微信搜【假裝懂編程】,與作者零距離交流
由于作業中經常用到kafka,但是對kafka的一些內部機制不是很熟悉,所以最近在看kafka相關的知識,我們知道kafka非常經典的訊息引擎,它以高性能、高可用著稱,那么問題來了,它是怎么做到高性能、高可用的?它的訊息是以什么樣的形式持久化的?既然寫了磁盤,為何速度還那么快?它是如何保證訊息不丟失的...?帶著這一系列的問題,我們來扒開kafka的面紗,
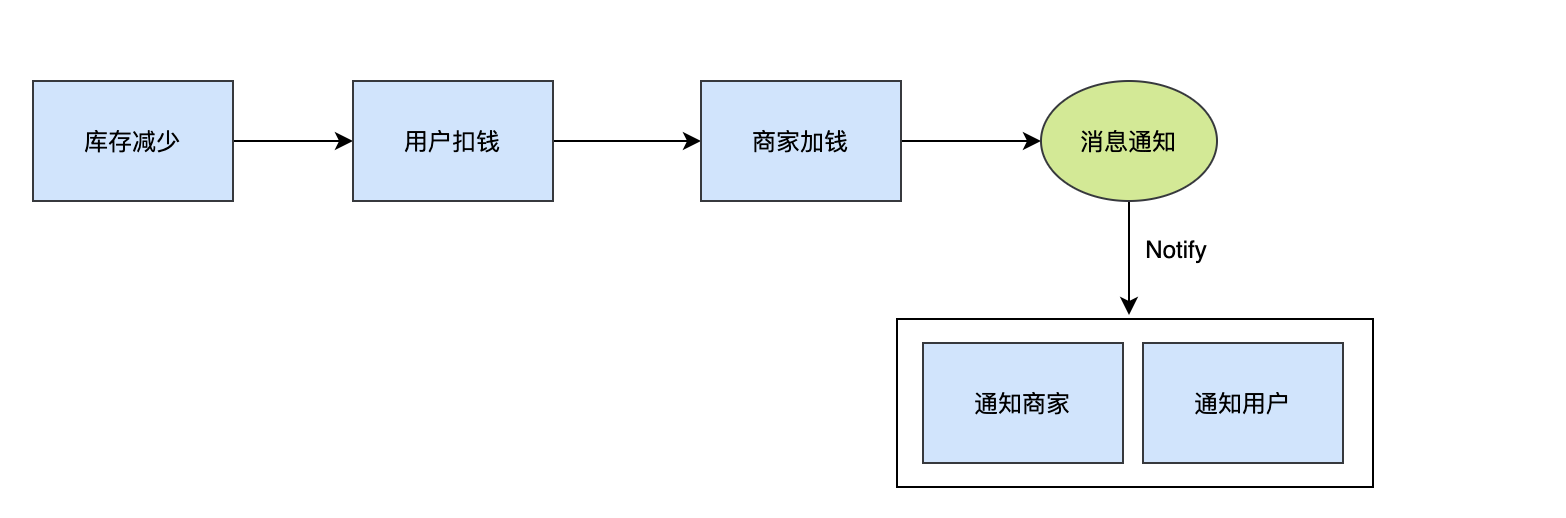
首先我們思考這樣一個問題:為什么需要訊息引擎?為什么不能直接走rpc? 以一個訂單系統為例:當我們下了一個訂單的時候,應該是要先減商品庫存,然后用戶支付扣錢,商家賬戶加錢...,最后可能還要發推送或者短信告訴用戶下單成功,告訴商家來訂單了,

這整個下單程序,如果全部同步阻塞,那么耗時會增加,用戶等待的時間會加長,體驗不太好,同時下單程序依賴的鏈路越長,風險越大,為了加快回應,減少風險,我們可以把一些非必須卡在主鏈路中的業務拆解出去,讓它們和主業務解耦,下單的最關鍵核心就是要保證庫存、用戶支付、商家打款的一致性,訊息的通知完全可以走異步,這樣整個下單程序不會因為通知商家或者通知用戶阻塞而阻塞,也不會因為它們失敗而提示訂單失敗,
接下來就是如何設計一個訊息引擎了,宏觀來看一個訊息引擎支持發送、存盤、接收就行了,
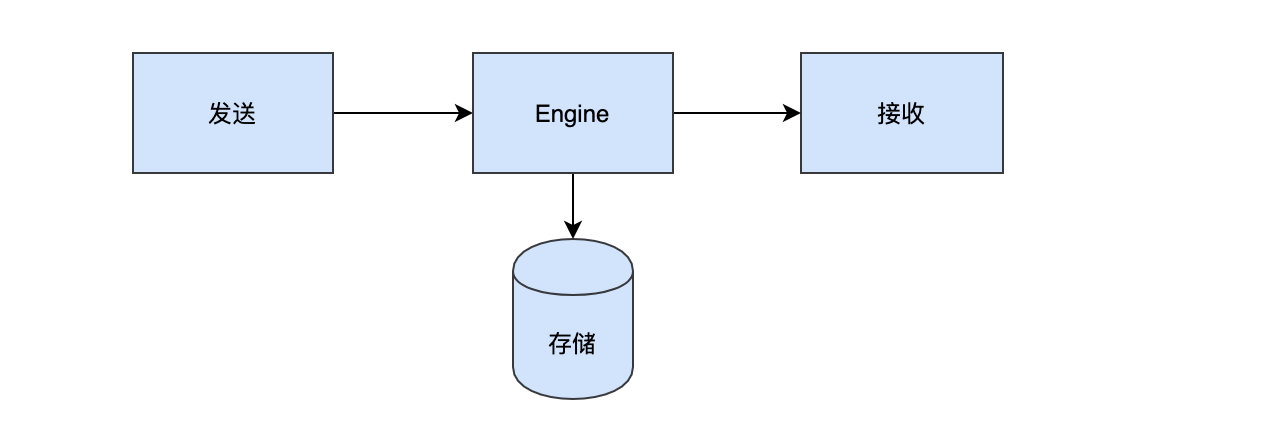
那么如上圖一個簡易訊息佇列模型出現了,Engine把發送方的訊息存盤起來,這樣當接收方來找Engine要資料的時候,Engine再從存盤中把資料回應給接收放就ok了,既然涉及到持久化的存盤,那么緩慢的磁盤IO是要考慮的問題,還有接收方可能不止一個,以上述訂單為例,下單完成之后,通過訊息把完成事件發出去,這時候負責用戶側推送的開發需要消費這條訊息,負責商戶側推送的開發也需要消費這條訊息,能想到的最簡單的做法就是copy出兩套訊息,但是這樣是不是顯得有點浪費?高可用也是一個需要考慮的點,那么我們的engine是不是得副本,有了副本之后,如果一個engine節點掛掉,我們可以選舉出一個新副本來作業,光有副本也不行,發送方可能也是多個,這時候如果所有的發送方都把資料打到一個Leader(主)節點上似乎也不合理,單個節點的壓力太大,可能你會說:不是有副本嗎?讓接收方直接從副本讀取訊息,這樣的話又帶來另一個問題:副本復制Leader的訊息延遲了咋辦?讀不到訊息再讀一次Leader?如果這樣的話,引擎的設計的貌似更加復雜了,似乎不太合理,那就得想一種既能不通過副本又能分散單節點壓力就行了,答案就是分片技術,既然單個Leader節點壓力太大,那么就分成多個Leader節點,我們只需要一個好的負載均衡演算法,通過負載均衡把訊息平均分配到各個分片節點就好了,于是我們可以設計出一套大概長這樣的生產者-消費者模型,
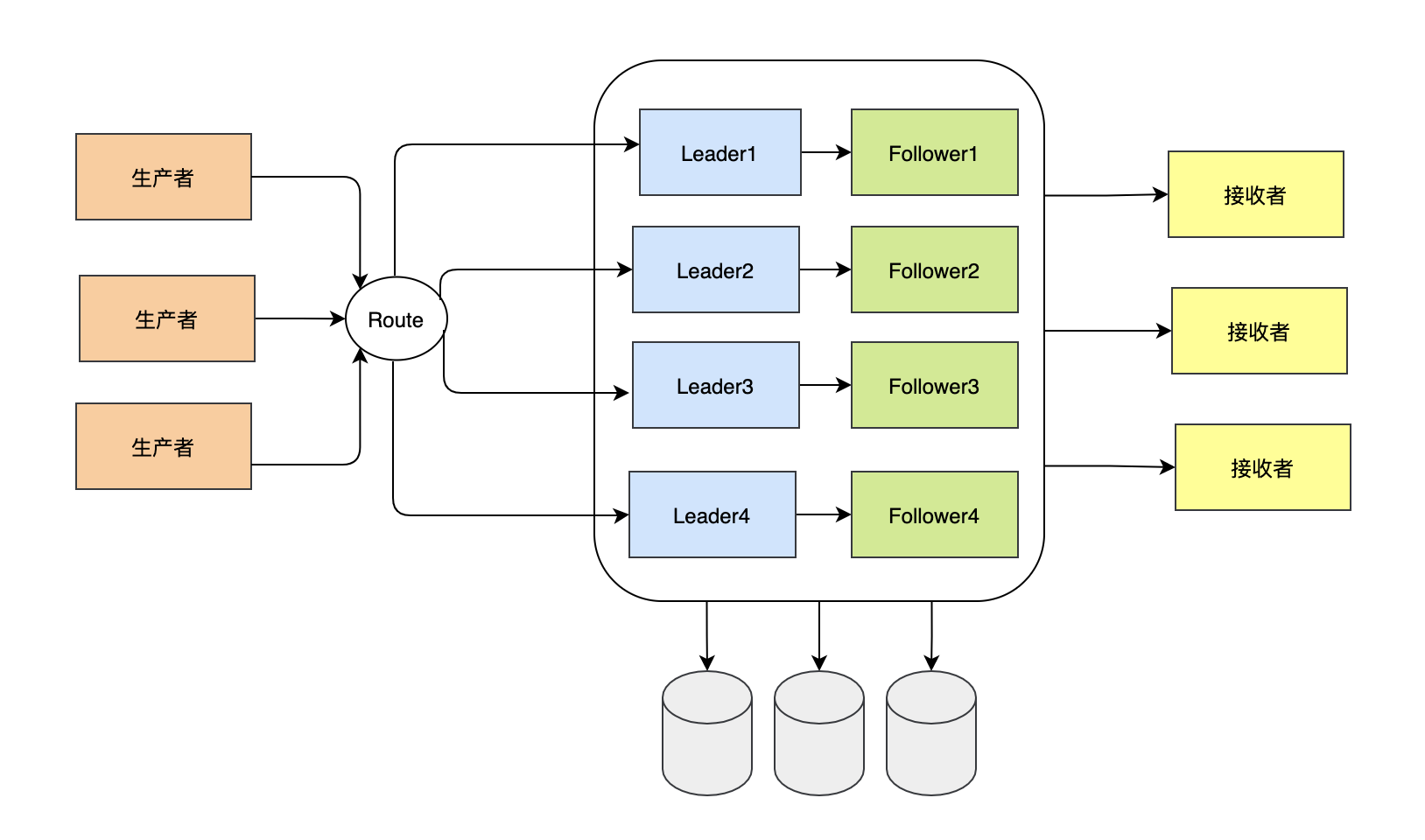
但是這些只是簡單的想法,具體如何實作還是很復雜的,帶著這一系列問題和想法,我們來看看kafka是如何實作的,
思考與實作
首先我們還是從kafka的幾個名詞入手,主要介紹下訊息、主題、磁區和消費者組,
一條訊息該怎么設計
訊息是服務的源頭,一切的設計都是為了將訊息從一端送到另一端,這里面涉及到訊息的結構,訊息體不能太大,太大容易造成存盤成本上升,網路傳輸開銷變大,所以訊息體只需要包含必要的資訊,最好不要冗余,訊息最好也支持壓縮,通過壓縮可以在訊息體本身就精簡的情況下變的更小,那么存盤和網路開銷可以進一步降低,訊息是要持久化的,被消費掉的訊息不能一直存盤,或者說非常老的訊息被再次消費的可能性不大,需要一套機制來清理老的訊息,釋放磁盤空間,如何找出老的訊息是關鍵,所以每個訊息最好帶個訊息生產時的時間戳,通過時間戳計算出老的訊息,在合適的時候進行洗掉,訊息也是需要編號的,編號一方面代表了訊息的位置,另一方面消費者可以通過編號找到對應的訊息,大量的訊息如何存盤也是個問題,全部存盤在一個檔案中,查詢效率低且不利于清理老資料,所以采用分段,通過分段的方式把大的日志檔案切割成多個相對小的日志檔案來提升維護性,這樣當插入訊息的時候只要追加在段的最后就行,但是在查找訊息的時候如果把整個段加載到記憶體中一條一條找,似乎也需要很大的記憶體開銷,所以需要一套索引機制,通過索引來加速訪問對應的Message,
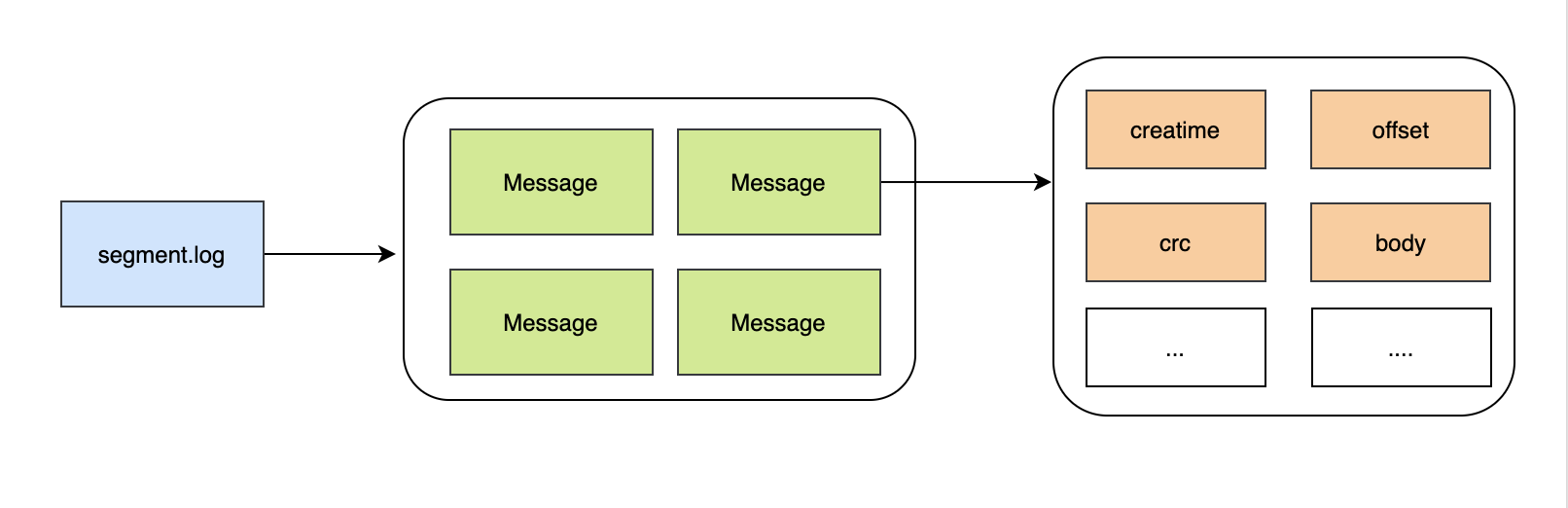
總結:一條kafka的訊息包含創造時間、訊息的序號、支持訊息壓縮,存盤訊息的日志是分段存盤,并且是有索引的,
為什么需要Topic
宏觀來看訊息引擎就是一發一收,有個問題:生產者A要給消費者B發送訊息,同時也要給消費者C發送訊息,那么消費者B和消費者C如何只消費到自己需要的資料?能想到的簡單的做法就是在訊息中加Tag,消費者根據Tag來獲取自己的訊息,不是自己的訊息直接跳過,但是這樣似乎不太優雅,而且存在cpu資源浪費在訊息的過濾上,所以最有效的辦法就是對于給B訊息不會給C,給C的訊息不會給B,這就是Topic,通過Topic來區分不同的業務,每個消費者只需要訂閱自己關注的Topic即可,生產者把消費者需要的訊息通過約定好的Topic發過去,那么簡單的理解就是訊息按照Topic分類了,
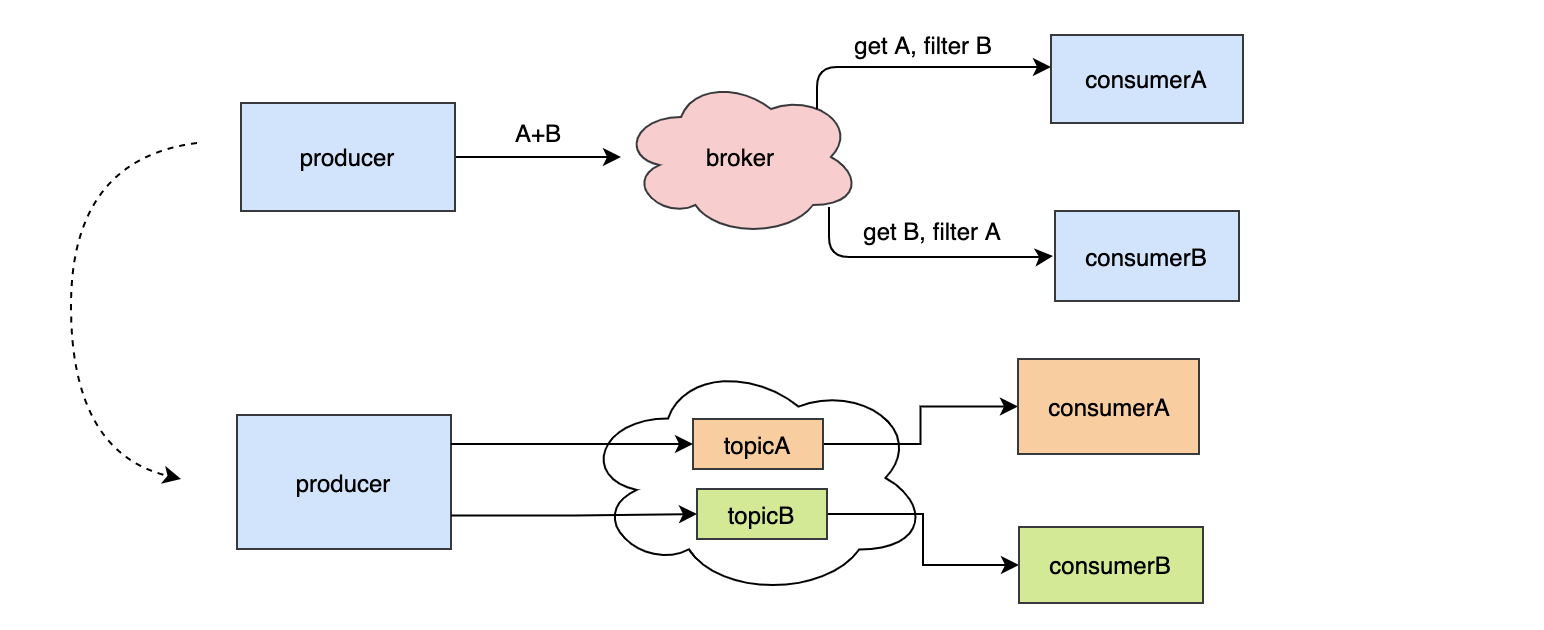
總結:Topic是個邏輯的概念,Topic可以很好的做業務劃分,每個消費者只需要關注自己的Topic即可,
磁區如何保證順序
通過上文我們知道磁區的目的就是分散單節點的壓力,再結合Topic和Message,那么訊息的大概分層就是Topic(主題)->Partition(磁區)->Message(訊息),也許你會問,既然磁區是為了降低單節點的壓力,那么干嘛不用多個topic代替多個磁區,在多個機器節點的情況下,我們可以把多個topic部署在多個節點上,似乎也能實作分布式,簡單一想似乎可行,仔細一想,還是不對,我們最侄訓要服務業務的,這樣的話,本來一個topic的業務,要拆解成多個topic,反而把業務的定義打散了,
好吧,既然有多個磁區了,那么訊息的分配是個問題,如果topic下面的資料過于集中在某個磁區上,又會造成分布不均勻,解決這個問題,一套好的分配演算法是很有必要的,
kafka支持輪詢法,即在多磁區的情況下,通過輪詢可以均勻地把訊息分給每個磁區,這里需要注意的是,每個磁區里的資料是有序的,但是整體的資料是無法保證順序的,如果你的業務強依賴訊息的順序,那么就要慎重考慮這種方案,比如生產者依次發了A、B、C三個訊息,它們分別分布在3個磁區中,那么有可能出現的消費順序是B、A、C,
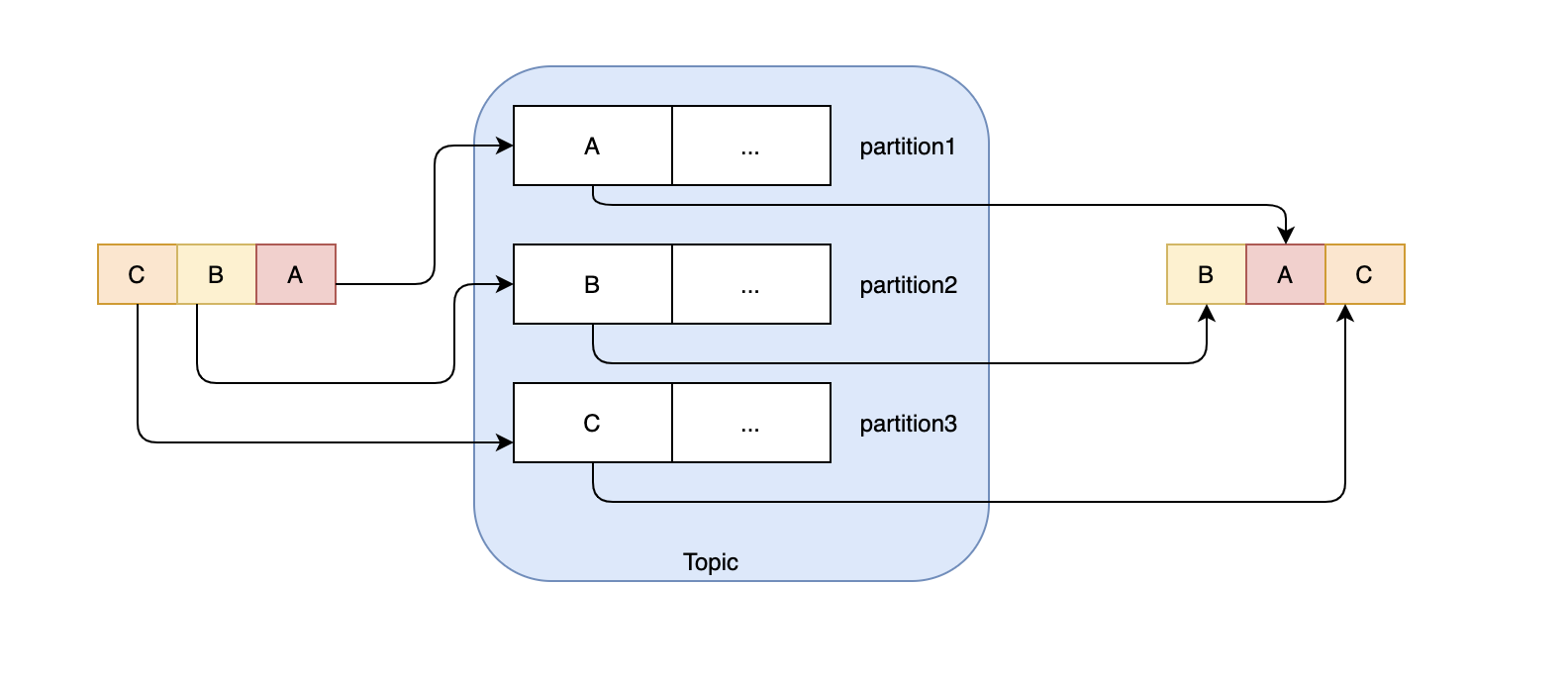
那么如何保證訊息的順序性?從整體的角度來看,只要磁區數大于1,就永遠無法保證訊息的順序性,除非你把磁區數設定成1,但是這樣的話吞吐就是問題,從實際的業務場景來說,一般我們可能需要某個用戶的訊息、或者某個商品的訊息有序就可以了,用戶A和用戶B的訊息誰先誰后沒關系,因為它們之間沒什么關聯,但是用戶A的訊息我們可能要保持有序,比如訊息描述的是用戶的行為,行為的先后順序是不能亂的,這時候我們可以考慮用key hash的方式,同一個用戶id,通過hash始終能保持分到一個磁區上,我們知道磁區內部是有序的,所以這樣的話,同一個用戶的訊息一定是有序的,同時不同的用戶可以分配到不同的磁區上,這樣也利用到了多磁區的特性,
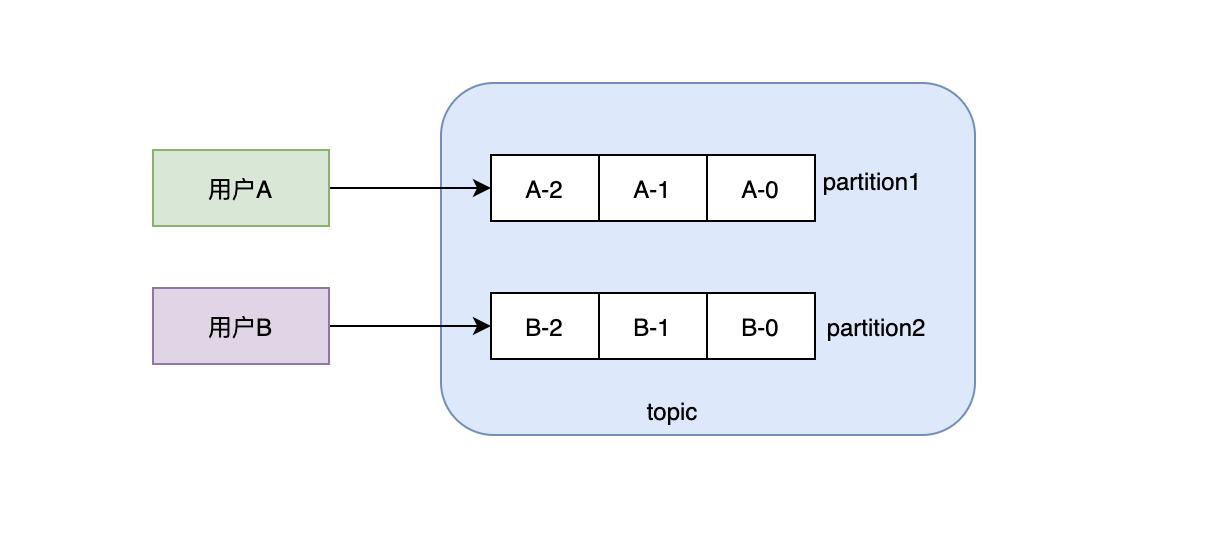
總結:kafka整體訊息是無法保證有序的,但是單個磁區的訊息是可以保證有序的,
如何設計一個合理的消費者模型
既然是設計訊息模型,那么消費者必不可少,實作消費者最簡單的方式就是起一個行程或者執行緒直接去broker里面拉取訊息即可,這很合理,但是如果生產的速度大于當前的消費速度怎么辦?第一時間想到的就是再起一個消費者,通過多個消費者來提升消費速度,這里似乎又有個問題,兩個消費者都消費到了同一條訊息怎么辦?加鎖是個解決方案,但是效率會降低,也許你會說消費的本質就是讀,讀是可以共享的,只要保證業務冪等,重復消費訊息也沒關系,這樣的話,如果10個消費者都爭搶到了同樣的訊息,結果有9個消費者都是白白浪費資源的,因此在需要多個消費者提升消費能力的同時,還要保證每個消費者都消費到沒被處理的訊息,這就是消費者組,消費者組下面可以有多個消費者,我們知道topic是磁區的,因此只要消費者組內的每個消費者訂閱不同的磁區就可以了,理想的情況下是每個消費者都分配到相同資料量磁區,如果某個消費者獲得的磁區數不平均(較多或者較少),出現資料傾斜狀態,那么就會導致某些消費者非常繁忙或者輕松,這樣就不合理,這就需要一套均衡的分配策略,
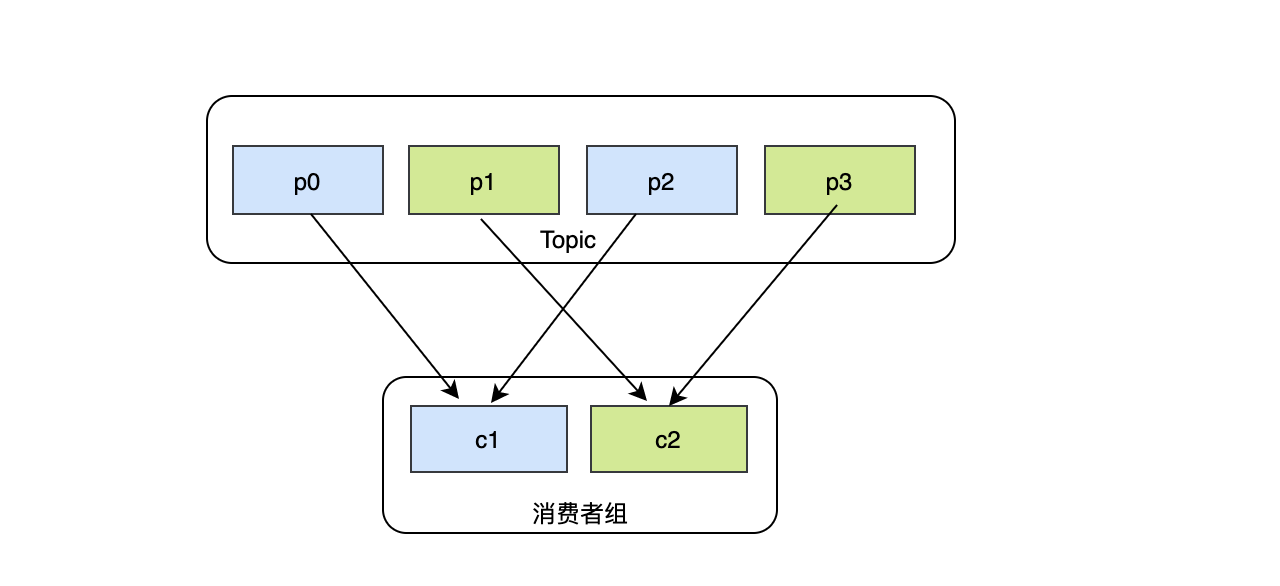
kafka消費者磁區分配策略主要有3種:
- Range:這種策略是針對topic的,會把topic的磁區數和消費者數進行一個相除,如果有余數,那就說明多余的磁區不夠平均分了,此時排在前面的消費者會多分得1個磁區,乍看其實挺合理,畢竟本來數量就不均衡,但是如果消費者訂閱了多個topic,并且每個topic平均算下來都多幾個個磁區,那么對于排在前面的消費者就會多消費很多磁區,
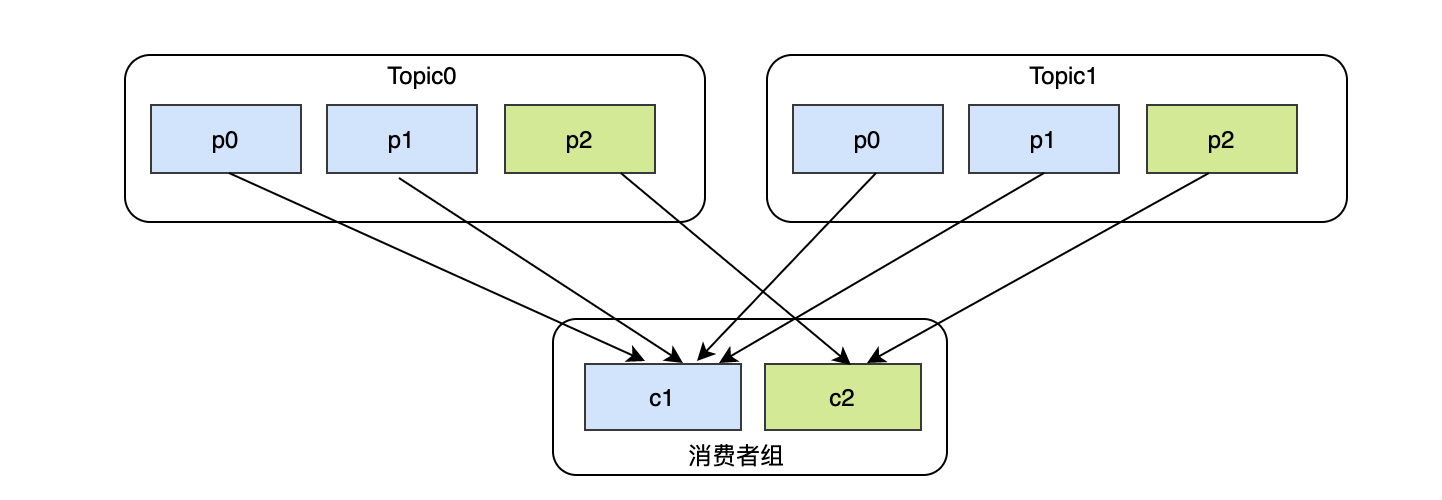
由于是按照topic維度來劃分的,所以最終:
- c1消費 Topic0-p0、Topic0-p1、Topic1-p0、Topic1-p1
- c2消費 Topic0-p2、Topic1-p2
最終可以發現消費者c1比消費者c2整整多兩個磁區,完全可以把c1的磁區分一個給c2,這樣就可以均衡了,
- RoundRobin:這種策略的原理是將消費組內所有消費者以及消費者所訂閱的所有topic的partition按照字典序排序,然后通過輪詢演算法逐個將磁區以此分配給每個消費者,假設現在有兩個topic,每個topic3個磁區,并且有3個消費者,那么大致消費狀況是這樣的:
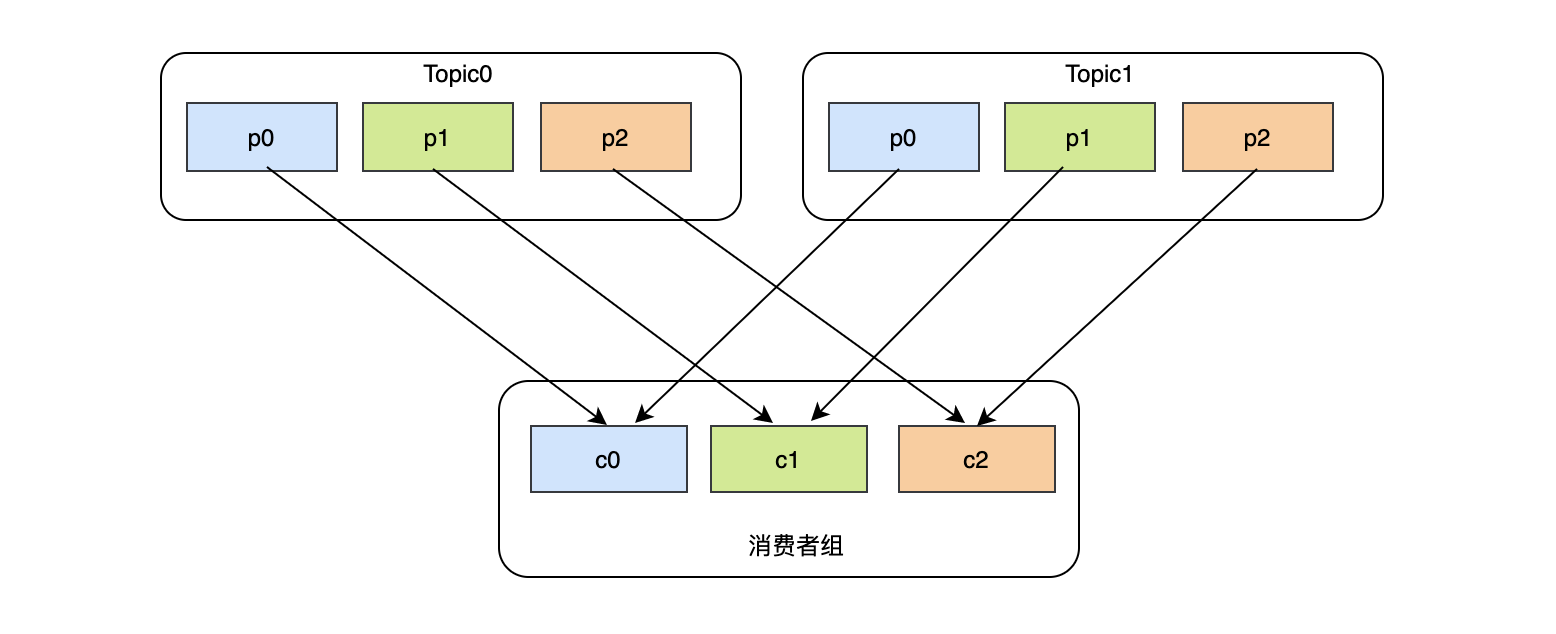
- c0消費 Topic0-p0、Topic1-p0
- c1消費 Topic0-p1、Topic1-p1
- c2消費 Topic0-p2、Topic1-p2
看似很完美,但是如果現在有3個topic,并且每個topic磁區數是不一致的,比如topic0只有一個磁區,topic1有兩個磁區,topic2有三個磁區,而且消費者c0訂閱了topic0,消費者c1訂閱了topic0和topic1,消費者c2訂閱了topic0、topic1、topic2,那么大致消費狀況是這樣的:
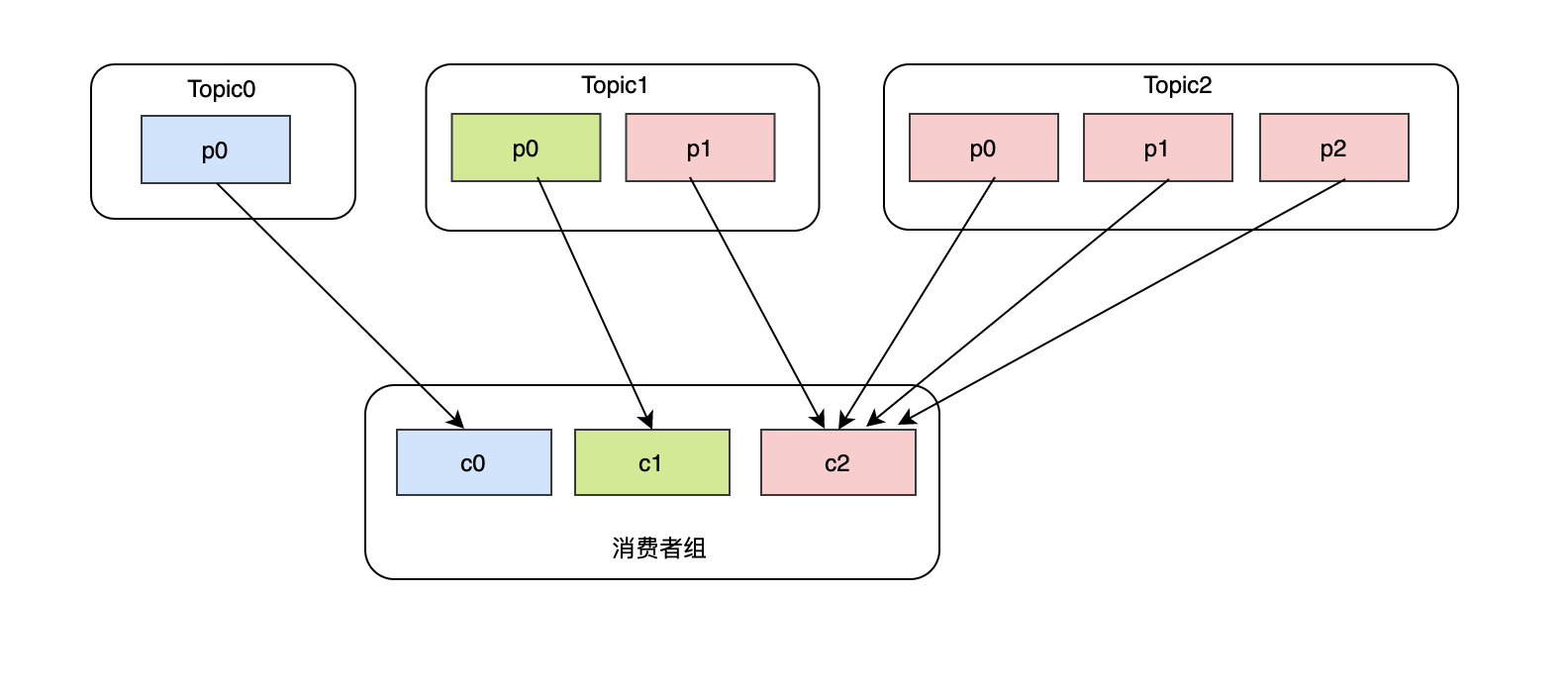
- c0消費 Topic0-p0
- c1消費 Topic1-p0
- c2消費 Topic1-p1、Topic2-p0、Topic2-p1、Topic2-p2
這么看來RoundRobin并不是最完美的,在不考慮每個topic磁區吞吐能力的差異,可以看到c2的消費負擔明顯很大,完全可以將Topic1-p1磁區分給消費者c1,
- Sticky:Range和RoundRobin都有各自的缺點,某些情況下可以更加均衡,但是沒有做到,
Sticky引入目的之一就是:磁區的分配要盡可能均勻,以上面RoundRobin 3個topic分別對應1、2、3個磁區的case來說,因為c1完全可以消費Topic1-p1,但是它沒有,針對這種情況,在Sticky模式下,就可以做到把Topic1-p1分給c1,
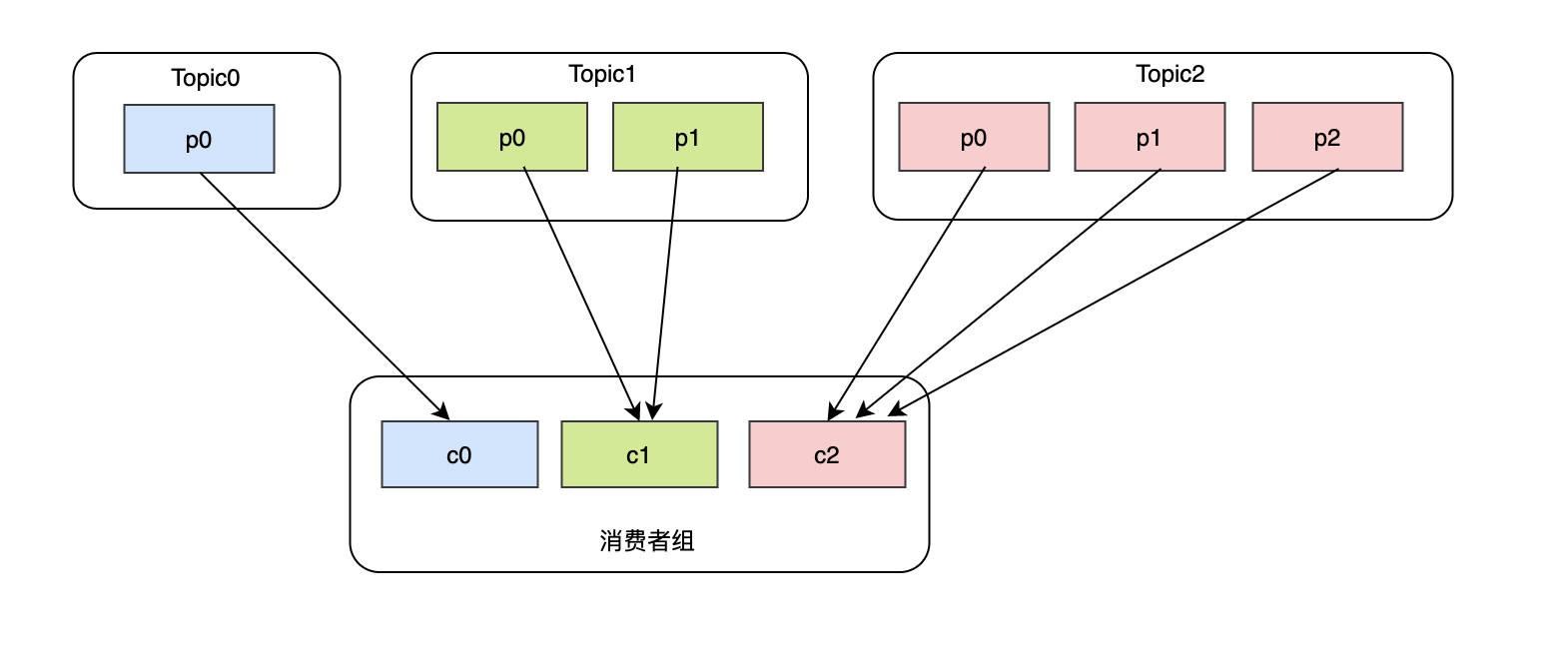
Sticky引入目的之二就是:磁區的分配盡可能與上次分配的保持相同,這里主要解決就是rebalance后磁區重新分配的問題,假設現在有3個消費者c0、c1、c2,他們都訂閱了topic0、topic1、topic2、topic3,并且每個topic都有兩個磁區,此時消費的狀況大概是這樣:
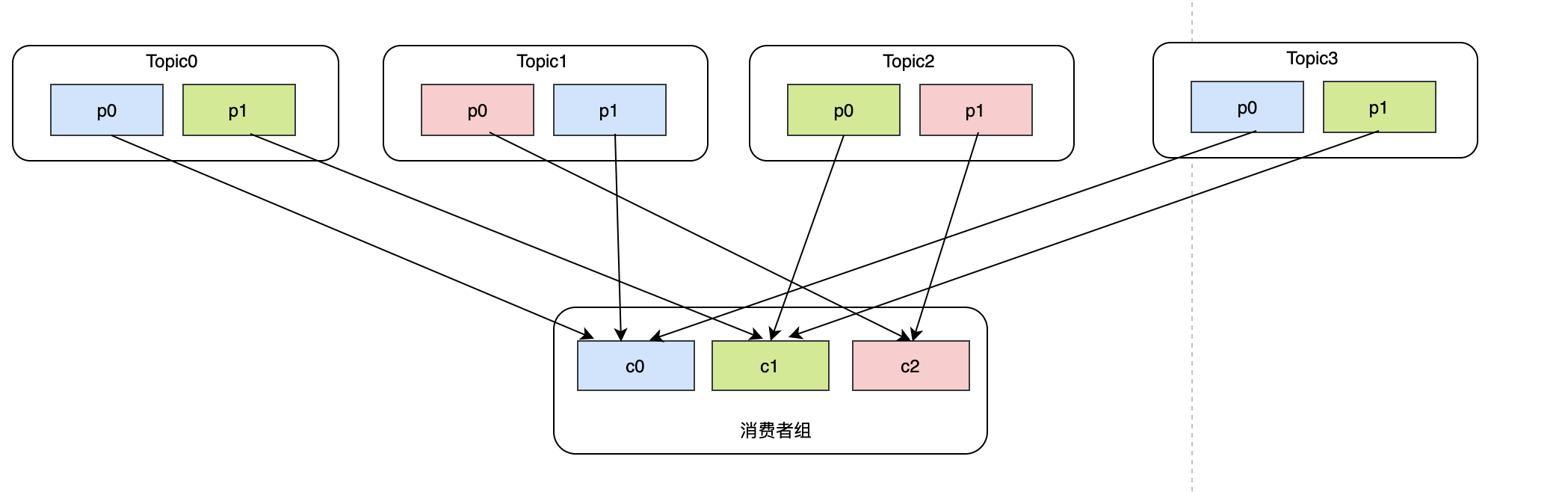
這種分配方式目前看RoundRobin沒什么區別,但是如果此時消費者c1退出,消費者組內只剩c0、c2,那么就需要把c1的磁區重新分給c0和c2,我們先來看看RoundRobin是如何rebalance的:
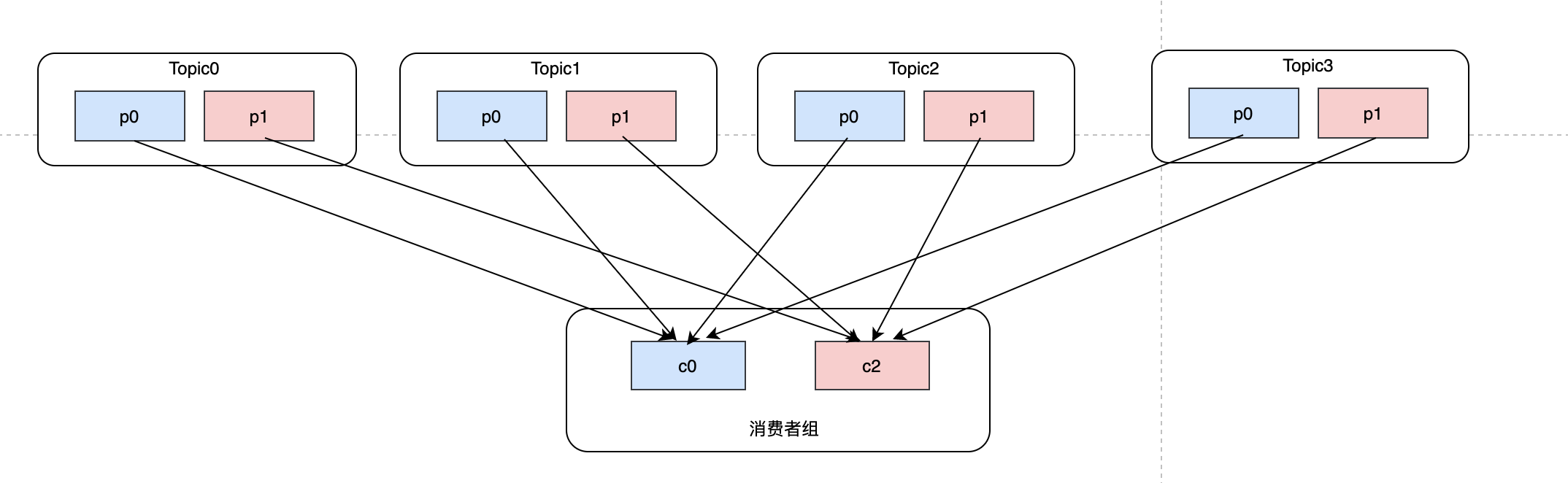
可以發現原來c0的topic1-p1分給了c2,原來c2的topic1-p0分給了c0,這種情況可能會造成重復消費問題,在消費者還沒來得及提交的時候,發現磁區已經被分給了一個新的消費者,那么新的消費者就會產生重復消費,但是從理論的角度來說,在c1退出之后,可以沒必要去動c0和c2的磁區,只需要把原本c1的磁區瓜分給c0和c2即可,這就是sticky的做法:
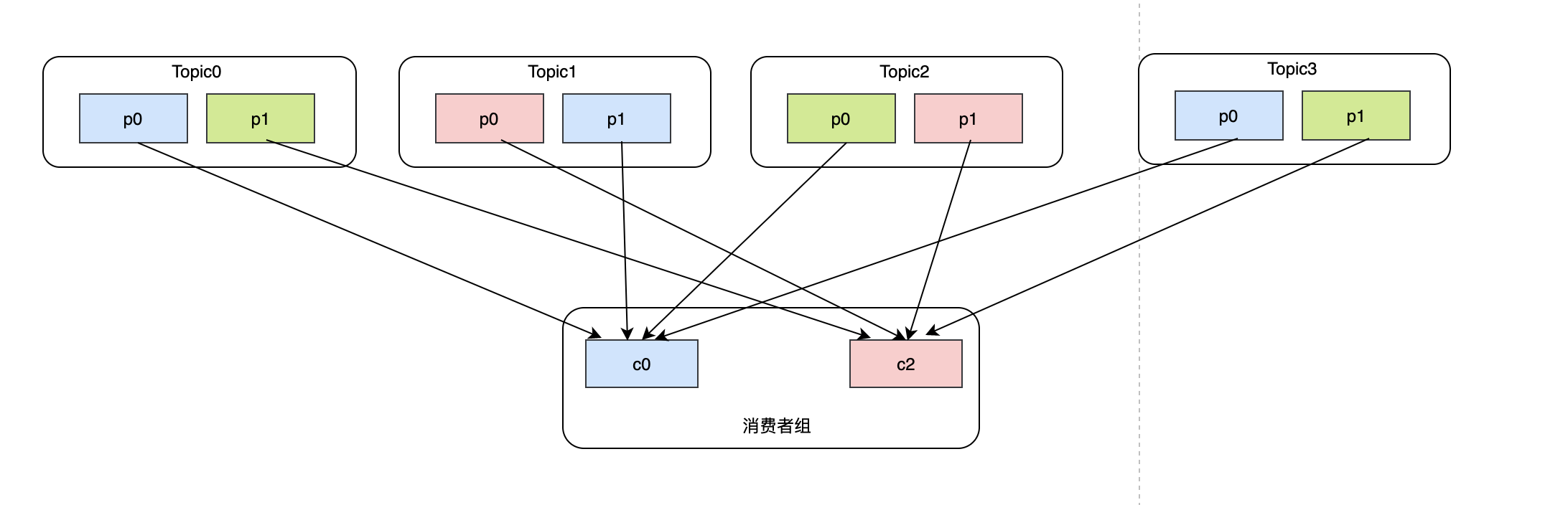
需要注意的是Sticky策略中,如果磁區的分配要盡可能均勻和磁區的分配盡可能與上次分配的保持相同發生沖突,那么會優先實作第一個,
總結:kafka默認支持以上3種磁區分配策略,也支持自定義磁區分配,自定義的方式需要自己去實作,從效果來看RoundRobin要好于Range的,Sticky是要好于RoundRobin的,推薦大家使用版本支持的最好的策略,
微信搜【假裝懂編程】,與作者零距離交流
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/316452.html
標籤:其他