首先感謝大佬的博客對我的指點,主要功能是能實時從攝像頭采集圖片,實時進行人臉檢驗和人臉對比,并且能將已經打卡人的名字保存到txt文本中,另外還有一個管理員系統,登錄后能錄入人臉,錄入姓名,效果如圖:
我的運行環境為:tensorflow=2.2.0,pyside2=5.15.2,python=3.8,numpy=1.19.3
人臉打卡界面主要包括了三個重要部分:
1.人臉檢測和人臉對比部分
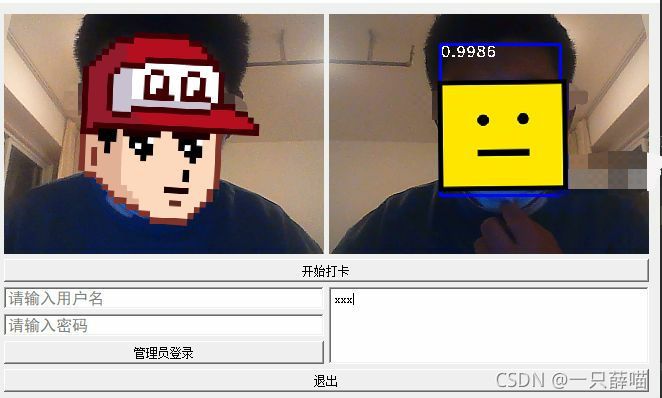
第一個是人臉檢測和人臉對比部分,該部分是主要作用是找到攝像頭中的人臉并與資料庫里的人臉對比,如果存在相應的人臉,則將人臉名字和人臉的概率放在同一個界面上,話不多說直接上圖:
左邊圖片是博主我的臉,右邊圖的左上方是人臉的概率,右下方是名字(當然是xxx了,手動滑稽),人臉框繪制以及概率名字這部分代碼為:
def detect_image(self, image):
image = np.array(image, np.float32)
old_image = np.array(image.copy(), np.uint8)
#---------------------------------------------------#
# Retinaface檢測部分-開始
#---------------------------------------------------#
# 資料的預處理
im_height, im_width, _ = np.shape(image)
scale = [np.shape(image)[1], np.shape(image)[0], np.shape(image)[1], np.shape(image)[0]]
scale_for_landmarks = [np.shape(image)[1], np.shape(image)[0], np.shape(image)[1], np.shape(image)[0],
np.shape(image)[1], np.shape(image)[0], np.shape(image)[1], np.shape(image)[0],
np.shape(image)[1], np.shape(image)[0]]
if self.letterbox_image:
image = letterbox_image(image,[self.retinaface_input_shape[1], self.retinaface_input_shape[0]])
anchors = self.anchors
else:
anchors = Anchors(self.cfg, image_size=(im_height, im_width)).get_anchors()
#---------------------------------------------------#
# 圖片預處理,歸一化
#---------------------------------------------------#
photo = np.expand_dims(preprocess_input(image),0)
#---------------------------------------------------#
# 將處理完的圖片傳入Retinaface網路當中進行預測
#---------------------------------------------------#
preds = self.retinaface.predict(photo)
#---------------------------------------------------#
# Retinaface網路的解碼,最終我們會獲得預測框
# 將預測結果進行解碼和非極大抑制
#---------------------------------------------------#
results = self.bbox_util.detection_out(preds,anchors,confidence_threshold=self.confidence)
#---------------------------------------------------#
# 如果沒有預測框則回傳原圖
#---------------------------------------------------#
if len(results)<=0:
return old_image
results = np.array(results)
if self.letterbox_image:
results = retinaface_correct_boxes(results, np.array((self.retinaface_input_shape[0], self.retinaface_input_shape[1])), np.array([im_height, im_width]))
#---------------------------------------------------#
# 4人臉框置信度
# :4是框的坐標
# 5:是人臉關鍵點的坐標
#---------------------------------------------------#
results[:,:4] = results[:,:4]*scale
results[:,5:] = results[:,5:]*scale_for_landmarks
#---------------------------------------------------#
# Retinaface檢測部分-結束
#---------------------------------------------------#
#-----------------------------------------------#
# Facenet編碼部分-開始
#-----------------------------------------------#
face_encodings = []
for result in results:
#----------------------#
# 影像截取,人臉矯正
#----------------------#
result = np.maximum(result, 0)
crop_img = np.array(old_image)[int(result[1]):int(result[3]), int(result[0]):int(result[2])]
landmark = np.reshape(result[5:],(5,2)) - np.array([int(result[0]),int(result[1])])
crop_img, _ = Alignment_1(crop_img,landmark)
#----------------------#
# 人臉編碼
#----------------------#
# 不失真的resize,然后進行歸一化
crop_img = np.array(letterbox_image(np.uint8(crop_img),(self.facenet_input_shape[1],self.facenet_input_shape[0])))/255
crop_img = np.expand_dims(crop_img,0)
# 利用影像算取長度為128的特征向量
face_encoding = self.facenet.predict(crop_img)[0]
face_encodings.append(face_encoding)
#-----------------------------------------------#
# Facenet編碼部分-結束
#-----------------------------------------------#
#-----------------------------------------------#
# 人臉特征比對-開始
#-----------------------------------------------#
face_names = []
P=Pinyin()
for face_encoding in face_encodings:
# 取出一張臉并與資料庫中所有的人臉進行對比,計算得分
matches, face_distances = compare_faces(self.known_face_encodings, face_encoding, tolerance = self.facenet_threhold)
name = "Unknown"
#print(face_distances)
# 找到已知最貼近當前人臉的人臉序號
best_match_index = np.argmin(face_distances)
if matches[best_match_index]:
name = self.known_face_names[best_match_index]
face_names.append(name)
#-----------------------------------------------#
# 人臉特征比對-結束
#-----------------------------------------------#
def chinese(strs):
if '\u4e00' <= strs[0] <= '\u9fa5':
return True
else:
return True
for i, b in enumerate(results):
text = "{:.4f}".format(b[4])
b = list(map(int, b))
cv2.rectangle(old_image, (b[0], b[1]), (b[2], b[3]), (0, 0, 255), 2)
cx = b[0]
cy = b[1] + 12
# print(text)
cv2.putText(old_image, text, (cx, cy),
cv2.FONT_HERSHEY_DUPLEX, 0.5, (255, 255, 255))
# landms
cv2.circle(old_image, (b[5], b[6]), 1, (0, 0, 255), 4)
cv2.circle(old_image, (b[7], b[8]), 1, (0, 255, 255), 4)
cv2.circle(old_image, (b[9], b[10]), 1, (255, 0, 255), 4)
cv2.circle(old_image, (b[11], b[12]), 1, (0, 255, 0), 4)
cv2.circle(old_image, (b[13], b[14]), 1, (255, 0, 0), 4)
name = face_names[i]
name = "".join(name.split(".jpg"))
panduan=chinese(name)
if panduan==True:
name1 = name
name = P.get_pinyin(name)
else:
name1 = name
name=name
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(old_image, name, (b[0] , b[3] - 15), font, 0.75, (255, 255, 255), 2)
#--------------------------------------------------------------#
# cv2不能寫中文,加上這段可以,但是檢測速度會有一定的下降,
# 如果不是必須,可以換成cv2只顯示英文,
#--------------------------------------------------------------#
#old_image = cv2ImgAddText(old_image, name, b[0]+5 , b[3] - 25)
return old_image,name1
2.UI界面設計
第二部分是打卡界面的設計,呼叫pyside2的庫設計界面,進行了相應的排版,代碼有點多,要是想看下篇博客我會寫出來,對咯排版后的圖也就是一開始的圖咯,
3.人臉錄入界面的設計
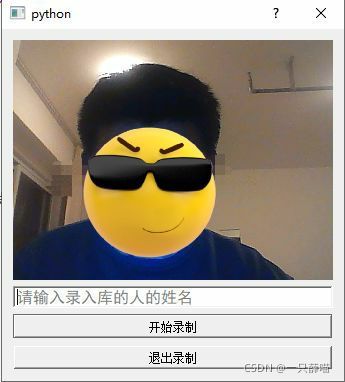
也就是在人臉打卡界面的管理員登錄口輸入正確的賬號和密碼后進入錄入人臉界面,主要涉及了建立第二視窗,將輸入姓名存盤到一個txt檔案中,界面如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/316065.html
標籤:AI
上一篇:擁抱AI技術,賦能智慧工業