligned} & \bm{x}^{(1)} = \bm{A}\bm{x}^{(0)} = 4(1,1)^T - 2(-3, 2)^T\\ & \bm{x}^{(2)} = \bm{A}^2\bm{x}^{(0)} = 4^2(1, 1)^T + 2(-3, 2)^T\\ & ...\\ & \bm{x}^{(4)} = \bm{A}^4\bm{x}^{(0)} = 4^4(1, 1)^T + 2(-3, 2)^T = 256(1, 1)^T + 2(-3, 2)^T\\ \end{aligned} \tag{1} \]可以看出是和占優特征值對應的特征向量在多次計算后會占優,在這里4是最大的特征值,而計算就越來越接近占優特征向量\((1, 1)^T\)的方向,
不過這樣重復與矩陣連乘和容易導致數值上溢,我們必須要在每步中對向量進行歸一化,就這樣,歸一化和與矩陣\(\bm{A}\)的連乘構成了如下所示的冪迭代演算法:
import numpy as np
def powerit(A, x, k):
for j in range(k):
# 每次迭代前先對上一輪的x進行歸一化
u = x/np.linalg.norm(x)
# 計算本輪迭代未歸一化的x
x = A.dot(u)
# 計算出本輪對應的特征值
lam = u.dot(x)
# 最后一次迭代得到的特征向量x需要歸一化為u
u = x / np.linalg.norm(x)
return u, lam
if __name__ == '__main__':
A = np.array(
[
[1, 3],
[2, 2]
]
)
x = np.array([-5, 5])
k = 10
# 回傳占優特征值和對應的特征向量
u, lam = powerit(A, x, k)
print("占優的特征向量:\n", u)
print("占優的特征值:\n", lam)
演算法運行結果如下:
占優的特征向量:
[0.70710341 0.70711015]
占優的特征值:
3.9999809247674625
觀察上面的代碼,我們在第\(t\)輪迭代的第一行,得到的是歸一化后的第\(t-1\)輪迭代的特征向量近似值\(\bm{u}^{(t-1)}\)(想一想,為什么),然后按照\(\bm{x}^{(t)} = \bm{A}\bm{u}^{(t-1)}\)計算出第\(t\)輪迭代未歸一化的特征向量近似值\(\bm{x}^{(t)}\),需要計算出第\(t\)輪迭代對應的特征值,這里我們我們直接直接運用了結論\(\lambda^{(t)} = (\bm{u}^{(t-1)})^T \bm{x^{(t)}}\),該結論的推導如下:
證明
對于第\(t\)輪迭代,其中特征值的近似未\(\bm{\lambda}^{(t)}\),我們想解特征方程
\[\bm{x^{(t-1)}} \cdot \lambda^{(t)} = \bm{A}\bm{x}^{(t-1)} \tag{2} \]以得到第\(t\)輪迭代時該特征向量對應的特征值\(\lambda^{(t)}\),我們采用最小二乘法求方程\((2)\)的近似解,我們可以寫出該最小二乘問題的正規方程為
\[(\bm{x}^{(t-1)})^T\bm{x}^{(t-1)} \cdot \lambda^{(t-1)} = (\bm{x}^{(t-1)})^T (\bm{A}\bm{x}^{(t-1)}) \tag{3} \]然而我們可以寫出該最小二乘問題的解為
\[\lambda^{(t)} = \frac{(\bm{x}^{(t-1)})^T\bm{A}\bm{x}^{(t-1)}}{(\bm{x}^{(t-1)})^T\bm{x}^{(t-1)}} \tag{4} \]式子\((4)\)就是瑞利(Rayleigh)商,給定特征向量的近似,瑞利商式特征值的最優近似,又由歸一化的定義有
\[\bm{u}^{(t-1)} = \frac{\bm{x}^{(t-1)}}{||\bm{x}^{(t-1)}||} = \frac{\bm{x}^{(t-1)}}{{[(\bm{x}^{(t-1)})^T\bm{x}^{(t-1)}]}^{\frac{1}{2}}} \tag{5} \]則我們可以將式\((4)\)寫作:
\[\lambda^{(t)} = (\bm{u}^{(t-1)})^T\bm{A}\bm{u}^{(t-1)} \tag{6} \]又因為前面已經計算出\(\bm{x}^{(t)} = \bm{A} \bm{u}^{(t-1)}\),為了避免重復計算,我們將\(\bm{x}^{(t)}\)代入式\((5)\)得到:
\[\lambda^{(t)} = (\bm{u}^{(t-1)})^T\bm{x}^{(t)} \tag{7} \]證畢,
可以看出,冪迭代本質上每步進行歸一化的不動點迭代,
2. 逆向冪迭代
上面我們的冪迭代演算法用于求解(絕對值)最大的特征值,那么如何求最小的特征值呢?我們只需要將冪迭代用于矩陣的逆即可,
我們有結論,矩陣\(\bm{A}^{-1}\)的最大特征值就是矩陣\(\bm{A}\)的最小特征值的倒數,事實上,對矩陣\(\bm{A} \in \R^{n \times n}\) ,令其特征值表示為\(\lambda_1, \lambda_2, ..., \lambda_n\),如果其逆矩陣存在,則逆矩陣\(A\)的特征值為\(\lambda_1^{-1}, \lambda_2^{-1}, ..., \lambda_n^{-1}\), 特征向量和矩陣\(A\)相同,該定理證明如下:
證明
有特征值和特征向量定義有
\[\bm{A}\bm{v} = \lambda \bm{v} \tag{8} \]這蘊含著
\[\bm{v} = \lambda \bm{A}^{-1}\bm{v} \tag{9} \]因而
\[\bm{A}^{-1}\bm{v} = \lambda^{-1}\bm{v} \tag{10} \]得證,
對逆矩陣\(\bm{A}^{-1}\)使用冪迭代,并對所得到的的\(\bm{A}^{-1}\)的特征值求倒數,就能得到矩陣\(\bm{A}\)的最小特征值,冪迭代式子如下:
\[\bm{x}^{(t+1)} = \bm{A}^{-1}\bm{x}^{(t)} \tag{11} \]但這要求我們對矩陣\(\bm{A}\)求逆,當矩陣\(\bm{A}\)過大時計算復雜度過高,于是我們需要稍作修改,對式\((11)\)的計算等價于
\[\bm{A}\bm{x}^{(t+1)} = \bm{x}^{(t)} \tag{12} \]這樣,我們就可以采用高斯消元對\(\bm{x}^{(t+1)}\)進行求解,
不過,我們現在這個演算法用于找出矩陣最大和最小的特征值,如何找出其他特征值呢?
如果我們要找出矩陣\(\bm{A}\)在實數\(s\)附近的特征值,可以對矩陣做出接近特征值的移動,我們有定理:對于矩陣\(\bm{A} \in \R^{n \times n}\),設其特征值為\(\lambda_1, \lambda_2, ..., \lambda_n\),則其轉移矩陣\(\bm{A}-sI\)的特征值為\(\lambda_1 -s, \lambda_2 -s, ..., \lambda_n -s\),而特征向量和矩陣\(A\)相同,該定理證明如下:
證明
有特征值和特征向量定義有
\[\bm{A}\bm{v} = \lambda \bm{v} \tag{13} \]從兩側減去\(sI\bm{v}\),得到
\[(\bm{A} - sI)\bm{v} = (\lambda - s)\bm{v} \tag{14} \]因而矩陣\(\bm{A} - sI\)的特征值為\(\lambda - s\),特征向量仍然為\(\bm{v}\),得證,
這樣,我們想求矩陣\(\bm{A}\)在實數\(s\)附近的特征值,可以先對矩陣\((\bm{A}-sI)^{-1}\)使用冪迭代求出\((\bm{A}-sI)^{-1}\)的最大特征值\(b\)(因為我們知道轉移后的特征值為\((\lambda - s)^{-1}\),要使\(\lambda\)盡可能接近\(s\),就得取最大的特征值),其中每一步的\(x^{(t)}\)可以對\((\bm{A}-sI)\bm{x}^{(t)}=\bm{u}^{(t-1)}\)進行高斯消元得到,最后,我們計算出\(\lambda = b^{-1} + s\)即為矩陣\(A\)在\(s\)附近的特征值,該演算法的實作如下:
import numpy as np
def powerit(A, x, s, k):
As = A-s*np.eye(A.shape[0])
for j in range(k):
# 為了讓資料不失去控制
# 每次迭代前先對x進行歸一化
u = x/np.linalg.norm(x)
# 求解(A-sI)xj = uj-1
x = np.linalg.solve(As, u)
lam = u.dot(x)
lam = 1/lam + s
# 最后一次迭代得到的特征向量x需要歸一化為u
u = x / np.linalg.norm(x)
return u, lam
if __name__ == '__main__':
A = np.array(
[
[1, 3],
[2, 2]
]
)
x = np.array([-5, 5])
k = 10
# 逆向冪迭代的平移值,可以通過平移值收斂到不同的特征值
s = 2
# 回傳占優特征值和對應的特征值
u, lam = powerit(A, x, s, k)
# u為 [0.70710341 0.70711015],指向特征向量[1, 1]的方向
print("占優的特征向量:\n", u)
print("占優的特征值:\n", lam)
演算法運行結果如下:
占優的特征向量:
[0.64221793 0.7665221 ]
占優的特征值:
4.145795530352381
3. 冪迭代的應用:PageRank演算法
冪迭代的一大應用就是PageRank演算法,PageRank演算法作用在有向圖上的迭代演算法,收斂后可以給每個節點賦一個表示重要性程度的值,該值越大表示節點在圖中顯得越重要,
比如,給定以下有向圖:
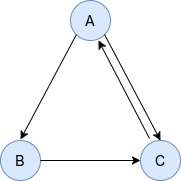
其鄰接矩陣為:
我們將鄰接矩陣沿著行歸一化,就得到了馬爾可夫概率轉移矩陣\(\bm{M}\):
\[\left( \begin{matrix} 0 & \frac{1}{2} & \frac{1}{2} \\ 0 & 0 & 1 \\ 1 & 0 & 0 \\ \end{matrix} \tag{16} \right) \]我們定義上網者從一個頁面轉移到另一個隨機頁面的概率是\(q\),停留在本頁面的概率是\(1-q\),設圖的節點數為\(n\),然后我們可以計算Google矩陣做為有向圖的一般轉移矩陣,對矩陣每個元素而言,我們有:
\[\bm{G}_{ij} = \frac{q}{n} + (1-q)\bm{M}_{ij} \tag{17} \]注意,Google矩陣每一列求和為1,這是一個隨機矩陣,它滿足一個性質,即占優特征值為1.
我們采用矩陣表示形式,即:
其中\(\bm{E}\)為元素全為1的\(n \times n\)方陣,
然后我們定義向量\(\bm{p}\),其元素\(\bm{p}_i\)是待在頁面\(i\)上的概率,我們由前面的冪迭代演算法知道,矩陣與向量重復相乘后向量會被推到特征值為1的方向,而這里,與特征值1對應的特征向量是一組頁面的穩態概率,根據定義這就是\(i\)個頁面的等級,即PageRank演算法名字中的Rank的由來,(同時,這也是\(G^T\)定義的馬爾科夫程序的穩態解),故我們定義迭代程序:
注意,每輪迭代后我們要對\(\bm{p}\)向量歸一化(為了減少時間復雜度我們除以\(p\)向量所有維度元素中的最大值即可,以近似二范數歸一化);而且,我們在所有輪次的迭代結束后也要對\(p\)向量進行歸一化(除以所有維度元素之和以保證所有維度之和為1),
我們對該圖的PageRank演算法代碼實作如下(其中移動到一個隨機頁面的概率\(q\)按慣例取0.15):
import numpy as np
# 歸一化同時迭代,k是迭代步數
# 欲推往A特征值的方向,A肯定是方陣
def PageRank(A, p, k, q):
assert(A.shape[0]==A.shape[1])
n = A.shape[0]
M = A.copy().astype(np.float32) #注意要轉為浮點型
for i in range(n):
M[i, :] = M[i, :]/np.sum(M[i, :])
G = (q/n)*np.ones((n,n)) + (1-q)*M
G_T = G.T
p_t = p.copy()
for i in range(k):
y = G_T.dot(p_t)
p_t = y/np.max(y)
return p_t/np.sum(p_t)
if __name__ == '__main__':
A = np.array(
[
[0, 1, 1],
[0, 0, 1],
[1, 0, 0]
]
)
k = 20
p = np.array([1, 1, 1])
q = 0.15 #移動到一個隨機頁面概率通常為0.15
# 概率為1-q移動到與本頁面鏈接的頁面
R= PageRank(A, p, k, q)
print(R)
該演算法運行結果如下:
[0.38779177 0.21480614 0.39740209]
可以看到20步迭代結束后網頁的Rank向量\(\bm{R}=(0.38779177, 0.21480614, 0.39740209)^T\),這也可以看做網頁的重要性程度,
知名程式庫和原始碼閱讀建議
PageRank演算法有很多優秀的開源實作,這里推薦幾個專案:
(1) Spark-GraphX
GraphX是一個優秀的分布式圖計算庫,從屬于Spark分布式計算框架,采用Scala語言實作了很多分布式的圖計算演算法,也包括我們這里所講的PageRank演算法,
檔案地址:https://spark.apache.org/graphx
原始碼地址:https://github.com/apache/spark
(2) neo4j
neo4j是一個采用Java實作的知名的圖資料庫,該資料庫也提供了PageRank演算法的實作,
檔案地址:https://neo4j.com/
原始碼地址:https://github.com/neo4j/neo4j.git
(3) elastic-search
如果你有興趣深入研究搜索引擎的實作,那么向你推薦elastic-search專案,它是基于Java實作的一個搜索引擎,
檔案地址:https://www.elastic.co/cn/
原始碼地址:https://github.com/elastic/elasticsearch.git
參考文獻
- [1] Timothy sauer. 數值分析(第2版)[M].機械工業出版社, 2018.
- [2] 李航. 統計學習方法(第2版)[M]. 清華大學出版社, 2019.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/315958.html
標籤:其他