Adaptive kernel selection network with attention constraint for surgical instrument classification
- 一、論文簡介
- 1.1 論文鏈接
- 1.2 論文基本資訊
- 二、詳細解讀
- 2.1 摘要
- 2.2 介紹
- 2.2.1 研究意義
- 2.2.2 資料集
- 2.2.3 問題難點
- 2.2.4 解決思路
- 2.3 背景
- 2.3.1 計算機視覺在醫療保健領域的應用
- 2.3.2 細粒度影像分類
- 2.4 ResNet的網路架構
- 2.4.1 神經網路并不是越深越好
- 2.4.2 ResNet v1
- 2.4.3 ResNet v2
- 2.5 SKA-ResNet的網路架構
- 2.5.1總體描述
- 2.5.2 SKA模塊
- 2.5.3 多尺度正則化(Multi-scale regularizer)
- 2.6 實驗結果
- 2.6.1 實作細節
- 2.6.2 與其他模型對比
一、論文簡介
1.1 論文鏈接
論文放在了我的百度網盤里,有需要的自取,
鏈接:https://pan.baidu.com/s/1V2WVqOFFXA_O34ENjskeWA
提取碼:0rf6
1.2 論文基本資訊

二、詳細解讀
2.1 摘要
計算機視覺(CV)技術在許多方面幫助醫療保健行業,如疾病診斷,然而,作為手術前后的關鍵環節,cv驅動技術對手術器械的庫存作業還沒有進行研究,為了降低手術器械丟失的風險和危害,我們提出了一種系統的手術器械分類研究,并引入了一種新的基于注意的深度神經網路SKA-ResNet,該網路主要由以下幾個部分組成:(a)具有選擇性核注意模塊的特征提取器,自動調整神經元的接受域,增強學習后的表達;(b)以KL-divergence為約束的多尺度正則化器,利用特征映射之間的關系,該方法易于在一個階段進行端到端訓練,且額外的計算負擔很少,此外,為了促進我們的研究,我們首次創建了一個新的手術器械資料集SID19(包含19種手術器械,共3800張影像),實驗結果表明,與現有模型相比,SKA-ResNet在SID19手術工具分類方面具有優越性,該方法的分類準確率達到97.703%,為外科手術工具的庫存和識別研究提供了良好的支持,此外,我們的方法可以在四個具有挑戰性的細粒度視覺分類資料集上實作最先進的性能,
2.2 介紹
2.2.1 研究意義
2020年,澳大利亞生產力委員會(Australian Productivity Commission)公布了一些醫療記錄,顯示43萬名患者遭受了痛苦,在這些患者中,與醫療器械相關的醫療事故更加突出,據《每日郵報》報道,在短短一年內,這些拙劣的外科醫生將醫療器械留在了至少23名中毒、感染或受傷的病人體內,因此,保證手術器械庫存作業的可靠性具有十分重要的意義,在手術器械的清點作業中,醫務人員主要負責清點手術器械的種類和數量,本文對外科器械的庫存作業進行了一系列的研究作業,目的是準確地識別出手術進行前后的外科器械,這項作業不僅節省了人力資源,而且可以迅速識別手術器械是否遺漏,有利于防止繼發性感染或致命醫療事故,
2.2.2 資料集
考慮了闌尾切除、膽囊切除、剖宮產手術器械包中的19類手術器械(包括愛麗絲鉗、不同尺寸止血鉗、橢圓形鉗、吸力頭、四種鉤、針夾、布鉗、長短齒鉗、線剪、組織剪、腸板等)作為創建的手術器械資料集(標記為SID19)的原材料,共有19張手術器械,3800張圖片,
2.2.3 問題難點
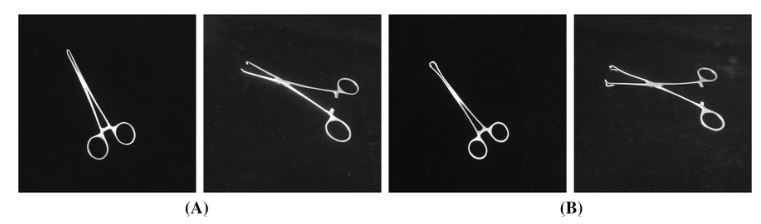
在SID19資料集中,存在某些屬于細粒度類的外科工具,它們具有非常微妙的差異,難以相互區分,其中,手術鉗和手術剪刀都包含幾個子類,即細粒度類,手術鉗的類別包括Alice鉗、不同尺寸的止血鉗、橢圓形鉗、長短牙鉗、布鉗,手術剪刀的種類包括線剪、組織剪等,這些子類別中的物件通常具有較大的類內差異和較小的類間差異,給識別任務帶來了困難,例如,下圖顯示了兩種不同狀態、視圖和角度的鉗類:愛麗絲鉗和闌尾鉗,愛麗絲鉗和闌尾鉗的前端有微小的區別,闌尾鉗的前端比愛麗絲鉗的前端圓得多,因此,本文所提出的手術器械分類任務不同于常見的自然影像分類,揭示了細粒度視覺分類(FGVC)的獨特特征,從而帶來了額外的困難,
2.2.4 解決思路
本文提出了一個新的細粒度視覺分類框架,名為SKA-ResNet,以探索手術器械分類的有效性,該方法包括兩個新的組成部分:一個是帶有選擇性核注意(SKA)模塊的堆疊標準殘塊的特征提取器和一個多尺度正則化器來探索增強的中間特征圖的關系,(后面會有詳細介紹)
2.3 背景
2.3.1 計算機視覺在醫療保健領域的應用
今天的醫療保健行業非常依賴醫學成像提供的精確診斷,醫學成像與不同診斷技術(包括x射線、計算機斷層掃描(CT)、磁共振成像(MRI)等)獲得的資料一起作業,醫學影像分析基于異質性病理影像,主要集中在疾病預防、預測、檢測、診斷、篩選等方面,
2.3.2 細粒度影像分類
FGVC任務的研究作業主要沿著兩個方向進行,即強監督學習和弱監督學習,其中,強監督學習方法將目標包圍盒、部分標注資訊和影像級別標簽添加到訓練網路中,學習目標特定的判別位置資訊,然而,這種方法存在以下問題:(a)對原始影像進行標注需要大量的人力資源;(b)人類標注的資訊有時并不準確,而弱監督學習網路只給出影像的類別進行分類,注意機制作為CV研究中最常用的方法,已被廣泛應用于各種分類、檢測和分割任務中,特別是在弱監督FGVC任務中,根據注意機制,資訊特征被強化,而不太有用的特征被抑制,此外,FGVC中還引入了其他弱監督模型用于特征關系學習,
2.4 ResNet的網路架構
參考博客:詳解深度學習之經典網路架構(六):ResNet 兩代(ResNet v1和ResNet v2)
2.4.1 神經網路并不是越深越好
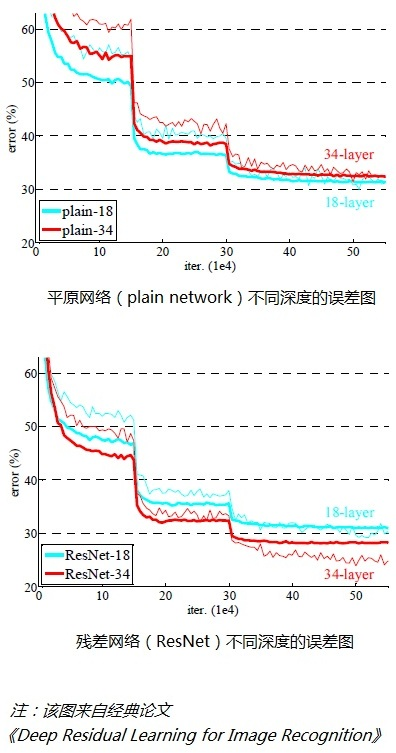
神經網路在反向傳播程序中要不斷地傳播梯度,而當網路層數加深時,梯度在傳播程序中會逐漸消失(假如采用Sigmoid函式,對于幅度為1的信號,每向后傳遞一層,梯度就衰減為原來的0.25,層數越多,衰減越厲害),因此導致無法對前面網路層的權重進行有效的調整,實驗現象表明,在不斷加神經網路的深度時,模型準確率會先上升然后達到飽和,再持續增加深度時則會導致準確率下降,示意圖如下:
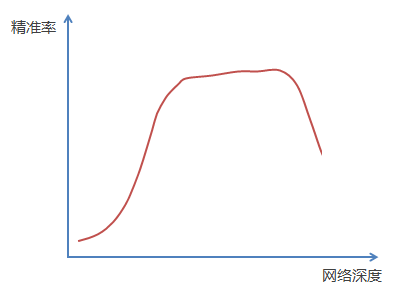
因此可以作這樣一個假設:假設現有一個比較淺的網路(Shallow Net)已達到了飽和的準確率,這時在它后面再加上幾個恒等映射層(Identity mapping,也即y=x,輸出等于輸入),這樣就增加了網路的深度,并且起碼誤差不會增加,也就是說更深的網路不應該帶來訓練集上誤差的上升,而這里提到的使用恒等映射直接將前一層輸出傳到后面的思想,便是著名深度殘差網路ResNet的靈感來源,
2.4.2 ResNet v1
ResNet引入了殘差網路結構(residual network),通過這種殘差網路結構,可以把網路層弄的很深(據說已經達到了1000多層),并且最終的分類效果也非常好,殘差網路的基本結構如下圖所示,
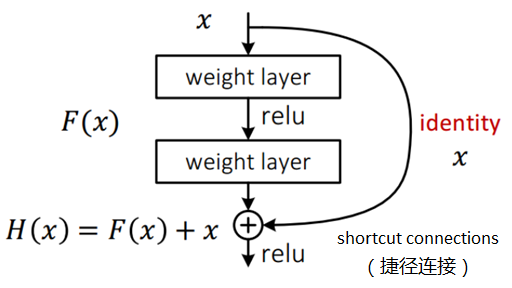
假定某段神經網路的輸入是x,期望輸出是H(x),即H(x)是期望的復雜潛在映射,如果是要學習這樣的模型,則訓練難度會比較大;回想前面的假設,如果已經學習到較飽和的準確率(或者當發現下層的誤差變大時),那么接下來的學習目標就轉變為恒等映射的學習,也就是使輸入x近似于輸出H(x),以保持在后面的層次中不會造成精度下降,在上圖的殘差網路結構圖中,通過“shortcut connections(捷徑連接)”的方式,直接把輸入x傳到輸出作為初始結果,輸出結果為H(x)=F(x)+x,當F(x)=0時,那么H(x)=x,也就是上面所提到的恒等映射,于是,ResNet相當于將學習目標改變了,不再是學習一個完整的輸出,而是目標值H(X)和x的差值,也就是所謂的殘差F(x) := H(x)-x,因此,后面的訓練目標就是要將殘差結果逼近于0,從而使準確率不會隨著網路的加深而下降,這種殘差跳躍式的結構,打破了傳統的神經網路n-1層的輸出只能給n層作為輸入的慣例,使某一層的輸出可以直接跨過幾層作為后面某一層的輸入,其意義在于為疊加多層網路而使得整個學習模型的錯誤率不下面感受一下34層的深度殘差網路的結構圖降反升的難題提供了新的方向,至此,神經網路的層數可以超越之前的約束,達到幾十層、上百層甚至千層,為高級語意特征提取和分類提供了可行性,下面來感受一下34層的深度殘差網路的結構圖:

實線的Connection部分,表示通道相同,計算方式為H(x)=F(x)+x;虛線的Connection部分,表示通道不同,計算方式為H(x)=F(x)+Wx,其中W是卷積操作,用來調整x維度的,除了上面提到的兩層殘差學習單元,還有三層的殘差學習單元,如下圖所示,
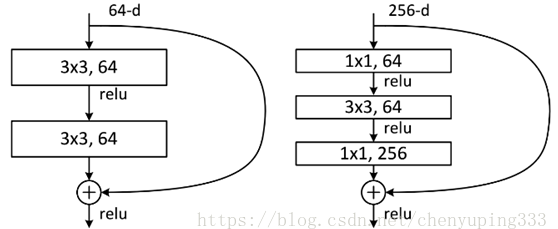
兩種結構分別針對ResNet34(左圖)和ResNet50/101/152(右圖),其目的主要就是為了降低引數,減少計算量,左圖是兩個3x3x256的卷積,引數數目: 3x3x256x256x2 = 1179648,右圖是第一個1x1的卷積把256維通道降到64維,然后在最后通過1x1卷積恢復,整體上用的引數數目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,右圖的引數數量比左圖減少了16.94倍,對于常規的ResNet,可以用于34層或者更少的網路中(左圖);對于更深的網路(如101層),則使用右圖,其目的是減少計算和引數量,如下圖所示,實驗表明深度殘差網路的確解決了深度增加導致錯誤率上升的問題,
2.4.3 ResNet v2
ResNet v2由ResNet的作者在第二篇相關論文《Identity Mappings in Deep Residual Networks》中提出,ResNet v1和ResNet v2的網路結構對比如下:
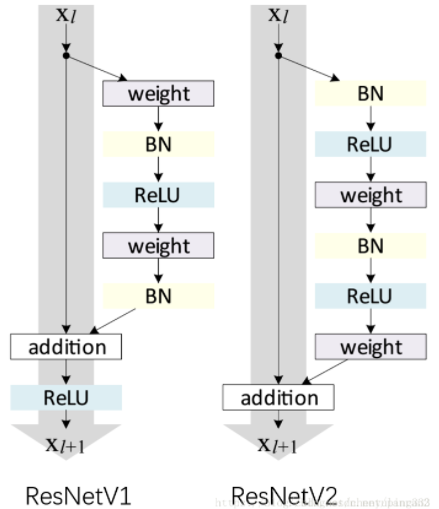
其中weight指conv層,BN指Batch Normalization層,ReLU指激活層,addition指相加,ResNet v2的結構好的原因在于兩點:1)反向傳播基本符合假設,資訊傳遞無阻礙;2)BN層作為pre-activation,起到了正則化的作用;ResNet V2 在每一層中都使用了 Batch Normalization,這樣處理后,新的殘差學習單元比以前更容易訓練且泛化性更強,
2.5 SKA-ResNet的網路架構
2.5.1總體描述
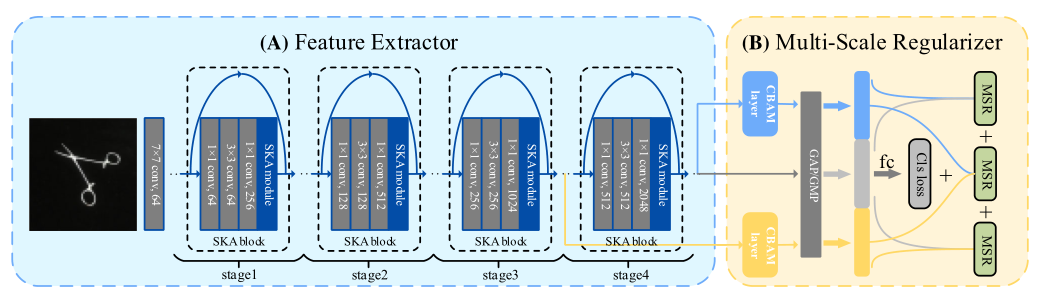
SKA-ResNet網路由兩個主要部分組成:(1)一個新的特征提取器(feature extractor),它由堆疊的標準殘差塊和選擇性核注意(SKA)模塊組成,無需額外的注意網路,即可為要識別的區域提取資訊特征圖,(2)多尺度正則化器,以特征圖與影像之間的關系為約束,學習不同細粒度類別之間的關系,與現有的專注于附加注意力網路的基于注意力的方法不同,本文方法以分散的方式將輕量級的SKA模塊嵌入到標準殘留塊中,此外,不同的特征圖和影像之間的關系利用多尺度正則化,以魯棒的細粒度特征表示,整個網路僅僅依靠影像級別的標簽進行端到端訓練,
2.5.2 SKA模塊
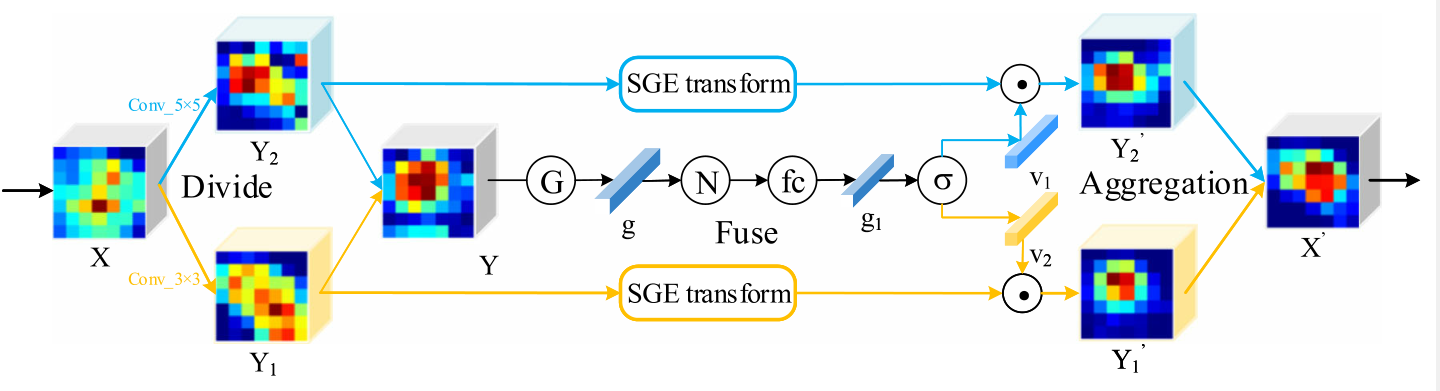
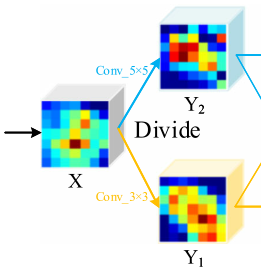
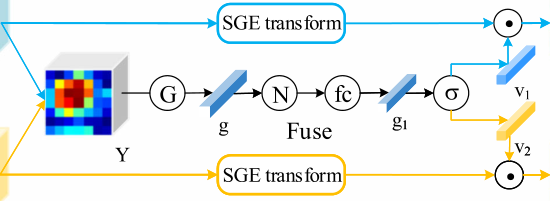
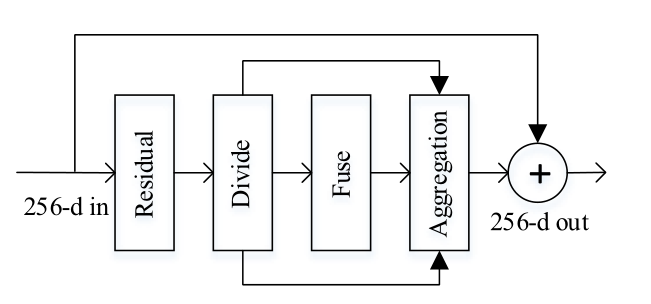
在特征提取階段,引入了輕量級SKA模塊,如上圖所示,特征提取器通過將SKA模塊嵌入到ResNet的堆疊標準殘差塊中,自動定位識別區域并增強相應的特征圖,SKA模塊的操作可以分為Divide, Fuse和Aggregation三部分,下面以兩個分支的SKA模塊為例進行詳細說明,
(1)Divide部分 :給定中間特征圖X,首先將其發送到兩個不同的卷積層,生成具有不同語意資訊的兩個特征圖Y1和Y2,卷積層由卷積(Converlution)、批量標準化(Batch Normalization)和ReLU函陣列成,這兩個卷積層的卷積核大小分別為3x3 和5x5,需要注意的是,得到的兩個feature map的大小與原始feature map X的大小相同,這個程序可以總結如下:
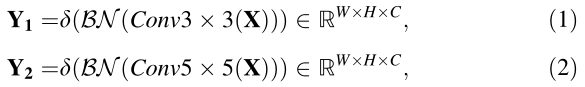
從前往后的三個變數分別表示為ReLU函式,批量標準化和卷積,
- Normalization:在資料分析之前,我們通常需要先將資料標準化(normalization),利用標準化后的資料進行資料分析,資料標準化處理主要包括資料同趨化處理和無量綱化處理兩個方面,資料同趨化處理主要解決不同性質資料問題,對不同性質指標直接加總不能正確反映不同作用力的綜合結果,須先考慮改變逆指標資料性質,使所有指標對測評方案的作用力同趨化,再加總才能得出正確結果,資料無量綱化處理主要解決資料的可比性,經過上述標準化處理,原始資料均轉換為無量綱化指標測評值,即各指標值都處于同一個數量級別上,可以進行綜合測評分析,
標準化的目的:
a.把特征的各個維度標準化到特定的區間;
b.把有量綱運算式變為無量綱運算式;
歸一化的好處:
a.加快基于梯度下降法或隨機梯度下降法模型的收斂速度;
b.提升模型的精度;
神經網路里主要有兩類物體:神經元或者連接神經元的邊,按照Normalization操作涉及物件的不同可以分為兩大類:一類是對第L層每個神經元的激活值或者說對于第L+1層網路神經元的輸入值進行Normalization操作,比如BatchNorm/LayerNorm/InstanceNorm/GroupNorm/Switchable Norm等方法;另外一類是對神經網路中連接相鄰隱層神經元之間的邊上的權重進行Normalization操作,比如Weight Norm,
Normalization 做的是什么?
對于第一類的Normalization操作,就像激活函式層、卷積層、全連接層、池化層一樣,Normalization也屬于網路的一層,對于神經元的激活值來說,不論哪種Normalization方法,其規范化目標都是一樣的,都是將其激活值規整為均值為0,方差為1的正態分布,即規范化函式統一都是如下形式:
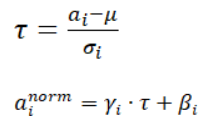
目前神經網路中常見的第一類Normalization方法包括BN,后面幾個演算法算是BN的改進版本,不論是哪個方法,其基本計算步驟都如上所述,大同小異,最主要的區別在于神經元集合S的范圍怎么定,不同的方法采用了不同的神經元集合定義方法,
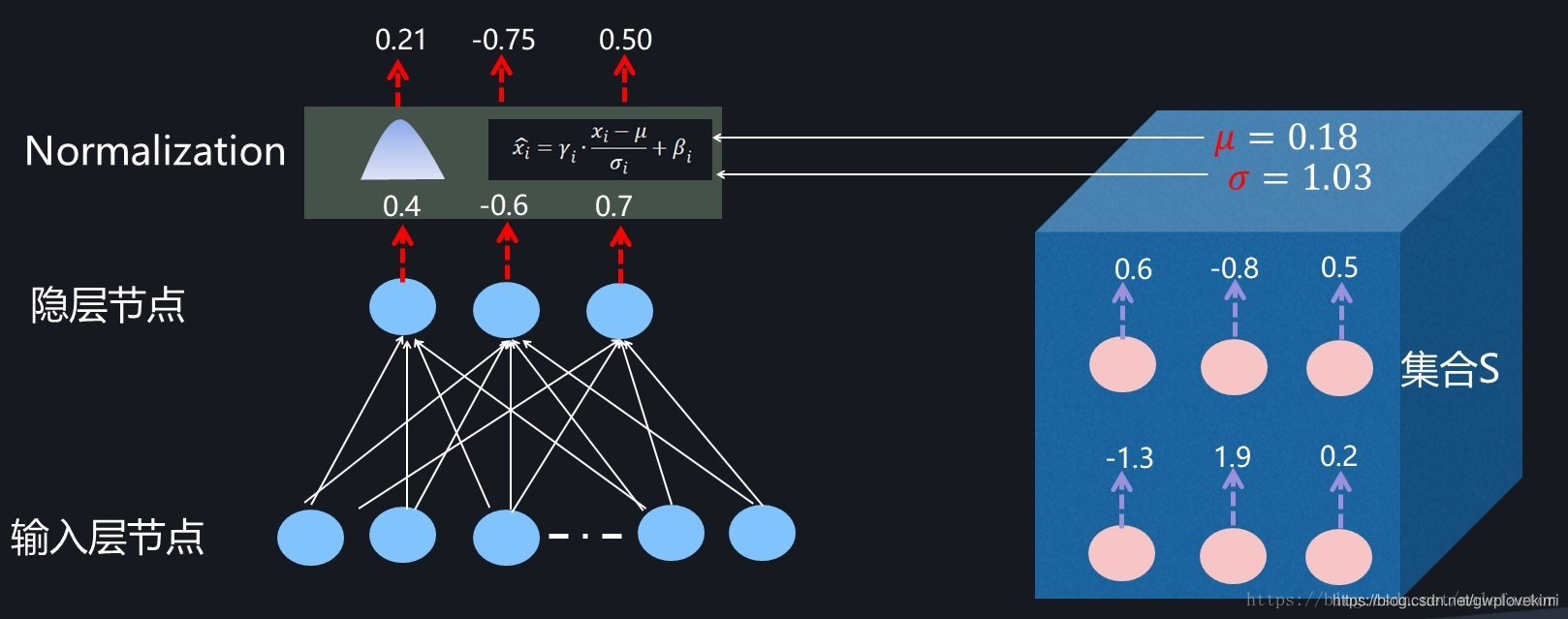
為什么這些Normalization需要確定一個神經元集合S呢?為了對網路中某個神經元的激活值規范到均值為0方差為1的范圍,必須有一定的手段求出均值和方差,而均值和方差是個統計指標,要計算這兩個指標一定是在一個集合范圍內才可行,所以這就要求必須指定一個神經元組成的集合,利用這個集合里每個神經元的激活來統計出所需的均值和方差,這樣才能達到預定的規范化目標,如下圖所示的例子中隱層的六個神經元在某刻進行Normalization計算的時候共用了同一個集合S,在實際的計算中,隱層中的神經元可能共用同一個集合,也可能每個神經元采用不同的神經元集合S,并非一成不變,
- Batch Normalization:批量標準化,簡稱BN,作用是將不同的輸入值進行標準化,降低規模的差異至同一個范圍內,這樣做的好處在于一方面提高梯度的收斂程度,加快訓練速度;另一方面使得每一層可以盡量面對同一特征分布的輸入值,減少了變化帶來的不確定性,也降低了對后層網路的影響,各層網路變得相對獨立,
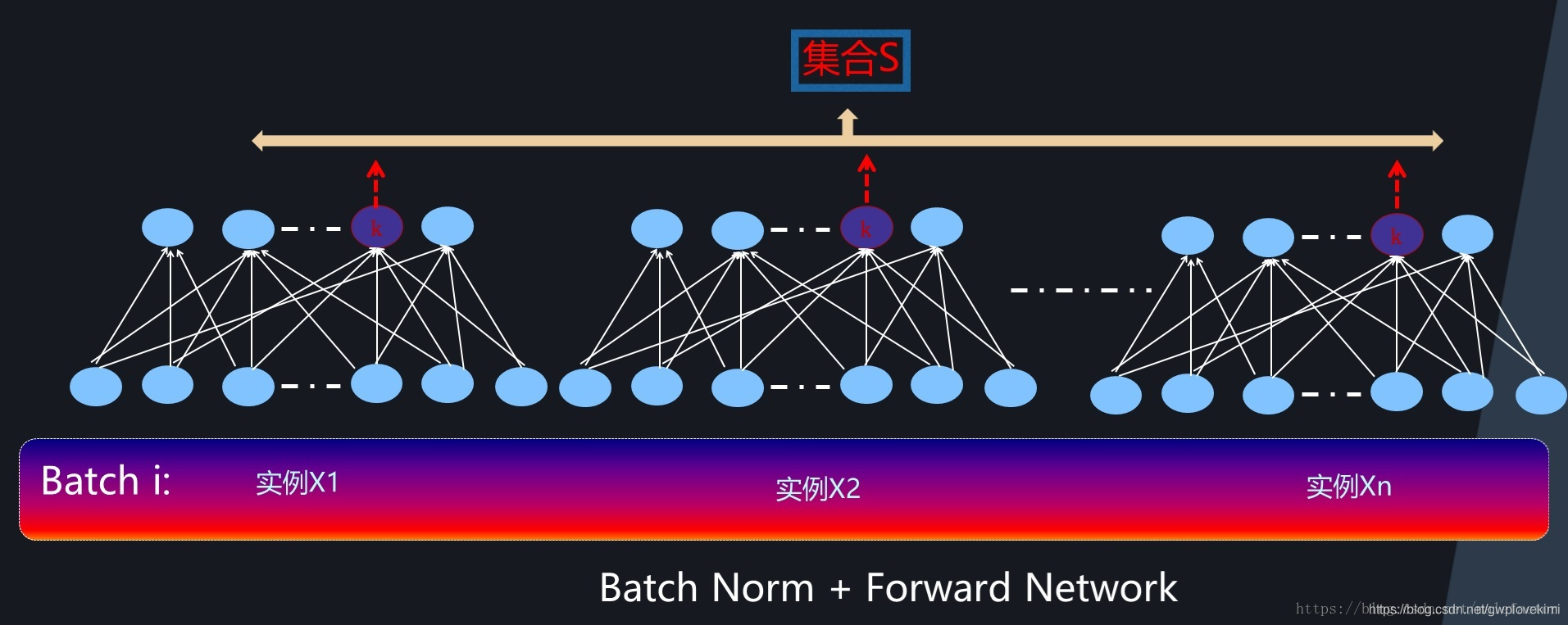
前向神經網路中的BatchNorm:在計算隱層某個神經元k激活的規范值的時候,對應的神經元集合S范圍是如何劃定呢?如上圖所示,對于神經元k來說,假設某個Batch包含n個訓練實體,那么每個訓練實體在神經元k都會產生一個激活值,也就是說Batch中n個訓練實體分別通過同一個神經元k的時候產生了n個激活值,BatchNorm的集合S選擇入圍的神經元就是這n個同一個神經元被Batch不同訓練實體激發的激活值,劃定集合S的范圍后,Normalization的具體計算程序與前文所述計算程序一樣,采用公式即可完成規范化操作,
CNN中的BatchNorm:常規的CNN一般由卷積層、下采樣層及全連接層構成,全連接層形式上與前向神經網路是一樣的,所以可以采取前向神經網路中的BatchNorm方式,而下采樣層本身不帶引數所以可以忽略,所以CNN中主要關注卷積層如何計算BatchNorm,CNN中的某個卷積層由m個卷積核構成,每個卷積核對三維的輸入(通道數X長X寬)進行計算,激活及輸出值是個二維平面(長X寬),對應一個輸出通道,由于存在m個卷積核,所以輸出仍然是三維的,由m個通道及每個通道的二維平面構成,
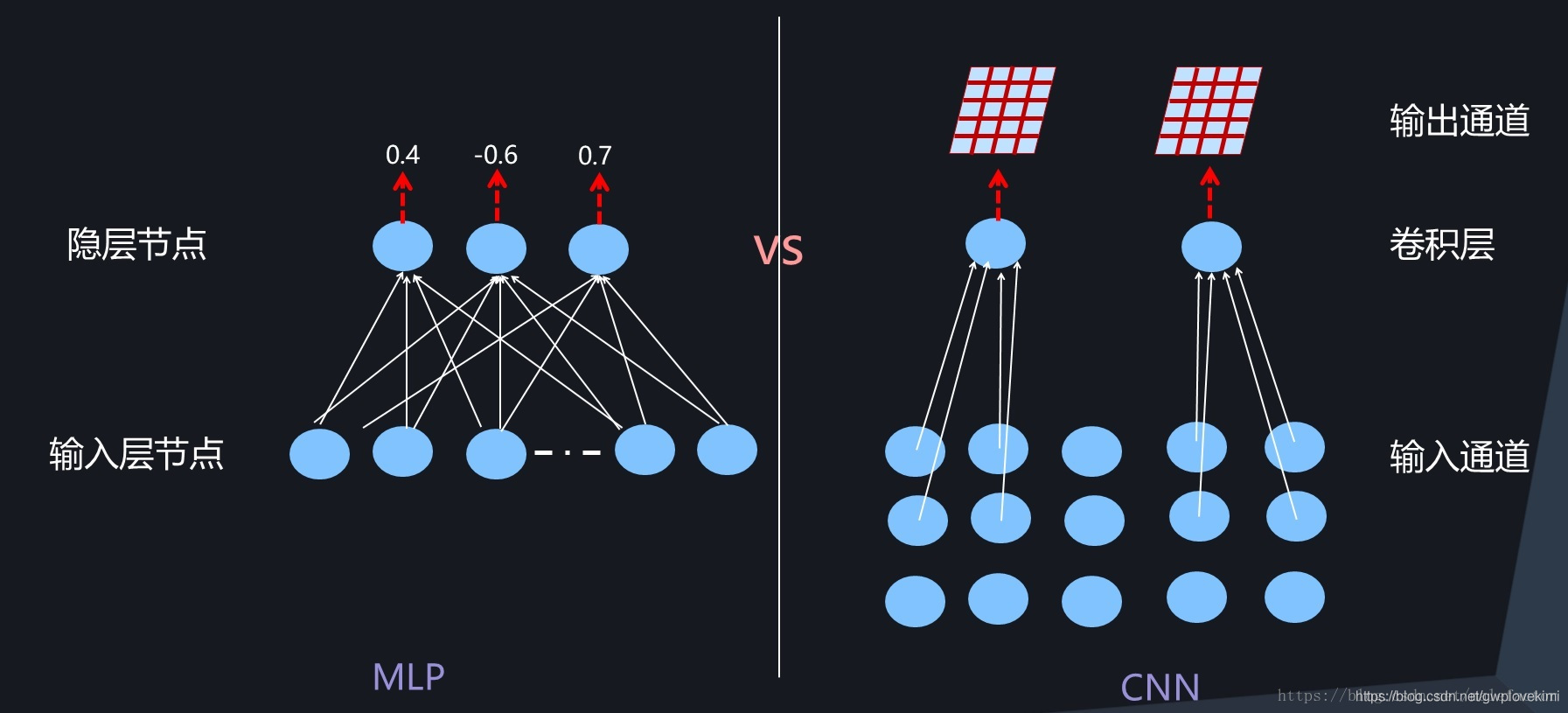
對于CNN某個卷積層對應的輸出通道k來說,假設某個Batch包含n個訓練實體,每個訓練實體在這個通道k都會產生一個二維激活平面,也就是說Batch中n個訓練實體分別通過同一個通道為k的卷積核的時候產生了n個激活平面,假設激活平面長為5,寬為4,則激活平面包含20個激活值,n個不同實體的激活平面共包含20n個激活值,那么BatchNorm的集合S的范圍就是由這20n個同一個通道被Batch不同訓練實體激發的激活平面中包含的所有激活值構成(對應圖中所有標為藍色的激活值),劃定集合S的范圍后,激活平面中任意一個激活值都需進行Normalization操作,其Normalization的具體計算程序與前文所述計算程序一樣,采用公式即可完成規范化操作,這樣即完成CNN卷積層的BatchNorm轉換程序,
BN的優點:
a.沒有它之前,需要小心的調整學習率和權重初始化,有了BN可以放心的使用大學習率,較大的學習率提高了學習速度;
b.Batchnorm本身上也是一種正則的方式,可以代替其他正則方式如dropout等;
BN的缺點:
a.對batchsize 大小敏感,太小的size不能體現資料特征,會大大影響結果,但是有些任務要求小size,BN便不能使用;
b.圖片風格轉換等應用場景,使用BN會帶來負面效果,這很可能是因為在Mini-Batch內多張無關的圖片之間計算統計量,榷訓了單張圖片本身特有的一些細節資訊; - ReLU函式:修正線性單元(Rectified linear unit),通常作為神經元的激活函式,
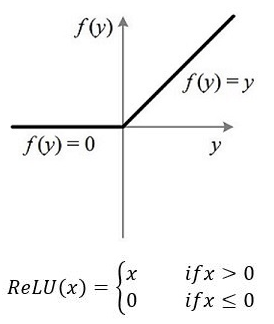
當訓練一個深度分類模型的時候,和目標相關的特征往往也就那么幾個,因此通過ReLU實作稀疏后的模型能夠更好地挖掘相關特征,擬合訓練資料,此外,相比于其它激活函式來說,ReLU有以下優勢:
a.對于線性函式而言,ReLU的表達能力更強,尤其體現在深度網路中;
b.對于非線性函式而言,ReLU由于非負區間的梯度為常數,因此不存在梯度消失問題(Vanishing Gradient Problem),使得模型的收斂速度維持在一個穩定狀態,(梯度消失問題:當梯度小于1時,預測值與真實值之間的誤差每傳播一層會衰減一次,如果在深層模型中使用sigmoid作為激活函式,這種現象尤為明顯,將導致模型收斂停滯不前,)
參考博客:
Normalization
深度學習基礎系列(七)| Batch Normalization
ReLU激活函式:簡單之美
(2)Fuse部分 :為了使神經元能夠根據刺激內容自適應地調整RF值的大小,采用了一個面向元素的求和門來整合來自兩個分支的不同資訊,生成混合特征圖Y,然后,利用Global Average Pooling (全域平均池化)操作生成Y的全域資訊,記為g,為了防止不同樣本之間的系數大小存在偏差,在通道上對g進行了Normalization(歸一化處理),然后,將得到的全域特征向量發送到fc層(Full Connection Layer ,全連接層),再通過卷積層進行1x1的卷積操作,批量標準化和ReLU函式,同時降低g的維數以提高效率,得到全域特征向量g1,再將SGE模塊嵌入到不同的分支中,分別生成具有空間群增強注意的Y1’和Y2’,這個程序可以總結如下:
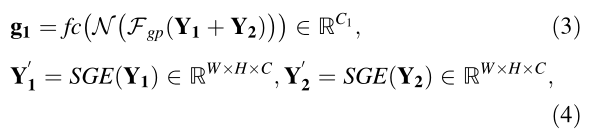
公式(3)中的三個變數從前往后分別表示fc層、歸一化和全域平均池化操作,公式(4)中的SGE指的是SGE模塊的操作,
- Pooling Layer:池化層,常見的的池化層有最大池化(max pooling)和平均池化(average pooling)兩種,如下圖所示,
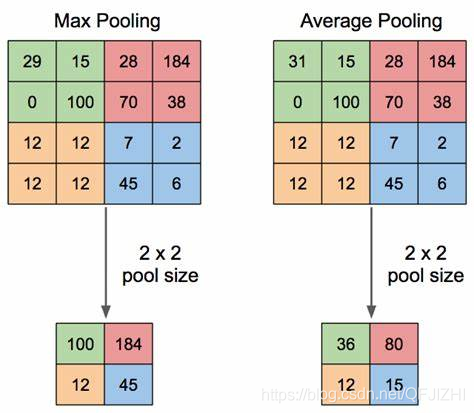
池化層的作用:
a.通過池化層可以減少空間資訊的大小,提高運算效率;
b.減少空間資訊也就意味著減少引數,這也降低了overfit的風險;
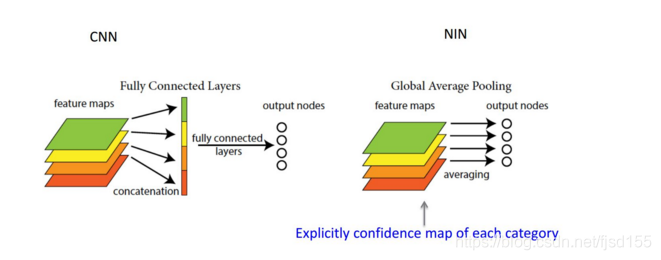
c.獲得空間變換不變性(translation rotation scale invarance,平移旋轉縮放的不變性); - Global Average Pooling:全域平均池化,主要是用來解決全連接的問題,可以減少引數數量,將最后一層的特征圖進行整張圖的一個均值池化,形成一個特征點,將這些特征點組成最后的特征向量,在softmax中進行計算,舉個例子,假如,最后的一層的資料是10個6X6的特征圖, 計算每張特征圖所有像素點的均值,然后輸出一個資料值,這樣共輸出10個資料值,組成一個1X10的特征向量,然后就可以送入softmax的分類中進行計算了,
全連接與全域均值池化的對比:
- Full Connection Layer:全連接層,在整個卷積神經網路中起到分類器的作用,通過卷積、激活函式、池化等深度網路后,再經過全連接層對結果進行識別分類,假設原圖片尺寸為9X9,在一系列的卷積、relu、池化操作后,得到尺寸被壓縮為2X2的三張特征圖,
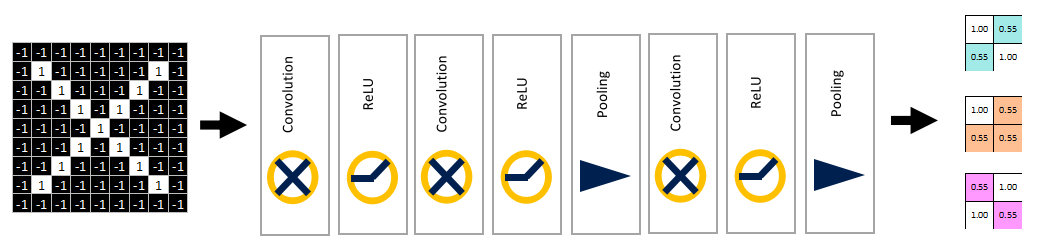
將經過卷積、激活函式、池化后的結果串起來,如下圖所示,
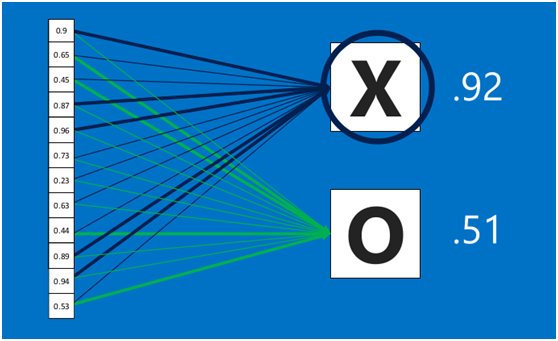
利用該模型進行結果識別時,根據模型訓練得出來的權重,以及經過前面的卷積、激活函式、池化等網路計算出來的結果,進行加權求和,得到各個結果的預測值,然后將取值最大的作為識別結果(如下圖,最后計算出來字母X的識別值為0.92,字母O的識別值為0.51,則結果判定為X),此外,全連接層也可以有多個,
- 1x1卷積:在 CNN 網路中,能夠實作降維,減少 weights 引數數量,也能夠實作升維,來拓寬 feature maps,在不改變 feature maps 的 size 的前提下,實作各通道之間的線性組合,實際上是通道像素之間的線性組合,后接非線性的激活函式,增加更多樣的非線性特征,
參考博客:
pooling layer(池化層)介紹及作用
Global Average Pooling
卷積神經網路中的 “全連接層”
卷積神經網路CNN【5】FC全連接層
1x1卷積核的作用
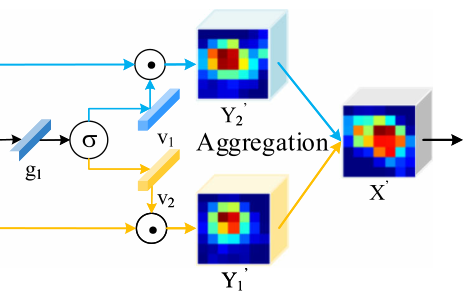
(3)Aggregation部分 :
在全域特征向量g1上應用softmax算子來選擇不同的資訊RFs,這個可以看作是一種軟注意機制,通過運算得到兩個不同的資訊特征向量v1和v2,通過用v1縮放Y1’和v2縮放Y2’,生成增強的特征圖A和B,將兩個分支的結果進行相加,得到最終的特征映射X’,這個程序可以總結如下:

其中,softmax表示softmax函式,
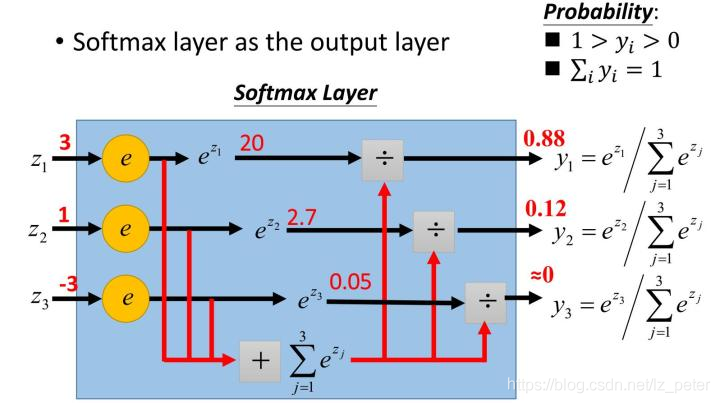
- softmax函式:又稱歸一化指數函式,它是二分類函式sigmoid在多分類上的推廣,目的是將多分類的結果以概率的形式展現出來,
參考博客:
一分鐘理解softmax函式(超簡單)
由于SKA模塊是輕量級的,沒有引入太多的計算量和引數,因此它可以輕松嵌入任何主流骨干網路,此外,該演算法在細粒度視覺分類任務中學習資訊特征圖具有較高的效率,本文將SKA模塊應用到ResNet的標準殘差塊中,構造了一個新穎高效的塊,構成了特征提取器的核心,通過上述特征提取器,可以提取有資訊的特征圖,
2.5.3 多尺度正則化(Multi-scale regularizer)
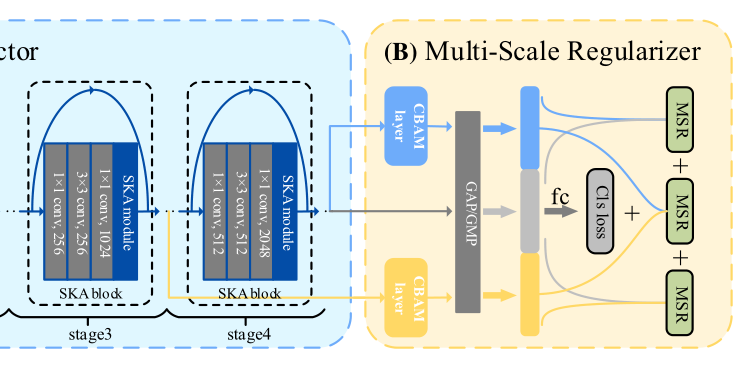
中層特征圖通常承載更精確的位置資訊,而高層特征圖則承載更有區別的語意資訊,因此,采用簡單的思想,從不同層提取的多尺度特征圖組合成金字塔結構進行預測,如上圖所示,設F3和F4分別為stage3和stage4的feature map,將它們提供給CBAM層,以加強語意資訊,然后從最后一個全連接層和一個SoftMax函式得到三個預測分布,P3, P4和P,P對應于F4,為原始特征提取器輸出的特征圖,已知預測分布P3、P4和P,則分類損失函式可表示為:
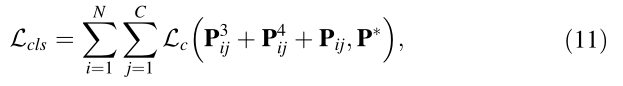
Lc表示交叉熵損失,P*是真實的標簽向量,C為類號,N為小批號,最后,通過定義的損失函式對整個模型進行優化:

超引數α用于平衡不同部分的貢獻,其值設定為1,
2.6 實驗結果
2.6.1 實作細節
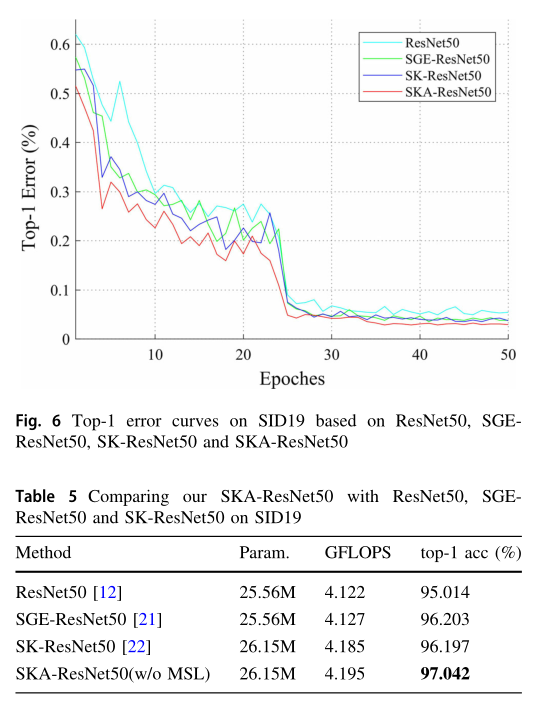
在新提出的手術器械資料集SID19上進行了實驗,其中有19個類,每個類有200張影像,訓練集與測驗集的比值是3:2,使用資料分片在SID19上進行分布式訓練,在gpu上均勻劃分資料,在資料處理階段,對影像進行均值/標準差重標,進行rgb歸一化處理,輸入影像的大小被調整為256X256用于訓練和測驗,然后,對每個影像進行隨機調整大小的裁剪,以獲得224X224的尺寸,
此外,在訓練和測驗階段采用隨機水平翻轉和垂直翻轉,在SID19上訓練了50個epoch,默認批大小設定為64,基礎學習率設定為0.01 (VGGNet[37]為0.1),它在50個周期中衰減10個周期,由于resnext50的固定優化結構,引數基數被設定為32以生成32個群組增強的注意力地圖,還原比r設為16,特別地,利用conv4_6和conv5_3之后的CBAM層生成用于ResNet50多尺度學習的增強特征圖F3和F4,兩個增強特征圖的尺寸為28X28X1024和14X14X2028,然后通過兩個不同的fc層生成相應的預測分布,采用top-1精度作為評價標準,采用交叉熵函式度量損耗,所有實驗都是基于Python 3.6和PyTorch框架實作,
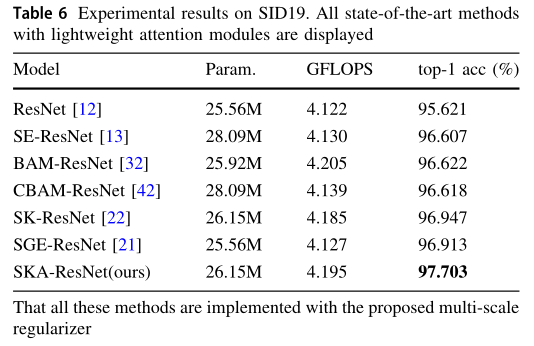
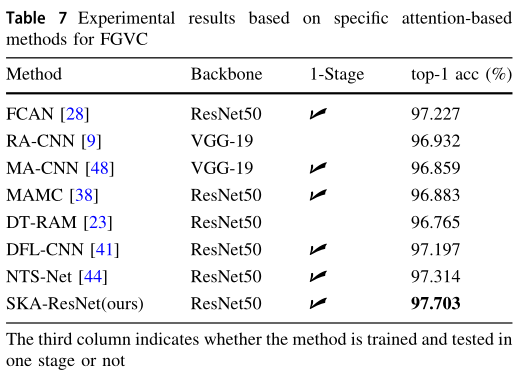
2.6.2 與其他模型對比
與輕量級注意模塊的比較:
為了公平比較,所有顯示方法都采用基于統一ResNet50骨干網的多尺度正則化器實作,所有的注意模塊都在最后一個BatchNorm層之后使用,
與基于注意的FGVC方法比較:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/316069.html
標籤:AI