大資料是為解決海量資料采集、存盤和計算,
hadoop是又Apache基金會所開發的分布式系統基礎架構,主要是為解決海量資料的存盤和海量資料的分析計算問題,
Hapood生態圈:
①高可靠性:hadoop底層維護多個資料副本,所以即使hadoop某個計算元素存盤出現故障,也不會導致資料丟失
②高擴展性:在集群間分配任務資料,可方便的擴展數數以千計的節點
③高效性:在MapReduce的思想下,Hadoop的并行作業的,以加快任務處理速度,
④高容錯性: 能夠自動將失敗的任務重新分配
在這里主要是介紹:hadoop 3.x
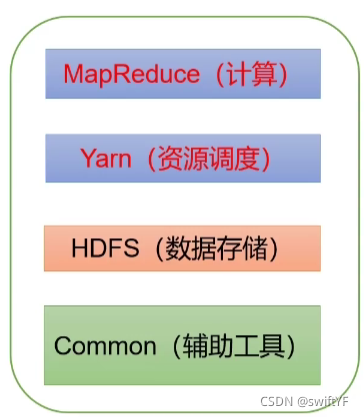
資料儲存的組件:
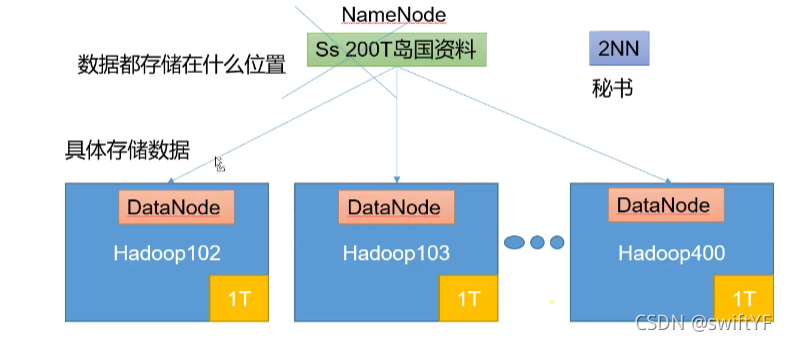
NameNode:存盤檔案的元資料,入檔案名,檔案目錄,檔案屬性(生成時間、副本數、檔案權限,以及每個檔案的塊串列和塊所在的DataNode),
DataNode:在本地檔案系統存盤檔案塊資料,以及塊資料的校驗和,
yarn:是一種資源協調者,是hadoop的資源管理器,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/316426.html
標籤:其他
上一篇:前端程式猿常用的編輯器