
目錄
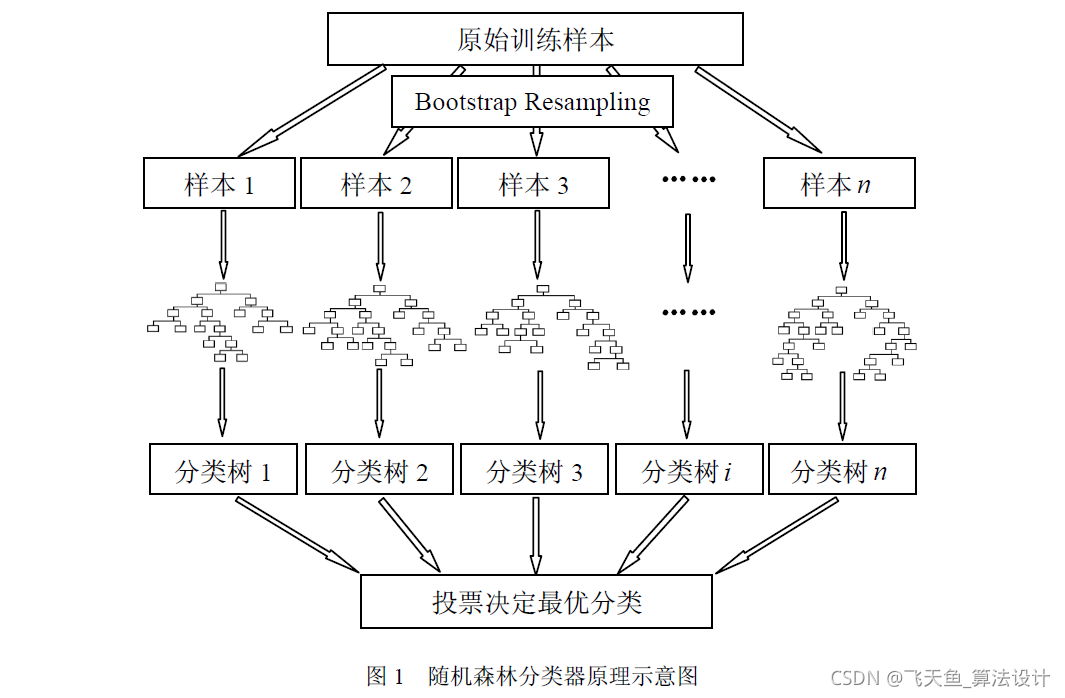
1 隨機森林重要性分析的基本原理
?
2 基于隨機森林的變數重要性評分
3 實戰案例
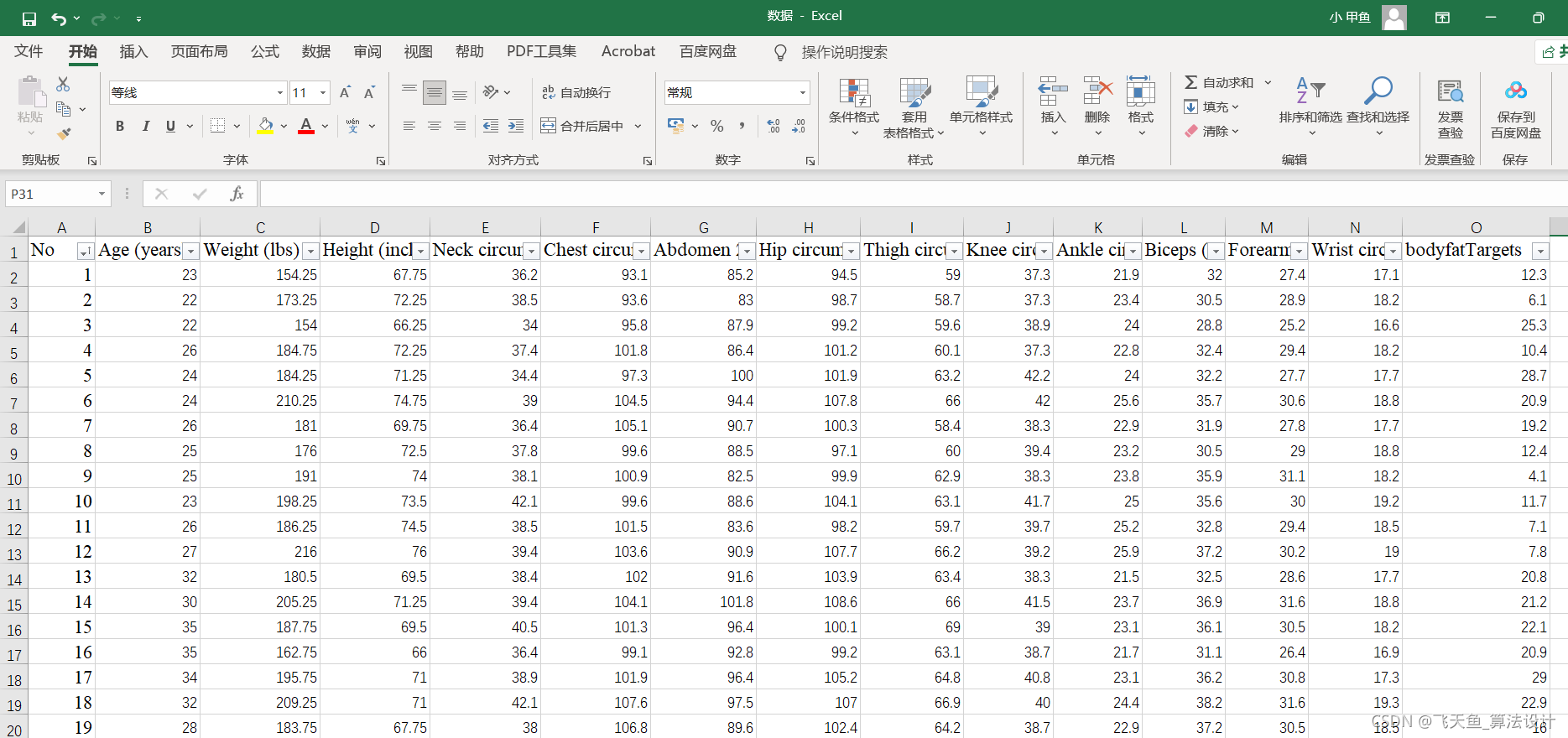
3.1 輸入變數(13個屬性因素,252組)
3.2 輸出變數(體脂含量指標,單輸出,252組)
3.3 部分代碼
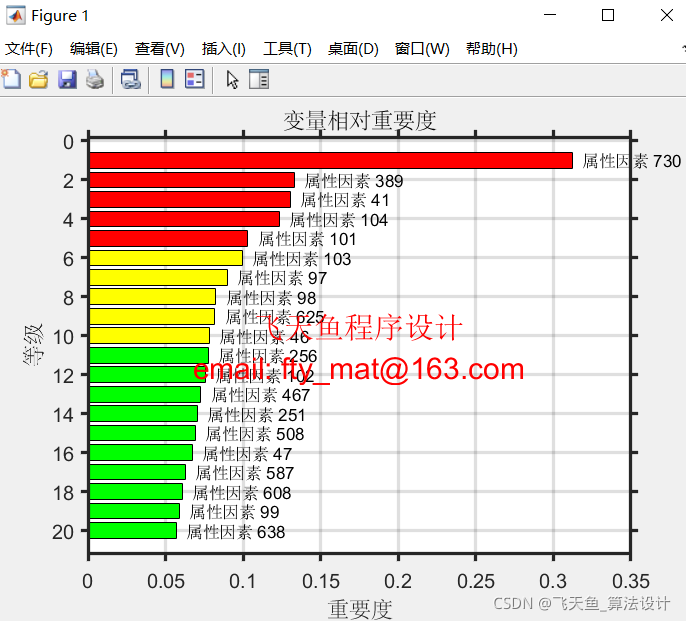
3.4 隨機森林對變數重要性分析結果
4 MATLAB全部代碼
1 隨機森林重要性分析的基本原理

2 基于隨機森林的變數重要性評分


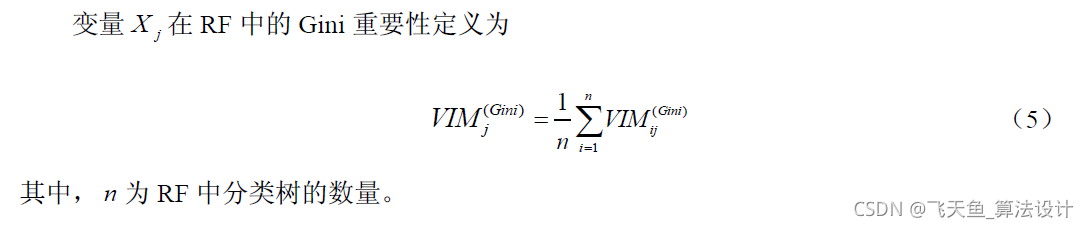


3 實戰案例
以人體的體脂資料集百分比資料集為例,資料集body_fat dataset,是深度學習中常用的預測應用資料,對該資料集的變數解釋如下:
3.1 輸入變數(13個屬性因素,252組)
1.年齡(年)
2.重量(磅)
3.高度(英寸)
4.頸圍(厘米)
5.胸圍(厘米)
6.腹部2周長(厘米)
7.臀圍(厘米)
8.大腿圍(厘米)
9.膝圍(厘米)
10.踝圍(厘米)
11.二頭肌(延長)周長(厘米)
12.前臂周長(厘米)
13腕圍(厘米)
3.2 輸出變數(體脂含量指標,單輸出,252組)
1. 身體脂肪含量
3.3 部分代碼
%% 隨機森林主程式
%----------------------------
clear
clc
close all
%資料匯入
data = xlsread('資料.xlsx', 'Sheet1', 'B2:O253');
%訓練/測驗資料
input = data(:,1:end-1);
output= data(:,end);
% 準備輸入和輸出訓練資料
input_train =input(1:ntrain,:);
output_train=output(1:ntrain,:);
% 準備測驗資料
input_test =input(ntrain+1:ntrain+ntest,:);
output_test=output(ntrain+1:ntrain+ntest,:);
%% 隨機森林引數設定
%葉子數
leaf=5;
%森林大小
ntrees=800;
%樹木根
fboot=1;
surrogate='on';
% 訓練模型
In = input_train;
Out = output_train;3.4 隨機森林對變數重要性分析結果
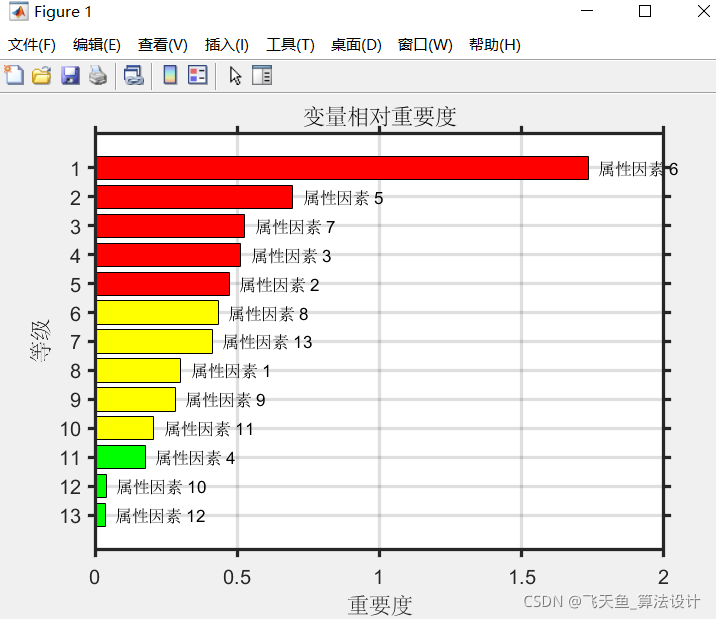
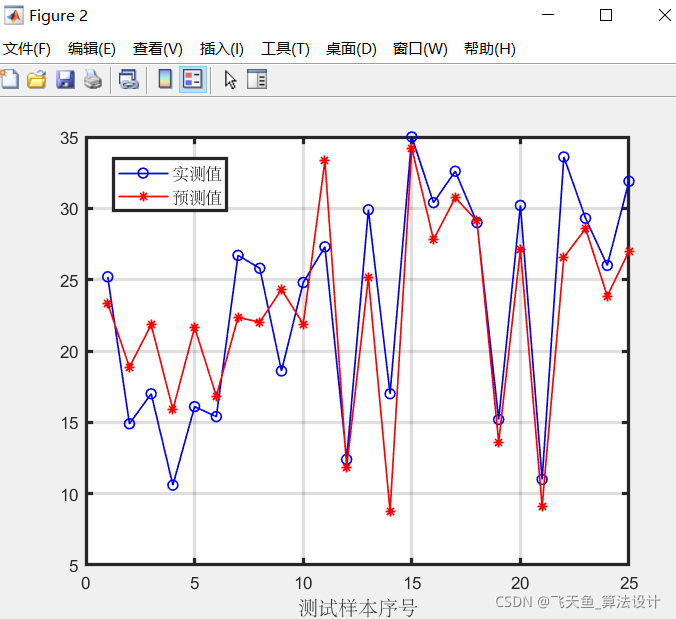
參考文獻:[1]馬金沙. 基于隨機森林變數重要性評分的變數篩選方法及其在腫瘤分型診斷中的應用[D].山西醫科大學,2021.
4 MATLAB全部代碼
MATLAB代碼地址https://mianbaoduo.com/o/bread/YZ6WlZ1x![]() https://mianbaoduo.com/o/bread/YZ6WlZ1x
https://mianbaoduo.com/o/bread/YZ6WlZ1x
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/316346.html
標籤:AI