6.1資料倉庫概念
6.1.1什么是資料倉庫
資料倉庫:資料倉庫是一個面向主題的、集成的、相對穩定的、反映歷史變化的資料集合,用于支持管理決策,
資料倉庫的目的:支持企業內部的商業分析和決策,讓企業可以基于資料倉庫的分析結果作出相關的經營決策,
資料倉庫的典型體系結構:
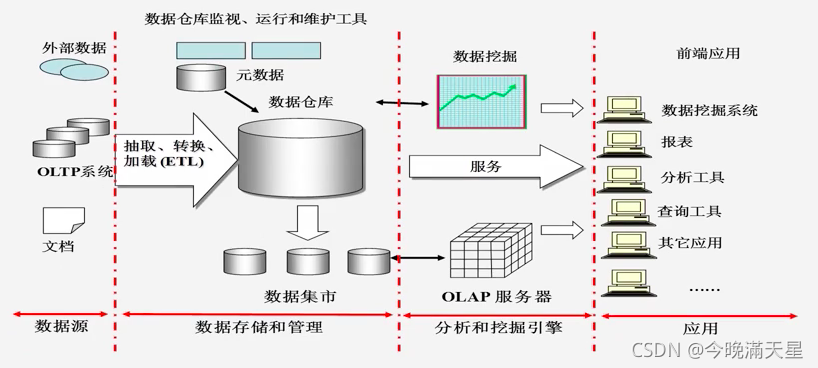
資料倉庫的資料都來自資料源,資料源中的資料需要經過抽取、轉換、加載(ETL程序),再進入資料倉庫,接著可以通過OLAP服務器和資料挖掘引擎,對上層應用提供服務,從而提供各種型別的服務,
資料倉庫是相對穩定的,倉庫中的資料不會頻繁變化甚至根本不會變化,大部分情況下,資料源中的資料經過ETL程序進入資料倉庫后就不會再發生變更,基本保留了歷史上所有時刻的狀態(大量歷史資料可以被用于多維資料OLAP分析,找出企業經營管理規律),但傳統資料庫只能存盤在某個時刻的狀態,原來的歷史資訊不保留,
傳統資料倉庫面臨的挑戰:
1.無法滿足快速增長的海量資料存盤需求,
2.無法有效處理不同型別的資料,
基于傳統資料庫構建,只能存盤結構化資料,
3.計算和處理能力不足,
沒有辦法橫向擴展,縱向擴展的能力也是有限的,
6.2Hive簡介
6.2.1概述
Hive是一個構建于Hadoop頂層的資料倉庫工具,支持大規模資料存盤分析,由于Hadoop是大資料處理架構、分布式處理架構,具有非常好的水平可擴展性,所以構建在其上的Hive也有很好的水平可擴展性,
雖然Hive是資料倉庫工具,但是它和傳統的資料倉庫是有區別的,
傳統的資料倉庫即是資料存盤產品也是資料分析處理產品,能同時支持資料的存盤和處理分析,然而,Hive本身并不支持資料存盤和處理,應該將它看作一個面向用戶的介面,相當于給用戶提供了一種編程語言,讓用戶可以用類似SQL的編程語言去撰寫分析需求,
Hive架構在底層的Hadoop核心組件之上,而Hadoop平臺有支持大規模資料存盤的組件HDFS、支持大規模資料處理的組件MapReduce,Hive正是借助于這兩個組件完成資料的存盤和處理,具體來說,Hive依賴分布式檔案系統HDFS存盤資料、依賴分布式并行計算模型MapReduce處理分析資料,
Hive為用戶提供了一種非常簡單的查詢語言,和SQL非常類似(借鑒SQL語言),即新的查詢語言HiveQL,
用戶可以通過HiveQL這種陳述句,執行具體的MapReduce任務,
并且,Hive支持類似SQL的介面,很容易進行移植,可以很容易的把原來構建在關系資料庫上的資料倉庫應用程式移植到Hadoop平臺上,
因此,Hive是一個可以提供有效合理直觀組織和使用資料的分析工具,
Hive兩個方面的特性
1.采用批處理方式處理海量資料
Hive本身并不負責資料的處理分析,會把用戶提交的HiveQL陳述句轉換成一系列的MapReduce任務執行,而MapReduce是典型的面相批處理的框架,
資料倉庫存盤的是靜態資料,不會發生頻繁變化甚至根本不會變化,所以對靜態資料的分析適合采用批處理方式,不需要快速回應給出結果,資料倉庫的這種靜態特性很適合使用Hive,
2.Hive提供了一系列對資料進行提取、轉換,加載(ETL)的工具
可以存盤、查詢和分析存盤在Hadoop中的大規模資料,這些工具可以很好的滿足資料倉庫的各種應用場景,
6.2.2Hive和Hadoop生態系統中各組件關系
Hive建立在Hadoop平臺之上,依賴HDFS存盤資料,依賴MapReduce處理資料,
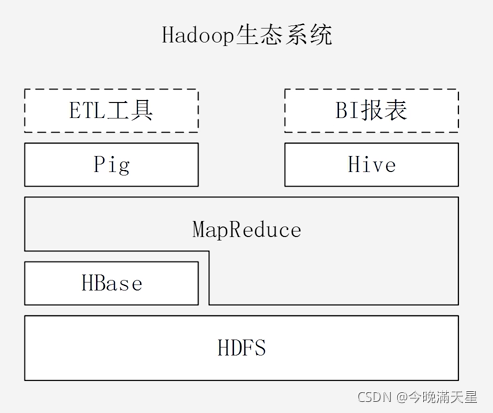
Pig是一種面向流式處理的語言,leisiyuSQL陳述句,可以通過撰寫Pig Latin腳本語言以使用資料倉庫和資料分析的作業,無需撰寫復雜代碼,在某種程度上,Pig和Hive提供的資料倉庫的功能是類似的,也是讓用戶輸入類似SQL的陳述句,也會把陳述句轉換為MapReduce任務運行,但是二者也存在區別,相對于Hive來說,它是一種輕量級分析工具,Pig比較適合做實時性互動分析,不適合做大規模資料批處理,二者在發展程序中應用場景不同,Pig主要用于資料倉庫的ETL環節,而Hive主要用于資料倉庫海量資料的批處理分析,
在Hadoop生態系統中,HBase是一款支持實時性互動的資料庫產品,彌補了HSFS的缺陷(HDFS只允許追加不允許修改,不支持隨機讀寫),這種資料讀寫可以利用HBase實作,HBase和Hive是一種互補的關系,Hive的時延較高,因此如果需要實時性查詢,可以通過HBase實作,
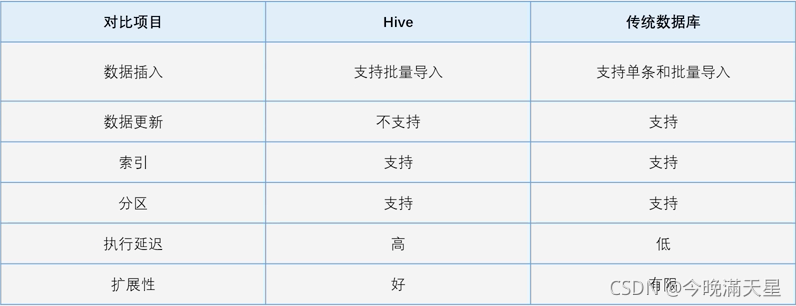
6.2.3Hive和傳統資料庫對比
Hive在很多方面和傳統資料庫類似,但是Hice底層依賴的是Hadoop兩大核心組件(HDFS和MapReduce),因此在很多方面又有別于傳統資料庫,
Hive和傳統資料庫在不同專案中的對比表:
6.2.4Hive在企業中的部署和應用
Hive在企業大資料分析平臺中的應用:
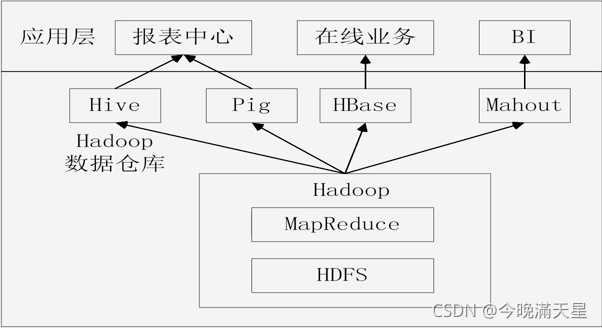
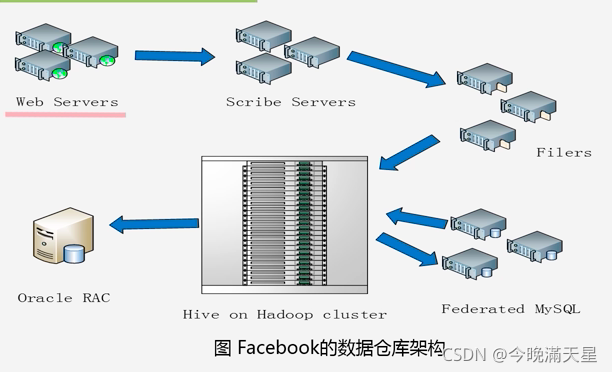
Hive在Facebook公司的應用
Facebook是Hive資料倉庫的開發者,這是由于基于Oracle的資料倉庫已經無法滿足激增的業務需求,所以Facebook公司開發了資料倉庫工具Hive,并在企業內部進行了大量部署,
Web服務器每天會產生大量的日志流,通過訂閱(Scribe)服務器進行收集整理,存盤到網路檔案服務器(Filers),Filers會將海量日志保存在分布式檔案系統HDFS上,同時,Facebook內部的許多關系型資料庫集群,例如MYSQL,用于存盤維度資料;這些資料也要被匯入Hadoop平臺,并存盤到HDFS中,各種資料都進入到HDFS之后,Hive就會為這些資料構建起一個資料倉庫,用戶即可進行各種操作,得到的分析結果可以匯入MYSQL,也可以匯入Oracle RAC,
6.2.5Hive系統架構
在系統架構中,包含三個非常核心的模塊:用戶介面模塊、驅動模塊(Driver)、元資料存盤模塊(Metastore),
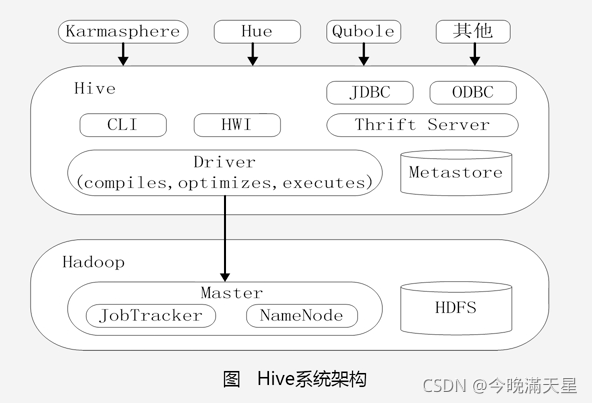
Hive對外訪問介面:
- CLI:一種命令列工具
- HWI:Hive Web Interface,是Hive的Web介面,
- JDBC和ODBC:開放資料庫連接介面,很多應用開發都支持,
- Thrift Server:基于Thrift架構開發的介面,允許外界通過這個介面實作對Hive倉庫的RPC呼叫,
驅動模塊(Driver):
包含編譯器、優化器、執行器,
負責把HiveQL陳述句轉換成一系列MapReduce作業,
元資料存盤模塊(Metastore):
是一個獨立的關系型資料庫,
存盤資料倉庫的各種元資料,比如表、表中的列、列的名稱、磁區資訊,
通過MySQL資料庫存盤Hive元資料,
Karmasphere、Hue、Qubole也可以訪問Hive資料倉庫,
其中,Qubole直接作為一種服務提供給用戶,不需要在本地部署資料倉庫,直接提供亞馬遜的AWS云平臺即可遠程使用資料倉庫,整個資料倉庫集群管理都是亞馬遜完成,
6.2.6Hive HA基本原理
Hive HA:全稱為Hive High Availability,高可用性Hive解決方案,
在實際應用中,Hive會表現出很多不穩定性,比如埠呼叫沒有回應、行程丟失等,Hive HA就是對這種不穩定性的解決方案,
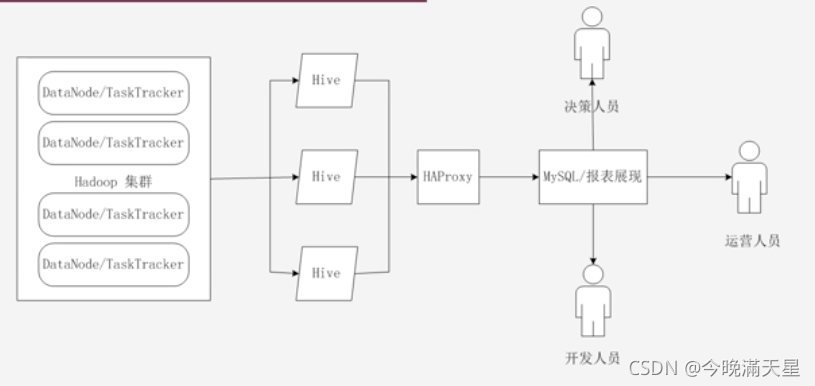
外部訪問先訪問HA Proxy,然后HA Proxy依次對底層的各個示例進行詢問示例是否可用,執行邏輯可用性測驗,如果通過測驗就將用戶請求轉發給這個可用的示例,否則將示例加入黑名單,每隔一定周期,HA Proxy會對列入黑名單的示例進行統一處理(進行重啟,重啟成功的重新放回資源池),
6.3SQL陳述句轉為MapReduce作業
Hive本身不做具體的資料處理和存盤,而是把SQL陳述句轉換成相關的MapReduce作業,
6.3.1SQL陳述句轉為MapReduce作業的基本原理
連接:怎么能用MapReduce來實作資料庫的連接操作?
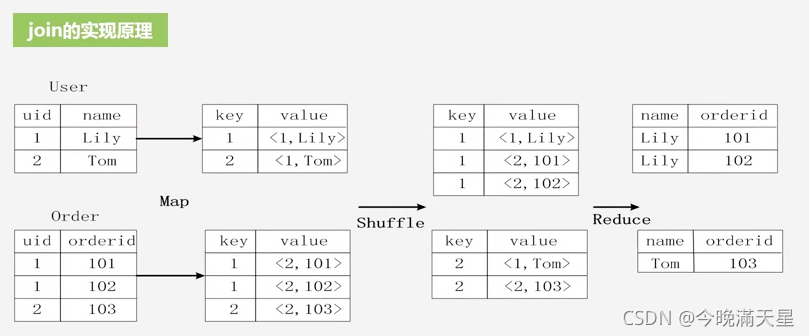
實體1. join的實作原理
user表和order表具有公共欄位uid,因此兩表具有連接條件,
首先,需要用戶撰寫一個Map處理邏輯,將關系資料庫的表輸入到Map處理邏輯中,對于輸入的每一行記錄通過Map進行轉換,生成一系列鍵值對,比如User表的第一行記錄經過Map處理后會輸出鍵值對,key為uid的值,value是一個二元組<1,Lily>,這個二元組中的1表示鍵值對所屬的表,是表User的標記位,同理,2是表Score的標記位,
通過Map函式,可以將輸入的User表和Order表都轉換成鍵值對,通過Shuffle的程序把這些鍵值對進行磁區、排序,分別發送給不同的Reduce,在圖中假設,把所有key為1的鍵值對都分配給第一個Reduce任務,把所有key為2的鍵值對都分配給第二個Reduce任務,
鍵值對進行Reduce操作的前提是他們的key相等且來自不同表,
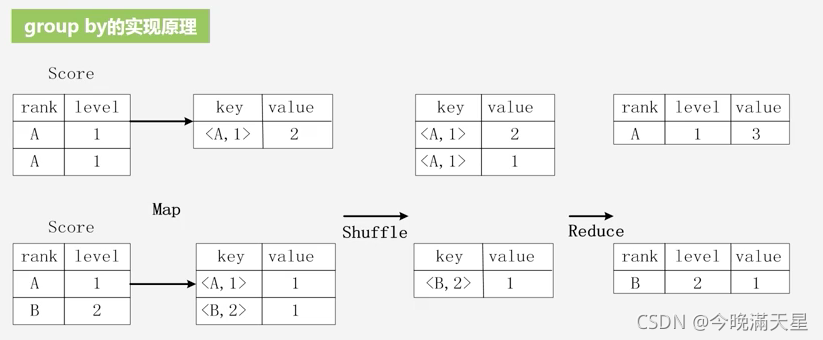
實體2. group by的實作原理
假設下圖中是來自Score表的兩個不同片段,現在想要進行group by操作,把表Score的不同片段按照rank和level的組合值進行合并,計算不同rank和level的組合值分別有幾條記錄,比如rank為A且level為1的記錄條數,該操作對應的SQL陳述句為:
select rank,level,count(*) as value
from score
group by rank,level
若想用MapReduce實作,首先把表輸入到Map函式中做用戶邏輯的處理,處理后輸出鍵值對,鍵值對的key為rank和level的組合,value為計算出的這種組合的記錄條數,
經過Map函式映射后,得到鍵值對串列,接著對這些鍵值對進行Shuffle操作,進行磁區、排序,然后分配給不同的Reduce任務處理,
6.3.2Hive中SQL查詢轉換成MapReduce作業的程序
當用戶向Hive輸入一段命令或查詢時,Hive需要與Hadoop互動來完成該操作:
1.驅動模塊接收該命令或查詢編譯器
2.對該命令或查詢進行決議編譯
3.由優化器對該命令或查詢進行優化計算
4.該命令或查詢通過執行器進行執行
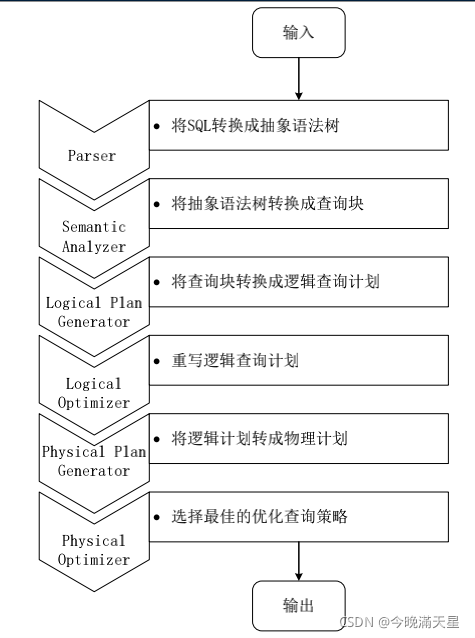
具體程序可以分為如下七個步驟:
1.由Hive驅動模塊中的編譯器對用戶輸入的SQL語言進行詞法和語法決議,將SQL陳述句轉化成抽象語法樹的形式,
2.抽象語法樹的結構仍然很復雜,不方便直接翻譯為MapReduce演算法程式,因此需要把抽象語法樹轉化為查詢塊,
3.把查詢塊轉換成邏輯查詢計劃,里面包含了許多邏輯運算子,
4.重寫邏輯操作計劃,進行優化合并多余操作,減少MapReduce任務數量,
5.將邏輯運算子轉換成需要執行的具體MapReduce任務,
6.對生成的MapReduce任務進行優化生成最終的MapReduce任務執行計劃,
7.由Hive驅動模塊中的執行器對最終的MapReduce任務進行執行輸出,
示意圖如下:
需要注意的是:
當啟動MapReduce程式時,Hive本身是不會生成MapReduce程式的,
需要通過一個表示"Job執行計劃"的XML檔案驅動執行內置的、原生的Mapper和Reducer模塊,Hive本身并不生成MapReduce演算法程式,
Hive通過和JobTracker通信來初始化MapReduce任務(JobTracker是MapReduce的管家),不必直接部署在JobTracker所在的管理節點上執行,
通常在大型集群上,會有專門的網關機來部署Hive工具,(網關機會和遠程節點上的JobTracker進行通信完成任務)
資料檔案通常存盤在HDFS上,HDFS由名稱節點管理,
6.4Impala
6.4.1Impala簡介
Hive建立在Hadoop平臺上,它依賴底層的MapReduce和HDFS,所以延遲比較高,針對這個問題,設計了Impala,也用于做資料倉庫分析,但是性能比Hive高3~30倍,
有人認為,Impala未來會稱為最流行的實時性互動查詢工具,
Impala是由Cloudera公司開發的新型查詢系統,允許通過SQL陳述句查詢底層資料,可以查詢PB級別以上的大資料,能查詢存盤在Hadoop的HDFS中,或者HBase中的資料,
Impala的運行需要依賴于Hive的元資料,
Impala最初是參考Google的Dremel系統(專門做實時性互動查詢的)進行設計的,
與Hive不同的是,Hive要將SQL陳述句轉換為底層的一系列MapReduce任務執行,而Impala采用了與商用并行關系資料庫類似的分布式查詢引擎,可以直接與HDFS和HBase進行互動查詢,查詢實時性比Hive高,
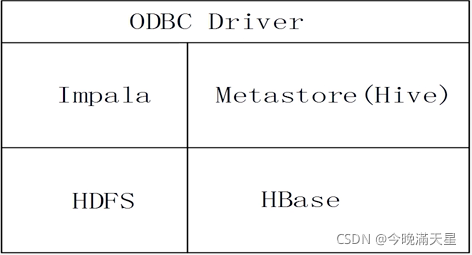
如下圖所示,Impala和Hive都是構建在底層的HDFS和HBase之上的,Impala和Hive都不是自身存盤資料,并且,Impala和Hive采用相同的SQL語法、ODBC驅動程式和用戶介面,
6.4.2Impala系統架構
圖中虛線部分,表示屬于Impala系統組件,實線部分表示Impala并不是單獨部署的,和Hadoop平臺的其他組件部署在同一個集群上面,
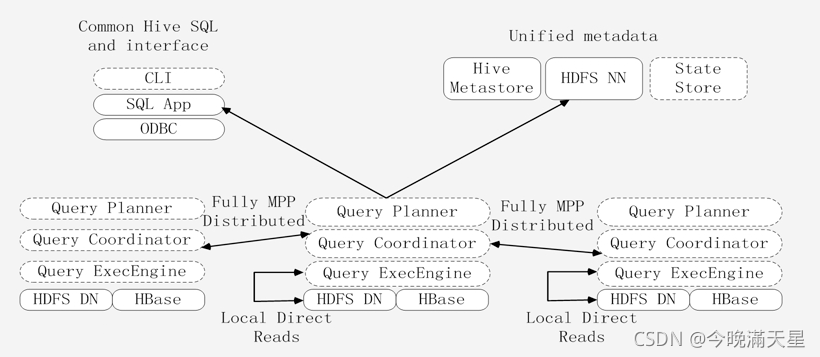
Impala和Hive、HDFS、HBase等工具是統一部署在一個Hadoop平臺上的,
Impala的三大組件:
-
Impalad
負責具體的相關查詢任務,
包含著三個模塊:Query Planner(查詢計劃器)、Query Coordinator(查詢協調器)、Query Exec Engine(查詢執行引擎),
負責協調客戶端提交的查詢的執行,
與HDFS的資料節點(HDFS DataNode)運行在同一節點上,以便就近處理資料,
給其他Impalad分配任務,以及收集其他Impalad的執行結果進行匯總,(大規模資料集分布存盤在不同的資料節點上,運行時要進行分布式查詢,每個子查詢查詢不同資料節點上的資料,這些子查詢由在不同資料節點上的Impalad執行,Impalad負責執行各自的子查詢,)
Impalad也會執行其他Impalad給其分配的任務(其他查詢發起后,也會有另外的Impalad作為管家,把分片分成多個子查詢給Impalad做),對本地HDFS和HBase里的部分資料進行操作, -
State Store
負責元資料管理和狀態資訊維護,
每個查詢提交后,系統會為其創建一個state store行程,由于不同節點上有多個Impalad行程,分別執行各自的任務,因此需要state store跟蹤執行情況、健康狀態資訊等,
因此,state store要負責收集分布在集群中各個Impalad行程的資源資訊用于查詢調度, -
CLI
用戶訪問介面,
CLI是給用戶提供查詢使用的命令列工具,同時提供了Hue、JDBC、ODBC的使用介面,
說明:
Impala的元資料是直接存盤在Hive中的,它借助Hive來存盤Impala的元資料,
Impala采用與Hive相同的元資料、相同的SQL語法、相同的ODBC驅動程式和用戶介面,使得在一個Hadoop平臺上可以統一部署Hive和Impala等分析工具,實作在一個平臺什么可以同時滿足批處理和實時查詢,
6.4.3Impala查詢執行程序
Impala執行查詢的程序如下所示:
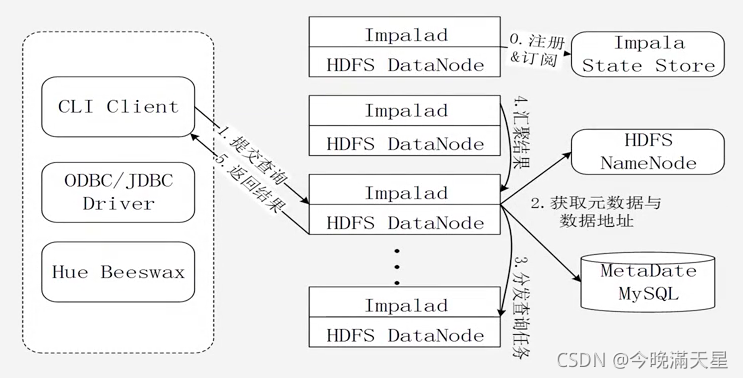
具體的查詢步驟為:
0.用戶的一個查詢提交之前,Impala先創建一個負責協調客戶端提交的查詢的Impalad行程,該行程會向Impala State Store提交注冊訂閱資訊,State Store會創建一個statestored行程,statestored行程通過創建多個執行緒來處理Impalad的注冊訂閱資訊,
1.用戶通過CLI客戶端提交一個查詢到Impalad行程,Impalad的Query Planner對SQL陳述句進行決議,生成決議樹,Planner把這個決議樹變成若干PlanFragment,發送到Query Coordinator(協調不同Impalad進行子查詢、收集結果等),
2.Coordinator通過從MySQL元資料庫中獲取元資料,從HDFS的名稱節點中獲取資料地址,以得到存盤這個查詢相關資料的所有資料節點,
3.Coordinator初始化相應Impalad上的任務執行,即把查詢任務分配給所有存盤這個查詢相關資料的資料節點,
4.Query Executor通過流式交換中間輸出,并由Query Coordinator匯聚來自各個Impalad的結果,
5.Coordinator把匯總后的結果回傳給CLI客戶端,
6.4.4Impala與Hive的比較
對比示意圖:
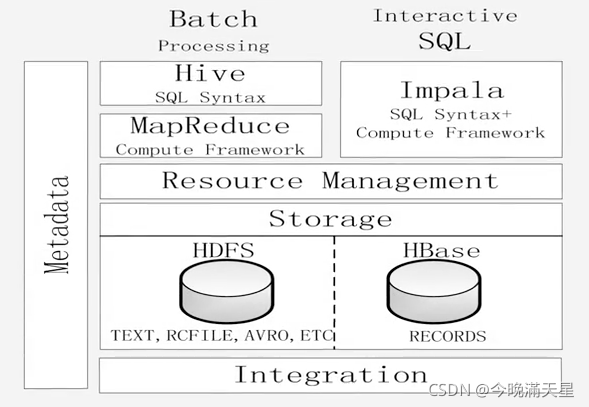
Impala與Hive的不同點:
- Hive適合于長時間的批處理查詢分析,而Impala適合于實時互動式SQL查詢,(Hive架構在MapReduce上,需要將SQL查詢轉換成MapReduce任務,而MapReduce是面向批處理的,延遲高,而Impala直接架構在底層上,性能高,)
- Hive依賴于MapReduce計算框架,Impala把執行計劃表現為一棵完整的執行計劃樹,直接分發執行計劃到各個Impala執行查詢,
- Hive在執行程序中,如果記憶體放不下所有資料則會使用外存,以確保查詢能順利執行完畢,而Impala在遇到記憶體放不下資料時,不會利用外存,因此Impala目前處理查詢時會受到一定的限制,
Impala與Hive的相同點:
- Hive與Impala使用相同的存盤資料池,都支持把資料存盤在HDFS和HBase中,
- Hive與Impala使用相同的元資料,
- Hive與Impala對SQL的解釋處理比較相似,都是通過詞法分析生成執行計劃,
總結:
Impala的設計目的不在于替換現有的MapReduce工具,(為了彌補Hive實時性不高的缺陷)
把Hive與Impala配合使用效果最佳,
可以先使用Hive進行資料轉換處理,之后再使用Impala在Hive處理后的結果資料集上進行快速的資料分析,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/317843.html
標籤:其他
上一篇:MySQL資料庫基礎