操作步驟:
1、首先在linux下新建一個.txt檔案,如word.txt,直接使用vim命令進行編輯

輸入幾個單詞

使用命令hadoop fs -put word.txt /wordcount/in 這邊可以指定一個目錄,
然后輸入命令hadoop jar hadoop-mapreduce-examples-3.1.4.jar wordcount /wordcount/in /wordcount/out
回車執行,
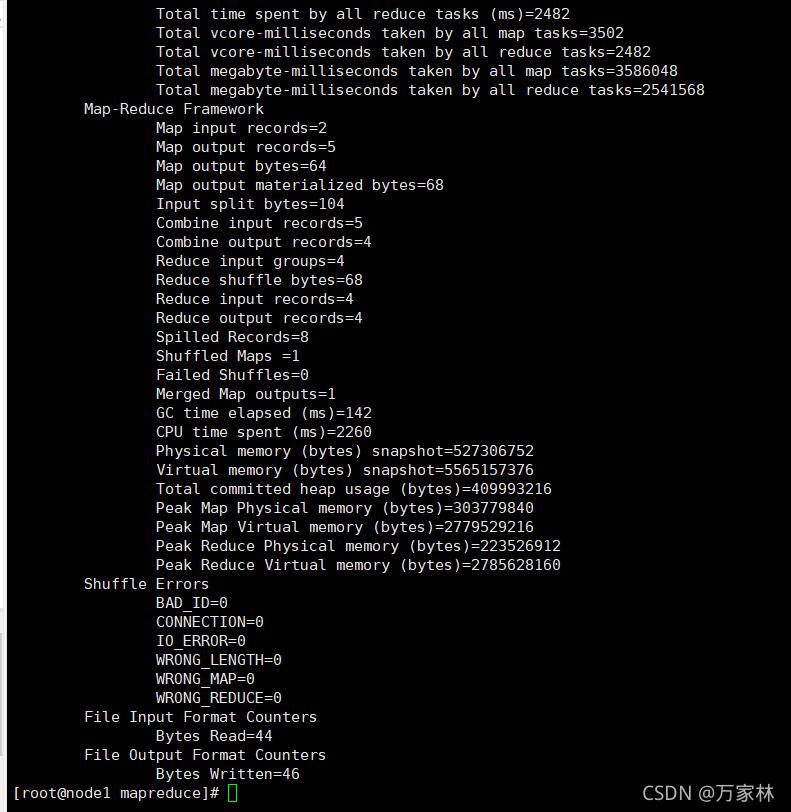
運行成功,接下來去瀏覽器查看資訊,打開瀏覽器輸入node1:9870
進入這個頁面,點擊
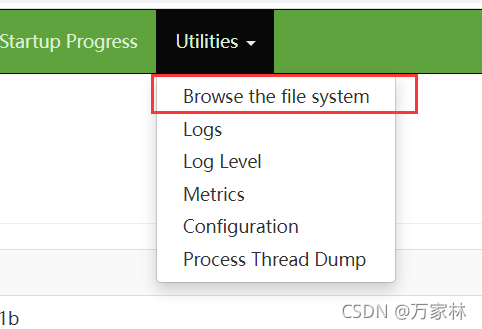

可以看到我們剛剛建的檔案夾,點擊進入可以看到in和out兩個檔案夾,我們打開檔案夾out,點擊part-r-0000,點擊download,下載完成后,用記事本打開就可以查看到對應的單詞和數量,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/316442.html
標籤:其他