2021華為杯數學建模B題思路 2021華為杯B題思路 空氣質量預報二次建模 2021華為杯數學建模B題思路 2021華為杯B題思路 空氣質量預報二次建模 2021華為杯數學建模B題思路 2021華為杯B題思路 空氣質量預報二次建模 2021華為杯數學建模B題思路 2021華為杯B題思路 空氣質量預報二次建模 2021華為杯數學建模B題思路 2021華為杯B題思路 空氣質量預報二次建模 2021華為杯數學建模B題思路 2021華為杯B題思路 空氣質量預報二次建模 2021華為杯數學建模B題思路 2021華為杯B題思路 空氣質量預報二次建模 2021華為杯數學建模B題思路 2021華為杯B題思路 空氣質量預報二次建模 2021華為杯數學建模B題思路 2021華為杯B題思路 空氣質量預報二次建模 2021華為杯數學建模B題思路 2021華為杯B題思路 空氣質量預報二次建模
允許售賣,鼓勵改進后再售賣,歡迎各位同行私信交流,有公眾號或博客的,加群給管理
鏈接:https://pan.baidu.com/s/15SzJ-HIQiSDmME9J8Zln9g
提取碼:6epk
第一問,按照附錄的實體計算AQI,第一問要用到的是附件1中“監測點A逐日污染物濃度實測資料”,BPHi、BPLo、IAQIHi、IAQILo這四個引數不用糾結,直接用案例中的就行,這是一Hi和Lo兩個元素的引數值做參考計算的,而Cp才是變數,指的是p物質的濃度值,計算的時候注意單位,Cp應當化為μg/m3進行計算,AQI最終的值取所有污染物的AQImax,首要污染物也就是AQImax最大的p物質
做第二問前,先檢查下資料,附件1中小表2和小表3,小表3是取小表2同日檢測值的均值,小表1中的資料也有些可用資料,很多人都說例外值直接刪了,其實不是,實際操作上應當是能補的資料盡量補,補不了的在選用資料做研究的時候直接從最后一個不能補的時間位置開始取數,前面的都不用納入研究,不知道大家有沒有發現,小表2中的風速和風向沒有可靠資料進行補充,發現最后一個缺失資料在2020-11-21時間點上,那么在這之前的資料都可以不用納入研究,僅取這個時間點之后的資料用于分析
![]()
先說說指標的例外值,濃度一般為正,對于例外的資料,可以取有效資料通過推薦系統系列方法去重新填寫,例如協同過濾推薦演算法
接下來說如何對缺失值進行處理,下面只是舉例,小表2中這里有部分缺失值
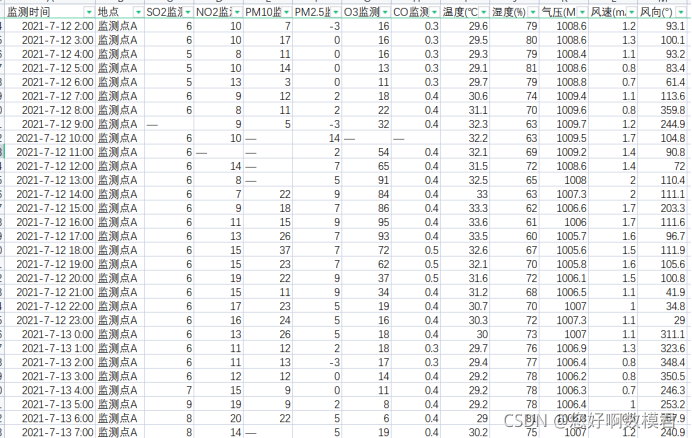
對于濃度資料,補充方式首選用小表3中的資料進行補充,補充方法:對小表2中缺失值用matlab中的fillmissing函式填充,函式得出的補充值還需進一步調整,如果補充后的當天24個資料的平均值與小表3中對應的資料相差小,那么就可以不再做處理,如果相差較大,那么就按等比例變動,使得當天24個資料盡可能的靠近小表3中的資料,對于小表2中缺失的氣象資料同樣的處理方式,對于小表2中溫度、適度、氣壓可以用小表1中地表溫度、濕度、大氣壓來補充(注意單位,這里取小表1中的資料,一個模型運行日期有三組預報資料,取第一組資料)
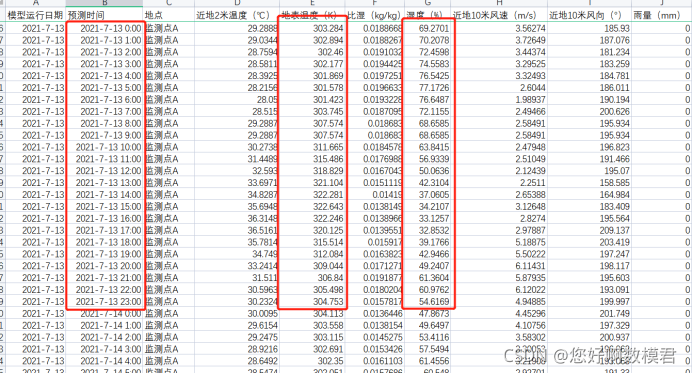
這道題還需要注意的就是單位,濃度有的是毫克有的是微克,做完題也一定再檢查下
第三問,基本上第二問說了大部分的思想,以附件1中監測點A為例,我們先來看可以用到哪些指標,再來說降維,“監測點A逐小時污染物濃度與氣象一次預報資料”這個表,第二列插入一列(看本段后示例圖),第一種構建資料集的做法:針對每個運行日期,例如以2020-7-23為例,復制三組當天的周期時間;第二種: 以三天為間隔周期設定時間,接下來按B列的時間將“監測點A逐小時污染物濃度與氣象實測資料”中的資料對應過來,接下來將原本所屬“監測點A逐小時污染物濃度與氣象一次預報資料”中的指標和“監測點A逐小時污染物濃度與氣象實測資料”的氣象指標作為輸入,“監測點A逐小時污染物濃度與氣象實測資料”中的污染物濃度作為輸出,第二個表的資料匹配過來后,第一個表中未匹配到的就不用考慮了,接下來的做法是將SO2監測濃度、NO2監測濃度、PM10監測濃度、PM2.5監測濃度、O3監測濃度、CO監測濃度視為六個模型,然后可以用一些相關性的方法(灰色關聯、皮爾遜、秩相關、肯德爾、余弦、典型相關分析、Elasticsearch相關性...)分別找出相關性Top前k個指標構建指標體系,然后可通過兩種方式構建預測模型,第一種預測模型可以是神經網路(深度學習)、決策樹系列(Xgboost)、其他機器學習演算法等拿不到關系式的演算法模型,也可以是回歸系列能求出關系式的模型,第一種做法不用多說,演算法內置函式本身就是非線性,最后繪制一些誤差、性能檢驗圖即可,第二種回歸的非線性做法簡單講下,雖然我們看回歸演算法都是線性擬合的,但是可以添加非線性變數,例如x=[X(:,1:15),X(:,1:15).^2,X(:,1:15).^3,X(:,1:15).^4,X(:,1:15).^5,exp(X(:,1:15))];構建一個非線性自變數集,然后直接帶入演算法求引數,由此可以得出2021-7-13 8:00到2021-7-15 23:00各污染物濃度資料,“監測點A逐日污染物濃度實測資料”表中的資料其實是當天0:00到23:00資料的平均值,只不過四舍五入了下,得到每天的各污染物濃度后,按第一問計算方式計算得到AQI,最后按污染物濃度及AQI預測結果表樣例整理出結果放論文中,
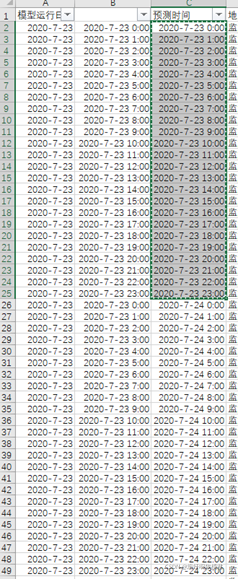 或
或 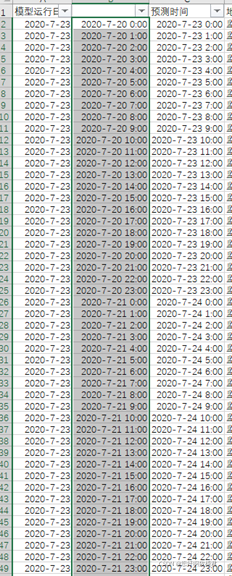
第四問,如果說單獨對A、A1、A2、A3分析,方法同第三問,但是本問要考慮隔壁監測點的環境,相當于本問的資料集中可選的指標不僅有自家的,還有隔壁老王的,其實也同樣可以按第三問做法來做,唯一的區別就是第三問中構建6種污染物濃度指標體系的時候合并其他三個檢測點的資料集,同樣用相關性方法選取,第四問可能就是4*6個指標體系了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/317796.html
標籤:AI