三、Spark MLlib應用
3.1、Spark ML線性模型
-
資料準備
基于Spark ML的線性模型需要DataFrame型別的模型資料,DataFrame需要包含:一列標簽列,一列由多個特征合并得到的特征列 -
訓練模型

-
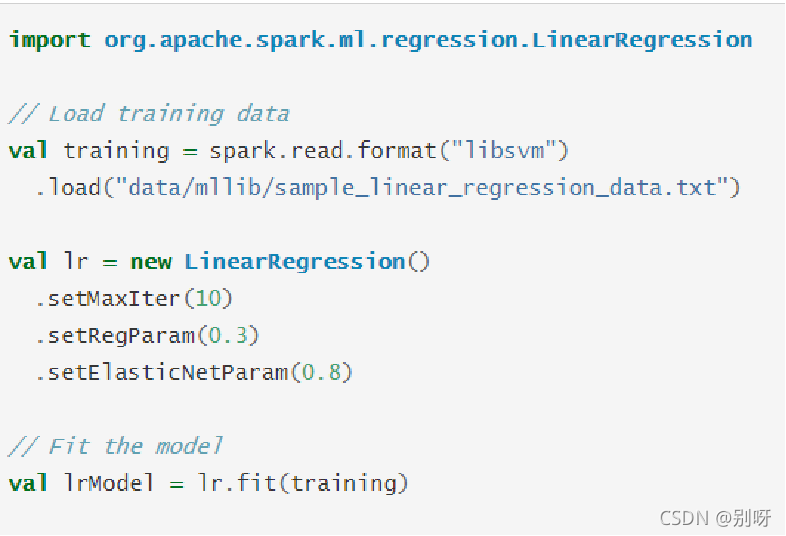
模型應用
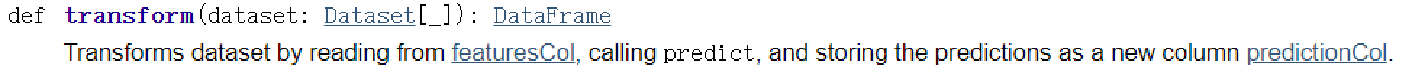
-
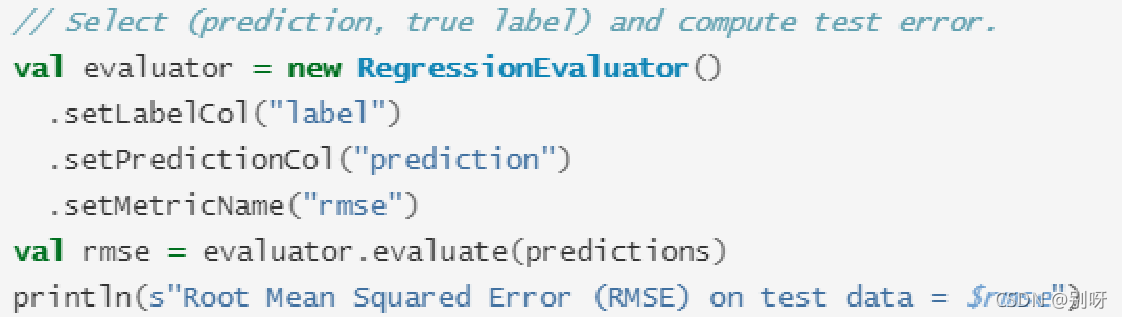
模型評估
任務1:
某專門面向年輕人制作肖像的公司計劃在國內再開設幾家分店,收集了目前已開設的分店的銷售資料(Y,萬元)及分店所在城市的16歲以下人數(X1,萬人)、人均可支配收入(X2,元)
要求:構建線性回歸模型,分析銷售資料與16歲以下人數(X1,萬人)、人均可支配收入(X2,元)的關系
資料 regressiondata.txt:

上傳到hdfs:

處理線性回歸模型資料:
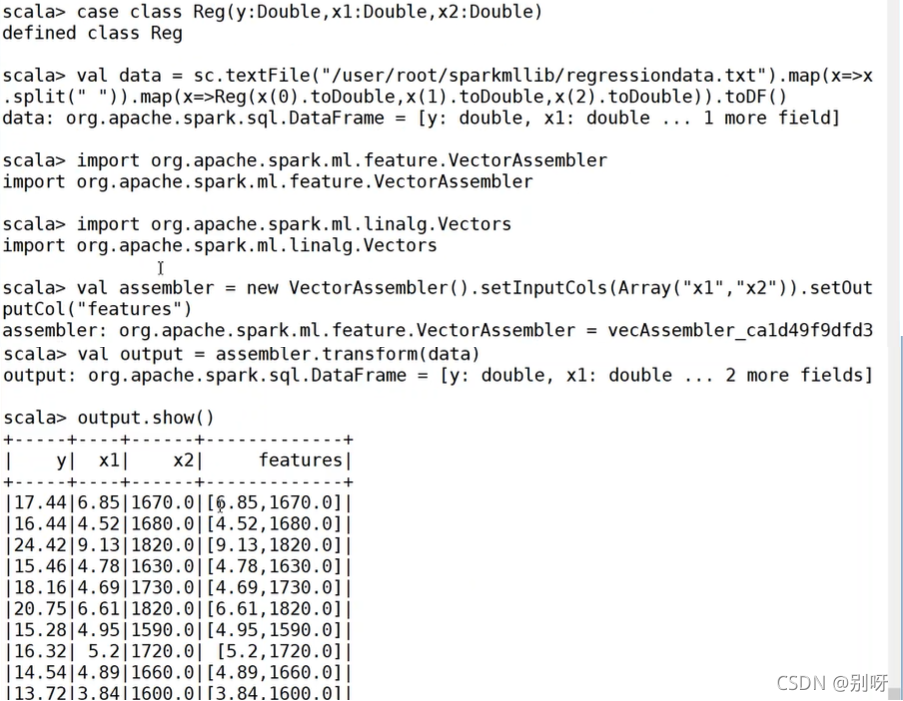
構建線性回歸模型:

預測:
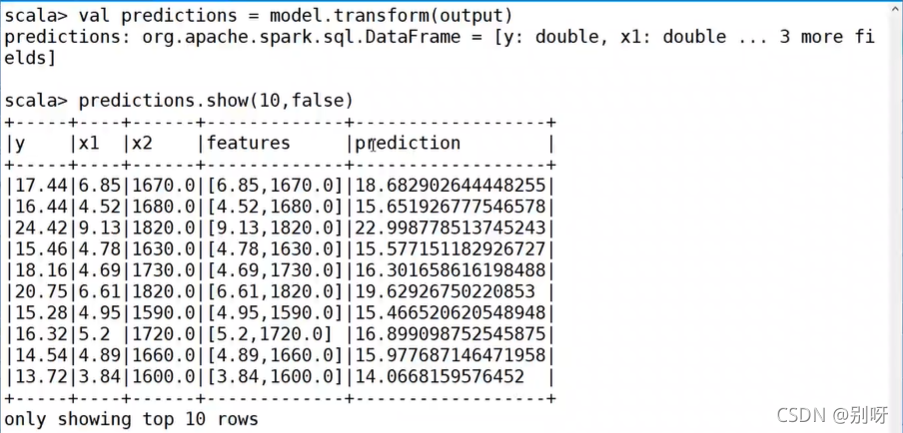
均方誤差:

3.2、協同過濾簡介
- 協同過濾推薦(Collaborative Filtering recommendation)是一項在資訊過濾和資訊系統中很受歡迎的技術,與傳統的基于內容過濾直接分析內容進行推薦不同,協同過濾分析用戶興趣,在用戶群中找到指定用戶的相似(興趣)用戶,綜合這些相似用戶對某一資訊的評價,形成系統對該指定用戶對此資訊的喜好程度預測,
- 協同過濾一般分為基于用戶的協同過濾和基于物品的協同過濾,基于用戶的協同過濾是依據用戶之間的相似性,將相似性高的用戶對于某種物品的喜好進行計算,從而推測指定用戶對于該物品的喜好
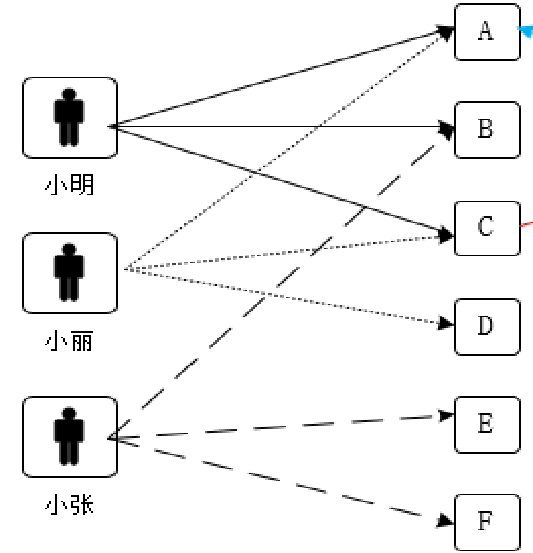
3.2.1、基于用戶的協同過濾
小明和小麗都喜歡A、C,說明小明小麗興趣比較相似,可把小明喜歡的B推薦給小麗,小麗喜歡的D推薦給小明
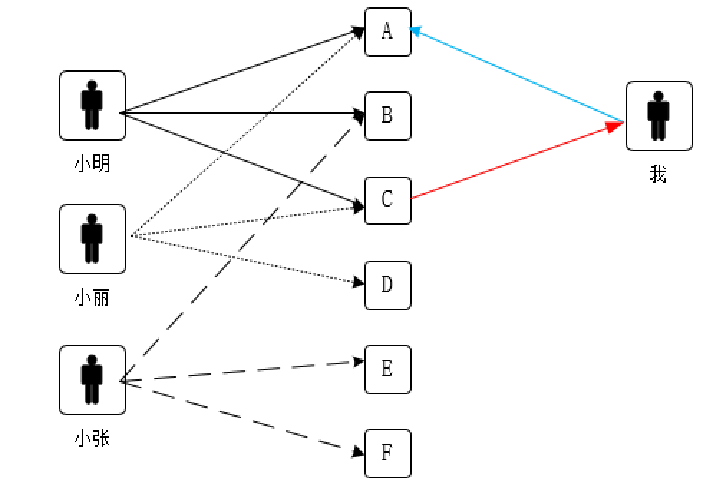
3.2.2、基于物品的協同過濾
小明喜歡A、B和C,小麗喜歡A、C和D,小張喜歡B、E和F,觀察三人擁有的物品,可以知道擁有A的也擁有C,可知A、C的關聯程度很高,即A、C相似度很高,如果此時指定用戶已經擁有A,顯然應該把C推薦給該用戶最合適,
3.2.3、基于ALS的協同過濾
從協同過濾的分類來說,ALS演算法屬于User-Item CF,也叫做混合CF,它同時考慮了User和Item兩個方面,
ALS是交替最小二乘的簡稱,在機器學習中,ALS特指使用交替最小二乘求解的一個協同過濾演算法,它通過觀察到的所有用戶給產品的打分,來推斷每個用戶的喜好并向用戶推薦適合的產品,
ALS演算法不像基于用戶或者基于物品的協同過濾演算法一樣,通過計算相似度來進行評分預測和推薦,而是通過矩陣分解的方法來進行預測用戶對物品的評分,
3.3、Spark ML ALS
官網:http://spark.apache.org/docs/latest/ml-features.html#vectorindexer
- 資料準備
需要3個列,用戶列、物品列、評分列 - 模型構建

- 模型應用
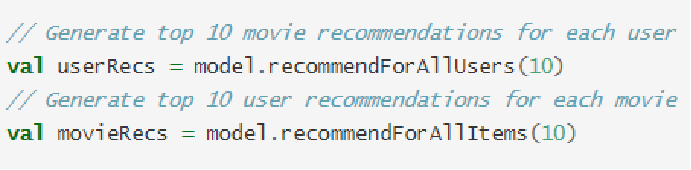
- 模型評估


任務2:
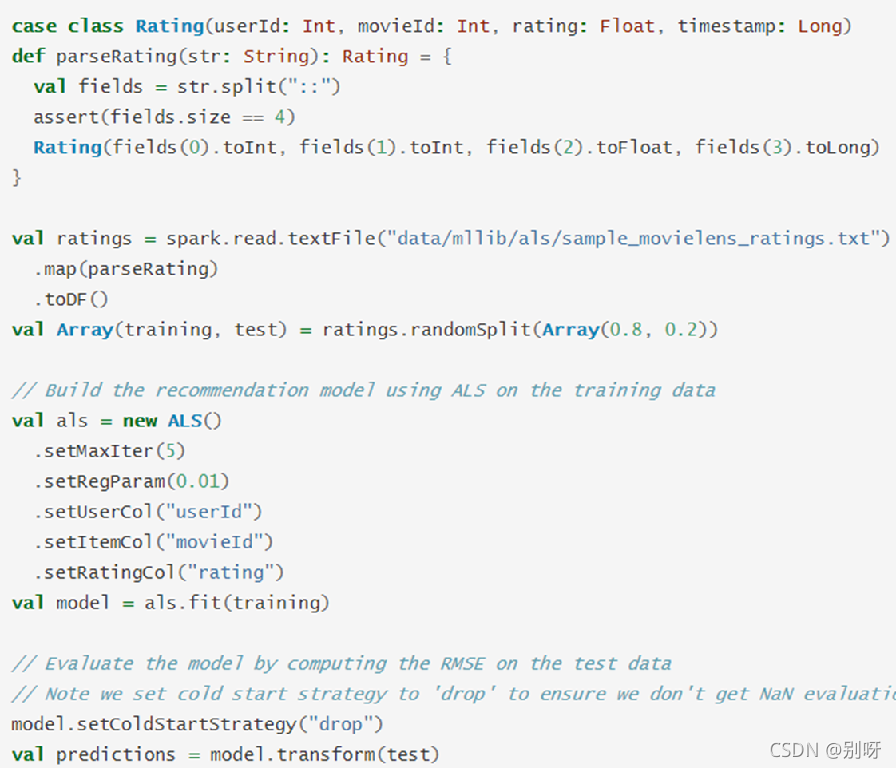
現有一份資料,記錄了用戶對電影的評分,如下所示,包括用戶id、電影id、評分,
要求:根據用戶的電影評分記錄,通過協同過濾演算法計算用戶之間的相似度,為用戶進行電影推薦,
資料 sample_movielens_data.txt:
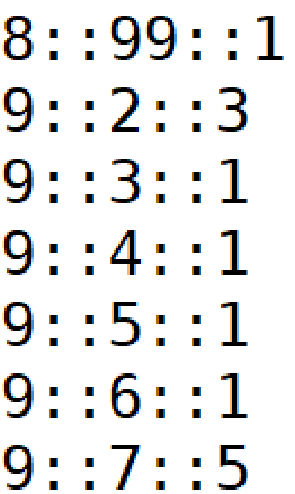
上傳到hdfs:

構建ALS演算法進行電影推薦:
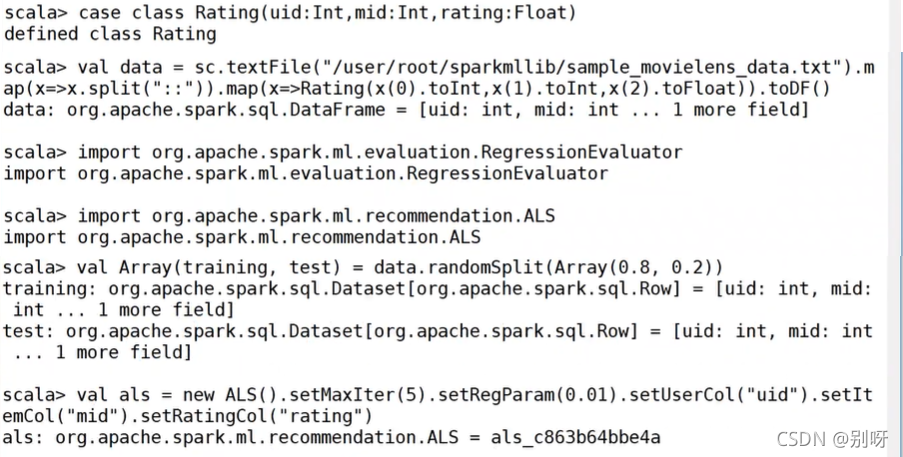
預測:

均方誤差:

給參與用戶推薦:
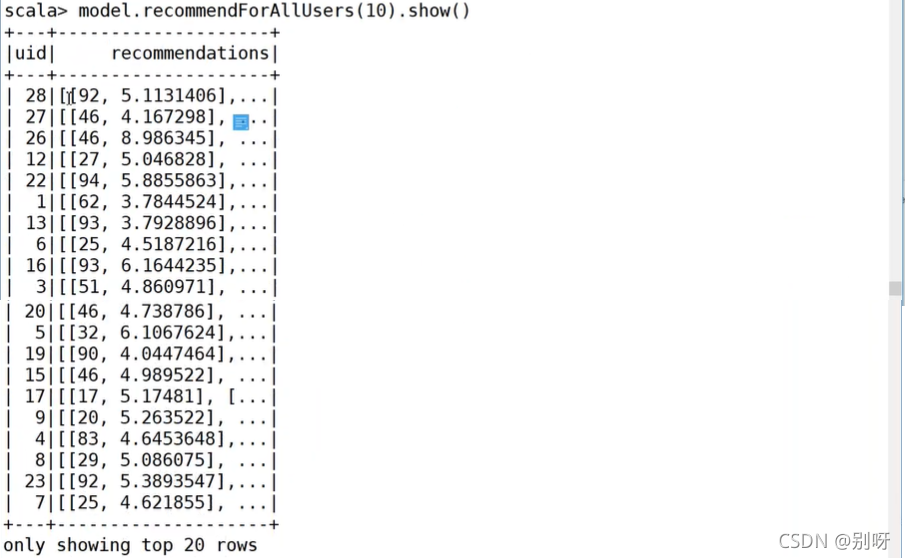
給參與模型構建的商品推薦相似商品:
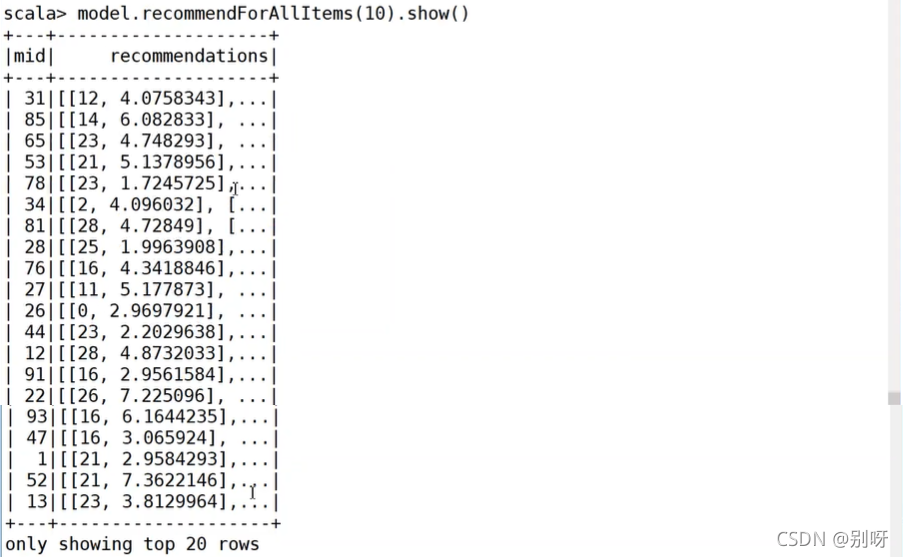
3.4、在IDEA實作ALS
在IDEA創建Spark工程見我博客:學習筆記Spark(五)—— 配置Spark IDEA開發環境
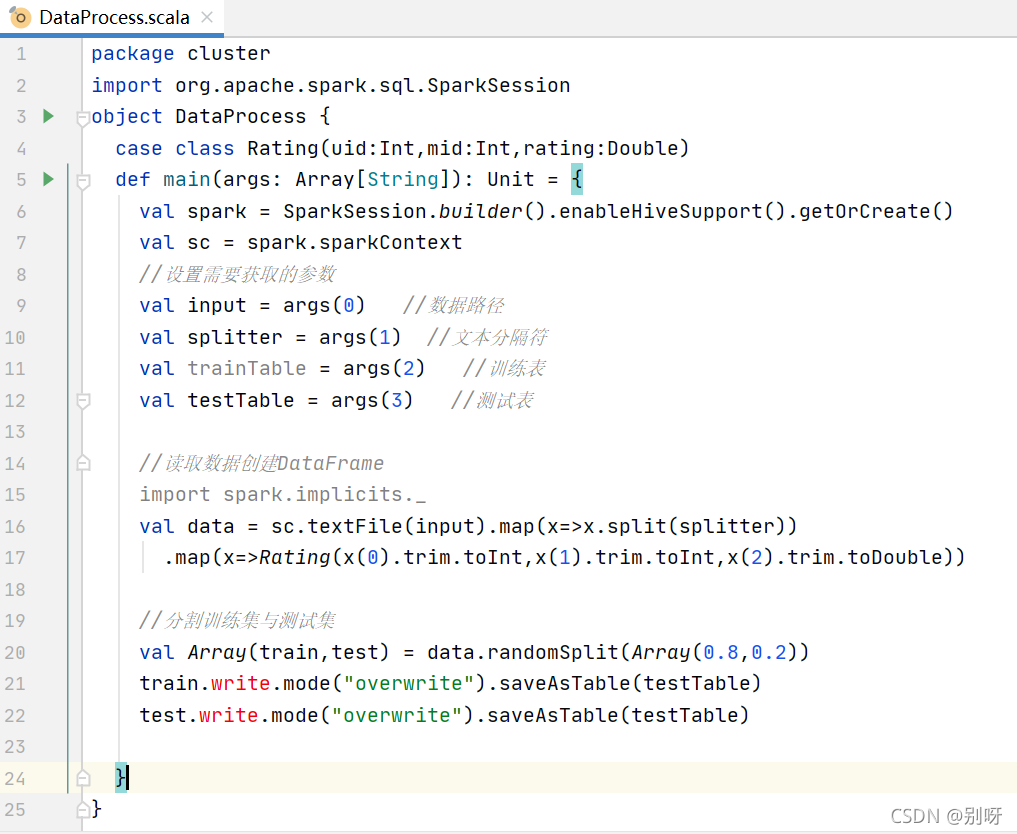
3.4.1、實作ALS資料處理程序
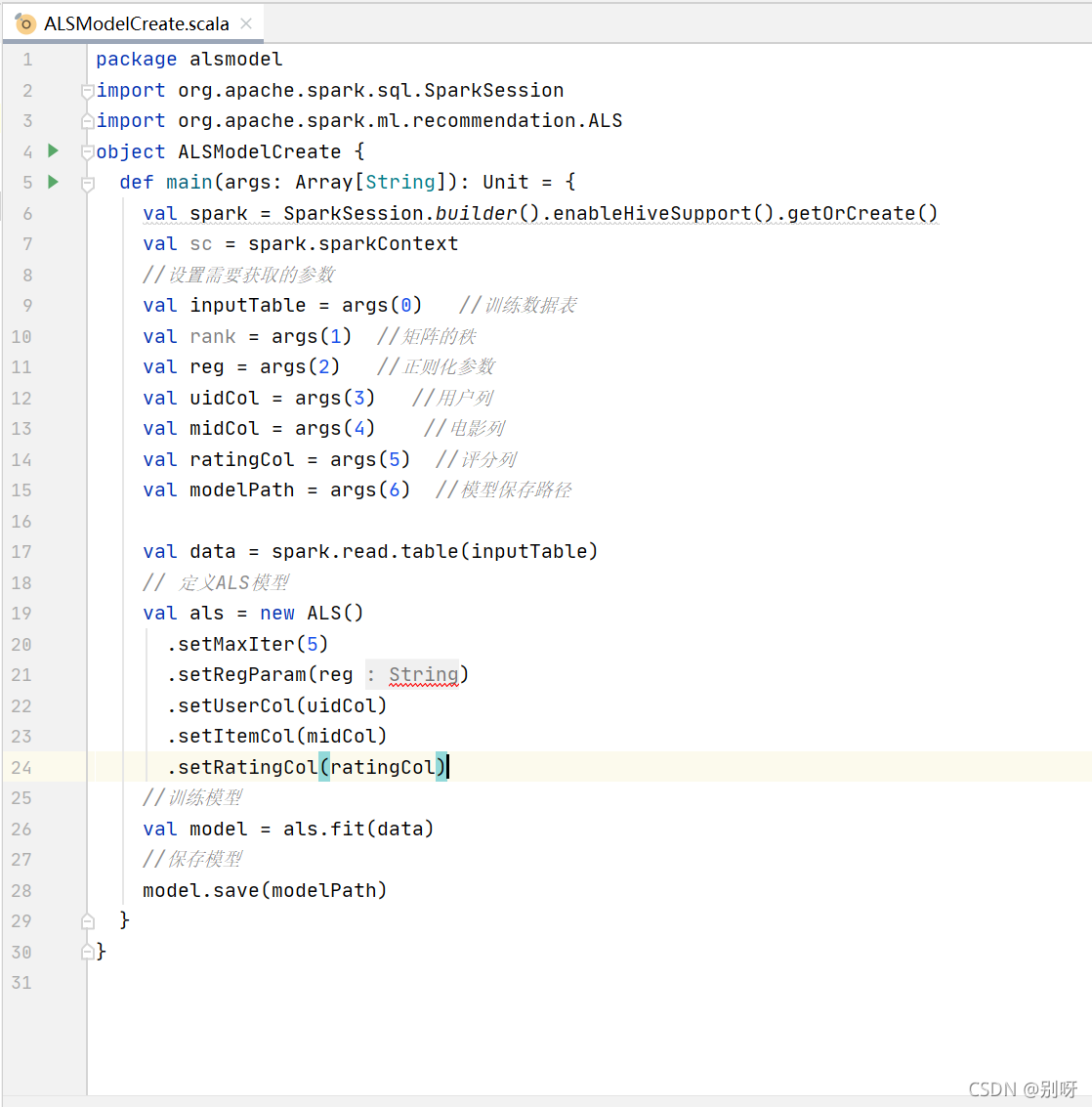
3.4.2、實作ALS模型構建程序
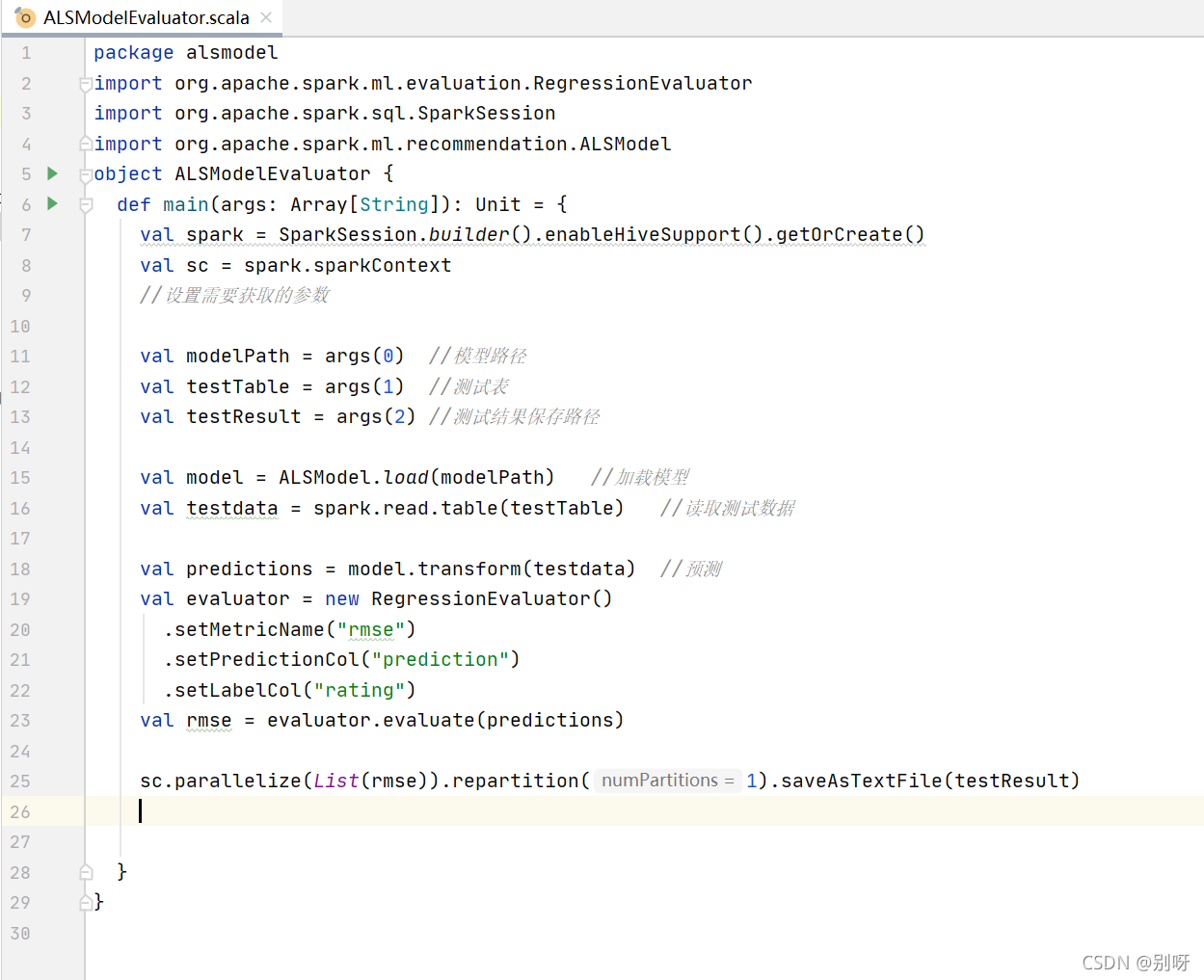
3.4.3、實作ALS預測與評估程序
3.4.4、實作ALS模型推薦程序
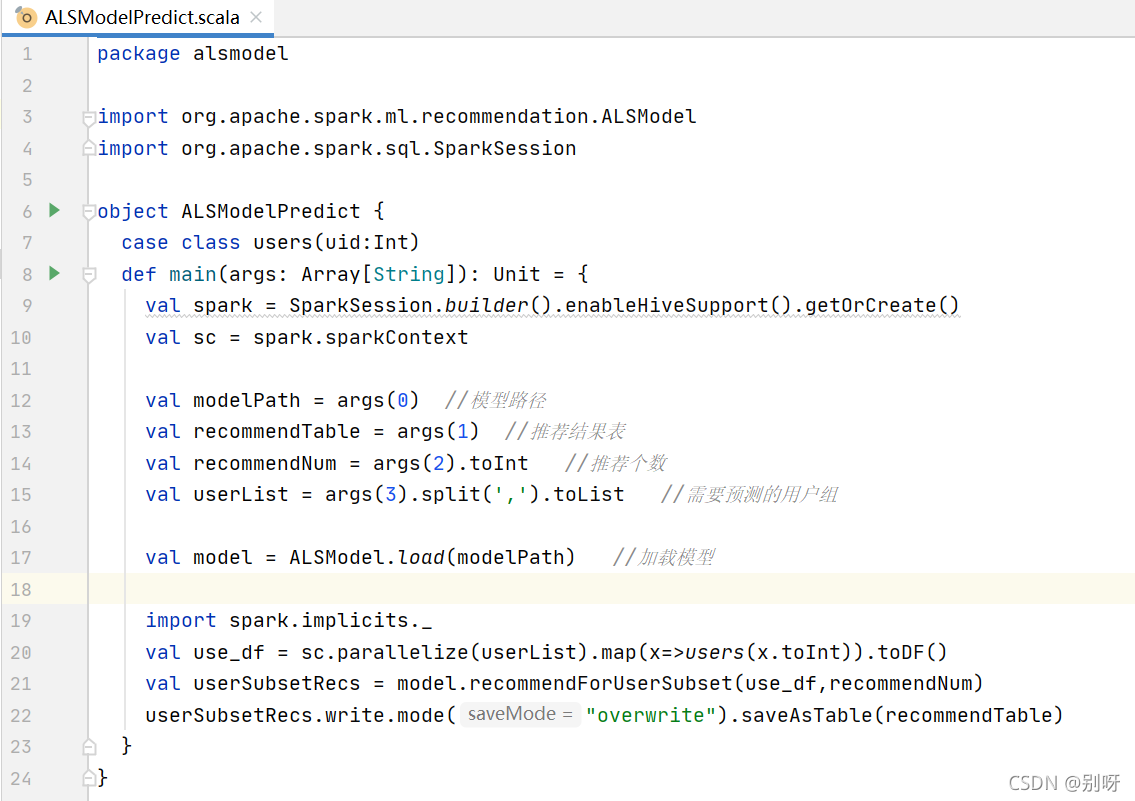
3.4.5、提交ALS電影推薦模型到集群
① 將程式打包成jar包,并上傳到linux的/opt目錄下

② spark-submit提交到集群



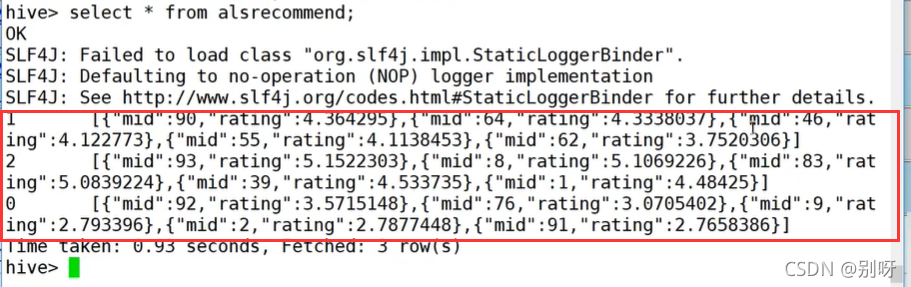
推薦結果記錄:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/317836.html
標籤:其他