隨著數字化轉型的發展,大資料人工智能計算日臻完善,資料與分析將成為企業戰略的核心,企業必須高度重視并大力投入,
1. 概述
1.1. Pandas高級資料分析知識體系
基于Pandas高級資料分析,知識技能包括:資料的讀寫、表內操作、表間操作(例如關系型資料庫表關聯,Excel sheet關聯等)、統計功能、分析計算(基于大資料機器學習高級分析計算)、可視化圖表等,
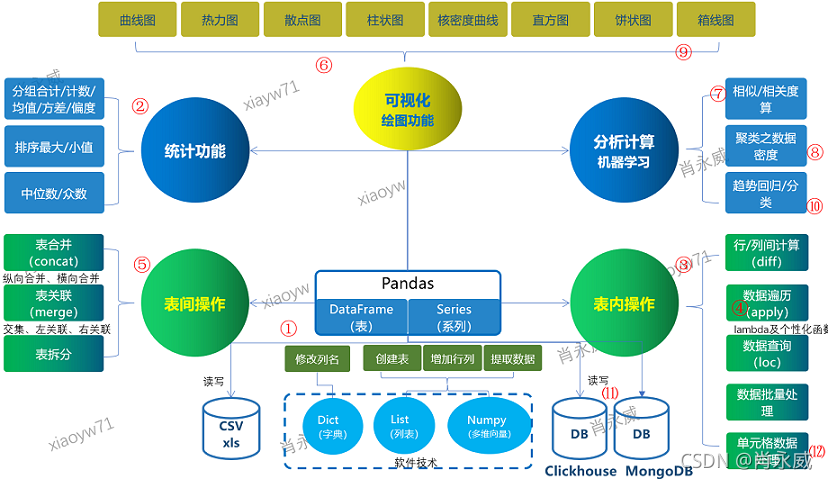
其中,資料層面使用常用的CSV資料檔案,以及Clickhouse資料倉庫和檔案型資料庫Mongo DB,
1.2. 高級資料分析程序
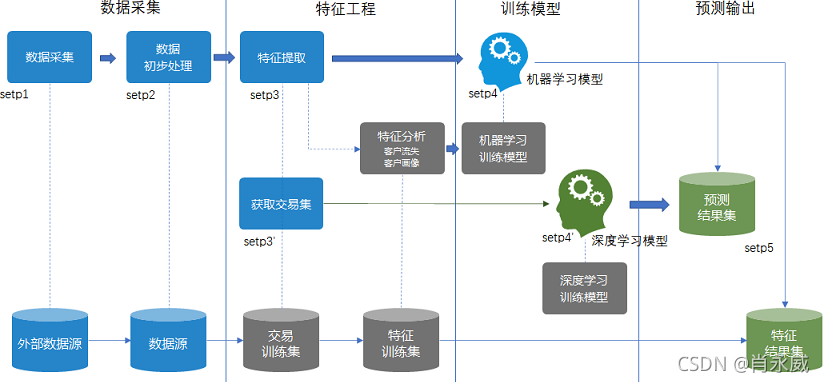
資料分析程序較為復雜,涉及到資料采集、資料治理、建立資料倉庫、特征工程、建立演算法模型、模型訓練等作業,本文以資料分析師的視角,只學習掌握資料采集、特征工程、建立演算法模型、模型訓練等知識技術內容,
1.3. 快速入門環境
1.3.1. 軟體開發環境
軟體開發環境為windows 10(也可以使用Centos 7),python為3.6.X,開發工具為Jupyter Notebook,建議計算機記憶體大于16G,互聯網網路順暢,
1.3.2. 業務場景
(1). pandas基本操作使用田徑運動員簡單資料演練
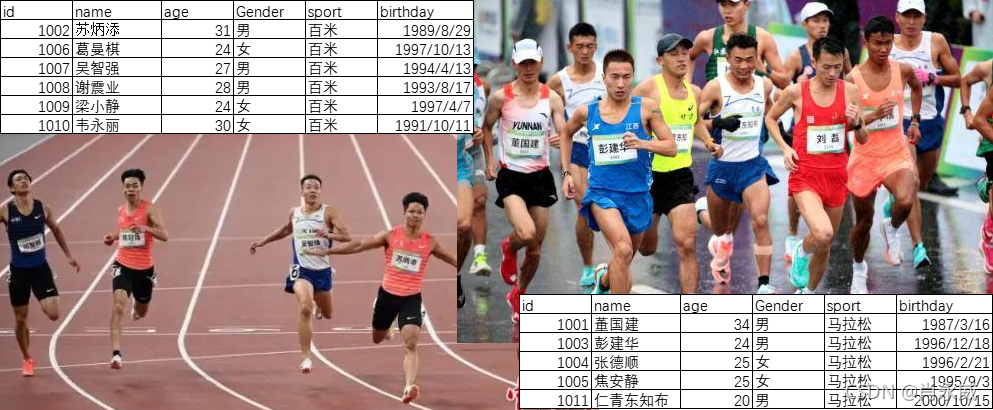
(2). 資料高級分析,使用少量、截取、脫密的客戶加油交易資料
2. 快速入門基礎
2.1. Pandas高級資料分析快速入門之一——Python開發環境篇
內容概述:
- Python是什么?
- 安裝Python
- Python開發環境安裝與配置
2.1. 安裝jupyter
2.2. 開發環境漢化
2.3. jupyter工具使用 - 高級資料分析工具安裝
3.1. Python工具包
3.2. Python依賴
2.2. Pandas高級資料分析快速入門之二——基礎篇
內容概述:
- Pandas構成
0.1. 第一個DataFrame
0.2. Pandas資料型別
0.3. Pandas資料型別轉換
0.4. 用到的Python基礎
0.4.1. 序列(List)
0.4.2. 字典 - 從讀取通用資料檔案開始
1.1. 讀XLS資料檔案
1.2. 讀CSV資料檔案 - 對表(DataFrame)增減資料
2.1. 增減行資料
2.1.1. 增加行
2.1.2. 洗掉行
2.2. 增減列資料
2.2.1. 增加列資料
2.2.2. 洗掉列資料 - 把資料保存到CSV檔案
- DataFrame單元格操作
4.1. 讀取單元格資料
4.2. 修改單元格資料 - 讀取Clickhouse資料
2.3. Pandas高級資料分析快速入門之三——資料挖掘與統計分析篇
內容概述:
- 前言
- 原資料挖掘——交易明細
1.1. 讀取原資料
1.2. 時序資料挖掘
1.3. 資料計算
1.4. 挖掘資料周期維度
1.5. 表關聯(merge)
1.6. 小結 - 常用特征提取——極限值與統計值
2.1. 最后一次交易關鍵特征
2.2. 關鍵極值特征
2.3. 累計/均值/計數等通常特征
2.4. 方差/標準差等波動特征
2.5. 其他 - 按周期統計分析資料
3.1. 月周期
3.2. 月特征提前——極限值與統計值
2.4. Pandas高級資料分析快速入門之四——資料可視化篇
內容概述:
- 關于Matlibplot
- Pandas繪圖
2.1. 畫直方圖
2.2. 畫密度圖曲線圖
2.3. 畫折線圖
2.4. 畫柱狀圖
2.5. 畫餅狀圖
2.6. 畫條形圖 - 復雜圖形
3.1. 熱力圖(皮爾遜相關)
3.2. 雷達圖
2.5. Pandas高級資料分析快速入門之五——機器學習特征工程篇
內容概述:
- Pandas高級資料分析使用機器學習概述
- 線性回歸計算斜率和方差
- 資料密度計算正常狀態/周期
- 相關分析計算特征間關系
- 歸一化、標準化
- 聚類——KMean
- 小結
2.6. Pandas高級資料分析快速入門之六——機器學習預測分析篇
內容概述:
- 訓練集、測驗集
- XGBoost分類模型訓練
1.1. 輸入資料集
1.2. 超引數設定
學習任務引數objective
驗證資料的評估指標eval_metric [根據目標默認]
Tree Booster引數
1.3. 模型訓練
1.4. 模型持久化 - 預測結果分析
2.1. 重要特征
2.2. 模型評估 - XGBoost分類持久化模型應用
附錄:引數
學習任務引數objective
驗證資料的評估指標eval_metric [根據目標默認]
3. 延申閱讀,常用實用操作與技巧
3.1. Pandas高級資料分析快速入門之資料篩選——分組排序篩選實踐筆記
內容概述:
- 排序
- 分組篩選
2.1. 分組后,篩選每組最后一條記錄
2.2. 分組后,篩選每組倒數第二條記錄
2.3. 分組后,篩選每組首條記錄
2.4. 分組后,篩選每組前兩條記錄(top2)
2.5. 按條件篩選分組
2.6. 分組后,按組篩選
2.7. 分組后,使用Filter篩選
3.2. Pandas高級資料分析快速入門之資料編輯——洗掉行與列
內容概述:
- 洗掉行
1.1. 按行索引洗掉行資料
1.2. 分組洗掉最后一行資料
1.3. 按條件查詢洗掉行資料
1.4. 按多個行索引洗掉多行
1.5. 按行范圍洗掉 - 洗掉列
2.1. 方法一:drop
2.2. 方法二:del - 總結
3.1. drop方法的用法
3.2. 依賴切片操作
3.3. 在CentOS7上部署Python開發工具Jupyter Notebook的遭遇
內容概述:
- 安裝Jupyter Notebook
- 部署Jupyter Notebook作業環境
2.1. 創建組態檔及遇到“缺少libstdc++.so.6庫”問題
2.2. 配置作業環境
2.3. 打開防火墻 - 啟動jupyter notebook服務
3.4. Pandas高級資料分析快速入門之工具使用——Jupyter匯出PDF問題
內容概述:
- 安裝Tex
- 安裝pandoc
- 其他安裝包
3.5. 資料處理技術、技巧集錦(Pandas、Numpy、List)
內容概述:
- pandas表合并
1.1. 兩個表橫向按資料行值相同關聯并集(以左表為基準表)
1.2. 兩個表橫向按資料行值相同交集合并(兩表交集)
1.3. 兩個表縱向合并 - pandas 分組過濾
2.1. 分組及列名處理
2.2. 過濾 - pandas表內資料處理
3.1. pandas按列過濾字串(濾除數字中非數字)
3.2. Pandas字串轉換時間處理
3.3. 資料滾動窗
3.4. 時間特征提取
3.5. 特征編碼與特征增維 - pandas DateFrame表的行、列操作
4.1. 取行和列的幾種常用方式
4.2. 插入列,重新排列
4.3. 資料上移、下移一行
4.4. 洗掉表最后一行、首行
4.5. 修改列名 - Numpy與DataFrame相互轉換
- list與pandas
6.1. 移除(洗掉)某個值
6.2. 字典與Pandas、Mongo操作 - Numpy陣列/矩陣操作
7.1. 二維陣列,按行取資料(陣列截斷)
7.2. 二維陣列,取具體幾列資料
7.3. 二維陣列,橫向合并資料
7.4. 二維陣列,縱向追加行 - Pandas創建表
8.1. 讀取檔案創建表
8.2. 讀取Mongo資料庫資料創建表
8.3. pandas轉Json存盤到Mongo
8.4. Mongo與Pandas資料讀取、存盤實體代碼
4. 相關內容
4.1. Python使用ClickHouse實踐與踩坑記
內容概述:
- 關于ClickHouse使用實踐
1.1. ClickHouse 應用于資料倉庫場景
1.2. 客戶端工具DBeaver
1.3. 大資料應用實踐 - Python使用ClickHouse實踐
2.1. ClickHouse第三方Python驅動clickhouse_driver
2.2. 實踐程式代碼 - 總結
4.2. Python開發中使用Mongo DB入門實踐
4.3. 應用XGboost實作多分類模型實踐
內容概述:
- 輸入資料
- 模型及其引數
- 預測輸出
- 模型的訓練
4.1 資料源及重要特征
4.2. 訓練引數優化 - 模型訓練的應用實踐代碼
- 關于fit()與train()的區別補充
5. 總結
基于特征工程和XGBoost演算法的預測方法,是較為易用、預測效果的資料分析方法,其中,方法的中間程序所產生的特征可用于解釋模型及業務,例如通過特征相關性、相似性、重要程度排序等分析,確定了對業務領域決策貢獻度較高的特征,該研究有助于優化業務領域影響因素分析,為業務人員提供分析依據,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/317841.html
標籤:其他
上一篇:hive資料庫及表操作
下一篇:MySQL資料庫基礎