1.
貢獻:
1.提出了一個用于聯合語意分割、邊界檢測和立體匹配的神經網路,其中語意和邊界資訊一致性成為視差估計的積極指導,
2.設計了一種使用注意力機制構建混合成本量的方法,該方法分別結合了三種不同的成本量,它們是語意成本量、邊界成本量和空間特征成本量,
4.
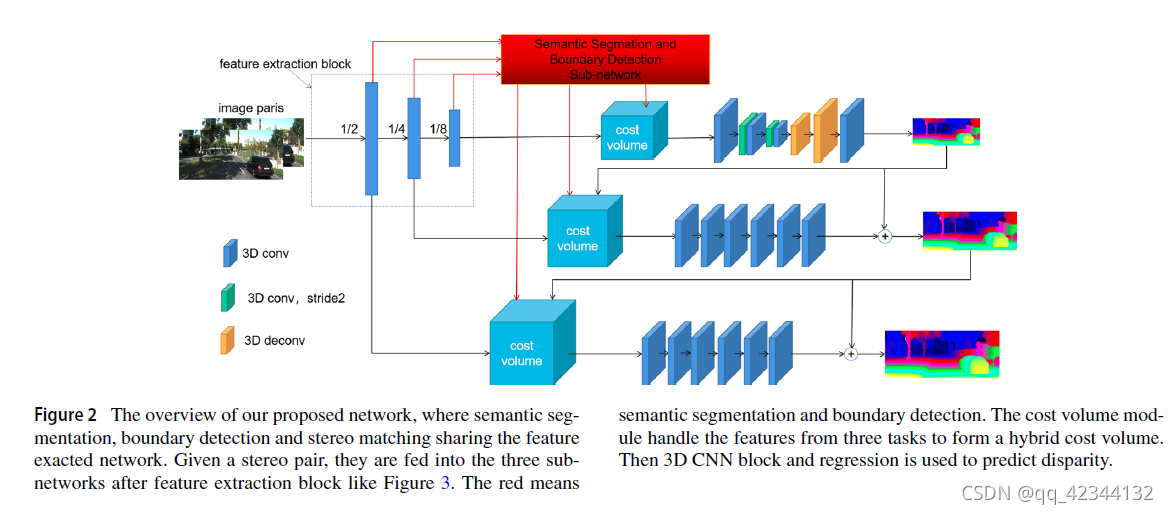
4.1 Basic Network Architecture
包括語意分割、邊界檢測和立體匹配三個分支, 以上三個分支共享特征提取模塊,減少了計算引數,從而提高了計算速度,
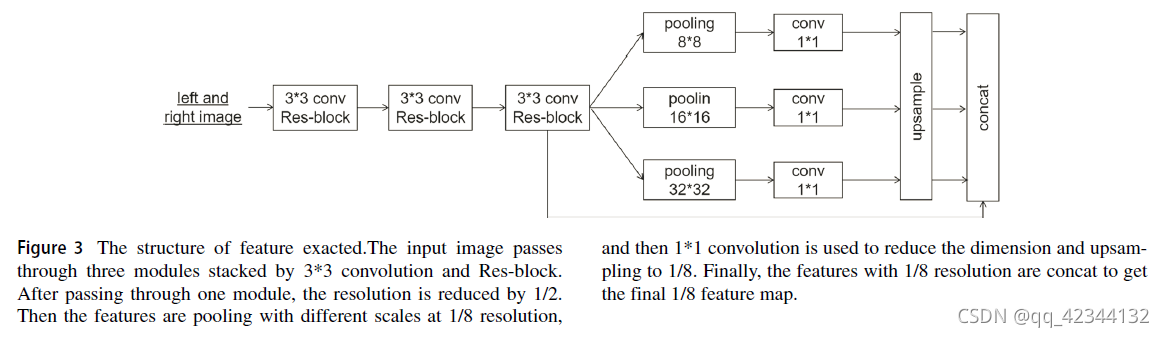
首先,立體影像對流入特征提取塊,如圖3所示,主要由二維卷積層和空間金字塔池化模塊組成,同時,共享左右影像的特征提取塊引數,
然后,將特征Fil 和Fir 饋入三個子網路, 語意特征Fisl 和Fisr 在語意分割子網中計算,邊界特征Fibl 和Fibr 在邊界檢測子網中計算,
然后將語意特征、邊界特征和空間特征輸入立體匹配神經網路, 立體匹配神經網路的結構基于從粗到細的準則,分為三個階段,在每個階段,混合成本量由三個成本量構成,分別由空間特征Fil 和Fir 、語意特征Fisl 和Fisr 以及邊界特征Fibl 和Fibr 組成,
最后利用3D CNN塊學習代價量,利用視差回歸層生成視差圖d或殘差圖, 值得注意的是,在最高解析度(eg.1/8)階段計算完整的視差圖,在較低解析度(例如1/4和1/2)階段逐漸細化視差,這樣可以減少記憶體 消耗并提高整個神經網路的速度,
4.2 StereoMatching Neural Network
部署由粗到細的殘差學習機制,有利于整體訓練并保持低計算時間,特征提取塊、語意分割子網和邊界檢測子網用于提取不同解析度的空間、語意和邊界特征,然后將相同解析度的特征輸入混合匹配模塊,得到混合成本量,
立體匹配神經網路主要由三個階段組成,
第一階段,建立完整的視差圖(解析度大小為1/8),匹配的搜索范圍是24,是1/4解析度范圍的一半, 然后在第二階段建立視差殘差圖, 第二階段的視差圖是將第一階段的視差圖與第二階段的視差殘差圖相加得到的(解析度大小為1/4), 第三階段進一步確立為第二階段,最后,第三階段的視差圖進行上采樣操作以獲得最終的預測視差,
![]()
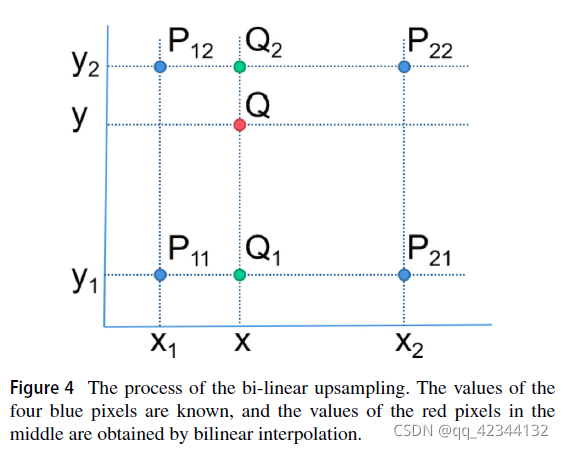
di代表1/2i解析度下的視差圖,ri代表視差殘差圖,u代表雙線性上采樣操作,如圖4所示,給定 P11 (x1, y1)、P12 (x1, y2)、P21 (x2, y1) 和 P22 (x2, y2) 的像素值為 f (P11)、f (P12)、f(P21) 和 f (P22),點Q(x,y)的像素值f(Q)計算如下:
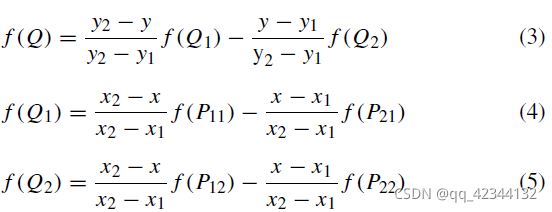
在第一階段,成本量直接由左右特征形成, 在第二和第三階段,成本量由左 Fil 和合成的左特征 ?Fil 形成,將先前解析度(如1/8或1/4)得到的視差影像通過雙線性上采樣操作進行上采樣,然后使用視差值對正確的特征Fir(如1/4或1/2)得到合成的左特征 ^Fil(例如 1/4 或 1/2),該程序定義為Fil (x,y) = Fir(x-u(ds+1),y),
在1/8解析度階段,3D CNN模塊由兩個卷積下采樣塊和兩個反卷積上采樣塊組成,如圖2所示,首先使用步長為2的3D卷積進行下采樣,然后使用步長為2的3D反卷積進行上采樣,然后在兩個塊之間添加跳躍連接以防止卷積中的資訊丟失,并且 Batchnorm3d 和 Relu 之后是卷積和反卷積層以對資料進行歸一化, 在 1/4 和 1/2 解析度階段,3D CNN 模塊用于學習大小為 D×H×W×C(D 為 5,H,W,C 為長度、高度和通道數)的成本量 相應的解析度特征),
而大多數3D卷積立體匹配演算法的成本vome是D×H×W×C,其中D為48或96,因此減少了所提出的立體匹配演算法的計算量, 由于視差通道 D 的值相對較小,因此 3D CNN 模塊由步長為 1 的堆疊 3D 卷積層組成,如圖 2 所示,
當特征圖從 1 / 4 解析度卷積到 1/8 解析度時,會丟失一些資訊,因此,1/4和1/2解析度的殘差圖可以補充1/8 和 1/4 解析度生成的視差圖中忽略的細節,
4.3 HybridMatching Module
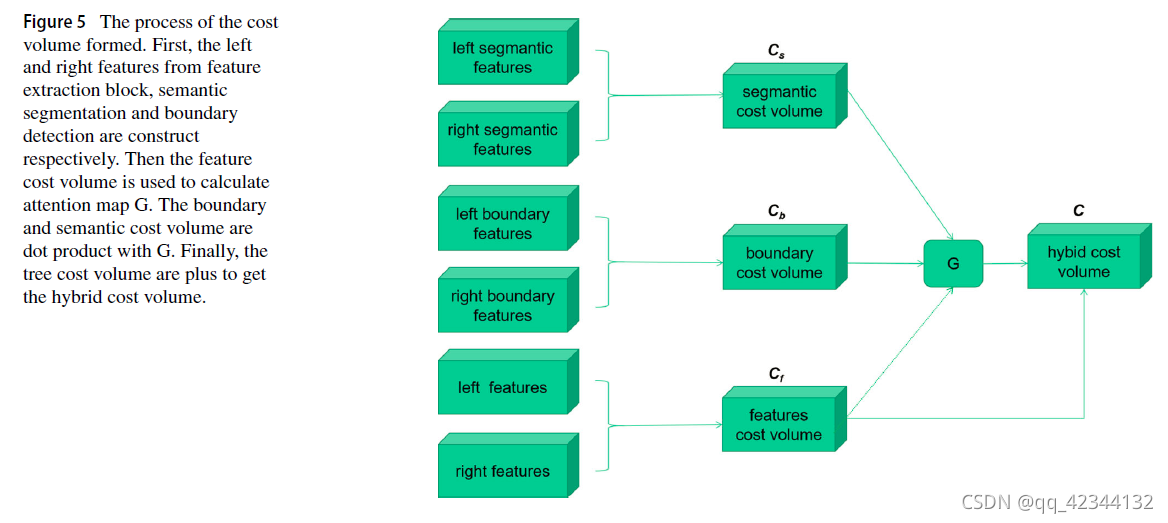
一個由三個代價量組成的混合代價量,用于捕獲語意和邊界資訊,從左右語意分割和邊界特征中學習像素之間的相似性,如圖5所示,特征代價量 Cf 由特征提取塊中提取的左右特征生成,語意代價量 Cs 由左右語意特征在雙線性上采樣和串聯預測前構造而成,邊界代價量 Cb 為 由左右邊界特征形成,構造三個成本量的方法定義為,
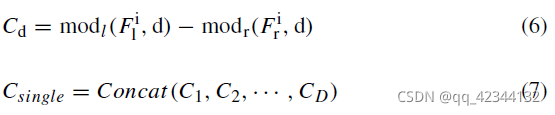
其中 modl 和 modr 代表左右移位函式,Fil 和Fir 是左右特征,其中i∈{1/2 , 1/4 , 1/8 } 是解析度, d ∈ [0,1,···,D] 是視差值,D 在 1/8 解析度下為 24,在 1/4 和 1/2 解析度下為 5, Cd 是視差 d 下的成本量,
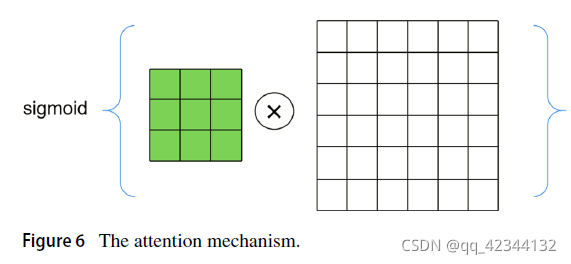
將三個成本體直接串聯在一起形成混合成本體會導致計算量大,包含冗余和重復資訊,因為混合成本體的大小為D×H×W×3C,其中H、W、C 是長度,高度和對應解析度特征的通道數,D是最大視差值,為了平衡三個代價量,引入了注意力機制[59]來引導三個代價量之間的資訊傳遞,選擇性地關注特征資訊,如圖6所示,首先,從成本量 Cf 中生成注意力圖 G 以進行選擇:
![]()
其中 Wf 表示卷積核矩陣,σ 表示用于對注意力圖進行歸一化的 sigmoid 函式, ? 表示卷積, 因此大小為 D×H×W×C 的混合成本體積描述如下:
![]()
其中 是逐元素乘法, Ws 和 Wb 分別代表卷積核矩陣, C是3D CNN模塊最終輸入的成本量,
4.4 Semantic Segmantation and Boundary Detection Sub-network
為了提高速度,快速立體匹配神經網路在一定程度上忽略了影像的細節,導致在無紋理和近邊界區域的精度下降, 為了提高這種準確性,使用語意資訊和邊界資訊來輔助立體匹配神經網路的視差生成, 語意資訊和邊界資訊可以幫助立體匹配演算法更加關注邊界、無紋理和小物體邊界區域的像素,從而提高演算法在這些區域的匹配精度, 語意分割和邊界檢測子網的結構設計相同,
子網路結構基于 FPN 中的金字塔結構,該模型主要由自下而上的下采樣結構和自上而下的上采樣結構兩種路徑組成,兩條路徑通過卷積水平連接,首先,根據圖3中提到的特征提取塊,對輸入影像提取1/2、1/4和1/8解析度的特征,1*1卷積層分別用于進一步降低1/2、1/4和1/8特征的維度,然后對1/8(1/4)特征進行雙線性上采樣,并添加到原來的1/4(1/2)特征上,得到最終的1/4(1/2)特征, 三個解析度的特征通過3*3的卷積層進行卷積,目的是消除混疊效應,即上采樣特征與原始特征重疊造成的特征不連續和失真, 不同解析度的特征后面是雙線性插值操作,將特征解析度上采樣到原始輸入影像的1/2,并使用堆疊算子級聯三個特征, 最后使用1*1卷積層來預測輸出,
4.5 Loss Function
語意感知平滑損失指導背景關系資訊的學習,邊界感知平滑損失指導提取與邊界相關的空間資訊,這也對估計連續視差圖施加了有益的物件級約束,此外,我們使用引數 λ1、λ2 和 λ3 來控制三個任務之間的權重, 邊界圖的ground truth是二元表示,因此使用標準的二元交叉熵損失來衡量邊界圖的預測與ground truth標簽之間的差異,語意分割損失函式是標準的交叉熵損失,作為語意分割演算法的大部分, 在 KITTI 和 Cityscapes 資料庫中,只有左邊的影像有語意標簽和邊界標簽, 然而語意分割和邊界檢測都需要預測輸入的左右影像的輸出, 因此,右側的輸出與左側的預測視差值發生扭曲, 左輸出和右輸出都可以由左地面實況監督,對于立體匹配任務,視差回歸用于為每個解析度生成視差圖,
lossdisp 定義為:
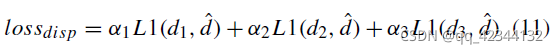
超引數 α1、α2 和 α3 用于平衡三種解析度的輸出, d1、d3、d3分別代表1/8、1/4、1/2解析度的預測視差值,平滑的 L1 損失函式在很多回歸任務中被廣泛使用,可以避免梯度爆炸,更加魯棒, 損失函式定義為:
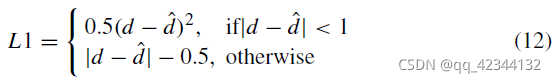
其中 ?d 指的是視差的真實情況,d 是預測圖,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/317701.html
標籤:其他
上一篇:OpenCV 3 創建一個自定義視窗并顯示讀入的影像
下一篇:17-直方圖